
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Text Mining on SAP HANA Cloud
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member43
Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-29-2021
4:06 AM
In this blog, I will introduce you to the text mining capabilities of SAP HANA Cloud added in April 2021 to the Predictive Analytics Library (PAL). Text mining capabilities are only supporting English for now.
SAP HANA Cloud's Text Mining functions include:
Text mining is the process of deriving high-quality information from text.
It involves the discovery by computer of previously unknown information by automatically extracting information from different written resources, including websites, books, emails, reviews, customer messages and articles.
High-quality information is typically obtained by devising patterns and trends by means such as statistical pattern learning.
Most organizations are reading text only at a human-scale.
Field workers fill in reports which are read only by their supervisors, sales and after-sales people read feedback from their own customers.
The knowledge of most people is limited to their own interactions with other employees, customers, suppliers.
Which is the most frequent spare-part mentioned on High criticality issues reported from Field engineers to the manufacturing plant ?
What are the top 3 operations taking place each month from the Maintenance department ?
What are the principal sources of dissatisfaction that leads customers to competitors ?
These questions become very hard to answer when there is no quantitative data in a large organization. Every employee only knows their little piece of the whole puzzle.
That is where Text Mining with SAP HANA Cloud can help you: it enables you to utilize the non-structured text data together with structured operational data in one database in order to understand your organization at scale.
Let me introduce you to the Text Mining capabilities of HANA Cloud by following the official manual.
Text Mining capabilities are part of the larger Predictive Analytics Library(PAL). Have a look at this blog to learn more about all functions offered in PAL.
The Term Analysis function calculates TF-IDF values of input documents.
It is a necessary step to use other functions. TF-IDF (term frequency–inverse document frequency) is a numerical statistic that is intended to reflect how important a word is to a document in a collection.
This is done by multiplying two metrics: how many times a word appears in a document (TF), and the inverse document frequency (IDF) of the word across a set of documents.
The TF–IDF value increases proportionally to the number of times a word appears in the document and is offset by the number of documents in the corpus that contain the word, which helps to adjust for the fact that some words appear more frequently in general.
Let's see an example :
Using SQL, create a simple table, with an ID column, content and a category as such :
Now, call the PAL_TF_ANALYSIS function on this table with this SQL command :
The PAL_TF_ANALYSIS function has 3 output tables.
Here are the results in my example :
1. PAL_TM_TERM_TAB includes all the details about the TF-IDF value for each word.
2. PAL_TM_DOC_TERM_FREQ_TAB lists the frequency of each term in each document.
3. PAL_TM_CATE_TAB lists the category to which each document belongs.
Based on this TF-IDF model, you can now predict in which category new documents belong based on their similarity to past documents.
Let us try to add 2 new documents without category in the table PAL_TM_PRED_TAB .
Now, let's use the PAL_TEXTCLASSIFICATION function to predict their category.
You can see that using the 3 outputs from the last function as inputs, HANA predicts the category to which these two documents belong.
The classification function has another output. It gives you the closest document used during training, and the logical distance to that document.
Two documents will be closer the more they have terms in common, and the least these terms are used in other documents.
Now that you understand how to work with the Text Mining functions, let us explore a real dataset.
Here is the flow that we are going to follow :

For this example, I used Python in a Jupyter Notebook.
I can share the code necessary to replicate this example. If you need some help to replicate it, contact me.
We start by importing the python libraries which we are going to use. The main one is the python HANA_ML library which allows us to use all Text Mining functions.
Then I define the connection to a SAP HANA Cloud database. You can see the host, port, user and password in this example. You can also use the secure user store to connect securely without showing your user/password in python.
In the commented section, I also show the necessary rights AFL__SYS_AFL_AFLPAL_EXECUTE_WITH_GRANT_OPTION to use PAL.
With this connection defined, I can now select the complaints from customers about their cars which I loaded into HANA Cloud beforehand.
I'll be using 4 columns from this dataset : ID, Manufacturer, Content and Category.
Manufacturer : in this case I filtered only on complaints addressed at FORD.
Content : the complaints in plain English text.
Category : Complaints have been categorized beforehand.
I divide my complaints in 3 datasets : Train (10240 rows), Validation(91025 rows) and Testing(12516 rows)
I then use the tf_analysis function on the train dataset to create a Text Mining model.
Calling it with python gives exactly the same result as the earlier SQL example.
This function has 3 output tables. I show some information on the first output below.
Now that the Text Mining model is created, I can categorize documents from the test dataset to check whether my model predicts accurately the category.
Here I select the first 3 records from my test dataset.
You can see in the content that the first record is categorized as a "ELECTRICAL SYSTEM" issue.
if you read the content, you will see that a parked vehicle suddenly caught on fire. It is believed to be due to an issue in the electrical system.
Then, I use the text_classification function on the first record without its category to check the result.
The record gets categorized as "VEHICLE SPEED CONTROL CRUISE CONTROL" !?
To me, the content seems to be more related to fire or an electrical issue than the cruise control system. You can see that indeed the cruise control stopped working for some time.
I decide to dig deeper and find which terms led to this result.
For this I use the function get_relevant_terms which gives me the top influencers and their contribution.
OK, "fire" is the most relevant term. This means that somehow the word "fire" is associated with cruise control !? Is speed control that dangerous ?
Let us find out more with the get_related_doc function which lists related documents that were used in the Text mining.
We see that the most related document in the train dataset is 113733. Let's open it!
Document 113733 tells a very similar story. A parked vehicle suddenly caught on fire.
And we notice that the cruise control also stopped working some time before the incident.
Finally, you can use the get_related_term and get_relevant_doc to find out more insights about words in your text.
get_related term will output words frequently used together with a particular term. In this case I did a search with "cruise".
get_relevant_doc will output documents related to a particular term. For example you can find other instances of customers complaining about cruise control.
In this blog, my goal was to give readers insights about HANA Cloud Text Mining capabilities.
I went into details into the implementation of such functions. Be it in SQL, or in Python, a data analyst can find her way through massive unstructured text with this technology.
I would like to leave you with the greatest strenght of this product.
Text Mining is not a stand-alone offering.
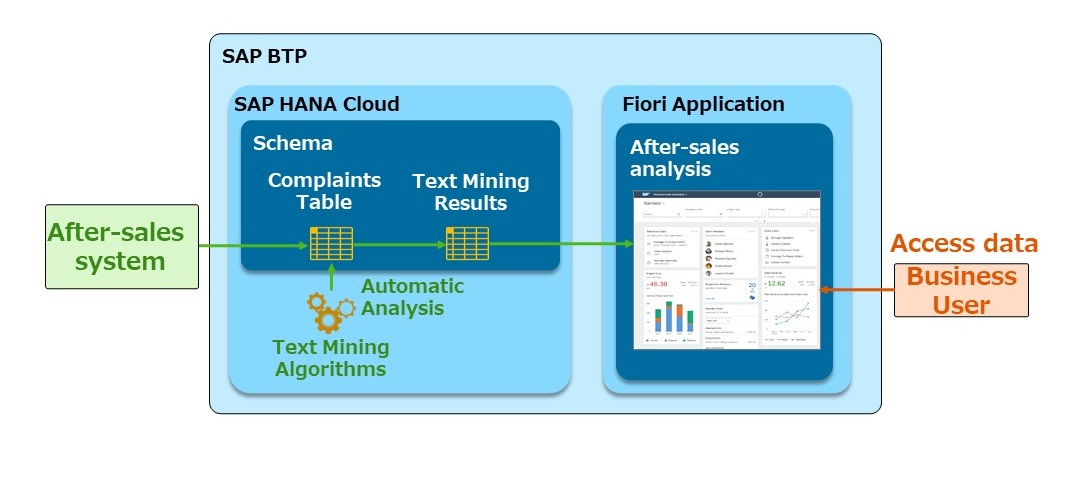
This is just one of the many algorithms offered within SAP HANA Cloud. It could easily be integrated with your other SAP applications, and work through a custom Fiori User Interface.
If you import data automatically from a CRM or After-sales system, service engineers could access an analytical app and find out insights about their customer feedback at a scale of millions of documents.
See Text mining at SAP HANA Cloud with Python for another use case.
Special thanks to Matthias Menz for providing this scenario.
Maxime SIMON
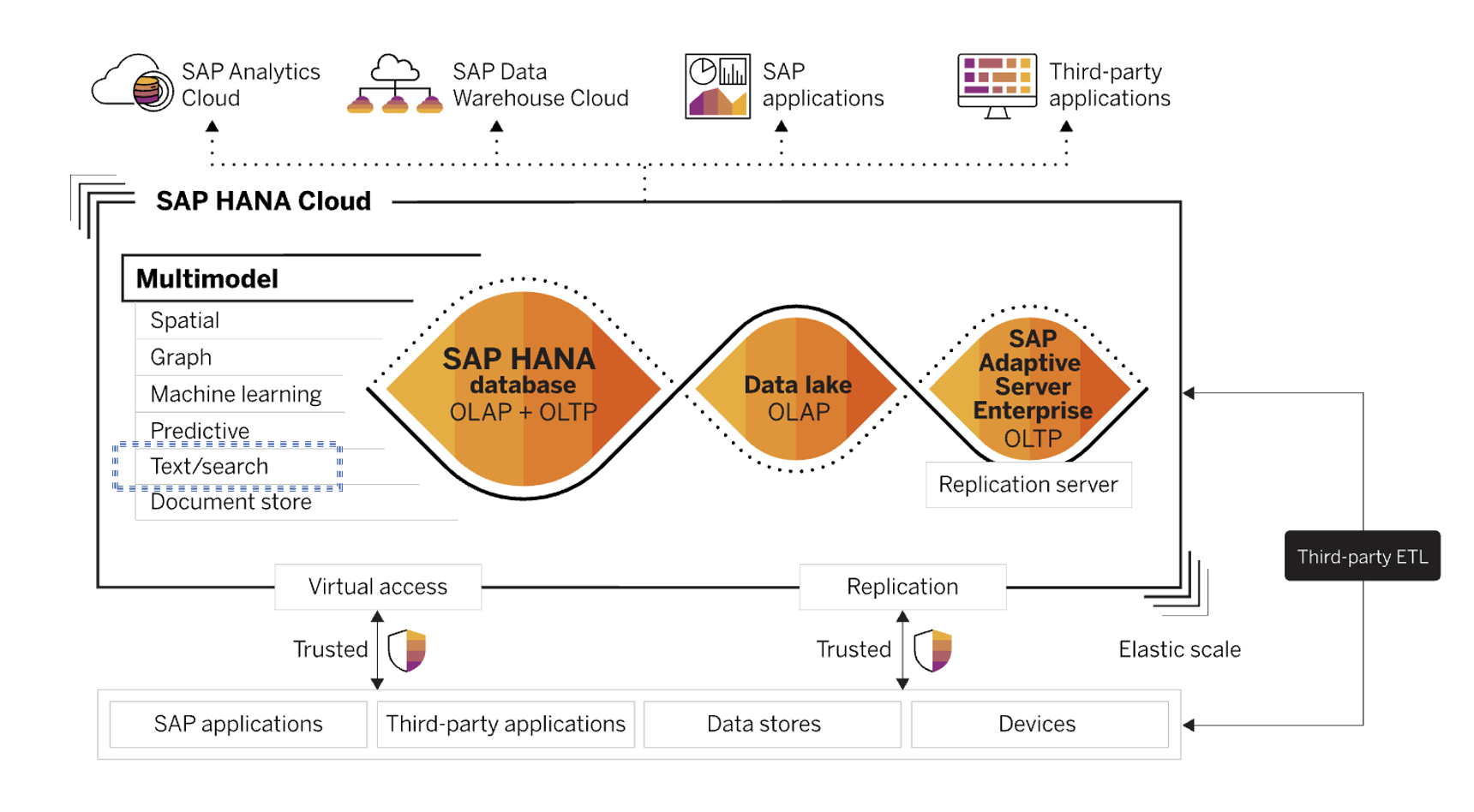
SAP HANA Cloud's Text Mining functions include:
- Term frequency analysis to identify important and high-frequent terms.
- Text classification: analysis functions (e.g. get related documents or terms, get relevant terms)
- Text processing included in Python machine learning client 2.8. The new module is called text.tm. It supports both SAP HANA cloud and SAP HANA on-premise equivalent functions
- What is Text Mining ?
- What is the value for your business ?
- SAP HANA Cloud Text Mining
- Real world example
- Conclusion
What is Text Mining ?
Text mining is the process of deriving high-quality information from text.
It involves the discovery by computer of previously unknown information by automatically extracting information from different written resources, including websites, books, emails, reviews, customer messages and articles.
High-quality information is typically obtained by devising patterns and trends by means such as statistical pattern learning.
What is the value for your business ?
Most organizations are reading text only at a human-scale.
Field workers fill in reports which are read only by their supervisors, sales and after-sales people read feedback from their own customers.
The knowledge of most people is limited to their own interactions with other employees, customers, suppliers.
Which is the most frequent spare-part mentioned on High criticality issues reported from Field engineers to the manufacturing plant ?
What are the top 3 operations taking place each month from the Maintenance department ?
What are the principal sources of dissatisfaction that leads customers to competitors ?
These questions become very hard to answer when there is no quantitative data in a large organization. Every employee only knows their little piece of the whole puzzle.
That is where Text Mining with SAP HANA Cloud can help you: it enables you to utilize the non-structured text data together with structured operational data in one database in order to understand your organization at scale.
SAP HANA Cloud Text Mining
Let me introduce you to the Text Mining capabilities of HANA Cloud by following the official manual.
Text Mining capabilities are part of the larger Predictive Analytics Library(PAL). Have a look at this blog to learn more about all functions offered in PAL.
The Term Analysis function calculates TF-IDF values of input documents.
It is a necessary step to use other functions. TF-IDF (term frequency–inverse document frequency) is a numerical statistic that is intended to reflect how important a word is to a document in a collection.
This is done by multiplying two metrics: how many times a word appears in a document (TF), and the inverse document frequency (IDF) of the word across a set of documents.
The TF–IDF value increases proportionally to the number of times a word appears in the document and is offset by the number of documents in the corpus that contain the word, which helps to adjust for the fact that some words appear more frequently in general.
Let's see an example :
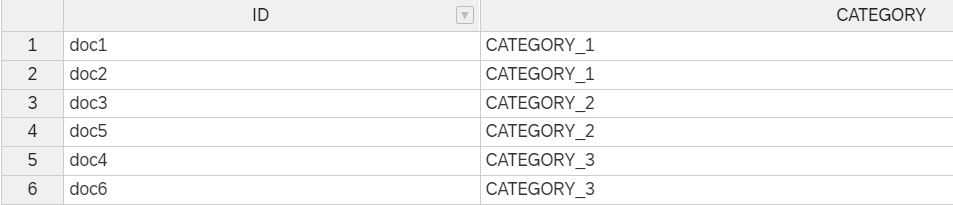
Using SQL, create a simple table, with an ID column, content and a category as such :
create column table PAL_TFIDF_DATA_TAB (
"ID" nvarchar(1000),
"CONTENT" nvarchar(1000),
"CATEGORY" nvarchar(1000)
);
INSERT INTO PAL_TFIDF_DATA_TAB VALUES('doc1','term1 term2 term2 term3 term3 term3','CATEGORY_1');
INSERT INTO PAL_TFIDF_DATA_TAB VALUES('doc2','term2 term3 term3 term4 term4 term4','CATEGORY_1');
INSERT INTO PAL_TFIDF_DATA_TAB VALUES('doc3','term3 term4 term4 term5 term5 term5','CATEGORY_2');
INSERT INTO PAL_TFIDF_DATA_TAB VALUES('doc5','term3 term4 term4 term5 term5 term5 term5 term5 term5','CATEGORY_2');
INSERT INTO PAL_TFIDF_DATA_TAB VALUES('doc4','term4 term6','CATEGORY_3');
INSERT INTO PAL_TFIDF_DATA_TAB VALUES('doc6','term4 term6 term6 term6','CATEGORY_3');Now, call the PAL_TF_ANALYSIS function on this table with this SQL command :
call _SYS_AFL.PAL_TF_ANALYSIS(
PAL_TFIDF_DATA_TAB,
PARAMETERS,
PAL_TM_TERM_TAB,
PAL_TM_DOC_TERM_FREQ_TAB,
PAL_TM_CATE_TAB
);The PAL_TF_ANALYSIS function has 3 output tables.
Here are the results in my example :
1. PAL_TM_TERM_TAB includes all the details about the TF-IDF value for each word.

2. PAL_TM_DOC_TERM_FREQ_TAB lists the frequency of each term in each document.

3. PAL_TM_CATE_TAB lists the category to which each document belongs.
Based on this TF-IDF model, you can now predict in which category new documents belong based on their similarity to past documents.
Let us try to add 2 new documents without category in the table PAL_TM_PRED_TAB .
create column table PAL_TM_PRED_TAB (
"ID" nvarchar(1000),
"CONTENT" nvarchar(1000)
);
INSERT INTO PAL_TM_PRED_TAB VALUES('doc10','term2 term2 term3 term3');
INSERT INTO PAL_TM_PRED_TAB VALUES('doc11','term4 term4 term4 term5');
Now, let's use the PAL_TEXTCLASSIFICATION function to predict their category.
call _SYS_AFL.PAL_TEXTCLASSIFICATION(
PAL_TM_TERM_TAB,
PAL_TM_DOC_TERM_FREQ_TAB,
PAL_TM_CATE_TAB,
PAL_TM_PRED_TAB,
PARAMETERS, ?, ?);You can see that using the 3 outputs from the last function as inputs, HANA predicts the category to which these two documents belong.

The classification function has another output. It gives you the closest document used during training, and the logical distance to that document.
Two documents will be closer the more they have terms in common, and the least these terms are used in other documents.

Real world example
Now that you understand how to work with the Text Mining functions, let us explore a real dataset.
Here is the flow that we are going to follow :
- As a data analyst, I am going to perform Text Mining on a large dataset of complaints related to cars in the US.
- Then I will classify new complaints based on the Text Mining model.
- Finally I will explore similar documents to uncover a cruise control issue !
For this example, I used Python in a Jupyter Notebook.
I can share the code necessary to replicate this example. If you need some help to replicate it, contact me.
We start by importing the python libraries which we are going to use. The main one is the python HANA_ML library which allows us to use all Text Mining functions.
Then I define the connection to a SAP HANA Cloud database. You can see the host, port, user and password in this example. You can also use the secure user store to connect securely without showing your user/password in python.
In the commented section, I also show the necessary rights AFL__SYS_AFL_AFLPAL_EXECUTE_WITH_GRANT_OPTION to use PAL.
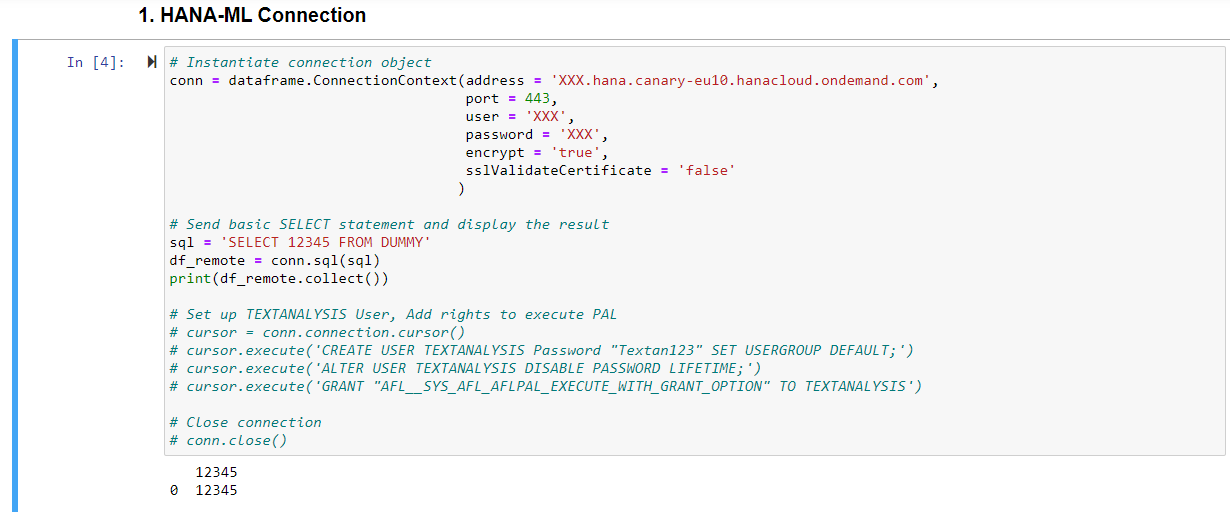
With this connection defined, I can now select the complaints from customers about their cars which I loaded into HANA Cloud beforehand.
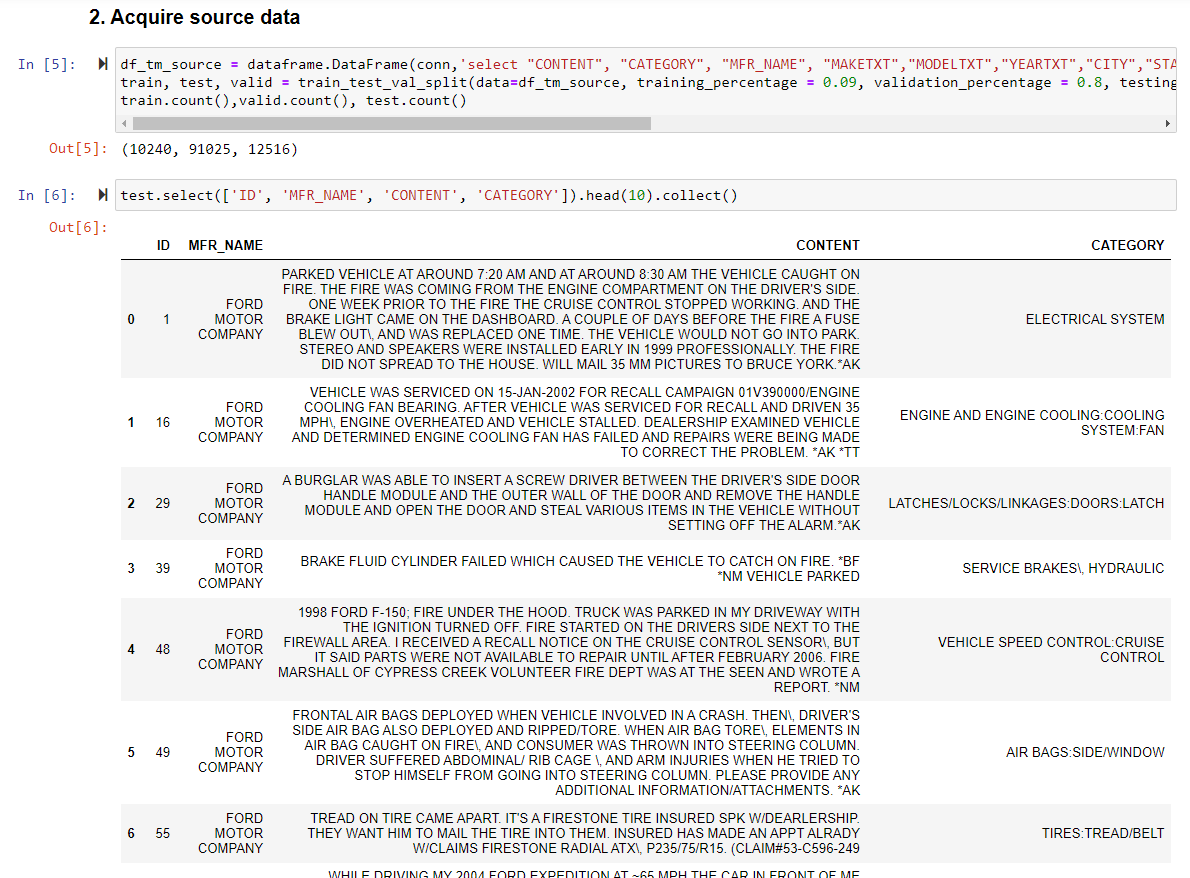
I'll be using 4 columns from this dataset : ID, Manufacturer, Content and Category.
Manufacturer : in this case I filtered only on complaints addressed at FORD.
Content : the complaints in plain English text.
Category : Complaints have been categorized beforehand.
I divide my complaints in 3 datasets : Train (10240 rows), Validation(91025 rows) and Testing(12516 rows)
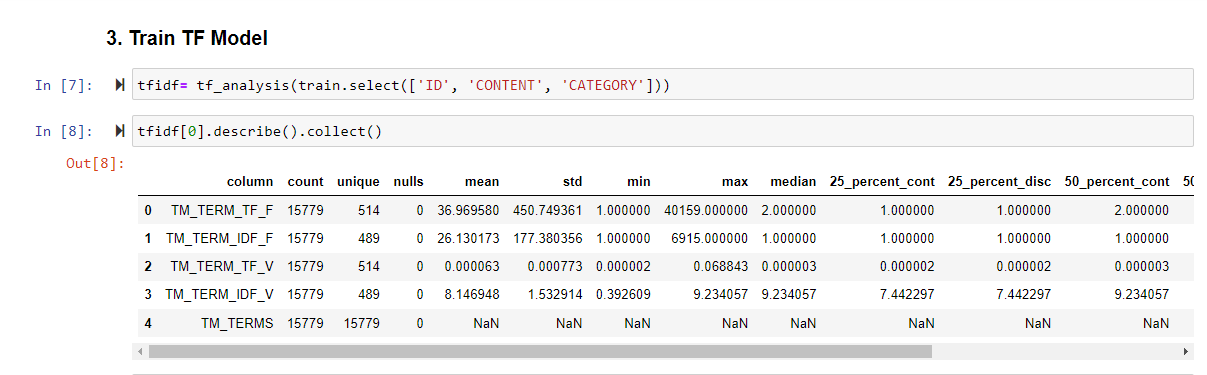
I then use the tf_analysis function on the train dataset to create a Text Mining model.
Calling it with python gives exactly the same result as the earlier SQL example.
This function has 3 output tables. I show some information on the first output below.
Now that the Text Mining model is created, I can categorize documents from the test dataset to check whether my model predicts accurately the category.
Here I select the first 3 records from my test dataset.
You can see in the content that the first record is categorized as a "ELECTRICAL SYSTEM" issue.
if you read the content, you will see that a parked vehicle suddenly caught on fire. It is believed to be due to an issue in the electrical system.
Then, I use the text_classification function on the first record without its category to check the result.
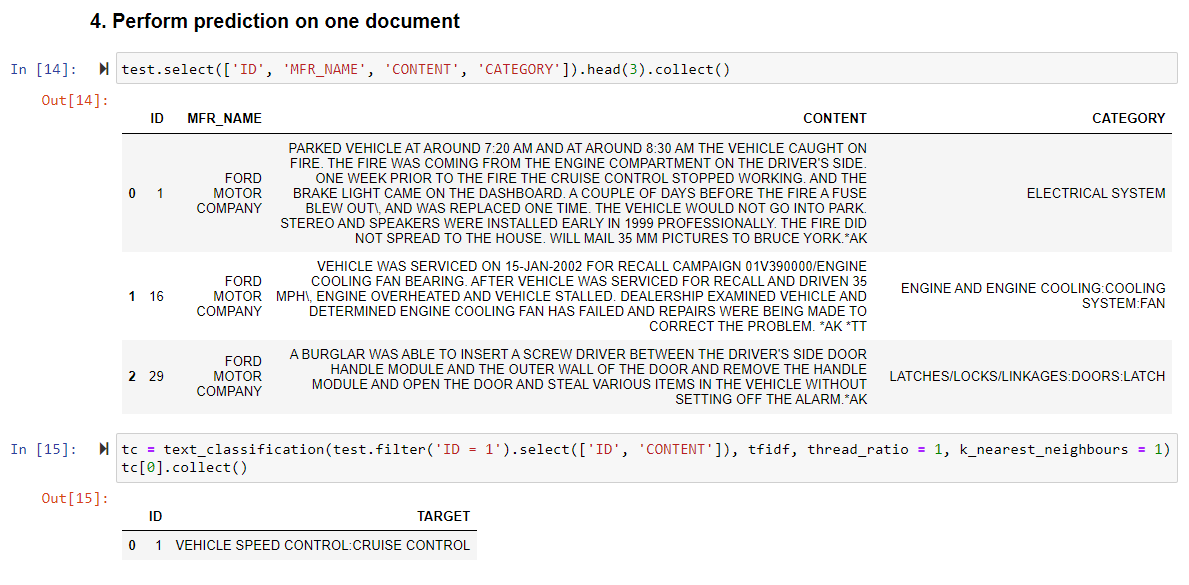
The record gets categorized as "VEHICLE SPEED CONTROL CRUISE CONTROL" !?
To me, the content seems to be more related to fire or an electrical issue than the cruise control system. You can see that indeed the cruise control stopped working for some time.
I decide to dig deeper and find which terms led to this result.
For this I use the function get_relevant_terms which gives me the top influencers and their contribution.

OK, "fire" is the most relevant term. This means that somehow the word "fire" is associated with cruise control !? Is speed control that dangerous ?
Let us find out more with the get_related_doc function which lists related documents that were used in the Text mining.
We see that the most related document in the train dataset is 113733. Let's open it!
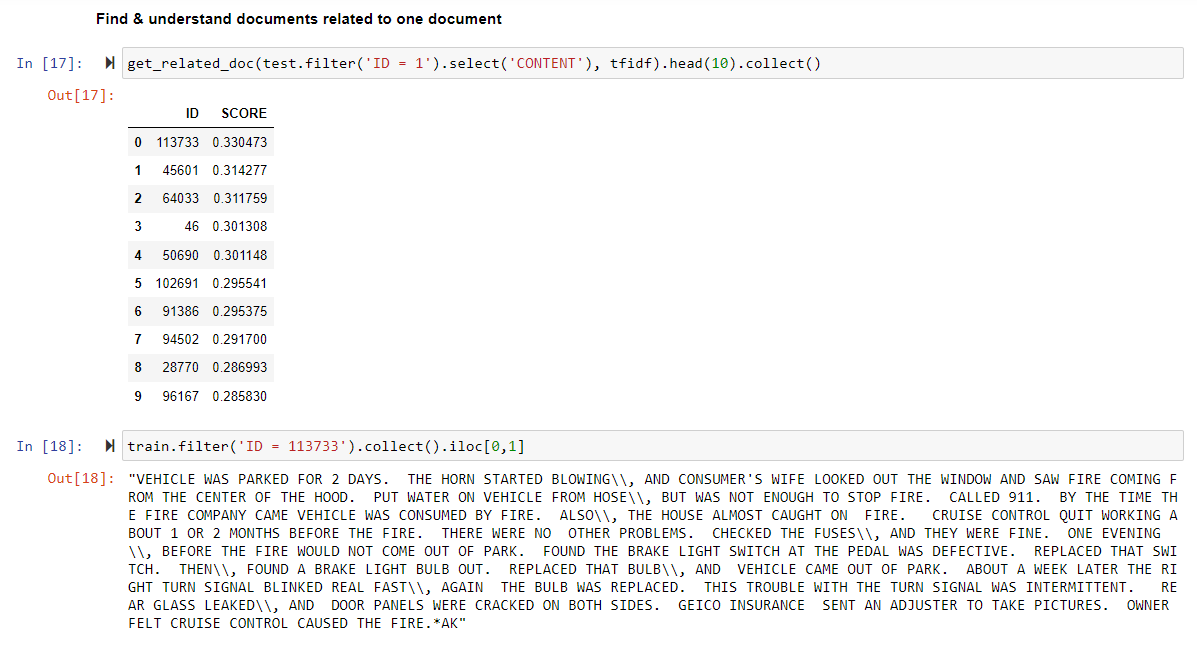
Document 113733 tells a very similar story. A parked vehicle suddenly caught on fire.
And we notice that the cruise control also stopped working some time before the incident.
This is exactly the kind of insights that you can only derive from text mining.
HANA Cloud leverages the experience amassed in a massive body of documents and find patterns which a human could never find. In this case the link between "cruise control" and "fire" in several documents.
Finally, you can use the get_related_term and get_relevant_doc to find out more insights about words in your text.
get_related term will output words frequently used together with a particular term. In this case I did a search with "cruise".
get_relevant_doc will output documents related to a particular term. For example you can find other instances of customers complaining about cruise control.

Conclusion
In this blog, my goal was to give readers insights about HANA Cloud Text Mining capabilities.
I went into details into the implementation of such functions. Be it in SQL, or in Python, a data analyst can find her way through massive unstructured text with this technology.
I would like to leave you with the greatest strenght of this product.
Text Mining is not a stand-alone offering.
This is just one of the many algorithms offered within SAP HANA Cloud. It could easily be integrated with your other SAP applications, and work through a custom Fiori User Interface.
If you import data automatically from a CRM or After-sales system, service engineers could access an analytical app and find out insights about their customer feedback at a scale of millions of documents.
See Text mining at SAP HANA Cloud with Python for another use case.
Special thanks to Matthias Menz for providing this scenario.
Maxime SIMON
- SAP Managed Tags:
- Machine Learning,
- SAP HANA Cloud
Labels:
5 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
85 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
269 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
10 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,578 -
Product Updates
322 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
393 -
Workload Fluctuations
1
Related Content
- What’s New in SAP Analytics Cloud Release 2024.08 in Technology Blogs by SAP
- SAP Enable Now setup in Technology Blogs by Members
- Flexible Workflow for PR in Technology Q&A
- explore the business continuity recovery sap solutions on AWS DRS in Technology Blogs by Members
- Unlocking Full-Stack Potential using SAP build code - Part 1 in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 11 | |
| 10 | |
| 10 | |
| 10 | |
| 9 | |
| 8 | |
| 8 | |
| 7 | |
| 7 | |
| 6 |