In this blog, we'll look at an example of how performance was significantly improved by making some enhancements to both the integration flow (iFlow) and the APIs that provided data from SAP S/4HANA Cloud (S/4HC). New requirements often arise when developing an iFlow on SAP Cloud Platform Integration (CPI). As such, the additional enhancements are added incrementally to the existing iFlow. Sometimes the end result is an iFlow that is a fully functioning that technically meets the requirements of the business but performs sub-optimally due to redundant calls, inefficient logic or a combination of both.
In this scenario, we'll look at an integration that extracts product related information from S/4HC to a flat file for consumption in a 3rd party system. The developed iFlow uses a looping process which subsequently queries the Product Master API (
https://api.sap.com/api/API_PRODUCT_SRV/resource) by Storage Location and Plant for an initial list of products. A_ProductPlan was used to retrieve the list of Products as this entity contains both Storage Location and Plant. This initial product list is then iterated using a General Splitter to make a few other OData calls to fetch the required information for each record before the final file is formed after a Gather step.
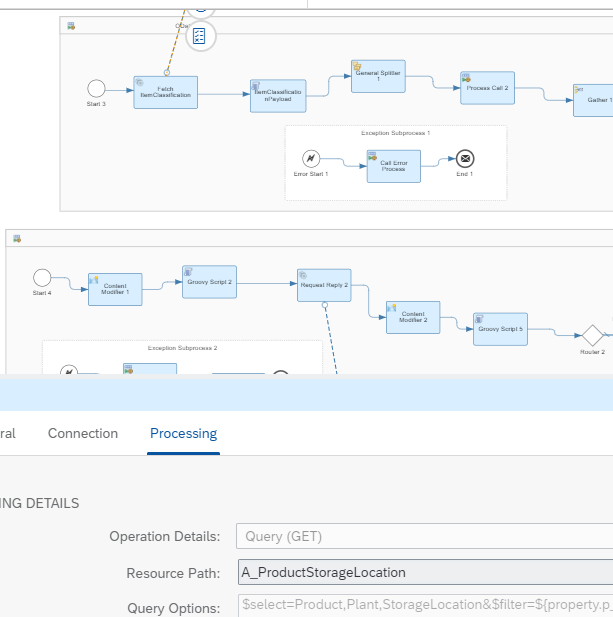
Figure 1: Initial iFlow layout
During the initial integration testing, feedback was provided that the integration needs capture the material creation date and also have a filter by product type (i.e. HAWA). Unfortunately, both of these fields are on the entity A_Product of the OData API --which cannot be expanded or filtered when using A_ProductStorageLocation. To meet the requirement, these fields were fetched in the first call of the sub process and if the current product wasn't of type (i.e. HAWA), the record was filtered out and no longer processed. (Figure 2)

Figure 2: Additional OData call
When the integration was tested, the file generated was validated as correct by the business teams. However, the integration took over 1 hr and 30 min to run (Figure 3).

Figure 3: Initial iFlow Execution Time
Although the integration started out using delivered whitelisted APIs from the SAP API hub, when the iFlow was analyzed further I realized that we may be able to consolidate the calls if we used a CDS view. One advantage to using a CDS view is that you can associate two or more CDS views together and expose as an External API and all attributes on the view become usable in the OData $filter expression. When you use an API from the API hub, you cannot $filter on an expanded entity set. In this case, a CDS view was created that joined I_ProductStorageLocation and I_Product. The CreationDate and ProductType from I_Product elements were used in addition to the other fields shown in Figure 4.

Figure 4: New CDS view
The new CDS view was added to the iFlow and was used for the initial product list. In addition, now that we are able to select CreationData and ProductType, we can retrieve the fields and also filter on them in the initial call as shown with the green circle in Figure 5. This also allowed the removal of the OData call for A_Product entirely as indicated with the red X in Figure 5.

Figure 5: New iFlow Design
The other change made that significantly improved performance was enabling parallel processing on the General Splitter (Figure 6). Of course, you wan to be sure your target system can handle the volume of calls due to the parallel calls. In addition, the order in which the records were collected was not important so there was not a dependency on this fact either.

Figure 6: Parallel Processing on General Splitter
The final change made on the iFlow was to enable HTTP Session reuse on the integration flow level (Figure 7).

Figure 7: HTTP Session Reuse
After making these changes and deploying the iFlow, the execution time was drastically reduced from 1hr 39min to just over 5 minutes -- a performance improvement of almost 95% (Figure 8).

Figure 8: New Processing Time
I hope you found this blog helpful.
Thanks,
Marty
