
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Cloud Integration - What You Need to Know About th...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Employee
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-16-2021
7:55 AM
This blog post describes the Kafka adapter of SAP Cloud Integration.
Apache Kafka is an event streaming platform. It is often described as a publish/subscribe messaging system or as a distributed commit log. Kafka stores key-value messages (records) in topics that can be partitioned. Each partition stores these records in order, using an incremental offset (position of a record within a partition). Records are not deleted upon consumption, but they remain until the retention time or retention size is met on the broker side. Until then, messages may be re-processed again and again by one or multiple (different) consumers.
To optimize efficiency, the underlying messaging protocol is TCP-based. Messages are usually grouped together to reduce network overhead, which results in larger network packages.
Kafka runs on a cluster of one or more servers (brokers) and all topics and partitions are distributed (and replicated) across these brokers. This architecture allows you to distribute the load and increase the fault-tolerance. Each broker that is part of a cluster acts as a leader for certain partitions and acts as a replica for partitions being led by other brokers.
Kafka messages or records are key-value pairs (with a timestamp). The optional key is typically used to send similar records to one partition. Records that are produced for the same topic and the same partition are usually grouped into batches to reduce the network overhead which results in larger network packages. Batches may be compressed to reduce their size and optimize data transfer. The additional CPU time required for compression is often negligible.
Kafka records are sent to (and retained in) so-called topics. Kafka topics are divided into one or several partitions. Records are assigned an (incremental) offset within a partition and are retained until the defined retention time or retention size on the broker is reached. This prevents infinite retention of records on the broker. The records may be consumed multiple times and without any limitations as long as they are retained on the broker.
Topic names are restricted as follows:
The Kafka sender adapter fetches Kafka record batches from one or more topics. You can find detailed information about all possible parameters in the Configure the Kafka Sender Adapter documentation.
The Connection tab contains basic connectivity-settings to address the broker. You can maintain more than one bootstrap server to support the case of broker-related unavailability. Cloud Integration offers SASL and Client Certificate authentication options. In Kafka terms, this translates to the following supported security protocols: SSL, SASL_PLAINTEXT and SASL_SSL with supported SASL mechanisms PLAIN and SCRAM-SHA-256.
Note: Any change of key or trust material requires a restart (or redeployment) of the integration flow.
In order to enable SASL_PLAINTEXT
In order to enable SASL_SSL
In order to enable SSL
The Processing tab allows you to specify the topic(s) to subscribe to. You can configure one or more (comma-separated) topics, as well as a simple pattern like MyTopic* to consume from all topics starting with MyTopic (e.g. MyTopic1, MyTopic2).
Kafka consumers are typically part of a consumer group. Different consumer groups are separated from each other, even if they consume from the same topics.
The integration flow id (initial integration flow name upon creation) is used as consumer group. This ensures that other integration flows cannot interfere with record consumption. Other integration flows may consume from the same topics, but they will do so within their own, individual consumer group.
If a consumer group loses all of its consumers, the broker will remember consumer groups and their last consumed offsets per partition for a defined period of time (broker setting: offsets.retention.minutes). This way, a consumer can reconnect to its group to continue where the group stopped (i.e. downtimes, software updates, un- or redeployments).
If a consumer group is not yet (first deployment) or not anymore (offset retention) known to the broker, a new consumer starts from the latest (newest) offset. It does not consume all records of a topic from the beginning, but listens for new records only. The consumer might also encounter a situation in which the last-known offset (and subsequent ones) does not exist anymore (partition size exceeded threshold or record is expired, both broker configurations). In such situations, the consumer also resets to the latest offset (auto.offset.reset = latest).
Cloud Integration does not offer user-defined consumer group definitions in the sender adapter (e.g. in a text field). This is a conscious decision based on several reasons:
If you are in need of a specific consumer group name, you can always create the integration flow with exactly the required name.
Within one consumer group, only one Kafka consumer may fetch records from one partition. Topics can be consumed in parallel, if
Example: Topic A with 3 partitions (0, 1 and 2)
Records from this topic can be consumed in parallel by up to 3 consumers (one per partition).
Cloud Integration allows you to define the number of Parallel Consumers within a range of 1 to 25. This configuration scales with the number of worker nodes. To distribute the load across these nodes, it is necessary to configure a value of Parallel Consumers of less than the number of partitions. Otherwise one worker node creates the necessary consumers and hooks onto all partitions before a second worker node has the chance to do the same.
Example: Topic B with 24 partitions and Parallel Consumers set to 24 (3 worker nodes)
All 3 worker nodes spawn 24 processing threads, while most probably only the first node is able to connect to all 24 partitions. The other worker nodes do not consume any messages from Topic B. To balance this fairly across all 3 worker nodes, Parallel Consumers need to be set to 8. As the number of worker nodes may change over time, it makes sense to leave 'some room' for later, i.e. to set the configuration to 5. This means that one consumer might read from several partitions, until there are more consumers than partitions.
For the above reason, it makes sense to leave this setting on its default value unless performance requirements and test results show a need to raise it. In many cases (depending on the scenario, of course), a single consumer is perfectly capable to handle many partitions and messages.
A message fetched by the Kafka sender adapter may fail during processing. The sender may either skip the failed message and continue with the next offset (at most once semantics unless the consumer dies within auto.commit.interval.ms) or retry the failed message (at least once semantics within the record retention on the broker). The option to retry a failed message can potentially lead to infinite retries. Therefore, it is recommended to handle failed messages in an exception subprocess.
The Kafka sender adapter offers additional configuration options to define retry intervals and reconnect intervals. High-frequent retries can put considerable load onto the broker (and to Cloud Integration), which can be avoided by increasing the intervals (meaning: slowing down).
The retry behavior is not easy to comprehend at first. Let us look behind the curtains with some examples. In the examples, we consider one topic with 6 partitions. Trying to consume a message from partition 6 leads to an error.
The single consumer C1 fetches messages from all 6 partitions. As defined, it fails when trying to process a record fetched from partition 6. Since Error Handling is set to Retry Failed Message, the consumer disconnects from the broker and waits for the configured Max. Retry Backoff (in ms) before reconnecting. In the meantime, no record is consumed from any partition.
Now we add a second worker node to the picture.
Both consumers C1 and D1 are part of the same consumer group. Hence, they collaborate with the message consumption of the topic, each working on 3 partitions. Once D1 fails and disconnects, a rebalance takes place on broker side and C1 takes over the other 3 partitions in addition. As C1 also fails when trying to process a message of partition 6, it potentially leaves all partitions unattended until D1 reconnects. This depends on the configured Max. Retry Backoff (in ms) and the time the broker needs to finish the rebalance.
The exact same situation may occur on a single node with Parallel Consumers set to 2 as depicted below.
In reality, the setup usually looks more complex. The last example tries to provide a glimpse on that.
I outlined a single worker with 6 parallel consumers. We can multiply this by additional worker nodes to complicate this further, but I think you get the picture. This time I reduced the Max. Retry Backoff (in ms) so that C6 is back and ready for re-processing within 2 rebalances. In such a case, C5 and C6 take turns to work on the last two partitions. It also shows that the continuous failure of partition 6 also affects the processing of partition 5, while the processing of the other partitions continues to work without any problems.
Based on what we saw, Max. Retry Backoff (in ms) is not necessarily the time gap before the next processing attempt. This is the case in Example 1, but not in the other examples. If another consumer is available, it takes over in the meantime and the observed retry interval might just equal the rebalance time on the broker.
The Kafka sender adapter fetches records in batches. It offers numerous configuration options to tweak the min. and max. sizes to fetch, limit the number of polled records and set a max. waiting time. Even when misconfigured, the sender adapter always tries to progress, i.e. it fetches a record even if it is larger than the defined fetch.max.bytes. But it does not add additional messages to the fetched batch, if the max. size has already been exceeded.
Consumed records / offsets will be committed automatically in 5 second intervals (auto.commit.interval.ms). If a message fails in between (with retry enabled), the last successfully executed offset is immediately committed. If the consumer shuts down (e.g. undeployment of the integration flow), it commits the last offset that was processed successfully.
This leaves one potential gap: If a rebalance happens on the broker side (e.g. a consumer / worker node crashes), there is a time window of up to 5 seconds (+ processing time) of uncommitted offsets. These records are processed again, once the consumer is up and running again, since the broker is unaware of the processing state on the client.
To illustrate this concept and potential consequences in more detail, I prepared a few examples. For simplicity reasons we just assume a topic with a single partition only.
In the first example the kafka consumer is configured to
With each call to poll, the consumer receives a single message. Independent of its processing status (successful or failed), it continues with the next offset (remember: consumer is configured to skip failed messages) and it has to reach out to the broker to get a new record. A commit of consumed offsets will take place during a poll attempt exceeding the 5 second interval. As the message processing time of Record 5 takes longer, the offsets are not committed immediately after 5 seconds, but a little later, as the message processing time affects the time of the next poll attempt. As the commit succeeds, the broker now knows the consumed offsets for this partition and consumer group.
This case is very similar to the first one, as the consumer is configured in the same way. We now introduce a rebalance taking place on the broker side, kicking the consumer out of its group.
While the consumer is processing Record 4, the consumer is kicked out of its consumer group. The consumer only realizes this, however, the next time it interacts with the broker, which is during the next poll attempt. Being kicked out, it is unable to commit the offset. It will reconnect, get the latest committed offset from the broker and has to start over. The 5 second commit interval will also start over, so the next attempt to commit may only happen after a minimum of 5 additional seconds.
This example illustrates that even a batch size of 1 can lead to several duplicates due to the auto commit interval. Still, the rebalance is realized by the consumer rather quickly due to the frequent poll() calls to the broker.
Fetching more messages at once from the broker means reaching out to the broker less frequent (which is the whole point in the first place). This saves roundtrips, but also delays the commit operation. The client is still configured to skip failed messages, but the Max. Number of Polled Records is increased to 5.
This time, the client receives 5 messages with the first poll and it interates over these messages before polling again. In this example, the client finished processing these 5 messages just shortly before the 5 second commit interval exceeds, so the subsequent call to poll() does not trigger any offset commit action. Instead, the client receives another set of 5 messages and will work on those before contacting the broker again. After Record 10 finished processing, the auto commit interval is clearly exceeded, so an offset commit is triggered and the broker finally knows the consumption state of this topic partition and consumer group.
Now that we know that the batch size has a significant influence on the offset commit, let us introduce problems in the last example.
To make matters worse, there is a rebalance on broker side now. Consumer configuration remains the same as described in the previous example.
This sequence is the same as before with the exception of a rebalance shortly after the second poll. Unfortunately, the client is not aware of this until it reaches out to the broker at a much later point in time. When the client finally tries to commit the 10 records it has processed so far, it realizes it was kicked out of the group. Being unable to commit, it has to start over. Within the time frame of this example, the broker never persists any consumer offset resulting in many duplicates.
In my attempt to sketch the worst case scenarios, you might think this is all bad, but not necessarily. First and foremost, these examples served to elaborate on the commit behavior of the adapter. Secondly, I hope to sensitize you on some corner cases, which may occur at times. This way you can be prepared or even adapt your configuration upfront to minimize the impact.
I intentionally configured the consumer to skip failed messages. This is not the default configuration and undesired in most cases. If you do not skip failed messages, any message processing failure would immediately result in a commit attempt of the previous offset in order to repeat the last offset. This reduces the time frame of uncommitted offsets making the client aware of potential rebalance activities on the broker side.
The default of Max. Number of Polled Records is 500. This is vastly higher than the numbers I used in my examples. While this is only one of the several parameters offered by the adapter to define the desired batch size, this does not necessarily mean that each batch contains 500 messages. As the adapter is constantly fetching new messages, chances are it will work on whatever new messages just came in within a very short time frame on the broker side. Still, if you are very concerned about duplicates, you may consider reducing this setting, especially when skipping failed messages.
Since the processing time of the messages is also a big factor, the number of fetched records should be aligned to the the same. In case messages are processed very fast, it makes sense to fetch more messages at once. If the processing time is very slow, fetching fewer messages at once seems to be a good idea. The additional round trip to the broker is negligible, if the time in between (spent processing) is very long. But it gives a chance to realize problems earlier.
If you experience regular rebalance activities, you should investigate on its cause. It may be caused by unfortunate configuration on either broker or consumer side (or both). As an example, it could be due to session timeouts, which is part of the next section below.
Each consumer comes with a processing and a heartbeat thread. The job of the heartbeat thread is to keep the connection alive and signal the liveliness to the broker. If no heartbeat is detected by the broker within the Session Timeout, the broker disconnects the consumer from its partitions and triggers a rebalance. It is recommended to set the Heartbeat Interval to less than 1/3 of the Session Timeout, so the client has at least three chances to reach the broker (i.e. to compensate for temporary network problems).
Kafka offers a setting max.poll.interval.ms to identify if the processing thread has died. If the processing time exceeds the configured value, the processing thread is assumed to have died: In this case the consumer is being disconnected from the broker and a rebalance takes place. Another (or a new) consumer connects to the topic partition and tries to re-process this message.
It is possible that the problem is not with the processing thread however, but the processing time simply exceeds the configured value. This can potentially lead to infinite retries (disconnects, rebalance ..), if the process continues to take longer than the configured max.poll.interval.ms.
Cloud Integration decided to sacrifice this mechanism to some extent to avoid these kind of problems (which may only occur late in production, if something changes (i.e. message sizes)) and for simplicity reasons. The impact of misconfiguration is quite high.
Instead, Cloud Integration sets this setting to 1 day, which is considered high enough to avoid infinite retries (in almost all cases).
Stored Kafka record headers are automatically transformed into message headers and can be used within an integration flow (if configured in the Allowed Header(s) field of the Runtime Configuration). The same is true for the following, additional headers:
The Kafka receiver adapter sends Kafka records (or batches) to exactly one topic (or partition). You can find detailed information about all possible parameters in the Configure the Kafka Receiver Adapter documentation.
The connection settings are identical to the sender side. Refer to the sender section above for further details.
The Processing tab allows you to define the topic to send messages to. This field also accepts a header (${header.myHeader}) or property (${property.myProperty}) reference to dynamically define the topic to send to during runtime. The Kafka record key can be defined by setting the header kafka.KEY upfront (i.e. using a Content Modifier). By setting the key of a record, you can influence the partition to send to. Same key means same partition, while the exact partition number is not important. You can also define the exact partition number with the help of the header kafka.PARTITION_KEY. The latter throws an exception, if the partition does not exist.
The Kafka receiver adapter can batch records to optimize network traffic. Batching usually happens during high load situations, as the producer does not wait infinitely for additional messages. It is possible to linger for a certain (short) period of time in case batching is more important than fast message processing. The Batch Size (in KB) operates on the uncompressed message sizes, optional compression happens afterwards.
The following compression algorithms are supported:
The record contains information about whether a message is compressed and which compression algorithm (of the above) is used. The Kafka consumer decompresses the record / batch automatically using the appropriate algorithm.
Kafka is not designed to handle large messages. It works best with messages that are huge in amount, but not in size. The broker can restrict the largest allowed record batch size (after compression) via message.max.bytes. Kafka does not put any restrictions on this setting, so it is capped at ~2GB (integer max. value). However, broker providers usually restrict this setting further (within a few megabytes, which makes a lot of sense). Check with your broker provider for more details.
The Kafka receiver adapter can restrict the max. uncompressed record batch size (before compression) via Max. Request Size (in KB). It is recommended to align this setting with the message.max.bytes of the broker. Sending requests to the broker, which exceed the broker limit, results in errors that are hard to detect and client retries. Cloud Integration limits the max. request size to 20MB.
Camel exchange headers are automatically transferred as Kafka record headers and vice versa. The following header types are supported (other types are skipped): String, Integer, Long, Double, Boolean, byte[]
Headers starting with Camel, org.apache.camel or kafka. are not propagated but filtered out.
Usually, the timestamp being transferred along with the record reflects the time when the record is sent. By setting the header kafka.OVERRIDE_TIMESTAMP, you can specify a custom timestamp instead. The value of this header needs to be of type java.lang.Long, which is somewhat inconvenient (i.e. when trying to send along the timestamp via common REST clients). There are simple options to convert the data type using a Content Modifier or a Script step in Cloud Integration.
Custom or human-readable date formats are not supported.
This section is not intended as a performance guide or anything close to it. Instead, I want to provide some "food for thought" in this context.
If the client needs to connect to the broker using SSL or SASL_SSL ("Connect with TLS"), the root certificate of the broker needs to be part of the tenant's keystore. If the certificate is missing, this usually results in error like below when trying to send a message to the broker:
com.sap.it.rt.adapter.http.api.exception.HttpResponseException: An internal server error occured: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target.
Usually, the certificate can easily be obtained by executing a TLS Connectivity Test directly from the tenant. Simply type in host and port of the broker, uncheck "Valid Server Certificate Required" and download the resulting certificates. Only the root certificate needs to be imported into the tenant's keystore.
Remember to restart (or redeploy) already deployed kafka-related integration flows afterwards to take effect.
If the provided broker host does not exist, the integration flow deployment fails with the following error message:
[CAMEL][IFLOW][EXCEPTION] : org.apache.kafka.common.KafkaException: Failed to construct kafka <consumer / producer> [CAMEL][IFLOW][CAUSE] : Cause: org.apache.kafka.common.config.ConfigException: No resolvable bootstrap urls given in bootstrap.servers
Double-check for typos or revert to your broker provider to get the correct connection details.
Trying to send a record to a non-existing topic results in an error unless the broker is configured to create topics automatically (auto.create.topics.enable). If automatic topic creation is disabled, any attempt to send a message leads to the following error after the configured Max. Blocking Time (in s), which defaults to 30 seconds:
com.sap.it.rt.adapter.http.api.exception.HttpResponseException: An internal server error occured: Topic <topic name> not present in metadata after 30000 ms..
Create the topic on broker side or correct your configuration to solve this problem.
Trying to consume records from a non-existing topic leads to infinite client retries. These retries are not visible to the user, but create some load on the tenant and the broker. Due to current limitations, the integration flow appears to be running successfully (The Integration Flow is deployed successfully). Since the topic does not exist, you won't see any messages being processed. You can revert to the Kafka Connectivity Test to check the connectivity upfront. It will list up to 200 topics, which are available on the broker side. The Kafka Connectivity Test is mentioned in the blog post Cloud Integration – Monitoring Polling Status in Kafka Sender Adapter.
Sending a single message that is larger than the max. allowed size the broker / topic accepts (message.max.bytes) results in the following exception:
com.sap.it.rt.adapter.http.api.exception.HttpResponseException: An internal server error occured: The request included a message larger than the max message size the server will accept..
It is highly recommended to check the message.max.bytes setting of the broker and set the Max. Request Size (in KB) correspondingly (notice the different unit (bytes vs. KB)) in the receiver adapter. Of course, you will still see an error trying to send a message that is too large, but the size-verification now happens on the client-side and avoids putting additional, unnecessary load on the broker. The error message changes slightly:
com.sap.it.rt.adapter.http.api.exception.HttpResponseException: An internal server error occured: The message is <number of bytes> bytes when serialized which is larger than <configured max. request size in bytes>, which is the value of the max.request.size configuration..
If you require to send larger messages, you need to adjust the broker (or topic) configuration first and adapt the receiver adapter configuration afterwards.
There might be cases when a single message is smaller than the max. allowed size of the broker / topic, but a batch of several of these messages are larger than the max. allowed size. This situation leads to the following error:
com.sap.it.rt.adapter.http.api.exception.HttpResponseException: An internal server error occured: Expiring <n> record(s) for <topic>-<partition>:<time> ms has passed since batch creation.
The client tries to send the message many times before this error appears, putting considerable load on client and broker. It is highly recommended to align the message.max.bytes setting of the broker with the Max. Request Size (in KB) of the receiver adapter. The adapter makes sure that the Batch Size (in KB) is configured smaller than the Max. Request Size (in KB). Following this recommendation helps you to avoid this error situation completely.
The design of the consumer group (being the integration flow id) avoids any conflicts between integration flows on the tenant. The same is not true across tenants (by choice).
Isolating tenants is not desirable in all cases. If you want to migrate content from one tenant to another tenant, you can easily export and import the content. The new tenant is able to join the existing consumer group and continue where the previous tenant stopped.
However, this means you need to take care when importing content as-is on any tenant. If the integration flow id remains unchanged (can be defined during import), a consumer is able to join an existing consumer group. This is not different from many other adapters (e.g. SFTP, MAIL, AMQP ..) polling data from somewhere.
The following features are not yet available and may come with a later release of the adapter:
The adapter can currently not connect to brokers, which are not exposed via the Internet. This limitation is based on a lack of proxy support of the kafka library itself, which itself is based on a lack of proxy support of the used java NIO library (https://bugs.openjdk.java.net/browse/JDK-8199457).
This blog post started with some basics about Kafka and continued with basic configuration settings and requirements to connect to a Kafka broker. I hope this helps you to get a smooth start when integrating your Kafka cluster with Cloud Integration. We looked at several complex topics and internals, which might be of interest to you and which is useful together with the official Kafka documentation. The troubleshooting section highlights a few of the most common error messages and how to resolve or avoid them. Finally, I outlined some of the current limitations and condensed the most relevant information (for the technical readers upon you) in the last two sections.
[1] Kafka: The Definitive Guide - Neha Narkhede, Gwen Shapira, and Todd Palino (First Edition)
Introduction
Apache Kafka is an event streaming platform. It is often described as a publish/subscribe messaging system or as a distributed commit log. Kafka stores key-value messages (records) in topics that can be partitioned. Each partition stores these records in order, using an incremental offset (position of a record within a partition). Records are not deleted upon consumption, but they remain until the retention time or retention size is met on the broker side. Until then, messages may be re-processed again and again by one or multiple (different) consumers.
To optimize efficiency, the underlying messaging protocol is TCP-based. Messages are usually grouped together to reduce network overhead, which results in larger network packages.
Kafka runs on a cluster of one or more servers (brokers) and all topics and partitions are distributed (and replicated) across these brokers. This architecture allows you to distribute the load and increase the fault-tolerance. Each broker that is part of a cluster acts as a leader for certain partitions and acts as a replica for partitions being led by other brokers.

Kafka Cluster [1]
Records & Batches
Kafka messages or records are key-value pairs (with a timestamp). The optional key is typically used to send similar records to one partition. Records that are produced for the same topic and the same partition are usually grouped into batches to reduce the network overhead which results in larger network packages. Batches may be compressed to reduce their size and optimize data transfer. The additional CPU time required for compression is often negligible.
Topics & Partitions
Kafka records are sent to (and retained in) so-called topics. Kafka topics are divided into one or several partitions. Records are assigned an (incremental) offset within a partition and are retained until the defined retention time or retention size on the broker is reached. This prevents infinite retention of records on the broker. The records may be consumed multiple times and without any limitations as long as they are retained on the broker.
Topic names are restricted as follows:
- [a-zA-Z0-9._-]
- max. 249 characters
- use either . (dot) or _ (underscore), but not both to avoid collisions

Topic with 4 partitions [1]
The Kafka Sender Adapter
The Kafka sender adapter fetches Kafka record batches from one or more topics. You can find detailed information about all possible parameters in the Configure the Kafka Sender Adapter documentation.
The Connection tab contains basic connectivity-settings to address the broker. You can maintain more than one bootstrap server to support the case of broker-related unavailability. Cloud Integration offers SASL and Client Certificate authentication options. In Kafka terms, this translates to the following supported security protocols: SSL, SASL_PLAINTEXT and SASL_SSL with supported SASL mechanisms PLAIN and SCRAM-SHA-256.

Sender Adapter - Connection tab
Note: Any change of key or trust material requires a restart (or redeployment) of the integration flow.
SASL
In order to enable SASL_PLAINTEXT
- the broker has to support SASL_PLAINTEXT (listener configuration, keystore and truststore configuration ..)
- Authentication has to be set to SASL
- Connect with TLS has to be disabled
- Credential Name needs to point to a deployed credential
In order to enable SASL_SSL
- the broker has to support SASL_SSL (listener configuration, keystore and truststore configuration ..)
- the Fully-Qualified Domain Name (FQDN) of the broker has to fit to the Common Name (CN) or Subject Alternative Name (SAN) of its certificate (hostname verification)
- Authentication has to be set to SASL
- Connect with TLS has to be enabled
- Credential Name needs to point to a deployed credential
- the root certificate of the broker has to be added to the keystore (you can usually use the TLS Connection Test to download the certificate)
Client Certificate
In order to enable SSL
- the broker has to support SSL (listener configuration, keystore and truststore configuration ..)
- the FQDN of the broker has to fit to the CN or SAN of its certificate (hostname verification)
- Authentication has to be set to Client Certificate
- Private Key Alias needs to point to a Key Pair in the keystore
- the root certificate of the broker has to be added to the keystore (you can usually use the TLS Connection Test to download the certificate)
The Processing tab allows you to specify the topic(s) to subscribe to. You can configure one or more (comma-separated) topics, as well as a simple pattern like MyTopic* to consume from all topics starting with MyTopic (e.g. MyTopic1, MyTopic2).

Sender Adapter - Processing tab
Consumer Groups
Kafka consumers are typically part of a consumer group. Different consumer groups are separated from each other, even if they consume from the same topics.
The integration flow id (initial integration flow name upon creation) is used as consumer group. This ensures that other integration flows cannot interfere with record consumption. Other integration flows may consume from the same topics, but they will do so within their own, individual consumer group.
If a consumer group loses all of its consumers, the broker will remember consumer groups and their last consumed offsets per partition for a defined period of time (broker setting: offsets.retention.minutes). This way, a consumer can reconnect to its group to continue where the group stopped (i.e. downtimes, software updates, un- or redeployments).
If a consumer group is not yet (first deployment) or not anymore (offset retention) known to the broker, a new consumer starts from the latest (newest) offset. It does not consume all records of a topic from the beginning, but listens for new records only. The consumer might also encounter a situation in which the last-known offset (and subsequent ones) does not exist anymore (partition size exceeded threshold or record is expired, both broker configurations). In such situations, the consumer also resets to the latest offset (auto.offset.reset = latest).
No support for user-configurable consumer groups
Cloud Integration does not offer user-defined consumer group definitions in the sender adapter (e.g. in a text field). This is a conscious decision based on several reasons:
- Avoid negative impact of productive scenarios from the sidelines by other groups or people working on other integration flows.
- This can happen by accident and might not be unlikely, in case you define own consumer groups in all integration flows.
- Copying integration flows can be very critical! (conflicts may start immediately or delayed, as outlined further below)
- We lose the clear relation between integration flow and consumer group. This relation is usually desirable (especially in exceptional / support cases)
- You might claim that messages have not been processed and neither you, nor Cloud Integration support can be certain that no other integration flow has been processing the same (maybe for some time, e.g. in a conflict-case).
- There is no historic data of previous configurations and involved integration flows might already been gone.
- Conflicting configuration of different integration flows might not be visible immediately.
- There is only one consumer per topic partition (per consumer group), but there might be more consumer threads on client side waiting to get a chance to bind to an empty topic partition.
- Depending on the context, the problem might only appear after software update, tenant restart (or crash), integration flow un- or re-deployments, broker rebalancing etc. (and maybe it takes several restarts, since the consumer threads will compete with each other)
- The current behavior is conflict-free across integration flows on one tenant.
If you are in need of a specific consumer group name, you can always create the integration flow with exactly the required name.
Parallel Consumption
Within one consumer group, only one Kafka consumer may fetch records from one partition. Topics can be consumed in parallel, if
- the topic is divided into multiple partitions and
- several consumers are spawned within the consumer group.
Example: Topic A with 3 partitions (0, 1 and 2)
Records from this topic can be consumed in parallel by up to 3 consumers (one per partition).
Cloud Integration allows you to define the number of Parallel Consumers within a range of 1 to 25. This configuration scales with the number of worker nodes. To distribute the load across these nodes, it is necessary to configure a value of Parallel Consumers of less than the number of partitions. Otherwise one worker node creates the necessary consumers and hooks onto all partitions before a second worker node has the chance to do the same.
Example: Topic B with 24 partitions and Parallel Consumers set to 24 (3 worker nodes)
All 3 worker nodes spawn 24 processing threads, while most probably only the first node is able to connect to all 24 partitions. The other worker nodes do not consume any messages from Topic B. To balance this fairly across all 3 worker nodes, Parallel Consumers need to be set to 8. As the number of worker nodes may change over time, it makes sense to leave 'some room' for later, i.e. to set the configuration to 5. This means that one consumer might read from several partitions, until there are more consumers than partitions.
For the above reason, it makes sense to leave this setting on its default value unless performance requirements and test results show a need to raise it. In many cases (depending on the scenario, of course), a single consumer is perfectly capable to handle many partitions and messages.
Retry Handling
A message fetched by the Kafka sender adapter may fail during processing. The sender may either skip the failed message and continue with the next offset (at most once semantics unless the consumer dies within auto.commit.interval.ms) or retry the failed message (at least once semantics within the record retention on the broker). The option to retry a failed message can potentially lead to infinite retries. Therefore, it is recommended to handle failed messages in an exception subprocess.
The Kafka sender adapter offers additional configuration options to define retry intervals and reconnect intervals. High-frequent retries can put considerable load onto the broker (and to Cloud Integration), which can be avoided by increasing the intervals (meaning: slowing down).
The retry behavior is not easy to comprehend at first. Let us look behind the curtains with some examples. In the examples, we consider one topic with 6 partitions. Trying to consume a message from partition 6 leads to an error.

Retry Behavior: Example 1
The single consumer C1 fetches messages from all 6 partitions. As defined, it fails when trying to process a record fetched from partition 6. Since Error Handling is set to Retry Failed Message, the consumer disconnects from the broker and waits for the configured Max. Retry Backoff (in ms) before reconnecting. In the meantime, no record is consumed from any partition.
Now we add a second worker node to the picture.

Retry Behavior: Example 2
Both consumers C1 and D1 are part of the same consumer group. Hence, they collaborate with the message consumption of the topic, each working on 3 partitions. Once D1 fails and disconnects, a rebalance takes place on broker side and C1 takes over the other 3 partitions in addition. As C1 also fails when trying to process a message of partition 6, it potentially leaves all partitions unattended until D1 reconnects. This depends on the configured Max. Retry Backoff (in ms) and the time the broker needs to finish the rebalance.
The exact same situation may occur on a single node with Parallel Consumers set to 2 as depicted below.
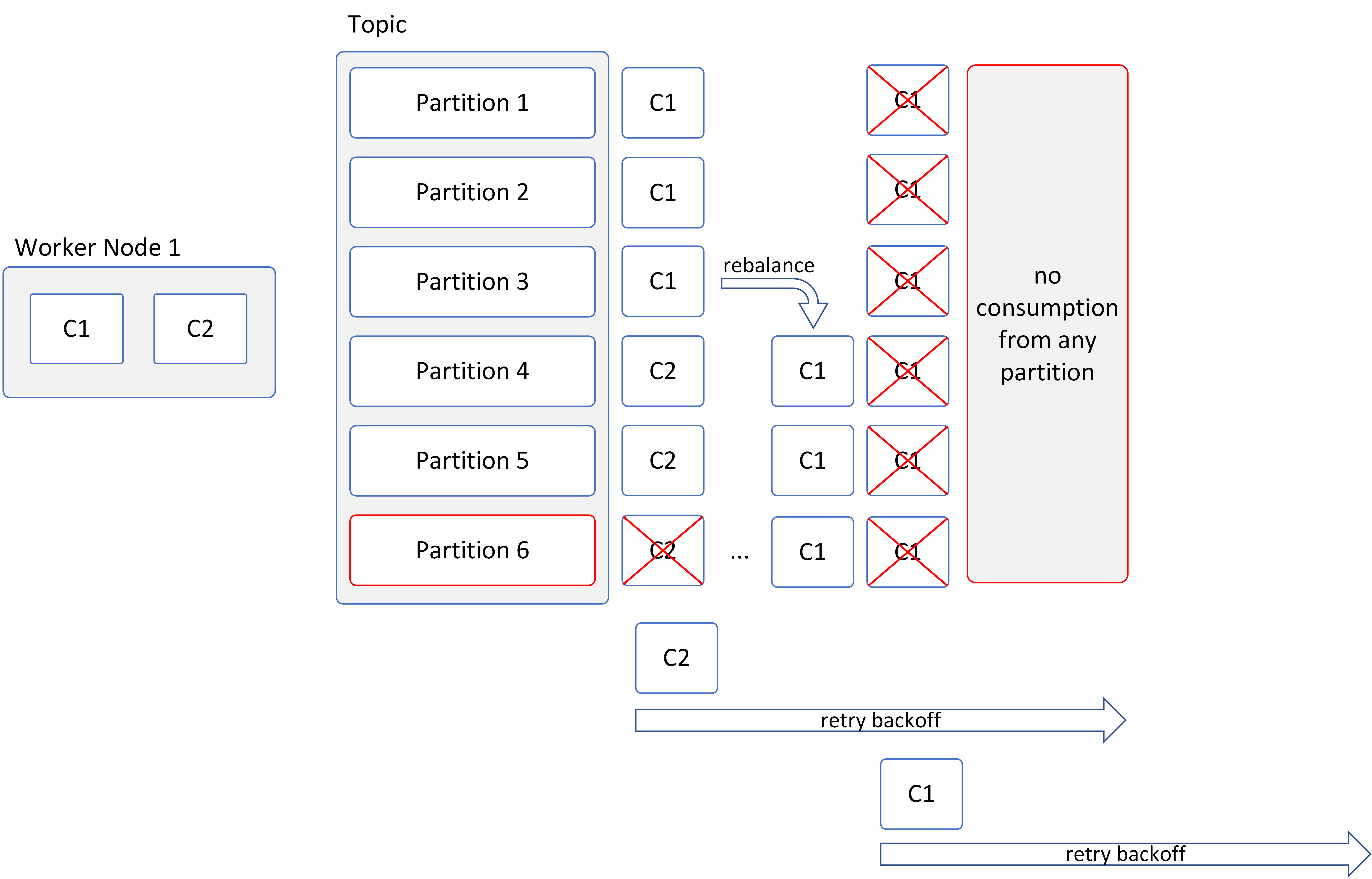
Retry Behavior: Example 3
In reality, the setup usually looks more complex. The last example tries to provide a glimpse on that.

Retry Behavior: Example 4
I outlined a single worker with 6 parallel consumers. We can multiply this by additional worker nodes to complicate this further, but I think you get the picture. This time I reduced the Max. Retry Backoff (in ms) so that C6 is back and ready for re-processing within 2 rebalances. In such a case, C5 and C6 take turns to work on the last two partitions. It also shows that the continuous failure of partition 6 also affects the processing of partition 5, while the processing of the other partitions continues to work without any problems.
Based on what we saw, Max. Retry Backoff (in ms) is not necessarily the time gap before the next processing attempt. This is the case in Example 1, but not in the other examples. If another consumer is available, it takes over in the meantime and the observed retry interval might just equal the rebalance time on the broker.
Fetch Optimization
The Kafka sender adapter fetches records in batches. It offers numerous configuration options to tweak the min. and max. sizes to fetch, limit the number of polled records and set a max. waiting time. Even when misconfigured, the sender adapter always tries to progress, i.e. it fetches a record even if it is larger than the defined fetch.max.bytes. But it does not add additional messages to the fetched batch, if the max. size has already been exceeded.

Sender Adapter - Advanced tab
Automatic Commit
Consumed records / offsets will be committed automatically in 5 second intervals (auto.commit.interval.ms). If a message fails in between (with retry enabled), the last successfully executed offset is immediately committed. If the consumer shuts down (e.g. undeployment of the integration flow), it commits the last offset that was processed successfully.
This leaves one potential gap: If a rebalance happens on the broker side (e.g. a consumer / worker node crashes), there is a time window of up to 5 seconds (+ processing time) of uncommitted offsets. These records are processed again, once the consumer is up and running again, since the broker is unaware of the processing state on the client.
To illustrate this concept and potential consequences in more detail, I prepared a few examples. For simplicity reasons we just assume a topic with a single partition only.
Example 1: batch size of 1 without rebalance
In the first example the kafka consumer is configured to
- skip failed messages
- Max. Number of Polled Records is set to 1

Auto Commit - Example 1
With each call to poll, the consumer receives a single message. Independent of its processing status (successful or failed), it continues with the next offset (remember: consumer is configured to skip failed messages) and it has to reach out to the broker to get a new record. A commit of consumed offsets will take place during a poll attempt exceeding the 5 second interval. As the message processing time of Record 5 takes longer, the offsets are not committed immediately after 5 seconds, but a little later, as the message processing time affects the time of the next poll attempt. As the commit succeeds, the broker now knows the consumed offsets for this partition and consumer group.
Example 2: batch size of 1 with rebalance
This case is very similar to the first one, as the consumer is configured in the same way. We now introduce a rebalance taking place on the broker side, kicking the consumer out of its group.

Auto Commit - Example 2
While the consumer is processing Record 4, the consumer is kicked out of its consumer group. The consumer only realizes this, however, the next time it interacts with the broker, which is during the next poll attempt. Being kicked out, it is unable to commit the offset. It will reconnect, get the latest committed offset from the broker and has to start over. The 5 second commit interval will also start over, so the next attempt to commit may only happen after a minimum of 5 additional seconds.
This example illustrates that even a batch size of 1 can lead to several duplicates due to the auto commit interval. Still, the rebalance is realized by the consumer rather quickly due to the frequent poll() calls to the broker.
Example 3: batch size of 5 without rebalance
Fetching more messages at once from the broker means reaching out to the broker less frequent (which is the whole point in the first place). This saves roundtrips, but also delays the commit operation. The client is still configured to skip failed messages, but the Max. Number of Polled Records is increased to 5.

Auto Commit - Example 3
This time, the client receives 5 messages with the first poll and it interates over these messages before polling again. In this example, the client finished processing these 5 messages just shortly before the 5 second commit interval exceeds, so the subsequent call to poll() does not trigger any offset commit action. Instead, the client receives another set of 5 messages and will work on those before contacting the broker again. After Record 10 finished processing, the auto commit interval is clearly exceeded, so an offset commit is triggered and the broker finally knows the consumption state of this topic partition and consumer group.
Now that we know that the batch size has a significant influence on the offset commit, let us introduce problems in the last example.
Example 4: batch size of 4 with rebalance
To make matters worse, there is a rebalance on broker side now. Consumer configuration remains the same as described in the previous example.

Auto Commit - Example 4
This sequence is the same as before with the exception of a rebalance shortly after the second poll. Unfortunately, the client is not aware of this until it reaches out to the broker at a much later point in time. When the client finally tries to commit the 10 records it has processed so far, it realizes it was kicked out of the group. Being unable to commit, it has to start over. Within the time frame of this example, the broker never persists any consumer offset resulting in many duplicates.
What now?
In my attempt to sketch the worst case scenarios, you might think this is all bad, but not necessarily. First and foremost, these examples served to elaborate on the commit behavior of the adapter. Secondly, I hope to sensitize you on some corner cases, which may occur at times. This way you can be prepared or even adapt your configuration upfront to minimize the impact.
I intentionally configured the consumer to skip failed messages. This is not the default configuration and undesired in most cases. If you do not skip failed messages, any message processing failure would immediately result in a commit attempt of the previous offset in order to repeat the last offset. This reduces the time frame of uncommitted offsets making the client aware of potential rebalance activities on the broker side.
The default of Max. Number of Polled Records is 500. This is vastly higher than the numbers I used in my examples. While this is only one of the several parameters offered by the adapter to define the desired batch size, this does not necessarily mean that each batch contains 500 messages. As the adapter is constantly fetching new messages, chances are it will work on whatever new messages just came in within a very short time frame on the broker side. Still, if you are very concerned about duplicates, you may consider reducing this setting, especially when skipping failed messages.
Since the processing time of the messages is also a big factor, the number of fetched records should be aligned to the the same. In case messages are processed very fast, it makes sense to fetch more messages at once. If the processing time is very slow, fetching fewer messages at once seems to be a good idea. The additional round trip to the broker is negligible, if the time in between (spent processing) is very long. But it gives a chance to realize problems earlier.
If you experience regular rebalance activities, you should investigate on its cause. It may be caused by unfortunate configuration on either broker or consumer side (or both). As an example, it could be due to session timeouts, which is part of the next section below.
Heartbeat
Each consumer comes with a processing and a heartbeat thread. The job of the heartbeat thread is to keep the connection alive and signal the liveliness to the broker. If no heartbeat is detected by the broker within the Session Timeout, the broker disconnects the consumer from its partitions and triggers a rebalance. It is recommended to set the Heartbeat Interval to less than 1/3 of the Session Timeout, so the client has at least three chances to reach the broker (i.e. to compensate for temporary network problems).
Max. Processing Time
Kafka offers a setting max.poll.interval.ms to identify if the processing thread has died. If the processing time exceeds the configured value, the processing thread is assumed to have died: In this case the consumer is being disconnected from the broker and a rebalance takes place. Another (or a new) consumer connects to the topic partition and tries to re-process this message.
It is possible that the problem is not with the processing thread however, but the processing time simply exceeds the configured value. This can potentially lead to infinite retries (disconnects, rebalance ..), if the process continues to take longer than the configured max.poll.interval.ms.
Cloud Integration decided to sacrifice this mechanism to some extent to avoid these kind of problems (which may only occur late in production, if something changes (i.e. message sizes)) and for simplicity reasons. The impact of misconfiguration is quite high.
Instead, Cloud Integration sets this setting to 1 day, which is considered high enough to avoid infinite retries (in almost all cases).
Message Headers
Stored Kafka record headers are automatically transformed into message headers and can be used within an integration flow (if configured in the Allowed Header(s) field of the Runtime Configuration). The same is true for the following, additional headers:
| Header | Type | Description |
| kafka.TOPIC | String | The topic from where the message originated. |
| kafka.PARTITION | Integer | The partition where the message was stored. |
| kafka.OFFSET | Long | The offset of the message. |
| kafka.KEY | Object | The key of the message, if configured. |
| kafka.TIMESTAMP | Long | The timestamp of the message. |
Kafka Receiver Adapter
The Kafka receiver adapter sends Kafka records (or batches) to exactly one topic (or partition). You can find detailed information about all possible parameters in the Configure the Kafka Receiver Adapter documentation.
The connection settings are identical to the sender side. Refer to the sender section above for further details.

Receiver Adapter - Connection tab
The Processing tab allows you to define the topic to send messages to. This field also accepts a header (${header.myHeader}) or property (${property.myProperty}) reference to dynamically define the topic to send to during runtime. The Kafka record key can be defined by setting the header kafka.KEY upfront (i.e. using a Content Modifier). By setting the key of a record, you can influence the partition to send to. Same key means same partition, while the exact partition number is not important. You can also define the exact partition number with the help of the header kafka.PARTITION_KEY. The latter throws an exception, if the partition does not exist.

Receiver Adapter - Processing tab
Batching
The Kafka receiver adapter can batch records to optimize network traffic. Batching usually happens during high load situations, as the producer does not wait infinitely for additional messages. It is possible to linger for a certain (short) period of time in case batching is more important than fast message processing. The Batch Size (in KB) operates on the uncompressed message sizes, optional compression happens afterwards.
Compression
The following compression algorithms are supported:
- gzip
- lz4
- snappy
- zstd
The record contains information about whether a message is compressed and which compression algorithm (of the above) is used. The Kafka consumer decompresses the record / batch automatically using the appropriate algorithm.
Max. Message Size
Kafka is not designed to handle large messages. It works best with messages that are huge in amount, but not in size. The broker can restrict the largest allowed record batch size (after compression) via message.max.bytes. Kafka does not put any restrictions on this setting, so it is capped at ~2GB (integer max. value). However, broker providers usually restrict this setting further (within a few megabytes, which makes a lot of sense). Check with your broker provider for more details.
The Kafka receiver adapter can restrict the max. uncompressed record batch size (before compression) via Max. Request Size (in KB). It is recommended to align this setting with the message.max.bytes of the broker. Sending requests to the broker, which exceed the broker limit, results in errors that are hard to detect and client retries. Cloud Integration limits the max. request size to 20MB.
Message Headers
Camel exchange headers are automatically transferred as Kafka record headers and vice versa. The following header types are supported (other types are skipped): String, Integer, Long, Double, Boolean, byte[]
Headers starting with Camel, org.apache.camel or kafka. are not propagated but filtered out.
Custom Timestamp
Usually, the timestamp being transferred along with the record reflects the time when the record is sent. By setting the header kafka.OVERRIDE_TIMESTAMP, you can specify a custom timestamp instead. The value of this header needs to be of type java.lang.Long, which is somewhat inconvenient (i.e. when trying to send along the timestamp via common REST clients). There are simple options to convert the data type using a Content Modifier or a Script step in Cloud Integration.
Custom or human-readable date formats are not supported.
Performance
This section is not intended as a performance guide or anything close to it. Instead, I want to provide some "food for thought" in this context.
- Do you have a performance problem? Have you clearly defined your performance expectations / KPIs? Performance needs to be measured to assert that the requirements are met and to be prepared for adjustments.
- Performance is not bound to the client and its configuration only (i.e. Cloud Integration), but it is highly influenced by other factors:
- broker (hardware, configuration)
- network
- topic partitioning
- record size
- record distribution
- etc.
- Do not simply set the number of Parallel Consumers to its upper limit of 25 assuming this would improve performance. It might, but it might also degrade your performance (and stability) depending on your context. This article outlines that this setting scales with the number of worker nodes and our recommendation to leave some room. Start adjusting the configuration options, if you cannot meet your performance requirements (which requires clear KPIs and measurements as stated before).
- There is no one-size-fits-all wrt. client configuration. Use the offered "advanced" configuration options of both sender and receiver adapters and monitor, if your performance improves as expected. If you don't have a performance problem, stick to the defaults.
Troubleshooting
Missing Broker Certificate
If the client needs to connect to the broker using SSL or SASL_SSL ("Connect with TLS"), the root certificate of the broker needs to be part of the tenant's keystore. If the certificate is missing, this usually results in error like below when trying to send a message to the broker:
com.sap.it.rt.adapter.http.api.exception.HttpResponseException: An internal server error occured: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target.
Usually, the certificate can easily be obtained by executing a TLS Connectivity Test directly from the tenant. Simply type in host and port of the broker, uncheck "Valid Server Certificate Required" and download the resulting certificates. Only the root certificate needs to be imported into the tenant's keystore.
Remember to restart (or redeploy) already deployed kafka-related integration flows afterwards to take effect.
Incorrect Host Configuration
If the provided broker host does not exist, the integration flow deployment fails with the following error message:
[CAMEL][IFLOW][EXCEPTION] : org.apache.kafka.common.KafkaException: Failed to construct kafka <consumer / producer> [CAMEL][IFLOW][CAUSE] : Cause: org.apache.kafka.common.config.ConfigException: No resolvable bootstrap urls given in bootstrap.servers
Double-check for typos or revert to your broker provider to get the correct connection details.
Missing Topic
Trying to send a record to a non-existing topic results in an error unless the broker is configured to create topics automatically (auto.create.topics.enable). If automatic topic creation is disabled, any attempt to send a message leads to the following error after the configured Max. Blocking Time (in s), which defaults to 30 seconds:
com.sap.it.rt.adapter.http.api.exception.HttpResponseException: An internal server error occured: Topic <topic name> not present in metadata after 30000 ms..
Create the topic on broker side or correct your configuration to solve this problem.
Trying to consume records from a non-existing topic leads to infinite client retries. These retries are not visible to the user, but create some load on the tenant and the broker. Due to current limitations, the integration flow appears to be running successfully (The Integration Flow is deployed successfully). Since the topic does not exist, you won't see any messages being processed. You can revert to the Kafka Connectivity Test to check the connectivity upfront. It will list up to 200 topics, which are available on the broker side. The Kafka Connectivity Test is mentioned in the blog post Cloud Integration – Monitoring Polling Status in Kafka Sender Adapter.
Message Too Large
Sending a single message that is larger than the max. allowed size the broker / topic accepts (message.max.bytes) results in the following exception:
com.sap.it.rt.adapter.http.api.exception.HttpResponseException: An internal server error occured: The request included a message larger than the max message size the server will accept..
It is highly recommended to check the message.max.bytes setting of the broker and set the Max. Request Size (in KB) correspondingly (notice the different unit (bytes vs. KB)) in the receiver adapter. Of course, you will still see an error trying to send a message that is too large, but the size-verification now happens on the client-side and avoids putting additional, unnecessary load on the broker. The error message changes slightly:
com.sap.it.rt.adapter.http.api.exception.HttpResponseException: An internal server error occured: The message is <number of bytes> bytes when serialized which is larger than <configured max. request size in bytes>, which is the value of the max.request.size configuration..
If you require to send larger messages, you need to adjust the broker (or topic) configuration first and adapt the receiver adapter configuration afterwards.
Batch Too Large
There might be cases when a single message is smaller than the max. allowed size of the broker / topic, but a batch of several of these messages are larger than the max. allowed size. This situation leads to the following error:
com.sap.it.rt.adapter.http.api.exception.HttpResponseException: An internal server error occured: Expiring <n> record(s) for <topic>-<partition>:<time> ms has passed since batch creation.
The client tries to send the message many times before this error appears, putting considerable load on client and broker. It is highly recommended to align the message.max.bytes setting of the broker with the Max. Request Size (in KB) of the receiver adapter. The adapter makes sure that the Batch Size (in KB) is configured smaller than the Max. Request Size (in KB). Following this recommendation helps you to avoid this error situation completely.
No Tenant Separation
The design of the consumer group (being the integration flow id) avoids any conflicts between integration flows on the tenant. The same is not true across tenants (by choice).
Isolating tenants is not desirable in all cases. If you want to migrate content from one tenant to another tenant, you can easily export and import the content. The new tenant is able to join the existing consumer group and continue where the previous tenant stopped.
However, this means you need to take care when importing content as-is on any tenant. If the integration flow id remains unchanged (can be defined during import), a consumer is able to join an existing consumer group. This is not different from many other adapters (e.g. SFTP, MAIL, AMQP ..) polling data from somewhere.
Current Limitations
The following features are not yet available and may come with a later release of the adapter:
- Schema registry support
- Cloud Connector support
- Integration Flow monitor does not reflect all connection problems of a consumer (some improvements are on its way as described in Cloud Integration – Monitoring Polling Status in Kafka Sender Adapter)
- ksqlDB support
- SASL/OAUTHBEARER
- Consumption of arbitrary offsets
- Consuming a certain partition only (as in contrast to consume from a topic)
- Transactional delivery
The adapter can currently not connect to brokers, which are not exposed via the Internet. This limitation is based on a lack of proxy support of the kafka library itself, which itself is based on a lack of proxy support of the used java NIO library (https://bugs.openjdk.java.net/browse/JDK-8199457).
TL;DR
- Security protocols SSL, SASL_SSL and SASL_PLAINTEXT supported with sasl mechanisms PLAIN and SCRAM-SHA-256.
- "Connect with TLS" requires the root certificate of the broker in the tenant's keystore. Run a TLS Connectivity Test to obtain it.
- Any change of key or trust material requires a restart (or redeployment) of the integration flow.
Consumer (Sender adapter)
- Consumer Group == Integration Flow ID (~ name)
- auto.offset.reset = latest
- Parallel Consumers (1 to 25) scale with the number of worker nodes; do not set this value to the number of partitions to leave room to scale (i.e. divide it by the number of worker nodes for fair load distribution)
- auto.commit.interval.ms = 5000
- max.poll.interval.ms = 86400000 (1 day)
- key.deserializer = StringDeserializer
- value.deserializer = ByteArrayDeserializer
Producer (Receiver adapter)
- Topic field can be set dynamically (${header...} or ${property...})
- Kafka key can be defined by manually setting the header kafka.KEY upfront (e.g. using a Content Modifier)
- Partition can be defined by setting kafka.PARTITION_KEY
- Custom timestamp can be defined by setting kafka.OVERRIDE_TIMESTAMP (datatype java.lang.Long)
- max.request.size is limited to 20MB
- buffer.memory = 32MB (per endpoint)
- key.serializer = StringSerializer
- value.serializer = ByteArraySerializer
Conclusion
This blog post started with some basics about Kafka and continued with basic configuration settings and requirements to connect to a Kafka broker. I hope this helps you to get a smooth start when integrating your Kafka cluster with Cloud Integration. We looked at several complex topics and internals, which might be of interest to you and which is useful together with the official Kafka documentation. The troubleshooting section highlights a few of the most common error messages and how to resolve or avoid them. Finally, I outlined some of the current limitations and condensed the most relevant information (for the technical readers upon you) in the last two sections.
References
[1] Kafka: The Definitive Guide - Neha Narkhede, Gwen Shapira, and Todd Palino (First Edition)
- SAP Managed Tags:
- SAP Integration Suite,
- Cloud Integration
Labels:
35 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
273 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
326 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
403 -
Workload Fluctuations
1
Related Content
- Top Picks: Innovations Highlights from SAP Business Technology Platform (Q1/2024) in Technology Blogs by SAP
- What’s New in SAP Datasphere Version 2024.8 — Apr 11, 2024 in Technology Blogs by Members
- How to build SOAP service in SAP Cloud Integration in Technology Blogs by Members
- HTTP receiver adapter - inbuilt retry option in Technology Q&A
- Nested JSON to SAP HANA Tables with SAP Integration Suite in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 12 | |
| 10 | |
| 10 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 4 |