
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- The highlights from the SAP HANA Cloud Workshops
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
04-01-2021
11:01 AM
Last week, Volker Saggau and I co-hosted the second series of the SAP HANA Cloud Workshops focusing on creating database objects in SAP HANA Cloud with SAP Business Application Studio in a federated scenario.
In the hands-on workshop, participants joined us with their own trial accounts of SAP HANA Cloud, HANA database and engaged in live questions during three sessions:
All three workshop sessions are now available for you to watch on-demand, in case you missed the sessions or would like to re-watch them:
Watch the Workshop on-demand
Each session comes with detailed instructional materials, like step-by-step workbooks, sample data and sample code that can be retrieved from a github repository.
You can find the workbooks and additional materials in the Resources of each session when watching it on-demand.
In this blog post, you can get an overview of the workshops content. We included the pages in the workbook so you can easily navigate the three sessions and find the content you need.
Pre-Requisites
Session 1: How to set up an environment and define data structure
(Watch on-demand / access the workbook)
In this first session, Volker Saggau went through the steps in setting up an SAP HANA native application development space and project in SAP Business Application Studio. This included binding it to an SAP HANA Cloud, HANA database, connecting the project to a github repository and creating tables and roles.
In the first half of the session, our goal was to create a development environment in SAP Business Application Studio and connect this environment to a github repository. To achieve this goal we followed these steps:
In the second half of the session, our goal was to create tables and roles in the development project. This included the following steps:
The objects we created in session 1 were then used in session 2.
Session 2: How to build up a federated scenario
(Watch on-demand / access the workbook)
In the second session, we worked in a federated scenario.
Using their own trial account (represented as T1 in the diagram below), participants connected to an SAP HANA Cloud, HANA database instance provided by us (represented as T2 in the diagram below) and a SAP HANA Cloud, data lake connected to this instance T2.
We showed what preparations we have made in our instance T2 in order for participants to work with the tables in T2 and SAP HANA Cloud, data lake.
After that, we showed how to perform the following steps:
In the second phase of session 2, we showed how to create a flowgraph to distribute data to different tables in the landscape and how to access them in a simple calculation view that uses a Union Node.
For this, we followed these steps:
Session 3: How to use calculation views in a federated scenario
(Watch on-demand / access the workbook)
In the third and final session, we brought all the preparations done in session 1 and 2 together to show how to use and optimize calculation views in the federated scenario.
Improving the calculation view for federated queries was done using different techniques like Union Pruning and Static Cache. We also showed how to manage access to data on record level by using analytic privileges.
These were the steps of session 3:
This concludes the highlights from this workshop series. If you missed it or want to re-watch it, you can find the on-demand sessions here:
Watch the Workshop on-demand
To stay up-to-date about upcoming events and new learning content, you can register for the SAP HANA Cloud Newsletter.
You can also click here to explore the SAP HANA Cloud Learning Tracks.
In the hands-on workshop, participants joined us with their own trial accounts of SAP HANA Cloud, HANA database and engaged in live questions during three sessions:
- March 23rd - Session 1: How to set up an environment and define data structure
- March 24th - Session 2: How to build up a federated scenario
- March 25th - Session 3: Create calculation views in SAP Business Application Studio
All three workshop sessions are now available for you to watch on-demand, in case you missed the sessions or would like to re-watch them:
Watch the Workshop on-demand
Each session comes with detailed instructional materials, like step-by-step workbooks, sample data and sample code that can be retrieved from a github repository.
You can find the workbooks and additional materials in the Resources of each session when watching it on-demand.
In this blog post, you can get an overview of the workshops content. We included the pages in the workbook so you can easily navigate the three sessions and find the content you need.
Pre-Requisites
- Sign-up for the SAP HANA Cloud trial. We recommend using the US server for this workshop.
- If you already have a trial account with SAP Cloud Platform, check your trial entitlements to add SAP HANA Cloud
- Provision an SAP HANA Cloud, SAP HANA database in trial.
- Make sure your SAP HANA Cloud, SAP HANA database is running in your trial account.
- Add a subscription to SAP Business Application Studio to your trial.
- Create a free account on github.com.
Session 1: How to set up an environment and define data structure
(Watch on-demand / access the workbook)

In this first session, Volker Saggau went through the steps in setting up an SAP HANA native application development space and project in SAP Business Application Studio. This included binding it to an SAP HANA Cloud, HANA database, connecting the project to a github repository and creating tables and roles.

In the first half of the session, our goal was to create a development environment in SAP Business Application Studio and connect this environment to a github repository. To achieve this goal we followed these steps:
- Creating a Dev Space in SAP Business Application Studio using the SAP HANA Native Application pre-settings (p.11)
- Setting the global git parameters in this dev space using the Terminal in SAP Business Application Studio (p.13)
- Generating an SSH key in SAP Business Application Studio and using it with a github account (pp.14-17)
- Creating a new repository in github (p.18)
- Building a new project in SAP Business Application Studio (p.20)
- Initializing the github environment in a development project (p.23)
- Adjusting the ".gitignore"-file of the project to only push selected artifacts to github (p.24)
- Pushing changes to the github repository (p.25)

In the second half of the session, our goal was to create tables and roles in the development project. This included the following steps:
- Creating an hdbmigration table using the Code Editor and deploying it (p.28)
- Creating three hdbroles using the Role Editor and Code Editor and deploying them (p.31)
- Committing all changes to the github repository (p.36)
The objects we created in session 1 were then used in session 2.
Session 2: How to build up a federated scenario
(Watch on-demand / access the workbook)
In the second session, we worked in a federated scenario.
Using their own trial account (represented as T1 in the diagram below), participants connected to an SAP HANA Cloud, HANA database instance provided by us (represented as T2 in the diagram below) and a SAP HANA Cloud, data lake connected to this instance T2.

We showed what preparations we have made in our instance T2 in order for participants to work with the tables in T2 and SAP HANA Cloud, data lake.
After that, we showed how to perform the following steps:
- Creating a PSE to manage the certificate for remote sources, creating a remote source from T1 to T2 (p.15). We also created dedicated users and used the remote source connection (p.19).
- Creating virtual tables pointing to a table in T2 and SAP HANA Cloud, data lake and managing privileges to access them (p.20)
- Importing sample data and managing privileges to access them (p.22)
In the second phase of session 2, we showed how to create a flowgraph to distribute data to different tables in the landscape and how to access them in a simple calculation view that uses a Union Node.

For this, we followed these steps:
- Creating a new development project (p.24)
- Using a calculation view to auto-generate .hdbsynonym and .hdbgrants files for access to other HDI-containers (p.25)
- Adjusting .hdbgrants files to manage authorizations (p.29)
- Creating a user-provided service connection and corresponding .hdbgrants file (p.30)
- Creating synonyms (p.33)
- Creating a flowgraph to load data from the imported sample data to the table created in session 1 (p.34)
- Previewing the data in SAP HANA Database Explorer (p.41)
- Creating a design-time virtual table (p.42)
- Using a flowgraph to load data to remote sources (p.45)
- Completing the calculation view by adding and mapping the different data sources (p.49)
- Creating a reference query that accesses the different data sources (p.55)
Session 3: How to use calculation views in a federated scenario
(Watch on-demand / access the workbook)
In the third and final session, we brought all the preparations done in session 1 and 2 together to show how to use and optimize calculation views in the federated scenario.
Improving the calculation view for federated queries was done using different techniques like Union Pruning and Static Cache. We also showed how to manage access to data on record level by using analytic privileges.
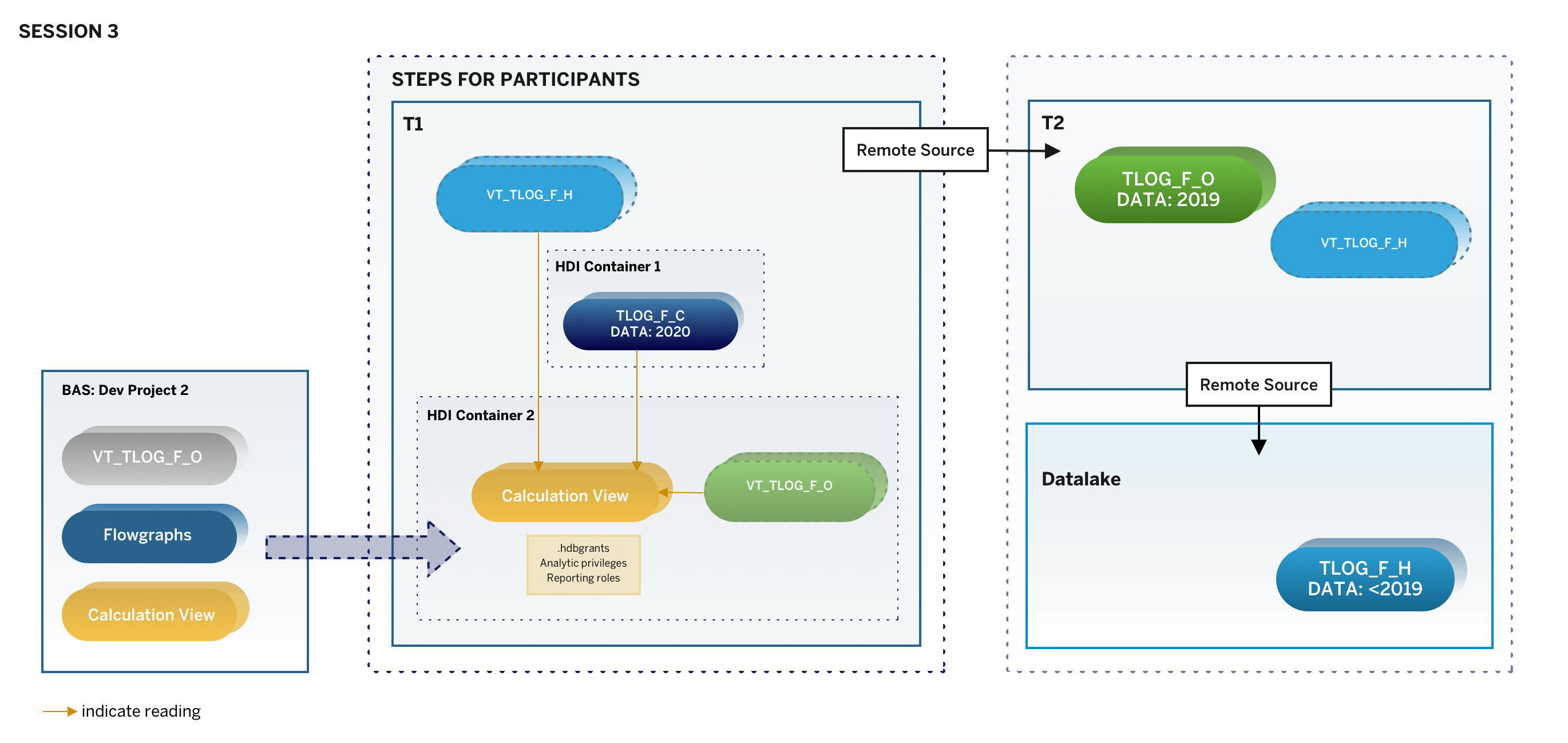
These were the steps of session 3:
- Using Union Pruning in a calculation view (p.10)
- Analyzing the Explain Plan to see Union Pruning at work (p.14)
- Using caching with Calculation Views (p.18), which included enabling individual columns for caching and analyzing the Explain Plan to see the effect of caching
- Applying Analytic Privileges to restrict what records of a view should be visible to individual users (p.25). This included creating Analytic Privileges, creating new HDI roles, granting privileges to these roles, as well as creating new users and granting them these roles
- Creating an analytic privilege that allows seeing the full data set of the calculation view (p.36), which included creating the development_debug_role to assign this privilege to the default user of the data preview. To also benefit from caching in a scenario with analytic privileges we adjusted the calculation view to create the cache before applying the analytic privilege
This concludes the highlights from this workshop series. If you missed it or want to re-watch it, you can find the on-demand sessions here:
Watch the Workshop on-demand
To stay up-to-date about upcoming events and new learning content, you can register for the SAP HANA Cloud Newsletter.
You can also click here to explore the SAP HANA Cloud Learning Tracks.
Labels:
2 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
299 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
344 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
423 -
Workload Fluctuations
1
Related Content
- ABAP Cloud Developer Trial 2022 Available Now in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform - Blog 5 in Technology Blogs by SAP
- Top Picks: Innovations Highlights from SAP Business Technology Platform (Q1/2024) in Technology Blogs by SAP
- What’s New in SAP Analytics Cloud Release 2024.08 in Technology Blogs by SAP
- Sneak Peek in to SAP Analytics Cloud release for Q2 2024 in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 40 | |
| 25 | |
| 17 | |
| 14 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |