
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- 【SAP HANA Cloud】テキストマイニングの活用方法
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
07-02-2021
10:55 AM
2021年4月、SAPはSAP HANA Cloud用の新しいテキストマイニング機能を発表しました。
以下からその概要や方法を説明します。
※現時点のHANA Cloudでテキストマイニングを行う場合、日本語は対応できません。
テキストマイニング(Text Mining)とは
文章を対象に行うデータマイニングの1種で、入力された大量のテキストデータを分析し、新たな情報やインサイトを取得する手法のことです。
〇なぜ必要なのか?
近年テクノロジーの発展によって、お客様からの問い合わせ文・アンケートの自由記入文などの企業内に蓄積されたデータやソーシャルメディア上に大量のテキストデータが発生し、情報量は膨大なものとなっています。
そのテキストデータから有益な情報を取り出すことや取り出した情報から分析・予測することは容易ではありません。その結果、多くの企業で「有益な情報を持っているのに活用できていない」という状況に陥っています。
SAP HANA Cloudの新機能

SAP HANA Cloudの新機能は以下です。
用語頻度分析:高頻度で登場する重要な用語を特定します。
テキスト分類機能:関連するドキュメントや単語を取得します。
また、これらの機能がPython機械学習クライアント2.8でもアクセスできるようになりました。(Pythonでの例は後述します。)
ここからは「これらの機能をどう実行するのか」簡単な例で確認していきます。
※テキストマイニング機能は、予測分析ライブラリ(PAL)の一部です。そのためPALの関数がいくつか登場しますが、気にせずそのままコピーしてください。詳しい情報を知りたい方はこちらをご覧ください。
※また、TF-IDF値を元にテキストマイニングを実行します。TF-IDF値の基礎情報はこちらをご覧ください。
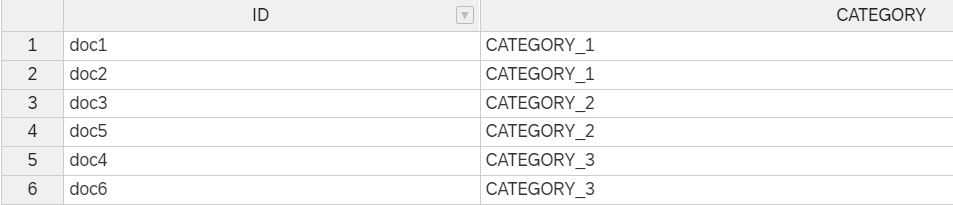
(1)SQLを使用して、ID(doc)・コンテンツ(term)・カテゴリー(category)のテーブルを作成します。
create column table PAL_TFIDF_DATA_TAB (
"ID" nvarchar(1000),
"CONTENT" nvarchar(1000),
"CATEGORY" nvarchar(1000)
);
INSERT INTO PAL_TFIDF_DATA_TAB VALUES('doc1','term1 term2 term2 term3 term3 term3','CATEGORY_1');
INSERT INTO PAL_TFIDF_DATA_TAB VALUES('doc2','term2 term3 term3 term4 term4 term4','CATEGORY_1');
INSERT INTO PAL_TFIDF_DATA_TAB VALUES('doc3','term3 term4 term4 term5 term5 term5','CATEGORY_2');
INSERT INTO PAL_TFIDF_DATA_TAB VALUES('doc5','term3 term4 term4 term5 term5 term5 term5 term5 term5','CATEGORY_2');
INSERT INTO PAL_TFIDF_DATA_TAB VALUES('doc4','term4 term6','CATEGORY_3');
INSERT INTO PAL_TFIDF_DATA_TAB VALUES('doc6','term4 term6 term6 term6','CATEGORY_3');(2)以下のSQLコマンド(call)を使用して、このテーブルでPAL_TF_ANALYSIS関数を呼び出します。
call _SYS_AFL.PAL_TF_ANALYSIS(
PAL_TFIDF_DATA_TAB,
PARAMETERS,
PAL_TM_TERM_TAB,
PAL_TM_DOC_TERM_FREQ_TAB,
PAL_TM_CATE_TAB
);PAL_TF_ANALYSISは3つのテーブルを出力します。
- PAL_TM_TERM_TAB:各単語のTF-IDF値に関する指標や詳細が表示されます。

- PAL_TM_DOC_TERM_FREQ_TAB:各ドキュメント内の各用語の頻度を一覧で表示します。

- PAL_TM_CATE_TABは、各ドキュメントが属するカテゴリーを一覧で表示します。
作成されたTF-IDFモデルによって、過去のドキュメントとの類似性に基づき、
これから追加する新しいドキュメントがどのカテゴリーに属するのかを分析してくれます。
(3)カテゴリーが分類されていない2つのドキュメントを追加します。
create column table PAL_TM_PRED_TAB (
"ID" nvarchar(1000),
"CONTENT" nvarchar(1000)
);
INSERT INTO PAL_TM_PRED_TAB VALUES('doc10','term2 term2 term3 term3');
INSERT INTO PAL_TM_PRED_TAB VALUES('doc11','term4 term4 term4 term5');
doc10,11には最終列のCategoryが明記されていません。そこで、、、
(4)PAL_TEXTCLASSIFICATION関数を使用してカテゴリーを予測します。
call _SYS_AFL.PAL_TEXTCLASSIFICATION(
PAL_TM_TERM_TAB,
PAL_TM_DOC_TERM_FREQ_TAB,
PAL_TM_CATE_TAB,
PAL_TM_PRED_TAB,
PARAMETERS, ?, ?);その結果、下記2つのアウトプットが表示されます。


これは、doc10,11に含まれる単語の種類・出現頻度などから類似するID(doc)を見つけ、カテゴリーの分類を実行したということです。
※ざっくりとしたイメージ
doc10を分析する→結果:doc10≒doc2
doc2はCATEGORY_1に分類されている→doc10:CATEGORY_1
提供価値
この機能はどんな価値をもたらすのかを、簡単にまとめておきます。
- 開発者
- Python(後述)・SQLを用い、SAP HANA Cloudのインスタンスに接続するだけで、あらゆるデータタイプを処理できる関数にアクセスし、簡単に分析ができます。テキストマイニングのために、ソースデータを加工する必要がありません。
- ビジネスユーザー
- 今まで見落としていたテキストデータから得られるインサイトを、提案・仮説に組み込むことができ、より質の高いアウトプットを出すことができます。
- また、優秀な社員が成功している要因は経験則も多く定性的になりがちで、他の社員へ共有しづらいことも多いかと思います。テキストマイニングを利用すれば、機械的にその分類や分析ができ、他の社員が簡単に確認することができます。
Pythonによる活用例
ここでは「実際にどのような新しいインサイトを得られるのか」具体例を紹介します。
ぜひ一緒にやってみてください!
今回はPython・Jupyter notebookを使用し、米国の自動車会社に関連するクレームのデータセットに対してテキストマイニングを実行します。
※Python/Jupyter notebook/HANA Cloudの初期設定が終わっていなければ、こちらをご確認ください。
1.Pythonライブラリをインポートする
今回は「pandas」を使用して、データ分析を行います。
またhana_mlを利用して、後ほど使用する関数もインポートします。
import pandas as pd
from datetime import date, datetime, timedelta
import os
from hdbcli import dbapi
from hana_ml import dataframe
from hana_ml.dataframe import create_dataframe_from_pandas
from hana_ml.algorithms.pal.partition import train_test_val_split
from hana_ml.text.tm import tf_analysis
from hana_ml.text.tm import get_related_doc, get_related_term, get_relevant_doc, get_relevant_term, get_suggested_term, text_classification
pd.set_option('display.max_colwidth', None)
pd.set_option("display.colheader_justify","left")2.HANA Cloudの接続を定義します。
HANA Cloudのインスタンスにアクセスするユーザーと取得権限を定義します。
これにより、ローカルのJupyter notebookとHANA Cloudのインスタンスを繋げることができます。
# Instantiate connection object
conn = dataframe.ConnectionContext(address = 'XXXX.hana.canary-eu10.hanacloud.ondemand.com',
port = 443,
user = 'XXXX',
password = 'XXXXX',
encrypt = 'true',
sslValidateCertificate = 'false'
)
# Send basic SELECT statement and display the result
sql = 'SELECT 12345 FROM DUMMY'
df_remote = conn.sql(sql)
print(df_remote.collect())
# Set up TEXTANALYSIS User, Add rights to execute PAL
# cursor = conn.connection.cursor()
# cursor.execute('CREATE USER TEXTANALYSIS Password "Textan123" SET USERGROUP DEFAULT;')
# cursor.execute('ALTER USER TEXTANALYSIS DISABLE PASSWORD LIFETIME;')
# cursor.execute('GRANT "AFL__SYS_AFL_AFLPAL_EXECUTE_WITH_GRANT_OPTION" TO TEXTANALYSIS')正常に作動すると、「12345」が返されます。
この接続を定義すると、HANA Cloud上のサンプルデータ(自動車会社のクレームのデータ)を選択できるようになります。
3.データをフィルタリングする
サンプルデータを使用する範囲でフィルタリングします。
今回は下記に従って、フィルタリングを行いました。
- メーカー:FORD(アメリカの大手自動車会社)
- データセットの分割:トーレーニング・検証・テスト(train/valid/test)
- 内容:英語のテキスト
df_tm_source = dataframe.DataFrame(conn,'select "CONTENT", "CATEGORY", "MFR_NAME", "MAKETXT","MODELTXT","YEARTXT","CITY","STATE" FROM COMPLAINTS').filter('MAKETXT = \'FORD\'').drop_duplicates(['CONTENT']).add_id('ID').cast('ID', 'NVARCHAR (5000)')
train, test, valid = train_test_val_split(data=df_tm_source, training_percentage = 0.1, validation_percentage = 0.8, testing_percentage = 0.1, random_seed = 41)
train.count(),valid.count(), test.count()また、使用する列をID・メーカー・コンテンツ・カテゴリーに絞りました。
test.select(['ID', 'MFR_NAME', 'CONTENT', 'CATEGORY']).head(5).collect()
4.TF-IDFモデルの作成
trainのデータセットでtf_analysis関数を使用して、モデルを作成します。
tfidf= tf_analysis(train.select(['ID', 'CONTENT', 'CATEGORY']))作成後、3つのアウトプットをPythonで呼び出すことができます。
前述のSQLの例と同じ結果が得られるので、概要だけ記載し内容は割愛します。
・tfidf[0]:TF/IDFに関する指標を表示します。
・tfidf[1]:ドキュメント内の用語頻度を表示します。
・tfidf[2]:ドキュメントごとに該当するカテゴリーを表示します。
5.データを選択する
「3.データをフィルタリングする」で表示されたアウトプットの「ID:1」に関して見ていきます。

ID:1の内容は、「駐車中の車両が突然燃えた・原因が分からない」というクレームです。
このレポートのカテゴリー(問題)は「Electrical System=エンジンシステム」と事前に分類されていることが分かります。
6.text_classificationを用いて、テキストを分類する
ここで「本当にエンジンシステムの問題なのか」を判断していきます。
text_classificaionを使用して、機械的に分類をかけてみます。
(ID:1に近いテキストや情報を元に、何の問題に分類されるのかを分析します。)
tc = text_classification(test.filter('ID = 1').select(['ID', 'CONTENT']), tfidf, thread_ratio = 1, k_nearest_neighbours = 1)
tc[0].collect()すると、「Vehicle Speed Control:Cruise Control」と返されます。

事前のデータでは、今回の問題はElectrical Systemが原因だと分類されていました。
しかし、テキストマイニングの結果では「Cruise Control=一定速度を維持する機能」が問題だと判断されたのです。
なぜ、そう判断されたのかを手順に従って確認してみます。
7.レポートを確認する
3つの関数を使って、なぜCruise Controlの問題と判断したかを確認します。
・get_relevant_term
ID:1に関連する「単語」を一覧で表示します。
get_relevant_term(test.filter('ID = 1').select('CONTENT'), tfidf).head(10).collect()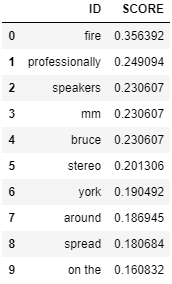
この結果、「Cruise Control」と関連して最も頻出する単語は「fire」であることが分かります。
つまり、火災事故(fire)のクレームに「Cruise Control」のことも書かれていることが多いということです。
・get_related_doc
この関数では、ID:1に類似する「ドキュメント」を一覧で表示します。
get_related_doc(test.filter('ID = 1').select('CONTENT'), tfidf).head(10).collect()
この結果、ID:1の内容に近いドキュメントがスコア順に一覧で表示されます。
また、ID:1の内容に最も近いドキュメントがID:113733であることが分かります。
この中で「ID:113733・46」に関して、その中身を確認してみます。
・train.filter
この関数では、指定したIDの内容を表示します。
train.filter('ID = 113733').collect().iloc[0,1]train.filter('ID = 46').collect().iloc[0,1]
内容を確認してみると、共通している事象として「火災事故が起こる前にCruise Controlが作動できなかったこと」が分かります。
この3つの関数により、突如起こったいくつかの火災事故の原因はCruise Controlが機能しなくなったことではないかと導き出すことができます。
手作業による分類や分析では、取得できる情報やインサイトに限界があります。このようにテキストマイニングを利用することで、膨大なテキストデータから機械的に類似パターンを発見し、瞬時に新しいインサイトを把握することができます。
最後に
HANA CloudではSQL・Pythonを使用し、簡単にテキストマイニングを利用できることが確認できました。
しかし、これまでの例では開発者しか分析結果を確認できないようにも思えます。そんなことありません!
様々なアプリケーションを連携させれば、ビジネスユーザーも簡単に分析することができます。
なぜなら、事前にプログラムを書いておくことで、自動的にテキストマイニングを実行することができるからです。
補足として、例を簡単に紹介します。

この図は、全体像です。CRM(顧客管理システム/Afterーsales system)からHANA Cloudへ
自動的にデータをインポートし、Fiori上で分析できることを表しています。
このシステム基盤があれば、営業マンが商談後にFioriを確認するだけで、
過去に類似した成功例はあるのか・どういうアプローチをしていたのかを瞬時に確認できます。
その結果、全社員が営業活動を日々改善することができます。
以上です、最後まで読んでいただきありがとうございます。
渡辺 朋輝
- SAP Managed Tags:
- SAP HANA Cloud,
- Python,
- SAP Text Analysis
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
178 -
Expert Insights
293 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
12 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
336 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
415 -
Workload Fluctuations
1
Related Content
- Python RAG sample for beginners using SAP HANA Cloud and SAP AI Core in Technology Blogs by SAP
- Issues with "SAP Analytics Cloud, add-in for Microsoft Excel" while working with SAP Datasphere in Technology Q&A
- SAP Analytics Cloud Excel Add In - Multiple Tables in Technology Q&A
- AI Core - on-premise Git support in Technology Q&A
- Lowest SAP ECC version that can be integrated with SAP BTP through Cloud Connector in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 29 | |
| 21 | |
| 10 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 5 | |
| 5 |