
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Spatial Anonymization with SAP HANA Cloud
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-05-2021
1:20 PM

Spatial Anonymization: How to hide personal data while keeping valuable insights. [1]
When dealing with personal location data, you quickly run into questions about data privacy and anonymization. Due to the global pandemic and the many different approaches for doing contact tracing, this topic got quite some media coverage during the last year. Luckily, for COVID-19 contact tracing there are working mechanisms in place, which do not involve the use of any location data. The German Corona-Warn-App for example leverages the exchange of Bluetooth tokens.
However, there are many scenarios where you would like to leverage existing location data in your company. Due to privacy concerns, opt-out of users or legislations such as GDPR, you are often not able to process this data, leverage its value and gain further insights. An example may be targeted marketing activities, where often times the exact location, that identifies an individual is not too important, but it is rather helpful to know the rough 'area' of an event. The technical question is now, how do you appropriately generalize an exact location to an area, that keeps certain guarantees in terms of anonymization?
As you may already know, SAP HANA offers support for Spatial Data Types as well as algorithms for Data Anonymization. In this blog, I will not go into the details of both - at least not more than necessary. There are plenty of blogs already existing that describe the concepts behind (just follow the links for more information). Instead I will focus on how to combine the spatial processing with the anonymization concepts and show you how to do Spatial Anonymization within SAP HANA.
I will try to explain the approach along an example. The issue here is, that any example involves a data set. And this per definition is a privacy sensitive dataset - otherwise anonymization does not make much sense. It lies in the nature of those datasets that they are hard to find online (...at least the ones, that I would use for a blog entry). So as a result, the example that I am presenting to you, may look a bit constructed.
That's because it really is.
The Dataset
I will be working with a dataset from a scientific publication [2]. The dataset comprises Foursquare check-ins of roughly 10 months in the cities of New York and Tokyo. I will be using the New York part for now. Along with the check-in data, there comes a dataset with a few details of some of the users, that did the check-in.
The data fields, that we are going to use are the following:
| Field | Type | Description |
| RECORD_ID | INTEGER | An ID, that I created during import |
| USER_ID | INTEGER | Link to user profile |
| LOC4326 | ST_GEOMETRY(4326) | Location of the check-in |
| UTC_TIME | TIMESTAMP | Time of the check-in |
Then there is a second data set containing some data for some user profiles:
| Field | Type | Description |
| USER_ID | INTEGER | Unique ID of the user |
| GENDER | NVARCHAR(6) | male/female |
| TWITTER_FRIENDS | INTEGER | Number of Twitter friends |
| TWITTER_FOLLOWER | INTEGER | Number of Twitter followers |
As you can see, this dataset already looks pretty anonymous. So let's construct a wild story.
The Constructed Story
Let's assume I have access to this dataset - maybe I am a Data Scientist working at the company. And let's also assume that the user profile data is a bit richer and actually contains at least the Twitter handle of the respective person. And of course, I am evil - that's the salt every good story needs.
At the restaurant on the table next to me, someone is talking about some really tasty cookies, that person has at home. I can see that this person is checking-in to Foursquare.
Picture this scene. (via imgflip)
I really need to get the Twitter handle of that person to send a tweet, that I know someone, who would love to try these cookies. I know the time and the location of the check-in and the gender of that person. Since I do have access to the check-in database, it will be easy for me to filter out the respective check-in and retrieve the profile data of that person! *evil laughter*
The Solution
Sounds constructed? Maybe. However, re-identification is an issue and has been shown in real-life scenarios - such as already in 2006 with search records: https://en.wikipedia.org/wiki/AOL_search_data_leak
So what can the owner of the dataset do to prevent this kind of attacks while still maintaining the value of the data itself? In a real-world scenario you could think of me being the Data Scientist and the owner being the Database Administrator. The administrator would love to keep all data access restricted, whereas the Data Scientist just want access to literally EVERYTHING. Wouldn't it be a good deal to provide a dataset, that is safe-to-use while still keeping insights and correlations?
One way to achieve this is to generalize data. So instead of showing a specific location, we just provide a rough area and instead of showing a specific timestamp, we provide a timespan. SAP HANA has a built-in anonymization algorithm, called k-Anonymity, that automatically generalizes data while giving certain guarantees with regards to anonymization.
The easiest is to explain this with our example: When I apply k-Anonymity with the parameter k=3 and apply the same query for time, location and gender on the result set, I am guaranteed to retrieve at least 3 check-in records.
While there is plenty of material out there, explaining how this works on SAP HANA with numerical or categorical data, I will show you today, how to additionally get the location and time dimension into the algorithm.
A Spatial Hierarchy
That's really the crux of the matter here! In order to use a database field for anonymization, you need to define a hierarchy on the data. For spatial data, there are of course some obvious hierarchies. For the location of the SAP Headquarters a possible hierarchy would be:
Exact Location > Walldorf (City) > Baden-Württemberg (State) > Germany (Country)
This kind of hierarchy has (at least) two drawbacks:
- It is not data-driven and you have to manually model all the hierarchies as part of your data
- It is static and not fine granular. Each step of generalization results in a major loss of information.
A data-driven way of defining a hierarchy on location data is to use so called Discrete Global Grid Systems (DGGS) or - a bit simpler - Geohashes.
Luckily, and not coincidentally, SAP HANA offers in-database handling of Geohashes for HANA2 SPS05 and HANA Cloud. You can generate Geohashes from geometries and translate them back to points or geometries.
Let's generate a Geohash for the SAP Headquarters:
SELECT
ST_GeomFromText('POINT(8.642057 49.293432)', 4326).ST_GeoHash()
FROM DUMMYThe resulting string is: u0y0ktsgn98z2pkqr5tt
So, that's a Geohash. A string of length 20, that can be reverted into a point, that is approximately at the same location like the originating point. This format can for example be used to exchange location information as a string representation and is helpful for programming APIs.
But how can we use this to define a hierarchy on our locations? Geohashes have an incredible valuable property. If you truncate them and leave away some characters at the end, the location just gets more imprecise.
Let's look at the first 5 characters as an example: u0y0k defines a rectangle. u0y0 is another rectangle, that is guaranteed to contain the first rectangle. This way the Geohashes give us a purely data-driven location hierarchy.
With our example:
u0y0ktsgn98z2pkqr5tt > ... > u0y0ktsgn98z > ... > u0y0kts > ... > u0 > u
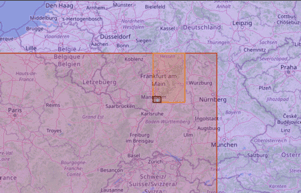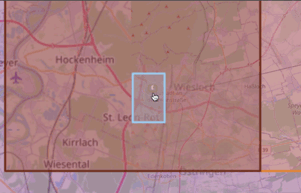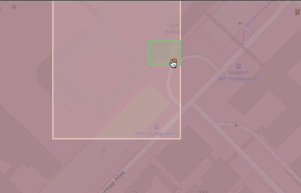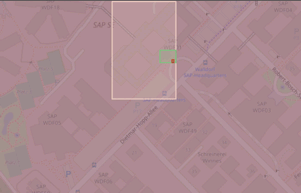
Spatial Hierarchy for the SAP Headquarters defined by Geohashes
The Actual Implementation
Well, then. Now we just need to put the pieces of our puzzle together, create the hierarchies and hand them over to our k-Anonymity algorithm.
First let's construct our base data set by joining the check-ins with the user profiles. We create a view, that we can use for anonymization.
CREATE OR REPLACE VIEW NYC_LINKED_CHECKINS AS
(
SELECT
nc.*,
nu.GENDER,
nu.TWITTER_FOLLOWER,
nu.TWITTER_FRIENDS
FROM NYC_CHECKINS nc
JOIN NYC_USER nu ON nc.USER_ID = nu.USER_ID
);Now, that we know about the magic of Geohashes, the spatial hierarchy gets REALLY easy. We need to create a stored function, that receives a value (i.e. a Geohash) and a level parameter and returns the generalized Geohash according to the level of generalization.
CREATE OR REPLACE FUNCTION GEOHASH_HIERARCHY
(
value NVARCHAR(20),
level INTEGER
)
RETURNS outValue NVARCHAR(20)
AS
BEGIN
outValue := LEFT(value, 20 - level);
END;Next thing, we need to take care about, is generalizing the time dimension. My naive approach here is to build the following hierarchy:
yyyy-mm-dd hh:mm:ss > yyyy-mm-dd hh:mm:00 > ... > yyyy-mm-dd 00:00:00 > .. > yyyy-01-01 00:00:00
So, with each step, we are cutting away the most fine granular time unit. From seconds, to minutes, to hours, and so on. Due to the implementation of the TO_TIMESTAMP function in SAP HANA, that also accepts partial time strings, we can do it the following way.
CREATE OR REPLACE FUNCTION TIMESTAMP_HIERARCHY
(
value TIMESTAMP,
level INTEGER
)
RETURNS outValue TIMESTAMP
AS
BEGIN
DECLARE ts_string NVARCHAR(27) = TO_NVARCHAR(value);
IF level = 0 THEN
outValue := TO_TIMESTAMP(ts_string);
ELSEIF level = 1 THEN
outValue := TO_TIMESTAMP(LEFT(ts_string, 16));
ELSEIF level = 2 THEN
outValue := TO_TIMESTAMP(LEFT(ts_string, 13));
ELSEIF level = 3 THEN
outValue := TO_TIMESTAMP(LEFT(ts_string, 10));
ELSEIF level = 4 THEN
outValue := TO_TIMESTAMP(LEFT(ts_string, 7));
ELSEIF level = 5 THEN
outValue := TO_TIMESTAMP(LEFT(ts_string, 4));
ELSEIF level = 6 THEN
outValue := '';
END IF;
END;Finally, we can create the view, that is doing the actual anonymization. For each field in the view, we need to determine the hierarchy, that is used for anonymization as a parameter. For time and location we use the functions, that we have defined above and for the gender, we just hardcode the embedded hierarchy (essentially this says to either show the gender if possible or not).
CREATE VIEW NYC_CHECKINS_3ANON (RECORD_ID, UTC_TIME, GEOHASH, GENDER)
AS
(
SELECT
RECORD_ID,
UTC_TIME,
LOC4326.ST_GeoHash() AS GEOHASH,
GENDER
FROM NYC_LINKED_CHECKINS
)
WITH ANONYMIZATION
(
ALGORITHM 'K-ANONYMITY' PARAMETERS '{"data_change_strategy": "restricted", "k":3, "loss": 0.2}'
COLUMN RECORD_ID PARAMETERS '{"is_sequence":true}'
COLUMN UTC_TIME PARAMETERS '{"is_quasi_identifier":true, "hierarchy":{"schema":"FOURSQUARE","function":"TIMESTAMP_HIERARCHY","levels":6}}'
COLUMN GEOHASH PARAMETERS '{"is_quasi_identifier":true, "hierarchy":{"schema":"FOURSQUARE","function":"GEOHASH_HIERARCHY","levels":19}}'
COLUMN GENDER PARAMETERS '{"is_quasi_identifier":true,"hierarchy":{"embedded":[["male"],["female"]]}}'
);To use this view, we need to initialize it with a so-called REFRESH statement.
REFRESH VIEW NYC_CHECKINS_3ANON ANONYMIZATION;And that was really it. We've prepared a view for doing spatial anonymization!
We can check the output of our view and observe the anonymized data:
SELECT TOP 100 * , ST_GeomFromGeoHash(GEOHASH, 4326) AS AREA
FROM NYC_CHECKINS_3ANON
ORDER BY RAND()The algorithm kept the gender information, but decided to provide only the month information instead of the exact timestamp (note that the day is set to 01) and only the 6-character Geohash. The map preview on the right side gives you an idea of the degree of spatial generalization.

Anonymized Check-in Data
Using the Anonymized Data
Let's get back to our constructed story: I have been at that Japanese Restaurant (lat: 40.7294418, lon: -73.989344) and have seen a male person at around 2012-04-14 06:35:00 UTC Time.
With the original data it is easy to look that up. Neither my GPS nor my watch are exact - but I am a Data Scientist and can add some uncertainty into my query. In this case, I am querying a 10-minute time window and an area of 100m around my location.
SELECT RECORD_ID, USER_ID, UTC_TIME, LOC4326, GENDER
FROM NYC_LINKED_CHECKINS
WHERE
GENDER = 'male' AND
UTC_TIME BETWEEN '2012-04-14 06:30:00' AND '2012-04-14 06:40:00' AND
LOC4326.ST_DISTANCE(ST_GeomFromText('POINT(-73.989344 40.7294418)', 4326)) < 100And here it is. I do have exactly one resulting record. USER_ID = 54 is the profile, that I need to check for further personal details.

Querying non-anonymized data results in 1 exact match
Now, my admin realized the mis-use and exchanged the original dataset with the one that we anonymized with k-Anonymity. Since we set the parameter k=3, we expect to get at least 3 records with a similar query. Since we are now dealing with (monthly) ranges and regions, the query has to be slightly adapted.
SELECT *
FROM NYC_CHECKINS_3ANON
WHERE
GENDER = 'male' AND
UTC_TIME = '2012-04-01 00:00:00' AND
ST_GeomFromGeoHash(GEOHASH, 1000004326).ST_Contains
(
ST_GeomFromText('POINT(-73.989344 40.7294418)', 1000004326)
) = 1The result of this query looks tremendously different. This time, I am receiving 62 records!

Querying anonymized data with the same parameters
You can also see, that the area now covers East Village instead of only one certain location. Note, that the checkin of user with user_id = 54 is still part of the data. It has not been removed. However, that one check-in, that evil me was looking for, is now hidden in 62 check-ins of male persons in East Village in the month of April.
Yet, the Data Scientist can still use this anonymized data to generate valuable insights, such as the profile of site visitors of time and location. The value of the data is not lost.
Summary
Anonymization and Data Privacy on data management level is real and respecting privacy concerns does not necessarily lead to major loss of information. With smart approaches, the value of data can be maintained, while decoupling it from personal information.
The unique value of SAP HANA lies in the combination of its Multi-model engines. Be it Graph or Spatial processing, Data Anonymization or Machine Learning - with interoperable engines you are able to get the maximum value out of your data in a safe and secure environment.
What you have seen above is not a step-by-step description and I expect you to run into the one or the other minor issue when replicating it with your SAP HANA Cloud Trial instance, where both - spatial processing and data anonymization - is on board. Most of these issues will be solvable - if this is not the case, please ask questions in the comments section below. In any case, I strongly encourage you to have a test drive with your own data!
Summing it all up, we only created 2 views and 2 functions: Anonymization does not have to be complex! Start using it today.
[1] Cover Photo by heylagostechie on Unsplash.
[2] Dingqi Yang, Daqing Zhang, Vincent W. Zheng, Zhiyong Yu. Modeling User Activity Preference by Leveraging User Spatial Temporal Characteristics in LBSNs. IEEE Trans. on Systems, Man, and Cybernetics: Systems, (TSMC), 45(1), 129-142, 2015. [PDF]
- SAP Managed Tags:
- SAP HANA Cloud,
- SAP HANA,
- SAP HANA multi-model processing,
- SAP HANA Spatial
Labels:
5 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
86 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
270 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,578 -
Product Updates
323 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
395 -
Workload Fluctuations
1
Related Content
- Enhanced Data Analysis of Fitness Data using HANA Vector Engine, Datasphere and SAP Analytics Cloud in Technology Blogs by SAP
- CAP LLM Plugin – Empowering Developers for rapid Gen AI-CAP App Development in Technology Blogs by SAP
- Enter the era of spatial computing for enterprise with SAP Build Code in Technology Blogs by SAP
- AI Foundation on SAP BTP: Q1 2024 Release Highlights in Technology Blogs by SAP
- SAP Datasphere News in March in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 11 | |
| 10 | |
| 10 | |
| 10 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 7 | |
| 6 |