
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Scripting import of multiple files into SAP HANA C...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Developer Advocate
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-24-2021
6:10 PM
Being the cloud-native product SAP HANA Cloud does not give you an access to the underlying OS shell and file system. Therefore it is not possible to load a file from the database server as you can do with on-prem SAP HANA. But through its broad data integration capabilities SAP HANA Cloud offers import and export data using popular cloud storage services.
In this post I show you steps done to import TPC-DS data files into my trial SAP HANA Cloud database's tables in a regular schema and share some of the gotchas. My database instance is hosted in
At the moment of writing this post Object Store service is only available in SAP BTP productive accounts, and I plan to return to that service another time. So, here I will use S3 service directly from AWS. At this moment S3 is available in AWS account's free tier for 12 months after an account creation.
Before we move on just a few words about the dataset and why.
The TPC Benchmark DS (TPC-DS) is "a decision support benchmark that models several generally applicable aspects of a decision support ...". While I am not going to use it for any benchmarking (which would not even make sense in the trial environment), I liked the fact that it provides the snowflake-modeled schema of a retail business's decision system. It is much closer to the real customer case, then most of the single-file datasets out there.
Instead of providing a data set, it provides two generators:
What's more the data generator allows you to create datasets of the different size, starting from 1GB of raw data. So, it is a volume that is nice to work with. I plan to play with it after this exercise too.
...in general:
To accomplish my goal I am using a command line more than UIs to make this text compact and to script repetitive task. This is more efficient when working with more files and bigger data, like in this exercise.
While all required command-line tools can be installed and used from any OS shell, here I am going to use the Linux-based AWS CloudShell service -- mostly for the performance reasons of moving generated files within the same region of the same cloud infrastructure.
AWS CloudShell is a free service, but with 1GB of persistent storage -- the limitation I needed to take into the consideration when generating files.
At the moment CloudShell is not available in AWS Frankfurt region
All code files are available in the SAP Tech Bytes repository: https://github.com/SAP-samples/sap-tech-bytes/tree/2021-02-22-saphanacloud-db-import-tpcds-datafiles....
You can create files following this post, you can copy their code from links provided in the post, or you can clone the code.
So, let's go.
Create a project folder
To make it consistent between different commands and scripts, and to make customizable for your needs let's create a file
Modify the file to set your own:
I used TPC-DS generator from https://github.com/gregrahn/tpcds-kit, because it can be compiled on MacOS too (but that's the different story).
In AWS CloudeShell run the following commands.
The
Now you should have TPC-DS data generator
If executed without any parameters
The approach I took was to generate a data file for each table listed in
I want the bucket to be close to my SAP HANA Cloud db instance, so I used a flag
To script the creation and movement of data files to S3 bucket I created an executable Bash script
...and execute it.
Let's check generated files and their total size in the bucket.
There are 25 files generated -- one for each target database table.
SAP HANA Cloud will use S3's REST API to get the data from the bucket. It will require an AWS user with an access key and required permissions.
It is a good idea to use an AWS user with a minimal permissions to read objects from the bucket.
Let's create a template file
...and a script
A copy of an access key is written to a file in the temporary directory and will be accessed during the execution of SQL statements to provide user's key+secret values.
Following steps could be done from SAP HANA Database Explorer or any other SQL client supporting SAP HANA Cloud. I will use command-line
For this activity we need to do following steps:
SAP HANA Clients should be installed in the default directory
I will use a flag
Let's check if we can connect to the database with this user key.
TPC-DS Kit provides a file
Logon to the database using
...and execute following statements.
The setup of trust follows defined steps described in https://help.sap.com/viewer/c82f8d6a84c147f8b78bf6416dae7290/2020_04_QRC/en-US/342122ab55684a20a2e07....
While still in an
If not, then let's create it with the name
Exit the
Now we need to create an entry for a public certificate of a virtual-hosted–style URI of the S3 bucket, which is
To do this programatically install
...and use it to retrieve the certificate for SSL access to HTTPS port 443.
Now that certificate is created in SAP HANA Cloud database, let's add it to the certificate collection
While I promised we are focusing on working with the command line, it is good to know that results the same can be achieved from SAP HANA Cloud Cockpit.
To script the import of 25 data files into corresponding database tables I created an executable Bash script
...and execute.
Bingo! The data is loaded and we can run some sample queries, like those generated by TPC-DS...
...but that's a kind of the exercise for another time!
Till next episode then,
-Vitaliy aka @Sygyzmundovych
In this post I show you steps done to import TPC-DS data files into my trial SAP HANA Cloud database's tables in a regular schema and share some of the gotchas. My database instance is hosted in
eu10 region of SAP Business Technology Platform (BTP), where infrastructure is provided by Amazon Web Services. So, I use Amazon Simple Storage Service (S3) as the cloud storage in this exercise.At the moment of writing this post Object Store service is only available in SAP BTP productive accounts, and I plan to return to that service another time. So, here I will use S3 service directly from AWS. At this moment S3 is available in AWS account's free tier for 12 months after an account creation.
Before we move on just a few words about the dataset and why.
What is TPC-DS?
The TPC Benchmark DS (TPC-DS) is "a decision support benchmark that models several generally applicable aspects of a decision support ...". While I am not going to use it for any benchmarking (which would not even make sense in the trial environment), I liked the fact that it provides the snowflake-modeled schema of a retail business's decision system. It is much closer to the real customer case, then most of the single-file datasets out there.
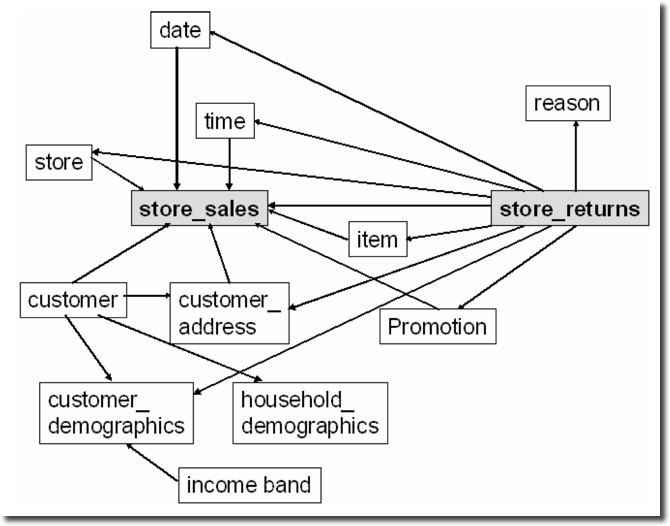
Store Sales Snow Flake Schema (source: The Making of TPC-DS)
Instead of providing a data set, it provides two generators:
- the data generator
dsdgen, which I used here, - the query generator
dsqgen, which could be nice if you want to practice knowledge gained during "The First Step Towards SAP HANA Query Optimization".
What's more the data generator allows you to create datasets of the different size, starting from 1GB of raw data. So, it is a volume that is nice to work with. I plan to play with it after this exercise too.
The flow of the exercise...
...in general:
- Generate TPC-DS data files using
dsdgenprogram. - Move files to S3 bucket using
awsclient. - Import data from files into SAP HANA Cloud database using
hdbsqlclient.
...and required tools
To accomplish my goal I am using a command line more than UIs to make this text compact and to script repetitive task. This is more efficient when working with more files and bigger data, like in this exercise.
If you are looking at the general introduction into the import of data into SAP HANA Cloud, then I would recommend to start with:
|
While all required command-line tools can be installed and used from any OS shell, here I am going to use the Linux-based AWS CloudShell service -- mostly for the performance reasons of moving generated files within the same region of the same cloud infrastructure.
AWS CloudShell is a free service, but with 1GB of persistent storage -- the limitation I needed to take into the consideration when generating files.
At the moment CloudShell is not available in AWS Frankfurt region
eu-central-1, so I had to open it in eu-west-1.
The code repository
All code files are available in the SAP Tech Bytes repository: https://github.com/SAP-samples/sap-tech-bytes/tree/2021-02-22-saphanacloud-db-import-tpcds-datafiles....
You can create files following this post, you can copy their code from links provided in the post, or you can clone the code.
git clone https://github.com/SAP-samples/sap-tech-bytes.git \
--branch 2021-02-22-saphanacloud-db-import-tpcds-datafiles-from-s3 \
~/Projects/saphc-hdb-import-tpcdsSo, let's go.
Create a file with project's environment variables
Create a project folder
~/Projects/saphc-hdb-import-tpcds:mkdir -p ~/Projects/saphc-hdb-import-tpcds
cd ~/Projects/saphc-hdb-import-tpcdsTo make it consistent between different commands and scripts, and to make customizable for your needs let's create a file
~/Projects/saphc-hdb-import-tpcds/env_tpcds.sh to store and configure environment variables.myTemp_folder=~/tmp
myProjects_folder=~/Projects
tpcds_kit_folder=${myProjects_folder}/tpcds-kit
tpcds_kit_tools_folder=${tpcds_kit_folder}/tools
tpcds_scale_factor=1
datasets_root_folder=~/Datasets
prefixObj=sf$(printf "%04d" ${tpcds_scale_factor})/data
aws_region=eu-central-1
s3bucket=tpcds4hdbc
aws_ro_s3user=S3TPC-reader
aws_key_file_folder=${myTemp_folder}
aws_key_file=${aws_ro_s3user}-access-key.json
HDB_USE_IDENT=AWSCloudShell
saphc_hdb_endpoint=8e1a286a-21d7-404d-8d7a-8c77d2a77050.hana.trial-eu10.hanacloud.ondemand.com:443Modify the file to set your own:
- SAP HANA Cloud database endpoint in
saphc_hdb_endpointvariable, and - globally unique S3 bucket name in
tpcds4hdbc.
Gotchas:
- Only a content of the user's home directory persisted between your AWS CloudShell sessions, so take this in considerations when setting folders structure
- AWS CloudShell virtual machines are changing internal IP addresses and therefore host names. To prevent issues with SAP HANA Clients, the
HDB_USE_IDENTenvironment variable is set.
- I have experienced the AWS CloudShell resetting the user session once in a while and it is causing the work folder and environment variables to be reset. You will find me adding
source ~/Projects/saphc-hdb-import-tpcds/env_tpcds.shat the beginning of every block of OS commands to make sure they are executed properly.
Generate TPC-DS data files and store them in S3
I used TPC-DS generator from https://github.com/gregrahn/tpcds-kit, because it can be compiled on MacOS too (but that's the different story).
In AWS CloudeShell run the following commands.
sudo yum install --assumeyes gcc make flex bison byacc git
source ~/Projects/saphc-hdb-import-tpcds/env_tpcds.sh
git clone https://github.com/gregrahn/tpcds-kit.git ${tpcds_kit_folder}
cd ${tpcds_kit_folder}/tools
make OS=LINUX
ls -l ds*The
make command will produce a lot of warnings, but it was Ok to ignore them and to move on.Now you should have TPC-DS data generator
dsdgen and query generator dsqgen available locally.
If executed without any parameters
./dsdgen will generate the smallest sample (1GB of size) with all data files in the current directory. The --scale option allows generating bigger samples, but even with 1GB we face the limitation of the CloudShell persistent storage.The approach I took was to generate a data file for each table listed in
tpcds.sql and to move (not copy) it to the S3 bucket defined as s3bucket variable in the file env_tpcds.sh. Remember to choose your own globally unique name for your S3 bucket!I want the bucket to be close to my SAP HANA Cloud db instance, so I used a flag
--region ${aws_region}, where I set this variable to eu-central-1 in env_tpcds.sh.cd ~/Projects/saphc-hdb-import-tpcds/
source ~/Projects/saphc-hdb-import-tpcds/env_tpcds.sh
aws s3 mb s3://${s3bucket} --region ${aws_region}
aws s3 ls ${s3bucket} --summarize
To script the creation and movement of data files to S3 bucket I created an executable Bash script
~/Projects/saphc-hdb-import-tpcds/gen_tpcds_s3_init.sh with the following code...#!/bin/bash
set -e
source ${0%/*}/env_tpcds.sh
log_file=${myTemp_folder}/${0##*/}__$(date +%Y%m%d%H%M).log
if [ ! -f ${tpcds_kit_tools_folder}/dsdgen ]; then
echo "You should have dsdgen installed and the environment configured in env_tpcds.sh!"
exit 1
fi
datasets_tpcds_files_folder=${datasets_root_folder}/tpcds-data/${prefixObj}/init
echo ${datasets_tpcds_files_folder}
mkdir -p ${datasets_tpcds_files_folder}
mkdir -p ${myTemp_folder}
touch ${log_file}
tables=$(grep table ${tpcds_kit_tools_folder}/tpcds.sql | grep --invert-match returns | cut -d' ' -f3)
for t in ${tables}
do
echo "Working on the table: "$t | tee -a ${log_file}
${tpcds_kit_tools_folder}/dsdgen -QUIET Y -FORCE \
-TABLE $t -SCALE ${tpcds_scale_factor} \
-DIR ${datasets_tpcds_files_folder} -DISTRIBUTIONS ${tpcds_kit_tools_folder}/tpcds.idx
for f in ${datasets_tpcds_files_folder}/*.dat; do
tail -3 $f >> ${log_file}
echo -e "$(wc -l $f) \n" >> ${log_file}
mv -- "$f" "${f%.dat}.csv"
done
aws s3 mv --recursive ${datasets_root_folder}/tpcds-data s3://${s3bucket}
done...and execute it.

Let's check generated files and their total size in the bucket.
source ~/Projects/saphc-hdb-import-tpcds/env_tpcds.sh
aws s3 ls s3://${s3bucket} --recursive --human-readable --summarize
There are 25 files generated -- one for each target database table.
Create a read-only user for the S3 bucket
SAP HANA Cloud will use S3's REST API to get the data from the bucket. It will require an AWS user with an access key and required permissions.
It is a good idea to use an AWS user with a minimal permissions to read objects from the bucket.
Let's create a template file
S3TPC-reader-inline-policy-template.json following the example from AWS documentation, but allowing only read access to the bucket...{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ListObjectsInBucket",
"Effect": "Allow",
"Action": "s3:ListBucket",
"Resource": "arn:aws:s3:::${s3bucket}"
},
{
"Sid": "AllowObjectRead",
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::${s3bucket}/*"
}
]
}...and a script
create_ro_s3user.sh to create a AWS user (S3TPC-reader) and its programatic access keys for an authentication:#!/bin/bash
source ${0%/*}/env_tpcds.sh
log_file=${myTemp_folder}/${0##*/}__$(date +%Y%m%d%H%M).log
mkdir -p ${myTemp_folder}
inline_policy_template=$(cat S3TPC-reader-inline-policy-template.json)
echo ${inline_policy_template//'${s3bucket}'/${s3bucket}} > ${myTemp_folder}/${aws_ro_s3user}-inline-policy.json
aws iam create-user --user-name ${aws_ro_s3user}
aws iam put-user-policy --user-name ${aws_ro_s3user} \
--policy-name inline_S3ReadTPCDSbucket \
--policy-document file://${myTemp_folder}/${aws_ro_s3user}-inline-policy.json
aws iam create-access-key --user-name ${aws_ro_s3user} > ${myTemp_folder}/${aws_ro_s3user}-access-key.json
cat ${myTemp_folder}/${aws_ro_s3user}-access-key.json
A copy of an access key is written to a file in the temporary directory and will be accessed during the execution of SQL statements to provide user's key+secret values.
Import the data from S3 bucket into SAP HANA Cloud tables
Following steps could be done from SAP HANA Database Explorer or any other SQL client supporting SAP HANA Cloud. I will use command-line
hdbsql within AWS CloudShell.For this activity we need to do following steps:
- Install SAP HANA Clients
- Create a database schema and tables to store the data
- Set host certificates required by SAP HANA
- Import data into tables
Install SAP HANA Clients
wget --no-cookies \
--header "Cookie: eula_3_1_agreed=tools.hana.ondemand.com/developer-license-3_1.txt" \
"https://tools.hana.ondemand.com/additional/hanaclient-latest-linux-x64.tar.gz" \
-P /tmp
tar -xvf /tmp/hanaclient-latest-linux-x64.tar.gz -C /tmp/
source ~/Projects/saphc-hdb-import-tpcds/env_tpcds.sh
/tmp/client/hdbinst --batch --hostname=${HDB_USE_IDENT}
SAP HANA Clients should be installed in the default directory
~/sap/hdbclient thanks to the flag --batch.For the general introduction into hdbsql I would recommend to start with tutorials: |
Add your database user to the SAP HANA Clients user store
I will use a flag
-i to interactively provide the password of my DBAdmin database user.source ~/Projects/saphc-hdb-import-tpcds/env_tpcds.sh
~/sap/hdbclient/hdbuserstore -i -H ${HDB_USE_IDENT} \
SET HANACloudTrial_DBAdmin ${saphc_hdb_endpoint} DBAdminLet's check if we can connect to the database with this user key.
~/sap/hdbclient/hdbsql -U HANACloudTrial_DBAdmin \
"SELECT Current_User FROM DUMMY"
Gotchas:
- As mentioned above, the use of
-H ${HDB_USE_IDENT}inhdbuserstorewill prevent loosing database user keys between AWS CloudShell sessions, as the internal host name is changing with each session.
- If you have problems connecting, then check my articles Secure connection from HDBSQL to SAP HANA Cloud and Allow connections to SAP HANA Cloud instance from selected IP addresses.
Create a schema and tables
TPC-DS Kit provides a file
tpcds-kit/tools/tpcds.sql with an ANSI-compliant SQL statements to create all required tables. I'll create a dedicated schema TPCDS for them.Logon to the database using
hdbsql and a created db user key.~/sap/hdbclient/hdbsql -A -U HANACloudTrial_DBAdmin...and execute following statements.
CREATE SCHEMA TPCDS;
SET SCHEMA TPCDS;
\input "/home/cloudshell-user/Projects/tpcds-kit/tools/tpcds.sql"
SELECT TABLE_NAME FROM TABLES WHERE SCHEMA_NAME='TPCDS';
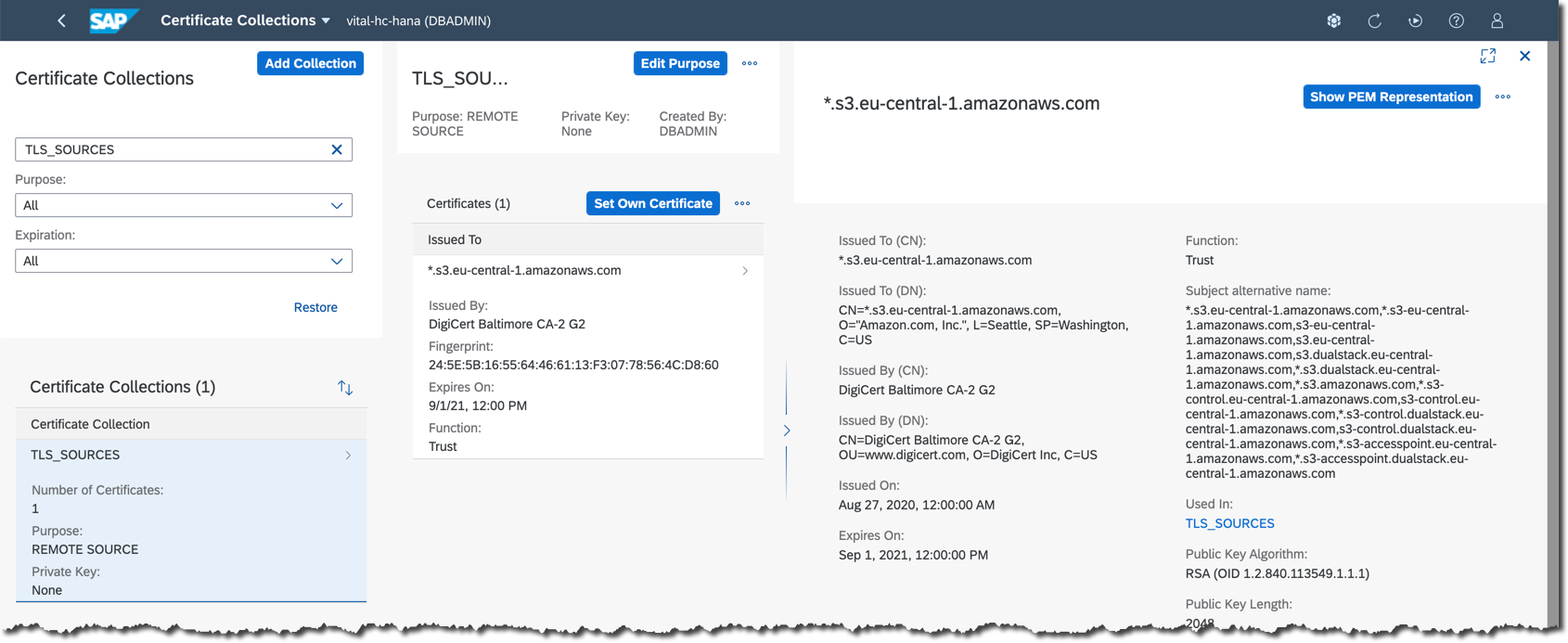
Setup certificates for S3 remote source in SAP HANA Cloud
The setup of trust follows defined steps described in https://help.sap.com/viewer/c82f8d6a84c147f8b78bf6416dae7290/2020_04_QRC/en-US/342122ab55684a20a2e07....
While still in an
hdbsql session connected to the database, check if a certificate collection (also called PSE, or Personal Security Environment) with REMOTE SOURCE purpose already exists.\al off
SELECT * FROM PSES WHERE PURPOSE='REMOTE SOURCE';If not, then let's create it with the name
TLS_SOURCES. But if it already exists, then skip the step of PSE creation and replace PSE name TLS_SOURCES in the SQL statements below with the one from your database instance.CREATE PSE TLS_SOURCES;
SET PSE TLS_SOURCES PURPOSE REMOTE SOURCE;Gotchas:
- Only one collection with unqualified purpose may exist. For more details see: https://help.sap.com/viewer/c82f8d6a84c147f8b78bf6416dae7290/2020_04_QRC/en-US/75d0cfec8e4f44c3a649d....
Exit the
hdbsql session to return to the OS shell.\quit
Now we need to create an entry for a public certificate of a virtual-hosted–style URI of the S3 bucket, which is
https://tpcds4hdbc.s3.eu-central-1.amazonaws.com in my case.To do this programatically install
openssl with yum in AWS CloudShell.sudo yum install --assumeyes openssl...and use it to retrieve the certificate for SSL access to HTTPS port 443.
source ~/Projects/saphc-hdb-import-tpcds/env_tpcds.sh
openssl x509 -in <(openssl s_client -connect ${s3bucket}.s3.${aws_region}.amazonaws.com:443 -prexit 2>/dev/null)
source ~/Projects/saphc-hdb-import-tpcds/env_tpcds.sh
~/sap/hdbclient/hdbsql -U HANACloudTrial_DBAdmin \
"CREATE CERTIFICATE FROM '$(openssl x509 -in <(openssl s_client -connect ${s3bucket}.s3.${aws_region}.amazonaws.com:443 -prexit 2>/dev/null))' COMMENT 'S3-${aws_region}';"
~/sap/hdbclient/hdbsql -A -U HANACloudTrial_DBAdmin \
"SELECT CERTIFICATE_ID, SUBJECT_COMMON_NAME, COMMENT FROM CERTIFICATES WHERE COMMENT='S3-${aws_region}';"
Now that certificate is created in SAP HANA Cloud database, let's add it to the certificate collection
TLS_SOURCES (or your existing certificate collection with the REMOTE SOURCE purpose).source ~/Projects/saphc-hdb-import-tpcds/env_tpcds.sh
export s3CertID=$(~/sap/hdbclient/hdbsql -U HANACloudTrial_DBAdmin -xa "SELECT CERTIFICATE_ID FROM CERTIFICATES WHERE COMMENT='S3-${aws_region}';")
~/sap/hdbclient/hdbsql -U HANACloudTrial_DBAdmin "ALTER PSE TLS_SOURCES ADD CERTIFICATE ${s3CertID};"
~/sap/hdbclient/hdbsql -U HANACloudTrial_DBAdmin -A "SELECT PSE_NAME, CERTIFICATE_ID, SUBJECT_NAME FROM PSE_CERTIFICATES WHERE PSE_NAME='TLS_SOURCES';"
While I promised we are focusing on working with the command line, it is good to know that results the same can be achieved from SAP HANA Cloud Cockpit.
Gotchas:
- It is important to note that the certificate is expiring on September 1st of this year (i.e. 2021). Certificates should be periodically checked and updated in real systems to keep applications running!
Import data from files in S3 bucket into SAP HANA Cloud tables
After all the setup and configuration are done it is time to import data into SAP HANA Cloud tables.
To script the import of 25 data files into corresponding database tables I created an executable Bash script
~/Projects/saphc-hdb-import-tpcds/imp_s3_hdbc_init.sh with the following code…#!/bin/bash
set -e
source ${0%/*}/env_tpcds.sh
log_file=${myTemp_folder}/${0##*/}__$(date +%Y%m%d%H%M).log
if [ ! -f ~/sap/hdbclient/hdbsql ]; then
echo "You should have ~/sap/hdbclient/hdbsql installed!"
exit 1
fi
keyid=$(jq -r ".AccessKey.AccessKeyId" ${aws_key_file_folder}/${aws_key_file})
keysecret=$(jq -r ".AccessKey.SecretAccessKey" ${aws_key_file_folder}/${aws_key_file})
tables=$(grep table ${tpcds_kit_tools_folder}/tpcds.sql | cut -d' ' -f3)
for t in ${tables}
do
echo -n "Inserting into $t"
query="IMPORT FROM CSV FILE 's3-${aws_region}://${keyid}:${keysecret}@${s3bucket}/${prefixObj}/init/${t}.csv' INTO TPCDS.${t} WITH FIELD DELIMITED BY '|' THREADS 2 FAIL ON INVALID DATA;"
# echo ${query//${keysecret}/'***'}
~/sap/hdbclient/hdbsql -U HANACloudTrial_DBAdmin -f "TRUNCATE TABLE TPCDS.${t}" >> ${log_file}
~/sap/hdbclient/hdbsql -U HANACloudTrial_DBAdmin -f "${query}" >> ${log_file}
echo ": " $(~/sap/hdbclient/hdbsql -U HANACloudTrial_DBAdmin -xa "SELECT COUNT(1) FROM TPCDS.${t}") " records"
done...and execute.
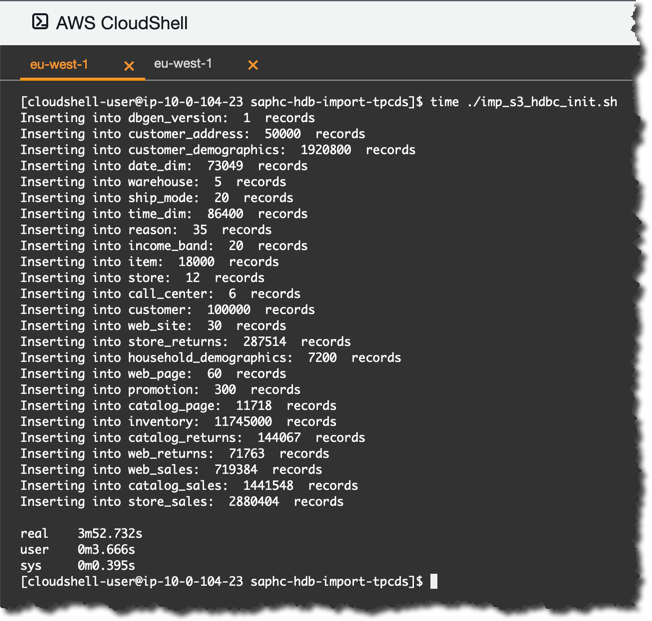
| For this step, I described as well an alternative approach: Import of multiple files into SAP HANA Cloud from a cloud storage (Amazon S3) using SAP Data Intelli.... |
Bingo! The data is loaded and we can run some sample queries, like those generated by TPC-DS...
SET SCHEMA TPCDS;
SELECT TOP 10
i_brand_id AS brand_id,
i_brand AS brand,
i_manufact_id,
i_manufact,
d_year,
sum(ss_ext_sales_price) AS ext_price
FROM
date_dim,
store_sales,
item,
customer,
customer_address,
store
WHERE d_date_sk = ss_sold_date_sk
AND ss_item_sk = i_item_sk
AND i_manager_id = 8
AND d_moy = 11
AND ss_customer_sk = c_customer_sk
AND c_current_addr_sk = ca_address_sk
AND substr( ca_zip, 1, 5 ) <> substr( s_zip, 1, 5 )
AND ss_store_sk = s_store_sk
GROUP BY
i_brand,
i_brand_id,
i_manufact_id,
i_manufact,
d_year
ORDER BY
ext_price DESC,
d_year DESC,
i_brand ASC,
i_brand_id ASC,
i_manufact_id ASC,
i_manufact ASC;
...but that's a kind of the exercise for another time!
| FYI, it is possible to import data from S3 buckets directly into the Relational Data Lake of SAP HANA Cloud, as described by sohit in Uploading S3 data into SAP HANA Cloud, Data Lake. |
Till next episode then,
-Vitaliy aka @Sygyzmundovych
- SAP Managed Tags:
- SAP HANA Cloud,
- SQL,
- Big Data
Labels:
8 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
86 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
270 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,578 -
Product Updates
323 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
395 -
Workload Fluctuations
1
Related Content
- Comprehensive Guideline to SAP VMS in Technology Blogs by Members
- Consuming CAPM Application's OData service into SAP Fiori Application in Business Application Studio in Technology Blogs by Members
- CAP LLM Plugin – Empowering Developers for rapid Gen AI-CAP App Development in Technology Blogs by SAP
- Trustable AI thanks to - SAP AI Core & SAP HANA Cloud & SAP S/4HANA & Enterprise Blockchain 🚀 in Technology Blogs by Members
- Replication flows: SAP Datasphere to Google BigQuery in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 11 | |
| 10 | |
| 10 | |
| 10 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 7 | |
| 6 |