
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- CPI Integration Flow improvements - Example Flow u...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-08-2020
9:42 AM
To design a scenario that is working fine is one thing; but to design a scenario in such a way that it also fulfills non-functional requirements like performance and robustness is quite another thing.
In this blog, I want to show you how we could improve a datastore scenario that was already running fine.
Baseline
Let me start by explaining the scenario:
The integration flow forms a REST service that provides three functionalities: senders store JSON messages in a datastore via a POST call, a potential receiver of those messages calls the REST service to pick them up from the datastore via a GET call. Via a DELETE call, this receiver can also delete messages from the datastore once it has picked them up successfully.
Let’s check the single operations in more detail.
Storing messages
This operation is identified by the HTTP method POST.
As the Datastore Select operation only supports XML messages, the incoming JSON message is first converted into XML before it is then stored in the datastore. The sender receives a http 200 response code.
Picking up messages
This operation is identified by the HTTP method GET.
The receiver of the messages would like to pick up all of them, but as there might be a lot of messages in the datastore (and returning all of them at once would overload the http response), a paging mechanism was implemented. A first datastore SELECT will fetch up to 10.000 messages; then we count the messages (as less messages could have been selected in case less than 10.000 messages existed) and a second SELECT call will fetch only 1000 messages (if at least 1000 messages exist, otherwise less). Afterwards, we want to calculate the difference between the first and the second SELECT result in order to determine the number of messages that might still remain to be picked up by the receiver. This way, the receiver can check if another call is required or not. The response is sent with a http 200 response code.
Important: For critical business data we strongly recommend to separate the Read of datastore entries from the Delete of datastore entries. We want to avoid that the response message gets affected by some network error and your messages are lost. Therefore, our REST service offers another operation for explicit deletion.
Deleting messages
This operation is identified by the HTTP method DELETE.
For each entry picked up from the call mentioned above, the receiver sends a separate call with one ID. A datastore GET call first checks if an entry with this ID is already available in the datastore and if yes, the entry is afterwards deleted via the datastore DELETE step. A response code 204 is returned to the sender. If the entry doesn’t exist in the datastore, a response code 404 is returned.
This design was working fine and the integration flow was running in a productive environment. But soon, the flow developer realized that during the work week, when the senders were pushing messages to the REST service, the datastore volume was growing bigger and bigger and the receiver couldn’t keep up with the pace in picking up and clearing the messages from the datastore. Only during weekends, when no senders were pushing new messages, the receiver could empty the datastore. The developer was faced with a reduction of the performance towards the end of the work week for the GET calls to pick up messages from the datastore.
Analysis
Together with the developer, I checked the scenario and found two potential improvement areas.
Paging mechanism inefficient
To read 10.000 entries just to get the exact number of messages left in the datastore is a performance killer. What’s worse, the number returned is not even accurate. If there are more than 10.000 entries in the datastore, the real number is not included in the calculation.
Deletion of messages inefficient
To have a separate HTTP call for a single deletion is causing lots of network overhead and has to be improved.
Improvements
Paging mechanism
In the new design, we only selected at max the desired number of datastore entries, e.g. 1000. Afterwards, we counted how many messages we received for real (you remember, the datastore SELECT returns all available messages up to the specified amount). In case the SELECT returned the full amount (i.e. 1000 entries), then that is a 99% indicator that the datastore contains more messages. In this case, our response to the receiver will contain (in addition to the requested 1000 entries) an information that there are more entries to be picked up. This can be in any form, a header, an additional XML tag, an XML attribute… anything the receiver can evaluate.
Deletion of messages
We got rid of the differentiation between the http 204 and the http 404 response. If an entry should be deleted, it doesn’t matter whether it’s available or not (and the datastore DELETE step doesn’t behave different neither). This way, we could skip the datastore GET call and instead do the DELETE directly.
As the datastore DELETE step does not only support the deletion of a single entry but of many entries, we asked the receiver to send only one call with an xml message containing all IDs instead of sending separate messages with single entry IDs. In the datastore DELETE step, we used an xpath expression pointing to the IDs in the message so that all items are removed in one shot.
Switching off JDBC transaction handling
This change is not necessarily required for optimizing the scenario but it’s in general a useful recommendation.
The JDBC transaction handling will make sure that all modifying DB operations share the same Commit or Rollback. If an entry is written and the flow fails before being finished, then nothing gets committed. By this data consistency is ensured.
To activate the JDBC transaction also means to use a DB connection for the whole processing time of the flow. As DB connections are a limited resource, I recommend to carefully check if the JDBC transaction is really required when DB operations are performed, and if not, to switch it off. You can find information on how to do so in Mandy’s blog about transaction handling.
In this flow, no transaction handling is required, as:
Result
The feedback from the integration developer is that now after our re-design even during the work week the datastore volume is not growing anymore and entries are being rapidly picked up and removed.
In this blog, I want to show you how we could improve a datastore scenario that was already running fine.
Baseline
Let me start by explaining the scenario:
The integration flow forms a REST service that provides three functionalities: senders store JSON messages in a datastore via a POST call, a potential receiver of those messages calls the REST service to pick them up from the datastore via a GET call. Via a DELETE call, this receiver can also delete messages from the datastore once it has picked them up successfully.
Let’s check the single operations in more detail.
Storing messages
This operation is identified by the HTTP method POST.
As the Datastore Select operation only supports XML messages, the incoming JSON message is first converted into XML before it is then stored in the datastore. The sender receives a http 200 response code.
Picking up messages
This operation is identified by the HTTP method GET.
The receiver of the messages would like to pick up all of them, but as there might be a lot of messages in the datastore (and returning all of them at once would overload the http response), a paging mechanism was implemented. A first datastore SELECT will fetch up to 10.000 messages; then we count the messages (as less messages could have been selected in case less than 10.000 messages existed) and a second SELECT call will fetch only 1000 messages (if at least 1000 messages exist, otherwise less). Afterwards, we want to calculate the difference between the first and the second SELECT result in order to determine the number of messages that might still remain to be picked up by the receiver. This way, the receiver can check if another call is required or not. The response is sent with a http 200 response code.
Important: For critical business data we strongly recommend to separate the Read of datastore entries from the Delete of datastore entries. We want to avoid that the response message gets affected by some network error and your messages are lost. Therefore, our REST service offers another operation for explicit deletion.
Deleting messages
This operation is identified by the HTTP method DELETE.
For each entry picked up from the call mentioned above, the receiver sends a separate call with one ID. A datastore GET call first checks if an entry with this ID is already available in the datastore and if yes, the entry is afterwards deleted via the datastore DELETE step. A response code 204 is returned to the sender. If the entry doesn’t exist in the datastore, a response code 404 is returned.
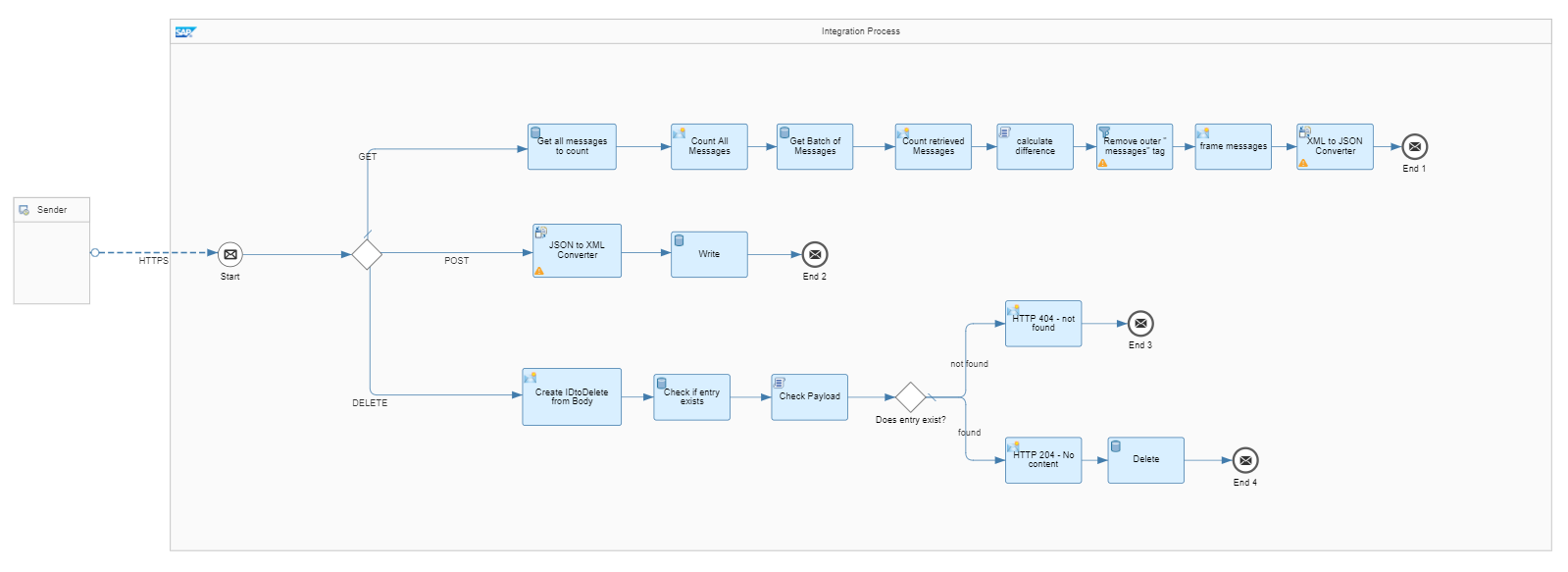
Figure 1: Original design of REST service
This design was working fine and the integration flow was running in a productive environment. But soon, the flow developer realized that during the work week, when the senders were pushing messages to the REST service, the datastore volume was growing bigger and bigger and the receiver couldn’t keep up with the pace in picking up and clearing the messages from the datastore. Only during weekends, when no senders were pushing new messages, the receiver could empty the datastore. The developer was faced with a reduction of the performance towards the end of the work week for the GET calls to pick up messages from the datastore.
Analysis
Together with the developer, I checked the scenario and found two potential improvement areas.
Paging mechanism inefficient
To read 10.000 entries just to get the exact number of messages left in the datastore is a performance killer. What’s worse, the number returned is not even accurate. If there are more than 10.000 entries in the datastore, the real number is not included in the calculation.
Deletion of messages inefficient
To have a separate HTTP call for a single deletion is causing lots of network overhead and has to be improved.
Improvements
Paging mechanism
In the new design, we only selected at max the desired number of datastore entries, e.g. 1000. Afterwards, we counted how many messages we received for real (you remember, the datastore SELECT returns all available messages up to the specified amount). In case the SELECT returned the full amount (i.e. 1000 entries), then that is a 99% indicator that the datastore contains more messages. In this case, our response to the receiver will contain (in addition to the requested 1000 entries) an information that there are more entries to be picked up. This can be in any form, a header, an additional XML tag, an XML attribute… anything the receiver can evaluate.
Deletion of messages
We got rid of the differentiation between the http 204 and the http 404 response. If an entry should be deleted, it doesn’t matter whether it’s available or not (and the datastore DELETE step doesn’t behave different neither). This way, we could skip the datastore GET call and instead do the DELETE directly.
As the datastore DELETE step does not only support the deletion of a single entry but of many entries, we asked the receiver to send only one call with an xml message containing all IDs instead of sending separate messages with single entry IDs. In the datastore DELETE step, we used an xpath expression pointing to the IDs in the message so that all items are removed in one shot.
Switching off JDBC transaction handling
This change is not necessarily required for optimizing the scenario but it’s in general a useful recommendation.
The JDBC transaction handling will make sure that all modifying DB operations share the same Commit or Rollback. If an entry is written and the flow fails before being finished, then nothing gets committed. By this data consistency is ensured.
To activate the JDBC transaction also means to use a DB connection for the whole processing time of the flow. As DB connections are a limited resource, I recommend to carefully check if the JDBC transaction is really required when DB operations are performed, and if not, to switch it off. You can find information on how to do so in Mandy’s blog about transaction handling.
In this flow, no transaction handling is required, as:
- the GET operation is not modifying anything, so the data consistency is not endangered.
- the POST operation is performing the datastore WRITE as the last step of the flow, so there can’t occur any errors after the data has been written. The data consistency is not endangered.
- the datastore DELETE is again the last step of the flow for the DELETE operation. The data consistency is not endangered.

Figure 2: New design of REST service
Result
The feedback from the integration developer is that now after our re-design even during the work week the datastore volume is not growing anymore and entries are being rapidly picked up and removed.
- SAP Managed Tags:
- SAP Integration Suite,
- Cloud Integration
Labels:
1 Comment
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
299 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
345 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
427 -
Workload Fluctuations
1
Related Content
- Exploring Integration Options in SAP Datasphere with the focus on using SAP extractors - Part II in Technology Blogs by SAP
- IoT - Ultimate Data Cyber Security - with Enterprise Blockchain and SAP BTP 🚀 in Technology Blogs by Members
- Introducing Blog Series of SAP Signavio Process Insights, discovery edition – An in-depth exploratio in Technology Blogs by SAP
- Unify your process and task mining insights: How SAP UEM by Knoa integrates with SAP Signavio in Technology Blogs by SAP
- Trustable AI thanks to - SAP AI Core & SAP HANA Cloud & SAP S/4HANA & Enterprise Blockchain 🚀 in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 40 | |
| 25 | |
| 17 | |
| 14 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |