
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- JEP 387 "Elastic Metaspace" - a new classroom for ...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member75
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
07-16-2021
3:50 PM
The Java Virtual Machine needs memory to breathe - sometimes more than we like. One of its hungrier subsystems can be the Metaspace, the part of the JVM holding class metadata. With JEP 387, SAP contributed a much more frugal and elastic implementation to the OpenJDK.
-- The original of this article (in German) can be found at JavaMagazin 7/2021 --
Java 16 came with a handful of new JEPs [1]. We find new features like the new Vector API and the now fully incubated Java Records. In this list, we also find the somewhat mysteriously named JEP 387: "Elastic Metaspace" [2]. Despite its relative obscurity, it was one of the largest outside contributions for this release, with the patch itself counting upwards of 25kloc.
What is a JEP?
Java - the Java Virtual Machine and the JDK - are developed under the umbrella of the OpenJDK [7], a massive Open Source project under the stewardship of Oracle and other companies. SAP has been a long-time contributor to that project, with our first involvement going back to 2012.
OpenJDK development is governed by processes, and normal enhancements go through a process called Request for Enhancement (RFE). An RFE requires patch reviews but usually little else unless the patch affects compatibility.
But significant changes to the JVM, the Java language, or the API surface of the JDK stretch the confines of an RFE. They are therefore subject to the more heavy-weight Java Enhancement Proposal process (which, in beautiful recursion, is defined by its own JEP [3]). A JEP requires much more extensive design- and code reviews. As a result, it often takes a lot longer than a simple RFE. Still, JEPs are essential to ensure the long-term quality and compatibility of the JDK.
Most JEPs Oracle does by itself, even though the process is open to all. That may come down to sheer talent pool size. But outside JEPs are possible and are done: for example, in 2019, Red Hat provided their well-known Shenandoah-GC as JEP 189.
At SAP, we authored several JEPs in the past, so JEP 387 is not our first rodeo either. We contributed large architecture ports (JEP 175: "PowerPC Port/AIX" and JEP 294: "s390x Port"), and, more recently, the smaller but well-received JEP 358: "Helpful NullPointerExceptions."
The JVM can be a resource-hungry beast. The largest consumer of memory is typically the Java heap, and arguably that is fine and expected since it contains the actual program data. All else is just necessary surplus - grease needed to make the machinery run.
Therefore, users are sometimes surprised to find that Java heap consumption is just a part of the total JVM process footprint. But there are many internal data we need to accommodate, for example:
All these data live outside the Java heap, either in C-Heap or in manually managed mappings. Colloquially named off-heap - or, somewhat more incorrectly, native - memory, the combined size of these regions can surpass that of the heap itself.
In the JVM, one of the largest consumers of native memory can be the Metaspace. So optimizing Metaspace footprint is worthwhile. Especially since it could spiral out of control if conditions were just the right kind of wrong: before Java 16, Metaspace did not cope well with certain - entirely valid - class loading patterns.
That was the primary purpose of JEP 387. Metaspace, introduced with Java 8, had remained for the most part unchanged since its inception. It was time for an overhaul.
The Metaspace holds class metadata. What are they?
A Java class consists of much more than just the
A Java class starts its life by being loaded by a class loader. During class loading, the loader creates the
A java class is removed - unloaded - only if its loading class loader dies. The Java Specification defines this:
This rule has some interesting consequences. An
Therefore, we have a "bulk-free" scenario: class metadata are bound to a class loader and released in bulk when that loader dies (there are exceptions to that rule we ignore here to keep things simple).
Today class metadata live in native memory. That had not always been the case: before Java 8, they lived in the heap within the so-called Permanent Generation (PermGen). The GC managed them like ordinary Java objects, and that came with several drawbacks.
As part of the Java heap, the size of the PermGen was limited. That size had to be specified upfront at VM start. A too-tight limit usually caused an irrecoverable OOM, and so users tended to oversize the PermGen. That wasted memory and address space. Living in the heap also meant that the PermGen had to be a contiguous region, which could problems on 32-bit platforms with their restricted address space.
Another problem of the PermGen was the effort needed to free metadata. The GC treated them like ordinary java objects: entities that can die and be collectible at arbitrary points in time. But class metadata are bound to their loader and hence their lifetime is quite predictable. Therefore, the flexibility of a general garbage collection was unnecessary and the associated cost wasted [6].
The PermGen also made life more difficult for JVM developers. Since the metadata lived in the Java heap, they were not address-stable; the GC could move them around. Handling these data from within the JVM was cumbersome since references needed to be resolved to physical pointers on access. In addition, it also made debugging the JVM and analyzing core files less fun.
In 1998, students in Stockholm built an alternative Java VM, the JRockit VM, and founded Appeal Virtual Machines. In 2002 BEA Systems took over Appeal, and in 2008 Oracle, in turn, acquired BEA.
In 2010, Oracle bought Sun Microsystems. After this second acquisition, Oracle owned two independent JVM implementations, the JRockit VM and the original Sun JVM. The JRockit JVM was canceled and the focus shifted on the Sun JVM.
Luckily, Sun had open-sourced its JVM before the takeover. In 2007 the OpenJDK project was founded, and a large part of the codebase had been published under GPLv2. After the Sun acquisition, Oracle thankfully did not revert that decision but continued to support the OpenJDK.
The JRockit VM did not keep class metadata in heap but in native memory. That coincided with the current thinking inside the ex-Sun-JVM group at that time. So it was decided to scrap the PermGen (see JEP 122: "Remove the Permanent Generation " [8]).
JEP 122 shipped with Java 8 in 2014: the PermGen had been removed for good, all class metadata shepherded over into native memory. Thus, the (first) Metaspace was born.
The authors of JEP 122 tailored the new Metaspace allocator for the fast and efficient management of class metadata, which are released in bulk. That differs from general-purpose allocators like the C-heap, which are geared toward tracking individual allocations with arbitrary, unpredictable lifetimes. General-purpose allocators pay for that flexibility with complexity and overhead. But bulk-released data don't need to be tracked individually, so this flexibility is unneeded.
Better suited for bulk-release data is a so-called Arena Allocator [9]. In its simplest form, an arena is a contiguous region: on each new allocation request, an allocation top pointer is pushed up to make space for the new allocation. This technique is primitive but very fast. It is also very memory-efficient since waste is limited to padding requirements. We pay for this efficiency by not being able to track individual allocations: allocations are not released individually but only as a whole, by scrapping the arena.
If this sounds familiar, it's because it is. Thread stacks are just arenas bound to a thread, and so is the old Unix process heap (
The Metaspace is also, in its heart, an arena allocator. Here, an arena is not bound to a thread like a thread stack or a TLAB. Instead, a class loader owns the arena and releases it upon death.
As a specialty, Metaspace arenas are able to handle prematurely released blocks. They are kept in a free-block dictionary within the arena. This is needed when old class metadata are released while the class lives on, e.g. at class redefinition. These cases are rare though.
Technically, a Metaspace arena does not consist of a single contiguous memory region but a chain of regions, so-called chunks. The chain grows on demand. When the class loader dies, the Metaspace allocator walks that chain and releases the chunks by adding them to a global free list for later reuse.
Underneath the chunk layer lives a custom virtual memory layer that manages much more coarse-grained memory mappings at the OS level. The size of these mappings (called virtual space nodes) can vary from several MB to several GB in the case of the class space.
Metaspace consists of two parts (on 64-bit): the "normal" Metaspace and the class space. The latter exists due to an optimization technique the JVM employs.
Every Java object has a header that contains a pointer to the Klass structure. On 64-bit platforms, this pointer uses up 64-bit. That is a lot! Consider that every java object contains this header.
To save memory, the JVM places all Klass structures into a confined region in memory and only stores the 32-bit offset into this region in the object header. That shrinks the object header size by four bytes, which shaves off several percent of heap memory (how much depends on the object granularity of your application).
The memory region the JVM uses is called the class space. It is part of the Metaspace. In contrast to other memory mappings Metaspace uses, the class space needs to be reserved at VM start. With 1G it is rather extensive, but that does not really matter since it gets committed on-demand only.
The first Metaspace, in Java 8, was a great improvement over the PermGen. But it also brought new problems, manifesting in occasional very high memory footprint and much-reduced elasticity. From a high level, these new problems were caused by the class metadata leaving the comfortable embrace of the Java heap and rolling its own memory allocator instead. Which, as it turned out, held some pitfalls.
At SAP, we investigated customer problems and got more involved with Metaspace development at that point.
For a start, Metaspace chunk management had been too rigid. Chunks, which came in various sizes, could never be resized. That limited their reuse potential after their original loader died. The free list could fill up with tons of chunks locked into the wrong size, which Metaspace could not reuse.
SAP contributed a large patch [11] for Java 11 which alleviated the problem but did not completely solve it. But this was SAPs first significant contribution in that area. Around that time we also contributed monitor tools to analyze Metaspace composition (
The first Metaspace also lacked elasticity and did not recover well from usage spikes.
When classes get unloaded, their metadata are not needed anymore. Theoretically, the JVM could hand those pages back to the Operating System. If the system faces memory pressure, the kernel could give those free pages to whoever needs it most, which could include other areas of the JVM itself. Holding on to that memory for the sake of some possible future class loads is not useful.
But Metaspace retained most of its memory by keeping freed chunks in the free list. To be fair, a mechanism existed to return memory to the OS by unmapping empty virtual space nodes. But this mechanism was very coarse-grained and easily defeated by even moderate Metaspace fragmentation. Moreover, it did not work at all for the class space.
In the old Metaspace, small class loaders were disproportionally affected by high memory overhead. If the size of your loaders hit those "sweet spot" size ranges, you paid significantly more than the loader needed. For example, a loader allocating ~20K of metadata would consume ~80K internally, wasting upward of 75% of the allocated space.
These amounts are tiny but quickly add up when dealing with swarms of small loaders. This problem mostly plagued scenarios with automatically generated class loaders, e.g., dynamic languages implemented atop Java.
We wanted to improve this. By that time, the Metaspace code base had gotten unwieldy and difficult to maintain, so we decided to scratch it completely and contribute a clean reimplementation. This work needed a JEP since due to its size and the involved risk, it was beyond the scope of a normal RFE. It needed much closer scrutiny, testing, and cooperation from Oracle's runtime- and GC folks.
With Java 16, JEP 387 shipped - the new Metaspace was born. It retained the basic principles of the old Metaspace architecture by being, in its core, an arena allocator atop its own virtual memory layer. But there were crucial differences.
The first Metaspace allocator committed memory in a very coarse-grained fashion. When it created a new chunk, it was fully committed. Chunks were never uncommitted as long as they lived, even if they idled around unused in the free list. This behavior made the first Metaspace very inelastic.
The Metaspace in Java 16 can commit and uncommit arbitrary memory ranges in a very fine-granular fashion, and that also works for the backing memory of life chunks. That ability makes the new Metaspace much more flexible: after a class loader dies and all its chunks are released from its arena and added to the free list, their backing memory can now be uncommitted. Thus, while the chunks reside in the free list waiting for reuse, they won't use up physical memory, only address space.
Moreover, we can now commit chunks lazily, partwise, instead of having them committed fully on creation. So, when a class loader starts allocating from a new chunk, it will get committed on-demand, and only as far as necessary to fulfill new allocation requests. This works a bit like thread stacks do. That way, we delay memory usage of physical pages as long as possible, perhaps forever, since often a loader does not use an entire chunk. We can now also hand larger chunks to loaders without suffering an overhead penalty, reducing fragmentation.
To achieve this new flexibility, we divided metaspace backing memory into a series of commit granules. These homogenously sized areas serve as the smallest unit of committing and uncommitting memory. A global bitmap remembers the commit state of each granule. The size of these granules is adjustable and determines the commit granularity.
Chunk geometry in the old Metaspace was rigid and inflexible. Chunks mainly existed in three rather arbitrarily spaced sizes and were very difficult to merge and split. That inefficient geometry quickly caused fragmentation when class unloading began and was the reason for the high per-class-loader overhead.
The new Metaspace uses a new allocation scheme to manage chunks in memory, based on the buddy allocation algorithm [13]. This algorithm is fast and efficient, achieves tight memory packing, and is very good at keeping fragmentation at bay. All that it manages at a pretty low runtime cost.
The buddy allocator algorithm is ancient, originating from the 1960s. It is widely used in C-Heap implementations or virtual memory management in operating systems. For instance, the Linux kernel uses a variant of this algorithm to manage physical pages.
A typical buddy allocator manages power-of-two-sized blocks. Because of that, it is not the best choice for implementing an "end-user" allocation scheme like malloc() since that would waste memory with every allocation not perfectly power-of-two-sized. But the way Metaspace uses buddy allocation, this limitation does not matter: the buddy allocator manages chunks that are not the end product of metadata allocation but the much more coarse-grained building blocks used to implement Metaspace arenas.
Very simplified, buddy allocation in Metaspace works like this:
Deallocation of a chunk works in reverse order:
Like a self-healing ice sheet, chunks splinter on allocation and crystallize back into larger units on deallocation. It is an excellent way of keeping fragmentation at bay even if this process repeats endlessly, e.g., in a JVM which loads and unloads tons of classes in its life time.
Now, "talk is cheap, show me the code". The code is out there. How does the new Metaspace shape up compared to the old one?
To demonstrate improvements in elasticity, we let a test case [14] cause a temporary memory spike in Metaspace by loading test classes via multiple class loaders (A). The loaders load the classes in an interleaved fashion to induce controlled fragmentation. After a short pause, the test unloads 90% of the loaders (B). We execute the test with Java 15 and Java 16 and monitor Metaspace footprint.
The JVM in Java 15 retains much or even all of its memory after (B). We can see that this effect worsens with fragmentation (which is very common). Faced with the same scenario, the new Metaspace in Java 16 recovers well from the usage peak, reacting much more elastic than before. Fragmentation has not much influence on this new-found elasticity.
At the end of the test, the test releases the final 10% of loaders (D). Note how the old allocator holds on to some memory even now, never entirely falling back to the pre-test footprint. In contrast, Metaspace in Java 16 is back to pre-test levels.
JEP 387 also reduced the overhead of class loaders. Let's see how that works out.
Again, our test program loads a lot of classes (20k). In the first test run, we spread class loading over 10k loaders, each of which loads just two classes. In the second run, we shift the ratio to 2.5k loaders and eight classes.
As before, the test unloads 90% of the classes (B), then waits a while and unloads the remaining 10% (C).
We compare the Metaspace footprint of Java 15 and Java 16 side by side. Owing to the waste overhead, Java 15 shows a much higher Metaspace footprint. Worst fares the 10000:2 case, where Metaspace consumes a whopping 800M, and still close to 400M in the 2500:8 case. In addition, Java 15 releases no memory after the spike.
The 10k:2 case nicely demonstrates the "valley of death" effect with the old allocator, where unlucky class loaders hitting just the wrong size range were penalized by very high overhead.
In Java 16, the Metaspace is not fazed by this scenario, behaving much more nicely now. Footprint grows to 260M and 230M, respectively. Also, it lets go of some of that memory after initial class unloading, so even in the face of this high fragmentation (lots of small interleaved loaders), it retains some elasticity.
A small side benefit of the delayed committing of chunks is a reduced footprint for small Java programs. With Java 15, even with a tiny "Hello World," Metaspace footprint was never less than 4.7MB. With Java 16, the JVM gets by with a lot less: about 450K of Metaspace are usually sufficient. Small fish, but every little bit helps.
As we saw, the new Metaspace in Java 16 saves memory - how much depends on the scenario. Elasticity and reduced fragmentation benefit mostly large applications with long uptimes. The decreased overhead per class loader helps cases with fine-granular loader schemes. The new Metaspace code base is also cleaner and less complex, which reduces costs for us maintainers and makes future enhancements easier.
Bringing a patch of this size upstream into the OpenJDK was a challenge. Happily, cooperation with the developers at Oracle was excellent. Oracle also provided a large part of the review muscle needed. Special thanks to Coleen Phillimore for her encouragement and help to navigate the JEP process.
Are JEPs feasible for OpenJDK contributors other than Oracle? We think so. But you need to have realistic expectations about the time it costs and the amount of communication involved. A JEP is a heavy-weight tool; it should only be used if really necessary. For most enhancements, the standard RFE process is just fine.
Links & Literatur
-- The original of this article (in German) can be found at JavaMagazin 7/2021 --
Java 16 came with a handful of new JEPs [1]. We find new features like the new Vector API and the now fully incubated Java Records. In this list, we also find the somewhat mysteriously named JEP 387: "Elastic Metaspace" [2]. Despite its relative obscurity, it was one of the largest outside contributions for this release, with the patch itself counting upwards of 25kloc.
What is a JEP?
Java - the Java Virtual Machine and the JDK - are developed under the umbrella of the OpenJDK [7], a massive Open Source project under the stewardship of Oracle and other companies. SAP has been a long-time contributor to that project, with our first involvement going back to 2012.
OpenJDK development is governed by processes, and normal enhancements go through a process called Request for Enhancement (RFE). An RFE requires patch reviews but usually little else unless the patch affects compatibility.
But significant changes to the JVM, the Java language, or the API surface of the JDK stretch the confines of an RFE. They are therefore subject to the more heavy-weight Java Enhancement Proposal process (which, in beautiful recursion, is defined by its own JEP [3]). A JEP requires much more extensive design- and code reviews. As a result, it often takes a lot longer than a simple RFE. Still, JEPs are essential to ensure the long-term quality and compatibility of the JDK.
Most JEPs Oracle does by itself, even though the process is open to all. That may come down to sheer talent pool size. But outside JEPs are possible and are done: for example, in 2019, Red Hat provided their well-known Shenandoah-GC as JEP 189.
At SAP, we authored several JEPs in the past, so JEP 387 is not our first rodeo either. We contributed large architecture ports (JEP 175: "PowerPC Port/AIX" and JEP 294: "s390x Port"), and, more recently, the smaller but well-received JEP 358: "Helpful NullPointerExceptions."
Off-Heap Memory and the Metaspace
The JVM can be a resource-hungry beast. The largest consumer of memory is typically the Java heap, and arguably that is fine and expected since it contains the actual program data. All else is just necessary surplus - grease needed to make the machinery run.
Therefore, users are sometimes surprised to find that Java heap consumption is just a part of the total JVM process footprint. But there are many internal data we need to accommodate, for example:
- Thread stacks
- GC control structures
- Interned Strings
- CDS archives and text segments
- JIT-compiled code (the code cache)
- and many many other things
All these data live outside the Java heap, either in C-Heap or in manually managed mappings. Colloquially named off-heap - or, somewhat more incorrectly, native - memory, the combined size of these regions can surpass that of the heap itself.
In the JVM, one of the largest consumers of native memory can be the Metaspace. So optimizing Metaspace footprint is worthwhile. Especially since it could spiral out of control if conditions were just the right kind of wrong: before Java 16, Metaspace did not cope well with certain - entirely valid - class loading patterns.
That was the primary purpose of JEP 387. Metaspace, introduced with Java 8, had remained for the most part unchanged since its inception. It was time for an overhaul.
Class Metadata
The Metaspace holds class metadata. What are they?
A Java class consists of much more than just the
java.lang.Class object in heap. When the JVM loads a class, it constructs a tree of structures composed mainly of pre-digested parts of the class file [4]. The root of this tree is a variable-sized structure named "Klass" (yes, capital 'K'), which - among many other things - also contains the class itable and vtable. Furthermore, the tree holds the constant pool, methods metadata, annotations, bytecode, and a whole lot more. It also contains data that are not loaded from class files but are purely runtime-generated, such as JIT-specific counters.... and their life cycle
A Java class starts its life by being loaded by a class loader. During class loading, the loader creates the
java.lang.Class object for this class in the heap and parses and stores metadata for this class in Metaspace. The more classes a loader loads throughout its life, the more metadata in Metaspace it accumulates. The class loader owns all these metadata.
Class metadata allocation
A java class is removed - unloaded - only if its loading class loader dies. The Java Specification defines this:
"A class or interface may be unloaded if and only if its defining class loader may be reclaimed by the garbage collector " [5].
This rule has some interesting consequences. An
java.lang.Classobject holds a reference to its loading java.lang.ClassLoader. All instances hold references to their java.lang.Classobject. Therefore, disregarding outside references, a class loader can only be collected when all its classes and all their instances are collectible. Once the class loader object is unreachable, the GC removes it and unloads all its classes. At that point, it also releases all class metadata the loader accumulated over its lifetime.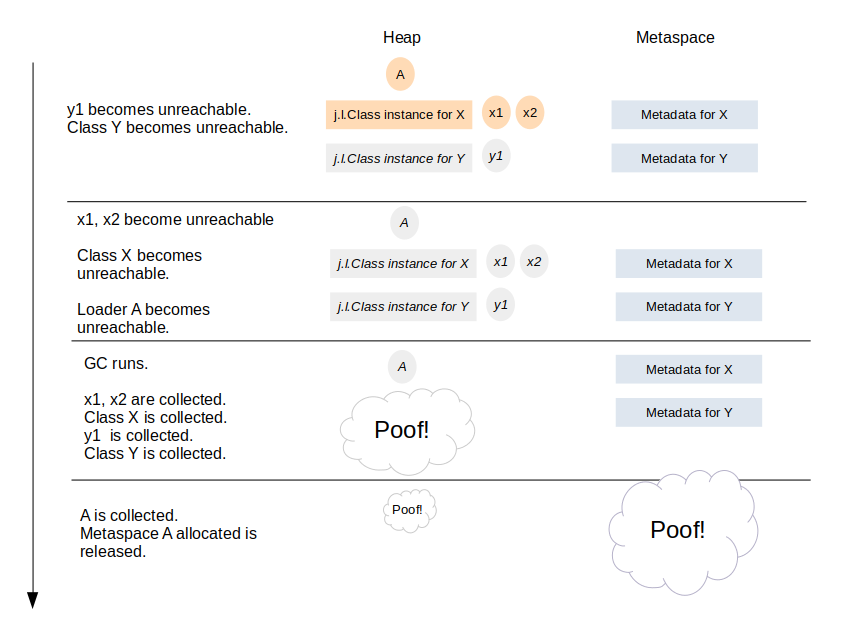
Class metadata deallocation
Therefore, we have a "bulk-free" scenario: class metadata are bound to a class loader and released in bulk when that loader dies (there are exceptions to that rule we ignore here to keep things simple).
Before Java 8: The Permanent Generation
Today class metadata live in native memory. That had not always been the case: before Java 8, they lived in the heap within the so-called Permanent Generation (PermGen). The GC managed them like ordinary Java objects, and that came with several drawbacks.
As part of the Java heap, the size of the PermGen was limited. That size had to be specified upfront at VM start. A too-tight limit usually caused an irrecoverable OOM, and so users tended to oversize the PermGen. That wasted memory and address space. Living in the heap also meant that the PermGen had to be a contiguous region, which could problems on 32-bit platforms with their restricted address space.
Another problem of the PermGen was the effort needed to free metadata. The GC treated them like ordinary java objects: entities that can die and be collectible at arbitrary points in time. But class metadata are bound to their loader and hence their lifetime is quite predictable. Therefore, the flexibility of a general garbage collection was unnecessary and the associated cost wasted [6].
The PermGen also made life more difficult for JVM developers. Since the metadata lived in the Java heap, they were not address-stable; the GC could move them around. Handling these data from within the JVM was cumbersome since references needed to be resolved to physical pointers on access. In addition, it also made debugging the JVM and analyzing core files less fun.
Intermission: BEA and the JRockit JVM
In 1998, students in Stockholm built an alternative Java VM, the JRockit VM, and founded Appeal Virtual Machines. In 2002 BEA Systems took over Appeal, and in 2008 Oracle, in turn, acquired BEA.
In 2010, Oracle bought Sun Microsystems. After this second acquisition, Oracle owned two independent JVM implementations, the JRockit VM and the original Sun JVM. The JRockit JVM was canceled and the focus shifted on the Sun JVM.
Luckily, Sun had open-sourced its JVM before the takeover. In 2007 the OpenJDK project was founded, and a large part of the codebase had been published under GPLv2. After the Sun acquisition, Oracle thankfully did not revert that decision but continued to support the OpenJDK.
The JRockit VM did not keep class metadata in heap but in native memory. That coincided with the current thinking inside the ex-Sun-JVM group at that time. So it was decided to scrap the PermGen (see JEP 122: "Remove the Permanent Generation " [8]).
Java 8 to Java 15: the first Metaspace
JEP 122 shipped with Java 8 in 2014: the PermGen had been removed for good, all class metadata shepherded over into native memory. Thus, the (first) Metaspace was born.
The authors of JEP 122 tailored the new Metaspace allocator for the fast and efficient management of class metadata, which are released in bulk. That differs from general-purpose allocators like the C-heap, which are geared toward tracking individual allocations with arbitrary, unpredictable lifetimes. General-purpose allocators pay for that flexibility with complexity and overhead. But bulk-released data don't need to be tracked individually, so this flexibility is unneeded.
Better suited for bulk-release data is a so-called Arena Allocator [9]. In its simplest form, an arena is a contiguous region: on each new allocation request, an allocation top pointer is pushed up to make space for the new allocation. This technique is primitive but very fast. It is also very memory-efficient since waste is limited to padding requirements. We pay for this efficiency by not being able to track individual allocations: allocations are not released individually but only as a whole, by scrapping the arena.
If this sounds familiar, it's because it is. Thread stacks are just arenas bound to a thread, and so is the old Unix process heap (
sbrk). The JVM keeps arenas in the Java heap for fast thread-local allocations (TLABs [10]). Video games have long used this technique to cram assets into limited memory and bulk-release them at the end of a level.The Metaspace is also, in its heart, an arena allocator. Here, an arena is not bound to a thread like a thread stack or a TLAB. Instead, a class loader owns the arena and releases it upon death.

Arena allocation in Metaspace
As a specialty, Metaspace arenas are able to handle prematurely released blocks. They are kept in a free-block dictionary within the arena. This is needed when old class metadata are released while the class lives on, e.g. at class redefinition. These cases are rare though.
Technically, a Metaspace arena does not consist of a single contiguous memory region but a chain of regions, so-called chunks. The chain grows on demand. When the class loader dies, the Metaspace allocator walks that chain and releases the chunks by adding them to a global free list for later reuse.
Underneath the chunk layer lives a custom virtual memory layer that manages much more coarse-grained memory mappings at the OS level. The size of these mappings (called virtual space nodes) can vary from several MB to several GB in the case of the class space.

Metaspace architecture
Side note: What exactly is the class space?
Metaspace consists of two parts (on 64-bit): the "normal" Metaspace and the class space. The latter exists due to an optimization technique the JVM employs.
Every Java object has a header that contains a pointer to the Klass structure. On 64-bit platforms, this pointer uses up 64-bit. That is a lot! Consider that every java object contains this header.
To save memory, the JVM places all Klass structures into a confined region in memory and only stores the 32-bit offset into this region in the object header. That shrinks the object header size by four bytes, which shaves off several percent of heap memory (how much depends on the object granularity of your application).
The memory region the JVM uses is called the class space. It is part of the Metaspace. In contrast to other memory mappings Metaspace uses, the class space needs to be reserved at VM start. With 1G it is rather extensive, but that does not really matter since it gets committed on-demand only.

Class space and compressed class pointers
Metaspace Problems
The first Metaspace, in Java 8, was a great improvement over the PermGen. But it also brought new problems, manifesting in occasional very high memory footprint and much-reduced elasticity. From a high level, these new problems were caused by the class metadata leaving the comfortable embrace of the Java heap and rolling its own memory allocator instead. Which, as it turned out, held some pitfalls.
At SAP, we investigated customer problems and got more involved with Metaspace development at that point.
Fixed chunk sizes
For a start, Metaspace chunk management had been too rigid. Chunks, which came in various sizes, could never be resized. That limited their reuse potential after their original loader died. The free list could fill up with tons of chunks locked into the wrong size, which Metaspace could not reuse.
SAP contributed a large patch [11] for Java 11 which alleviated the problem but did not completely solve it. But this was SAPs first significant contribution in that area. Around that time we also contributed monitor tools to analyze Metaspace composition (
jcmd VM.metaspace [12]).The lack of elasticity
The first Metaspace also lacked elasticity and did not recover well from usage spikes.
When classes get unloaded, their metadata are not needed anymore. Theoretically, the JVM could hand those pages back to the Operating System. If the system faces memory pressure, the kernel could give those free pages to whoever needs it most, which could include other areas of the JVM itself. Holding on to that memory for the sake of some possible future class loads is not useful.
But Metaspace retained most of its memory by keeping freed chunks in the free list. To be fair, a mechanism existed to return memory to the OS by unmapping empty virtual space nodes. But this mechanism was very coarse-grained and easily defeated by even moderate Metaspace fragmentation. Moreover, it did not work at all for the class space.
High per-classloader overhead
In the old Metaspace, small class loaders were disproportionally affected by high memory overhead. If the size of your loaders hit those "sweet spot" size ranges, you paid significantly more than the loader needed. For example, a loader allocating ~20K of metadata would consume ~80K internally, wasting upward of 75% of the allocated space.
These amounts are tiny but quickly add up when dealing with swarms of small loaders. This problem mostly plagued scenarios with automatically generated class loaders, e.g., dynamic languages implemented atop Java.
Java 16: Metaspace, reinvented
We wanted to improve this. By that time, the Metaspace code base had gotten unwieldy and difficult to maintain, so we decided to scratch it completely and contribute a clean reimplementation. This work needed a JEP since due to its size and the involved risk, it was beyond the scope of a normal RFE. It needed much closer scrutiny, testing, and cooperation from Oracle's runtime- and GC folks.
With Java 16, JEP 387 shipped - the new Metaspace was born. It retained the basic principles of the old Metaspace architecture by being, in its core, an arena allocator atop its own virtual memory layer. But there were crucial differences.
Commit Granules
The first Metaspace allocator committed memory in a very coarse-grained fashion. When it created a new chunk, it was fully committed. Chunks were never uncommitted as long as they lived, even if they idled around unused in the free list. This behavior made the first Metaspace very inelastic.
The Metaspace in Java 16 can commit and uncommit arbitrary memory ranges in a very fine-granular fashion, and that also works for the backing memory of life chunks. That ability makes the new Metaspace much more flexible: after a class loader dies and all its chunks are released from its arena and added to the free list, their backing memory can now be uncommitted. Thus, while the chunks reside in the free list waiting for reuse, they won't use up physical memory, only address space.
Moreover, we can now commit chunks lazily, partwise, instead of having them committed fully on creation. So, when a class loader starts allocating from a new chunk, it will get committed on-demand, and only as far as necessary to fulfill new allocation requests. This works a bit like thread stacks do. That way, we delay memory usage of physical pages as long as possible, perhaps forever, since often a loader does not use an entire chunk. We can now also hand larger chunks to loaders without suffering an overhead penalty, reducing fragmentation.
To achieve this new flexibility, we divided metaspace backing memory into a series of commit granules. These homogenously sized areas serve as the smallest unit of committing and uncommitting memory. A global bitmap remembers the commit state of each granule. The size of these granules is adjustable and determines the commit granularity.
Buddy Allocation
Chunk geometry in the old Metaspace was rigid and inflexible. Chunks mainly existed in three rather arbitrarily spaced sizes and were very difficult to merge and split. That inefficient geometry quickly caused fragmentation when class unloading began and was the reason for the high per-class-loader overhead.
The new Metaspace uses a new allocation scheme to manage chunks in memory, based on the buddy allocation algorithm [13]. This algorithm is fast and efficient, achieves tight memory packing, and is very good at keeping fragmentation at bay. All that it manages at a pretty low runtime cost.
The buddy allocator algorithm is ancient, originating from the 1960s. It is widely used in C-Heap implementations or virtual memory management in operating systems. For instance, the Linux kernel uses a variant of this algorithm to manage physical pages.
A typical buddy allocator manages power-of-two-sized blocks. Because of that, it is not the best choice for implementing an "end-user" allocation scheme like malloc() since that would waste memory with every allocation not perfectly power-of-two-sized. But the way Metaspace uses buddy allocation, this limitation does not matter: the buddy allocator manages chunks that are not the end product of metadata allocation but the much more coarse-grained building blocks used to implement Metaspace arenas.
Very simplified, buddy allocation in Metaspace works like this:
- Classloader requests space for metadata; its arena needs and requests a new chunk from the chunk manager.
- The chunk manager searches the free list for a chunk equal or larger than the requested size.
- If it found one larger than the requested size, it splits that chunk repeatedly in halves until the fragments have the requested size.
- It now hands one of the splinter chunks over to the requesting loader and adds the remaining splinters back into the free list.
Deallocation of a chunk works in reverse order:
- Classloader dies; its arena dies too and returns all its chunks to the chunk manager
- The chunk manager marks each chunk as free and checks its neighboring chunk ("buddy"). If it is also free, it fuses both chunks into a single larger chunk.
- It repeats that process recursively until either a buddy is encountered that is still in use, or until the maximum chunk size (and by that, maximum defragmentation) is reached.
- The large chunk is then decomitted to return memory to the operating system.
Like a self-healing ice sheet, chunks splinter on allocation and crystallize back into larger units on deallocation. It is an excellent way of keeping fragmentation at bay even if this process repeats endlessly, e.g., in a JVM which loads and unloads tons of classes in its life time.

Buddy allocation in Metaspace
Results
Now, "talk is cheap, show me the code". The code is out there. How does the new Metaspace shape up compared to the old one?
Better Elasticity
To demonstrate improvements in elasticity, we let a test case [14] cause a temporary memory spike in Metaspace by loading test classes via multiple class loaders (A). The loaders load the classes in an interleaved fashion to induce controlled fragmentation. After a short pause, the test unloads 90% of the loaders (B). We execute the test with Java 15 and Java 16 and monitor Metaspace footprint.
The JVM in Java 15 retains much or even all of its memory after (B). We can see that this effect worsens with fragmentation (which is very common). Faced with the same scenario, the new Metaspace in Java 16 recovers well from the usage peak, reacting much more elastic than before. Fragmentation has not much influence on this new-found elasticity.
At the end of the test, the test releases the final 10% of loaders (D). Note how the old allocator holds on to some memory even now, never entirely falling back to the pre-test footprint. In contrast, Metaspace in Java 16 is back to pre-test levels.
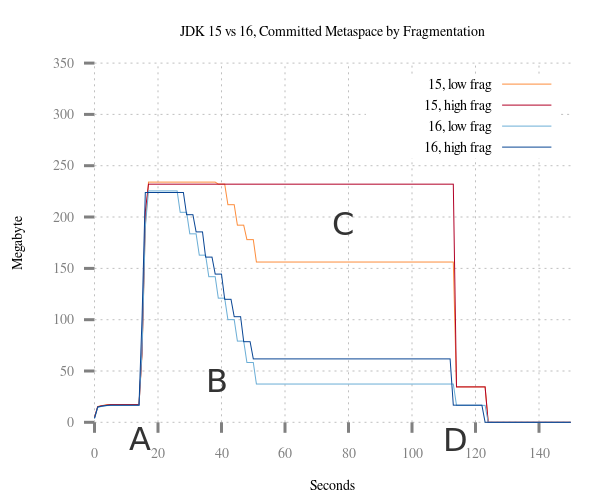
Improved Elasticity after usage spikes
Less overhead per class loader
JEP 387 also reduced the overhead of class loaders. Let's see how that works out.
Again, our test program loads a lot of classes (20k). In the first test run, we spread class loading over 10k loaders, each of which loads just two classes. In the second run, we shift the ratio to 2.5k loaders and eight classes.
As before, the test unloads 90% of the classes (B), then waits a while and unloads the remaining 10% (C).
We compare the Metaspace footprint of Java 15 and Java 16 side by side. Owing to the waste overhead, Java 15 shows a much higher Metaspace footprint. Worst fares the 10000:2 case, where Metaspace consumes a whopping 800M, and still close to 400M in the 2500:8 case. In addition, Java 15 releases no memory after the spike.
The 10k:2 case nicely demonstrates the "valley of death" effect with the old allocator, where unlucky class loaders hitting just the wrong size range were penalized by very high overhead.
In Java 16, the Metaspace is not fazed by this scenario, behaving much more nicely now. Footprint grows to 260M and 230M, respectively. Also, it lets go of some of that memory after initial class unloading, so even in the face of this high fragmentation (lots of small interleaved loaders), it retains some elasticity.

Less overhead for fine-grained class loaders
Smaller Metaspace use for small java programs
A small side benefit of the delayed committing of chunks is a reduced footprint for small Java programs. With Java 15, even with a tiny "Hello World," Metaspace footprint was never less than 4.7MB. With Java 16, the JVM gets by with a lot less: about 450K of Metaspace are usually sufficient. Small fish, but every little bit helps.
Wrapping up
As we saw, the new Metaspace in Java 16 saves memory - how much depends on the scenario. Elasticity and reduced fragmentation benefit mostly large applications with long uptimes. The decreased overhead per class loader helps cases with fine-granular loader schemes. The new Metaspace code base is also cleaner and less complex, which reduces costs for us maintainers and makes future enhancements easier.
Bringing a patch of this size upstream into the OpenJDK was a challenge. Happily, cooperation with the developers at Oracle was excellent. Oracle also provided a large part of the review muscle needed. Special thanks to Coleen Phillimore for her encouragement and help to navigate the JEP process.
Are JEPs feasible for OpenJDK contributors other than Oracle? We think so. But you need to have realistic expectations about the time it costs and the amount of communication involved. A JEP is a heavy-weight tool; it should only be used if really necessary. For most enhancements, the standard RFE process is just fine.
Further reading
- Leo Korinth, one of the JEP reviewers, published his own take on the new Metaspace, with more implementation details: "Metaspace in OpenJDK 16"
- A series of articles detailing the Metaspace implementation, how to size and monitor it: https://stuefe.de/posts/metaspace/metaspace-architecture
Links & Literatur
- [1] JDK 16
- [2] JEP 387: Elastic Metaspace
- [3] JEP 1: JDK Enhancement-Proposal & Roadmap Process
- [4] The Java Virtual Machine Specification
- [5] Java Language Specification - Class Unloading
- [6] Thomas Schatzl, Laurent Daynès, H. Mössenböck, „Optimized memory management for class metadata in a ...
- [7] The OpenJDK project page
- [8] JEP 122: Remove the Permanent Generation
- [9] Wikipedia, Region-based memory management
- [10] JVM Anatomy Quark #4: TLAB allocation
- [11] JDK-8198423 "Improve metaspace chunk allocation"
- [12] https://stuefe.de/posts/metaspace/analyze-metaspace-with-jcmd
- [13] Buddy Memory Allocation
- [14] https://github.com/tstuefe/javamagazin-jep387-examples
- SAP Managed Tags:
- Java,
- SAP Java Virtual Machine
Labels:
1 Comment
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
299 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
344 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
422 -
Workload Fluctuations
1
Related Content
- Pioneering Datasphere: A Consultant’s Voyage Through SAP’s Data Evolution in Technology Blogs by Members
- Safeguard your SAP BW conversion with SAP Enterprise Support services in Technology Blogs by SAP
- Regular multi-day service to support customers adopt SAP Build Apps in Technology Blogs by SAP
- How to Improve Modular Enterprise Resource Planning and Business Process Management Curriculum by Teaching Holistic Business Transformation in Technology Blogs by SAP
- Plan your Conversion to SAP Datasphere with BW Bridge, or SAP BW/4HANA in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 40 | |
| 25 | |
| 17 | |
| 13 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |