
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP HANA Calculation View Union Node Data Pruning ...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-11-2021
12:02 AM
Introduction:
I am working for a customer and their business is mainly in the oil and gas industry. As you may be aware of SAP's solution IS-Oil (Industry Specific – oil & gas) is tailor-made for the oil and gas industry. With the emerging of S/4HANA many-core module database tables have been re-designed or new tables are made available for simplicity, redundancy, and performance reasons. So, we are going to take an example based on two important tables which are MATDOCOIL and MATDOCOIL_INDEX.
MATDOCOIL: It is a standard SAP Transparent table in SAP IS-Oil application, which mainly contains additional converted quantities, unit of measures, and Quantity conversion parameters. Up to 60 additional quantities (ADQNTP*) and unit of measure (MSEHI*) can be stored into separate table columns.
MATDOCOIL_INDEX: It is a standard SAP Transparent table in SAP IS-Oil application, the main purpose of this table is to support SAP HANA-optimized aggregation for additional oil quantities in MATDOCOIL through new indexing format; this means that individual additional quantities are stored in separate columns within the table MATDOCOIL and are then referenced within table MATDOCOIL_INDEX. Example: entry in the table with key MSEHI = ‘KG’ and MSEHI_INDEX = 3 means additional converted quantity in KG unit of measure is stored in the columns ADQNTP3, MSEHI3 of the table MATDOCOIL
What is union data pruning?
The simple answer is the technique for the union view node that helps to optimize the query execution at the union node level.
Requirement (Scenario):
To build a material inventory report using SAP HANA calculation views with the user having an option to select a required unit of measure using HANA Input Parameter and Display the additional converted quantity along with a unit of measure. As mentioned in the introduction MATDOCOIL table contains additional converted quantities into different units of measures based on the configuration e.g. KG, BBL, LB, UG6, TON, etc.
Problem:
Additional converted quantity, units of measure are stored in different columns ADQNTP*, MSEHI* in MATDOCOIL table. Hence transpose of columns into rows is required. This is achieved using creating multiple projection nodes (Projection_1 for ADQNTP1, MSEHI1, Projection_2 for ADQNTP2, MSEHI2, and so forth) mapped DATA SOURCES into UNION node in HANA Calculation view with Input Parameters like for unit of measure, etc.
GOOD NEWS! Because we were able to meet the requirement for the report. Reporting is showing the expected numbers, BUT WHAT ABOUT PERFORMANCE? Are the business users happy? The big answer is NO. Often in the analytics projects, many a time no one calls out good(great) performance as a requirement it's overlooked and later stage work is done as performance improvement. So why not do from Day1 and Be pro-active? 😊
Now we have the requirement and the problem. Let’s JUMP into the main topic now i.e. UNION Pruning to get the best performance with small effort. Broadly there are two options: Option 1. Configuration Table Based Union Pruning. Option 2. Constant Mapping Based Union Pruning. I will try my best to discuss both options with pros, cons, and use cases related to our requirements.
Transpose of Columns into Rows Design.

Option 1. Configuration Table Based Union Pruning.
- As the name says it based on a configuration table so there is a need to create a table (.hdbtable) or database view with standard configuration columns. Entries in this table help the HANA engine in run-time to decide on union node which data sources (projection_1, projection_2, etc.) to consider for search rather NOT looking at all projections.
- WITHOUT union pruning HANA calculation view EXPLAIN PLAN and Execution time.
- Performance Measure.
- Column search is performed on ALL data sources (projections).
- Execution time: ~556 ms for 1000 records.

- Column Search ~70 secs and Memory ~6.1 GB


- Performance Measure.
- WITH union pruning HANA calculation view Steps, EXPLAIN PLAN, and Execution time.
- Create a pruning configuration table.

- Maintain the entries in the configuration table. This can be done using manual inserts, CSV upload, stored procedure, etc. If you notice column INPUT which is maintained for different union data sources (projection_1, projection2, projection_22, etc.) and LOW_VALUE column contains different units of measure. This configuration table helps the engine to perform a search only on a specific data source(projection) based on LOW_VALUE which is MSEHI1 and filtered using HANA Input Parameter.

- Add Projection node with filter after Union node. On column MSEHI1. This is also maintained on the pruning configuration table.
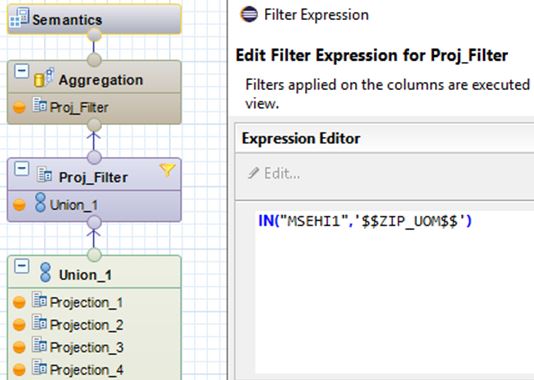
- To enable pruning on the HANA Calculation view add a pruning configuration table created in the Advanced section setting. Note: If the configuration table is empty then the HANA calculation view will execute as normal WITHOUT union pruning as discussed earlier.

- Performance Measure.
- Column search is performed on ONLY data sources (projections) based on configuration table match found. In this case its on Projection_1 for UoM = ‘BB6’. You see in EXPLAIN PLAN with one search performed only.
- Execution time: ~343 ms for 1000 records. Around 38% improvement seen on 1000 records and it bumps up exponential with high data volume like ~50-60%

- Instead of Column search, it's Analytical with an execution time of ~9.6 secs and 1/3rd of memory reduction from ~6.1 GB to ~2 GB.


Option 2. Constant Mapping Based Union Pruning.
- As the name says it is based on constant mapping. Yes, its union node constant mapping column and filtering it to avoid unwanted search on other data sources (projection nodes).
- WITHOUT union pruning HANA calculation view EXPLAIN PLAN and Execution time. Different from the above example because performed in a development environment.
- Performance Measure.
- Column search is performed on ALL data sources (projections).
- Execution time: ~107 ms for 1000 records.

- Performance Measure.
- WITH constant mapping union node pruning HANA calculation view Steps, EXPLAIN PLAN, and Execution time.
- Create stored procedure with input for a unit of measure HANA input parameter and Output to get MSEHIINDEX value. MATDOCOIL_INDEX table used.

- Create HANA Input Parameter of Type Derived from Procedure/Scalar UDF and use the above-stored procedure. Map the Input Parameters correctly.

- Create a CONSTANT column in union node with values 1,2, 3..10..11..20.. etc. based on the ADQNTP*, MSEHI* mappings.

- Add Projection node with filter after Union node. On constant column PRUNING_INDEX. This step enables pruning.

- Performance Measure.
- Column search is performed for one data source (projection_1) without filter condition due to constant mapping in the union node.
- Execution time: ~52 ms for 1000 records. Around 51% improvement seen on 1000 records and it bumps up exponential with high data volume like ~60%
- Low memory consumption (Not shown here but was checked in Plan Viz)

Conclusion:
- The union pruning technique helps a LOT in performance gain for the union node with many data sources(projections) to reduce execution time and memory consumption.
- MATDOCOIL based reports can leverage pruning powerful techniques along with the MATDOCOIL_INDEX table to build optimized data models.
- Union pruning using configuration table needs table and values should be maintained correctly to see the benefit and avoiding data issues. Union pruning using constant needs to make sure constant values are correctly defined and how to invoke them.
- Both union pruning techniques are powerful and the deciding factor must be based on the requirements.
References:
- SAP Managed Tags:
- SQL,
- SAP HANA,
- SAP HANA studio
Labels:
2 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
295 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
341 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
419 -
Workload Fluctuations
1
Top kudoed authors
| User | Count |
|---|---|
| 35 | |
| 25 | |
| 17 | |
| 13 | |
| 8 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 6 |