
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP Business Technology Platform – software lifecy...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
07-08-2021
1:39 PM
Note – this and associated blogs are result of collaboration between swiftc.
Purpose of this blog is to present several possibilities (approaches, solutions, services) for handling software lifecycle management (will use acronym SwLM every now and then) aspects of solutions built on the SAP Business Technology Platform (SAP BTP). Our focus has been on SAP BTP capabilities in the SaaS and PaaS portfolio though some elements would also be applicable to hybrid scenarios where some components of the solution are deployed by customer on infrastructure of their choice. While we constrained ourselves to capabilities within SaaS and PaaS portfolio, we do refer to key considerations where hybrid scenarios are involved.
In the good tradition of blog series developed by SAP HANA Database & Analytics, Cross Solution Management team, we wanted to present a sample end-to-end use case including all relevant components of such case in as much detail as necessary.
In this blog we describe a working scenario where several capabilities are used to deliver a reasonable software lifecycle management approach. Why “reasonable”? Because we cannot really call it best or even common practice nor a prescribed recipe from SAP. We hope this will become clearer as we present our case.
Our first task was to look at the approaches and tools available in the broadly defined software lifecycle space, then try to map which of them could (and sometimes should) be used in what situation. This of course is to some degree subjective mapping as we grappled with the following major dilemma: should we try to find a solution that - in a simplest possible way - provides largest possible coverage, or should we pick tools individually based on closest integration with a particular scenario? We decided to try and land somewhere in the middle.
So let’s get on with it.
Our inspiration came from a solution our colleagues built as documented in the blog SAP BTP Data & Analytics Showcase - Integration. We modified it slightly to better suit the story we want to tell.
In essence, the solution spreads across following data lifecycle phases:
Several artefacts in various phases will need to be developed and deployed in a coordinated manner – this is the essence of our DevOps story.
In our case, the above is mapped to selected SAP Business Technology Platform capabilities and within each of them, we need to develop/configure required artefacts as follows:
The overall solution stack that is in our focus today is presented in the graphics below:
Now we know what we need to develop and manage, so the last thing we need is decide what kind of toolset we need to build and promote through the landscape.
In building our DevOps approach we focused on following key elements:
Before we proceed, it is worthwhile talking briefly about the Project “Piper” as per documentation:
“SAP implements tooling for continuous delivery in project "Piper". The goal of project "Piper" is to substantially ease setting up continuous delivery in your project using SAP technologies.”
One of the accelerators delivered with the project is “A set of Docker images to setup a CI/CD environment […]” and today, these “[…] images are optimized for use with project "Piper" on Jenkins”. Therefore, in our set-up, we have used Jenkins as the automation tool with Project “Piper” enhancements. It should be noted that SAP is working on revamp of the Project “Piper” with one of the objectives to make it independent of Jenkins and available to be combined with your automation tool of choice (like Azure DevOps Pipelines, Bamboo and others). Therefore, if you are interested in using Project “Piper” with your CI/CD tool of choice, make sure you check the latest information on the documentation page. If you would like to try it yourself, refer to How to Use Project “Piper” Docker Images for CI/CD with Azure DevOps.
Based on our needs, we have mapped the artefacts we need to build (and promote through the landscape) and the tools we can use to help us do that. In fact, we have also looked at artefacts beyond our immediate needs, so you will find below some that are not used in our scenario, but might be relevant for you. However, please note the list below is not exhaustive when it comes to types of artefacts you might be dealing with. We have highlighted in green the areas which are used in our scenario and demo.
Remember – this is snapshot in time and with ever-changing capabilities of SAP BTP it is worth to check the current state before making project decisions.
In the action column, we identify the following only:
Deploy – includes deployment of a package to target solution; import also considered where relevant.
(1) Artefacts created in the applications can be exported to archives/files and loaded to SCM, but there is no direct interaction between development tool and SCM.
(2) Currently, promotion of artefacts for SAC and DWC (modelling services), is based on Analytic Content Network (ACN) and there are no APIs to interact with that process from outside. Internal PoC is being carried out so stay tuned for this to change (no timelines or commitments given).
(3) As of Aug'21 release, you can configure CI/CD jobs for the development of custom Cloud Integration content. This allows you to pull the latest changes from your Git repository, package and upload to SAP Integration Suite, and Test and deploy integration flows.
(4) Refer to blog Transportion and CI/CD with SAP Data Intelligence for more details on various artefacts in SAP Data Intelligence and their relation to CI/CD processes.
You may also want to refer to the official documentation SAP Solutions for Continuous Integration and Delivery which explains current SAP’s position on CI/CD.
There is one notable omission from the matrix above – SAP Cloud ALM (Application Lifecycle Management). We considered using it as the coordinator for our deployment activities for various artefacts across all layers of the solution. Unfortunately, the capabilities required for such coordination are not available today, but are firmly on the roadmap. We may revisit this blog when SAP Cloud ALM is ready.
So, how did we decide to go about deployment coordination? Let’s look at interactions between our selected tool stack – in the matrix below, read column-wise to see how initiator tool can interact with other tool (we have highlighted in green areas which are used in our scenario and demo):
Just a reminder that we set ourselves specific scope constraints – that is to use SaaS/PaaS offering only. In hybrid deployment, you should also consider CTS+ and Change Request Management as per Interplay of SAP Cloud Platform Transport Management, CTS+ and ChaRM in hybrid landscapes blog.
Based on the solution scope and requirements, further overlayed with DevOps tools, capabilities and integration, we have arrived at the following DevOps architecture:
It should be noted that while we depict SAP Continuous Integration & Delivery in the diagram, we are not using it in our scenario. It would have been our choice over 3rd party CI/CD tool like Jenkins, if it offered integration with all components of our solution stack. At the time of writing, SAP Continuous Integration & Delivery did not offer integration with SAP Data Intelligence.
Therefore, our choice has landed with CI/CD tool (Jenkins in our case) as the main DevOps pipeline coordinator and executor as we have already deployed and used it for Project “Piper”.
Please note that in our demo we only used two environments – DEVelopment (DEV) and PRoDuction (PRD) - and our lifecycle workflows are tailored for such simplified landscape. Adjustments would be needed for landscapes with other environments (for example Test). With 2-environment set-up, we use the environments as follows:
There are following pipelines and steps configured within our DevOps approach:
It is important to recognise that DevOps pipeline can (and should) also be used to perform tests – technical and/or functional. While we check success of MTA deployment above, we do not check whether the function it (the MTA packaged app) provides actually works. Test could be as simple as checking return code from an API call. Such tests are not included in our scenario, but worth considering.
Diagram below illustrates the DevOps flows:
You might ask - what fundamental differences (if any) would we have in 3-environment landscape? Very good question. The difference would be primarily visible in the scenario with CI/CD pipeline and SAP CTMS. The How to integrate SAP Cloud Platform Transport Management into your CI/CD pipeline blog shows fully fledged integration between CI/CD pipeline and SAP CTMS (based on Project “Piper”). The main difference in a landscape with additional (1 or more) pre-production environment (like TeST), would be that CTMS is taking over from CI/CD pipeline from Test environment onwards. Consider this slightly altered diagram reflecting such a change:
Also, in the case of pipeline without integration with CTMS, we can choose to propagate to TeST and PRoDuction in the same pipeline or in separate ones. We could use TeST step to prepare package and place it in nominated folder in CI/CD server and then get PRoDuction step to pick up prepared solution package(s) and deploy into PRoDuction.
Back to our case, the above flows are executed within independent pipelines created for each solution artefact (or development project). But how can we coordinate these flows? As mentioned earlier, relevant capabilities of SAP Cloud ALM are on the roadmap but not ready for us yet, so we had to look for alternatives.
We decided to use what we already have in our toolset and used CI/CD (Jenkins in our case) to build coordination pipeline. There are two basic types of coordination pipeline that we can consider – refer to the diagram below:
Parallel execution pipeline is suitable for scenarios where we want the deployments to happen in parallel and where there is no cross-dependency between deployed artefacts. In this case, failure of any of the subordinate pipelines does not affect deployment of parallel one.
Sequential execution is suitable for scenarios where there is direct dependency between individual pipelines (or rather artefacts within). In this case, execution of any subsequent step is dependent on the result of directly preceding step execution.
In our case we have decided to use parallel execution approach. This is because in our example solution flow, the change we are deploying involves modification of data model – namely, we simulate a new field added in the calculation view and associated OData service. This change has a following impact across the solution:
In this scenario, the biggest risks of causing disruption to the flow while introducing the change are:
Also, we are using SAP Cloud Transport Management service (CTMS) in such a way that deployment to PRD is not controlled by the CI/CD pipeline, which only places the package in import queue of the CTMS. In turn, CTMS controls the deployment to the PRD tenant/system. Therefore, deployment of DI package should not proceed until CTMS completes import to HC PRD tenant.
Side note – we would ideally try to develop a solution in such a way that either the two versions of deployment can co-exist and reference a compatible version from another layer or abstract the delta change into separate set of objects. But that comes with own challenges and potentially sub-optimal deployments.
So, let’s try to protect ourselves from a scenario where deployment is not fully successful at any stage of the way. We will do it by controlling deployment as follows:
The video below provides a complete walkthrough the example solution covering following sections (since the overall video is 52 minutes long, provided jump links to go straight to particular section):
You might have noticed we also showed how SAP Alert Notification service for SAP BTP can be utilised to collect information about some deployment steps (MTA deployment, CTMS event) and turn it into a notification using your preferred channel (we used Microsoft Teams in our case).
There is of course quite a bit of further detail that happens behind the scenes. To keep things tidy we decided to describe them in separate blogs which all form parts of this series:
And remember, our story is just one of many – the intent was to show what needs to be considered and what are the current capabilities in that space. These capabilities will continuously evolve thus it is imperative that you review the capabilities before deciding on your own DevOps approach and toolset.
---------
Notable materials utilised in preparation of this blog:
Introduction
Purpose of this blog is to present several possibilities (approaches, solutions, services) for handling software lifecycle management (will use acronym SwLM every now and then) aspects of solutions built on the SAP Business Technology Platform (SAP BTP). Our focus has been on SAP BTP capabilities in the SaaS and PaaS portfolio though some elements would also be applicable to hybrid scenarios where some components of the solution are deployed by customer on infrastructure of their choice. While we constrained ourselves to capabilities within SaaS and PaaS portfolio, we do refer to key considerations where hybrid scenarios are involved.
In the good tradition of blog series developed by SAP HANA Database & Analytics, Cross Solution Management team, we wanted to present a sample end-to-end use case including all relevant components of such case in as much detail as necessary.
In this blog we describe a working scenario where several capabilities are used to deliver a reasonable software lifecycle management approach. Why “reasonable”? Because we cannot really call it best or even common practice nor a prescribed recipe from SAP. We hope this will become clearer as we present our case.
Our first task was to look at the approaches and tools available in the broadly defined software lifecycle space, then try to map which of them could (and sometimes should) be used in what situation. This of course is to some degree subjective mapping as we grappled with the following major dilemma: should we try to find a solution that - in a simplest possible way - provides largest possible coverage, or should we pick tools individually based on closest integration with a particular scenario? We decided to try and land somewhere in the middle.
So let’s get on with it.
What is our problem/requirement?
Our inspiration came from a solution our colleagues built as documented in the blog SAP BTP Data & Analytics Showcase - Integration. We modified it slightly to better suit the story we want to tell.
In essence, the solution spreads across following data lifecycle phases:
- Ingestion: sourcing data from its origin(s)
- Transformation: transforming data (including quality improvement) to suit the end objective
- Data staging and repository: storing intermediary (staging) and final data products
- Publishing/consumption: making data available or publishing it to consumers – users via analytical dashboards and other systems via APIs
Several artefacts in various phases will need to be developed and deployed in a coordinated manner – this is the essence of our DevOps story.
In our case, the above is mapped to selected SAP Business Technology Platform capabilities and within each of them, we need to develop/configure required artefacts as follows:
- Ingestion & Transformation: SAP Data Intelligence Cloud (DI) >> data processing pipelines (graphs)
- Data staging and repository: SAP HANA Cloud (HC) >> tables and views delivered via Cloud Application Programming (CAP) model project
- Publishing/consumption:
- SAP Analytics Cloud (SAC) >> data models, stories, dashboards
- SAP BTP, Cloud Foundry (CF) >> OData services delivered via Cloud Application Programming (CAP) model project
The overall solution stack that is in our focus today is presented in the graphics below:

Solution stack
Now we know what we need to develop and manage, so the last thing we need is decide what kind of toolset we need to build and promote through the landscape.
How do we go about it?
In building our DevOps approach we focused on following key elements:
- Source Code Management system (SCM): Git is our tool of choice.
- Build and deployment automation: we have focused on two options – Project “Piper” and SAP Continuous Integration and Delivery.
- Delivery automation: SAP Cloud Transport Management service (CTMS)
Before we proceed, it is worthwhile talking briefly about the Project “Piper” as per documentation:
“SAP implements tooling for continuous delivery in project "Piper". The goal of project "Piper" is to substantially ease setting up continuous delivery in your project using SAP technologies.”
One of the accelerators delivered with the project is “A set of Docker images to setup a CI/CD environment […]” and today, these “[…] images are optimized for use with project "Piper" on Jenkins”. Therefore, in our set-up, we have used Jenkins as the automation tool with Project “Piper” enhancements. It should be noted that SAP is working on revamp of the Project “Piper” with one of the objectives to make it independent of Jenkins and available to be combined with your automation tool of choice (like Azure DevOps Pipelines, Bamboo and others). Therefore, if you are interested in using Project “Piper” with your CI/CD tool of choice, make sure you check the latest information on the documentation page. If you would like to try it yourself, refer to How to Use Project “Piper” Docker Images for CI/CD with Azure DevOps.
Based on our needs, we have mapped the artefacts we need to build (and promote through the landscape) and the tools we can use to help us do that. In fact, we have also looked at artefacts beyond our immediate needs, so you will find below some that are not used in our scenario, but might be relevant for you. However, please note the list below is not exhaustive when it comes to types of artefacts you might be dealing with. We have highlighted in green the areas which are used in our scenario and demo.
Remember – this is snapshot in time and with ever-changing capabilities of SAP BTP it is worth to check the current state before making project decisions.
In the action column, we identify the following only:
- Build – includes preparation of a deployable package; export also considered where relevant.
Deploy – includes deployment of a package to target solution; import also considered where relevant.
| Solution | Artefact(s) | Git | Action | Project “Piper” | SAP Continuous Integration and Delivery | SAP Cloud Transport Management service (CTMS) |
| SAP BTP, Cloud Foundry apps | Fiori, services - packaged in MTA using CAP model | Yes | Build | Yes | Yes (CAP and SAP UI5) | No |
| Deploy | Yes | Yes (CAP and SAP UI5) | Yes (CAP and SAP UI5) | |||
| SAP HANA Cloud | Database artefacts - packaged in MTA using CAP model | Yes | Build | Yes | Yes (Through HDI Container in CAP) | No |
| Deploy | Yes | Yes (Through HDI Container in CAP) | Yes (Through HDI Container in CAP) | |||
| SAP Data Intelligence | Solutions (graphs, operators, etc.) (4) | Yes | Build | Yes | No | No |
| Deploy | Yes | No | No | |||
| SAP Analytics Cloud | Data models in Analytics Content Network (ACN) | No (1) | Build | No (2) | No (2) | No (2) |
| Deploy | No (2) | No (2) | No (2) | |||
| Integration Suite | Cloud Integration content | Yes | Build | Yes | Yes (3) | Only export of content package to CTMS |
| Deploy | Yes | Yes (3) | Yes | |||
| SAP Data Warehouse Cloud - embedded HANA Cloud service | Same as SAP HANA Cloud | Yes | Build | Yes | Yes (Through HDI Container in CAP) | No |
| Deploy | Yes | Yes (Through HDI Container in CAP) | Yes (Through HDI Container in CAP) | |||
| SAP Data Warehouse Cloud - modeling services | Data models in Analytics Content Network (ACN) | No (1) | Build | No (2) | No (2) | No |
| Deploy | No (2) | No (2) | No |
(1) Artefacts created in the applications can be exported to archives/files and loaded to SCM, but there is no direct interaction between development tool and SCM.
(2) Currently, promotion of artefacts for SAC and DWC (modelling services), is based on Analytic Content Network (ACN) and there are no APIs to interact with that process from outside. Internal PoC is being carried out so stay tuned for this to change (no timelines or commitments given).
(3) As of Aug'21 release, you can configure CI/CD jobs for the development of custom Cloud Integration content. This allows you to pull the latest changes from your Git repository, package and upload to SAP Integration Suite, and Test and deploy integration flows.
(4) Refer to blog Transportion and CI/CD with SAP Data Intelligence for more details on various artefacts in SAP Data Intelligence and their relation to CI/CD processes.
You may also want to refer to the official documentation SAP Solutions for Continuous Integration and Delivery which explains current SAP’s position on CI/CD.
There is one notable omission from the matrix above – SAP Cloud ALM (Application Lifecycle Management). We considered using it as the coordinator for our deployment activities for various artefacts across all layers of the solution. Unfortunately, the capabilities required for such coordination are not available today, but are firmly on the roadmap. We may revisit this blog when SAP Cloud ALM is ready.
So, how did we decide to go about deployment coordination? Let’s look at interactions between our selected tool stack – in the matrix below, read column-wise to see how initiator tool can interact with other tool (we have highlighted in green areas which are used in our scenario and demo):
caller > callee V | Git (as SCM) | Project “Piper” | SAP Continuous Integration and Delivery | SAP Cloud Transport Management service |
| Git (as SCM) | Automation pipeline can pull content from Git into the pipeline | SAP Continuous Integration and Delivery can pull content from Git into the pipeline | - | |
| Project “Piper” | Git can trigger automation pipeline via webhook | No | - | |
| SAP Continuous Integration and Delivery | Git can trigger automation pipeline via webhook | No | - | |
| SAP Cloud Transport Management service | No direct integration | Automation pipeline can call CTMS API (upload, import) | Automation pipeline can call CTMS API (upload, import) |
Just a reminder that we set ourselves specific scope constraints – that is to use SaaS/PaaS offering only. In hybrid deployment, you should also consider CTS+ and Change Request Management as per Interplay of SAP Cloud Platform Transport Management, CTS+ and ChaRM in hybrid landscapes blog.
What did we get to?
Based on the solution scope and requirements, further overlayed with DevOps tools, capabilities and integration, we have arrived at the following DevOps architecture:

Tooling stack
It should be noted that while we depict SAP Continuous Integration & Delivery in the diagram, we are not using it in our scenario. It would have been our choice over 3rd party CI/CD tool like Jenkins, if it offered integration with all components of our solution stack. At the time of writing, SAP Continuous Integration & Delivery did not offer integration with SAP Data Intelligence.
Therefore, our choice has landed with CI/CD tool (Jenkins in our case) as the main DevOps pipeline coordinator and executor as we have already deployed and used it for Project “Piper”.
Please note that in our demo we only used two environments – DEVelopment (DEV) and PRoDuction (PRD) - and our lifecycle workflows are tailored for such simplified landscape. Adjustments would be needed for landscapes with other environments (for example Test). With 2-environment set-up, we use the environments as follows:
- DEVelopment:
- perform development or modelling,
- perform initial deployment.
- PRoDuction:
- perform deployment
- either directly via CI/CD pipeline, or
- indirectly, via Transport Management service.
- perform deployment
There are following pipelines and steps configured within our DevOps approach:
- Flow for SAP Data Intelligence (DI)
- Modeling of the DI graph is performed in DI DEV tenant using DI modelling tools.
- Visual Studio Code for SAP Data Intelligence embedded in DI DEV tenant is used to integrate selected DI model content with Git repository.
- Push/Commit to Git repository triggers a webhook to CI/CD pipeline DI Build & Deploy.
- DI Build & Deploy pipeline uses a custom build Docker image (with Jenkins and DI command line tool) to perform following steps:
- package Git repository content into DI solution file,
- import DI solution file to DI PRD tenant.
- Flow for SAP HANA Cloud and SAP BTP, Cloud Foundry
- Development of the application artefacts is performed in SAP Business Application Studio (BAS) using Cloud Application Programming model.
- BAS is integrated with Git repository for source code management.
- Push/Commit to Git repository triggers a webhook to associated CI/CD pipeline HC/CF build & deploy + send to CTMS.
- HC/CF build & deploy + send to CTMS pipeline uses Project “Piper” Docker image to perform following steps (all steps below are executed sequentially - only when previous step completed successfully):
- build MTA package,
- deploy MTA package to HC/CF DEV tenant,
- upload MTA package to SAP Cloud Transport Management service (CTMS),
- attach uploaded package to DEV node,
- export uploaded package from DEV node – this results in package being queued for import in the PRD node.
Note that technically, it would also be possible to trigger import into PRD from the pipeline. However, we decided to keep the control of final import into PRD outside of the automation pipeline.
It is important to recognise that DevOps pipeline can (and should) also be used to perform tests – technical and/or functional. While we check success of MTA deployment above, we do not check whether the function it (the MTA packaged app) provides actually works. Test could be as simple as checking return code from an API call. Such tests are not included in our scenario, but worth considering.
Diagram below illustrates the DevOps flows:
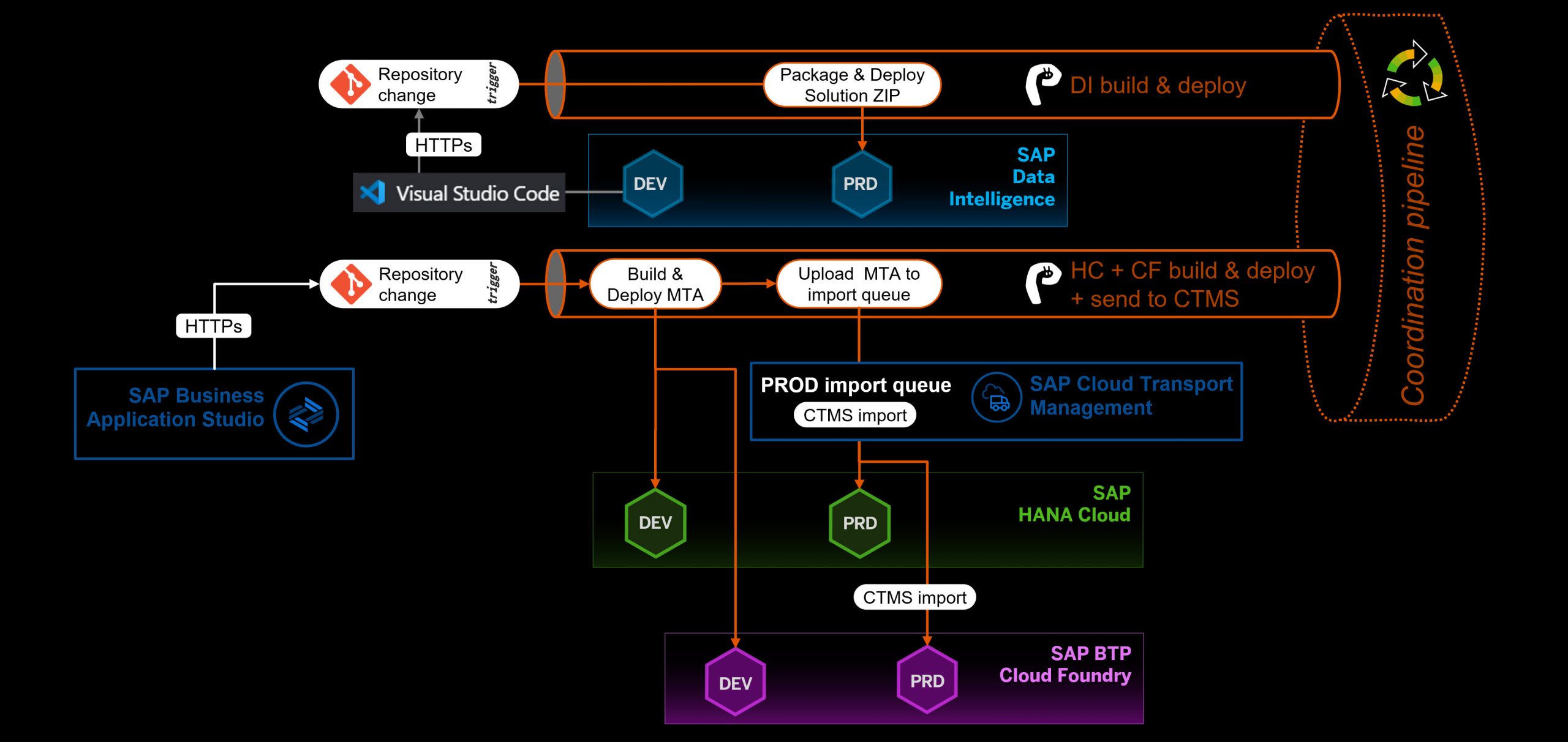
Automation flow
You might ask - what fundamental differences (if any) would we have in 3-environment landscape? Very good question. The difference would be primarily visible in the scenario with CI/CD pipeline and SAP CTMS. The How to integrate SAP Cloud Platform Transport Management into your CI/CD pipeline blog shows fully fledged integration between CI/CD pipeline and SAP CTMS (based on Project “Piper”). The main difference in a landscape with additional (1 or more) pre-production environment (like TeST), would be that CTMS is taking over from CI/CD pipeline from Test environment onwards. Consider this slightly altered diagram reflecting such a change:

Automation flow with 3 environments
Also, in the case of pipeline without integration with CTMS, we can choose to propagate to TeST and PRoDuction in the same pipeline or in separate ones. We could use TeST step to prepare package and place it in nominated folder in CI/CD server and then get PRoDuction step to pick up prepared solution package(s) and deploy into PRoDuction.
Back to our case, the above flows are executed within independent pipelines created for each solution artefact (or development project). But how can we coordinate these flows? As mentioned earlier, relevant capabilities of SAP Cloud ALM are on the roadmap but not ready for us yet, so we had to look for alternatives.
We decided to use what we already have in our toolset and used CI/CD (Jenkins in our case) to build coordination pipeline. There are two basic types of coordination pipeline that we can consider – refer to the diagram below:

Coordination pipeline options
Parallel execution pipeline is suitable for scenarios where we want the deployments to happen in parallel and where there is no cross-dependency between deployed artefacts. In this case, failure of any of the subordinate pipelines does not affect deployment of parallel one.
Sequential execution is suitable for scenarios where there is direct dependency between individual pipelines (or rather artefacts within). In this case, execution of any subsequent step is dependent on the result of directly preceding step execution.
In our case we have decided to use parallel execution approach. This is because in our example solution flow, the change we are deploying involves modification of data model – namely, we simulate a new field added in the calculation view and associated OData service. This change has a following impact across the solution:
- SAP Data Intelligence (DI) graph must be amended to provision data required for the additional field,
- That field must be added to data model in SAP HANA Cloud (HC) – table(s) and views,
- Data consumption OData on Cloud Foundry runtime (CF) must be enhanced to expose the new field,
- SAP Analytics Cloud (SAC) model and reports must be amended to consume additional field.
It should be noted that SAP Analytics Cloud is not included in our automation demo – just mentioned here for completeness of the impact.
In this scenario, the biggest risks of causing disruption to the flow while introducing the change are:
- when SAP DI tries to push new data field to SAP HANA Cloud and the field isn’t there,
- when SAC report expects field which is not available in source model,
- when external consumers expects OData to contain the field while it is not available in source model.
Also, we are using SAP Cloud Transport Management service (CTMS) in such a way that deployment to PRD is not controlled by the CI/CD pipeline, which only places the package in import queue of the CTMS. In turn, CTMS controls the deployment to the PRD tenant/system. Therefore, deployment of DI package should not proceed until CTMS completes import to HC PRD tenant.
Side note – we would ideally try to develop a solution in such a way that either the two versions of deployment can co-exist and reference a compatible version from another layer or abstract the delta change into separate set of objects. But that comes with own challenges and potentially sub-optimal deployments.
So, let’s try to protect ourselves from a scenario where deployment is not fully successful at any stage of the way. We will do it by controlling deployment as follows:
- Phase #1 - execute CI/CD pipelines in parallel:
- Deployment of SAP HANA Cloud (HC) and OData (Cloud Foundry, CF) artefacts to ensure that data model is ready:
- CI/CD pipeline delivers the packages to the import buffer of HC/CF PRD tenant
- Deployment of SAP Data Intelligence (DI) artefacts:
- CI/CD pipeline deploys the packages to DI PRD tenant, but the DI graphs remain un-scheduled.
- Deployment of SAP HANA Cloud (HC) and OData (Cloud Foundry, CF) artefacts to ensure that data model is ready:
- Phase #2 - execute CTMS import to HC and CF PRD tenants.
- Phase #3 - execute DI graph to provision data required for updated data model.
- Phase #4 - deployment of SAP Analytics Cloud models
This is done manually using export/import or content exchange via Analytical Content Network (ACN).
The video below provides a complete walkthrough the example solution covering following sections (since the overall video is 52 minutes long, provided jump links to go straight to particular section):
- Introduction – the scenario and context
- Design time artefacts – what they look like and how they are managed (direct jump link)
- Build pipelines – how they are configured (direct jump link)
- SAP Cloud Transport Management – key set-up elements (direct jump link)
- First deployment – step-by-step (direct jump link)
- Implementation of change across selected artefacts – the flow (direct jump link)
- Takeaways
You might have noticed we also showed how SAP Alert Notification service for SAP BTP can be utilised to collect information about some deployment steps (MTA deployment, CTMS event) and turn it into a notification using your preferred channel (we used Microsoft Teams in our case).
There is of course quite a bit of further detail that happens behind the scenes. To keep things tidy we decided to describe them in separate blogs which all form parts of this series:
- Blog Integration aspects in the CI/CD approach
This blog is divided into sections dealing with integration of:
- development tools and source code management, specifically:
- SAP Business Application Studio and GitHub
- Visual Studio Code for SAP Data Intelligence and GitHub
- source code management and automation pipeline, specifically:
- GitHub and Project “Piper”
- automation pipeline and delivery management, specifically:
- Project “Piper” and SAP Cloud Transport Management
- automation pipeline and end point, specifically:
- Project “Piper” and SAP HANA Cloud or SAP BTP, Cloud Foundry runtime
- Project “Piper” and SAP Data Intelligence Cloud
- delivery management and end point, specifically:
- SAP Cloud Transport Management and SAP HANA Cloud or SAP BTP, Cloud Foundry runtime
- development tools and source code management, specifically:
The blog also features detailed videos documenting selected integration aspects.
- Blog Project “Piper” – Jenkins on Docker
This blog describes how we built our custom Jenkins build server using Project "Piper" enhanced with SAP Data Intelligence CI/CD integration components. - Blog Table lifecycle (aka Schema Evolution) in SAP HANA (Cloud) with .hdbmigrationtable
This blog discusses ways in which lifecycle of changes to data model (schema) can be managed with new CDS artefact.
And remember, our story is just one of many – the intent was to show what needs to be considered and what are the current capabilities in that space. These capabilities will continuously evolve thus it is imperative that you review the capabilities before deciding on your own DevOps approach and toolset.
---------
Notable materials utilised in preparation of this blog:
- SAP Discovery Center:
- SAP Continuous Integration & Delivery
- SAP Cloud Transport Management
- SAP Business Application Studio
- SAP Cloud ALM
- SAP Alert Notification Service for SAP BTP
- Other content:
- Continuous Integration and Delivery by SAP, especially:
- SAP Solutions for Continuous Integration and Delivery
- Continuous Integration and Delivery Best Practices Guide
- Best Practices for SAP BTP - Delivering Applications
- Project “Piper”
- Integrate SAP Cloud Transport Management Into Your CI/CD Pipeline
- Git source control in SAP BAS
- Visual Studio Code for SAP Data Intelligence
- Git Integration and CI/CD Process with SAP Data Intelligence
- SAP API Business Hub – API for SAP Cloud Transport Management
- DevOps Community
- openSAP: Efficient DevOps with SAP
- DevOps with SAP Business Technology Platform | Hands-on Video Tutorials
- Continuous Integration and Delivery by SAP, especially:
- Roadmap information:
- SAP Continuous Integration & Delivery
- SAP Cloud Transport Management
- SAP Business Application Studio
- SAP Cloud ALM
- SAP Alert Notification Service for SAP BTP
- Developer’s guides:
- Create an SAP Cloud Application Programming Model Project for SAP HANA Cloud
- Build Your First OData-Based Backend Service
- Blogs:
- How to integrate SAP Cloud Platform Transport Management into your CI/CD pipeline by boris.zarske
- Interplay of SAP Cloud Platform Transport Management, CTS+ and ChaRM in hybrid landscapes by harald.stevens
- Working with Github in SAP Business Application Studio by showkath.naseem
- SAP Data Intelligence: Git Workflow and CI/CD Process by christian.sengstock
- Transportion and CI/CD with SAP Data Intelligence by thorsten.hapke
- Achieve Continuous Integration and Delivery using DevOps services in SAP Cloud Platform and Transport Portal sites using Transport Management Service on SAP Cloud Platform by muralidaran.shanmugham2
- SAP Managed Tags:
- SAP Data Intelligence,
- SAP HANA Cloud,
- DevOps,
- SAP Cloud Transport Management,
- SAP Business Technology Platform
Labels:
2 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
275 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
329 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
407 -
Workload Fluctuations
1
Related Content
- SAP HANA Cloud Vector Engine: Quick FAQ Reference in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform - Blog 7 in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP BTP - Blog 4 Interview in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
- Top Picks: Innovations Highlights from SAP Business Technology Platform (Q1/2024) in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 10 | |
| 7 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 4 |