はじめに
SAP HANA Viewにおいて、メモリ消費量をいかに最適化するかということは、性能チューニングのポイントの一つです。この最適化を実現するための機能の一つに、メモリ消費量の最適化を目的としたOptimizing Join Columns があります。このブログではこの機能を活用していただくために、機能概要と利用シーンを紹介します。
機能概要と利用目的
説明のためにJoinノードを含むHANA Viewを作成して、これを参照するクエリを考えます。
下記の2つのテーブルを用意します。
create column table left_table
(
requested_column NVARCHAR(30),
join_key NVARCHAR(30),
measure DECIMAL(10,2)
)
;
create column table right_table
(
join_key NVARCHAR(30),
not_requested_column NVARCHAR(30)
)
;
テーブルには下記のデータが格納されています。


これらのテーブルを使用して、下記の要領でHANA Viewを作成します。
- HANA Viewの定義

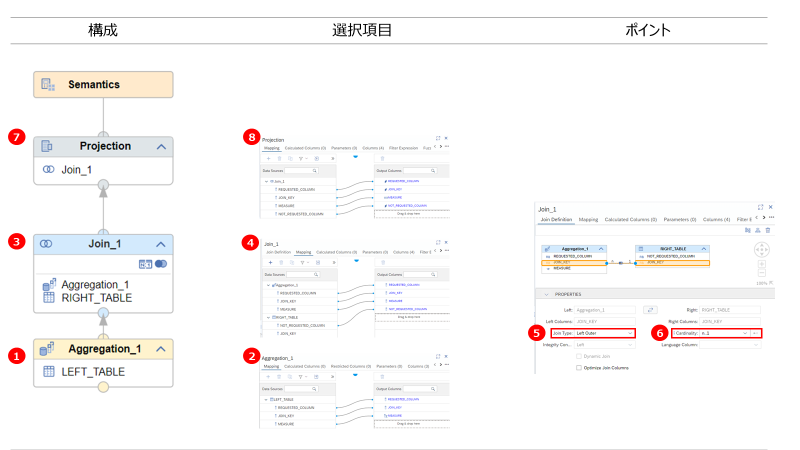
- Aggregationノードを作成、データソースとしてleft_tableを設定
- すべての項目をOutput Columnsに設定
- Joinノードを作成、データソースに1で作成したAggregationノードとright_tableを設定
- right_tableのjoin_keyを除くすべての項目をOutput Columnsに設定
- Joinノードの定義設定:Join TypeをLeft Outerに設定
- Joinノードの定義設定:Cardinalityをn..1に設定
- Projectionノードを作成、データソースとして3で作成したJoinノードを設定
- すべての項目をOutput Columnsに設定
デフォルトでは、このようなHANA Viewを対象にしたクエリの選択リストに、結合キーとなる列(結合列)を指定しない場合にも、内部で結合列は自動的に取得されています。例えば、下記クエリを実行すると、内部で結合列(join_key)が集計対象に含まれていることが確認できます。
SELECT
"REQUESTED_COLUMN",
"MEASURE"
FROM "TEST_HDI_1"."TEST_CALVIEW"
;
- クエリにEXPLAIN PLAN句を付与して取得した実行計画

一方、Optimizing Join Columnsを使用する場合は、後述する前提条件を満たしている場合に限って、内部でこの結合列を取得せずにクエリを実行することができます。
- Optimize Join Columnsを有効化して、同じクエリにEXPLAIN PLAN句を付与して取得した実行計画

このように、Optimizing Join Columnsを有効化することで、集計関数の対象カラムを削減できます。そして、集計関数の対象カラムを少なくすることで、集計後の中間データサイズ(レコード数)を小さくすることが可能です。これは、クエリ全体で使用するメモリ消費量の削減につながります。Optimizing Join Columnsを使用する目的は、このメモリ消費量の最適化であるといえます。
最適化の効果は、集計関数の対象として含まれる不要な結合列のグラニュラリティ(データの粒度)が高いほど、大きくなります。
Optimizing Join Columnsを使用するための前提条件
この機能を使用するための条件は下記の通りです。HANA Viewと実行するクエリがこれらを満たす必要があります。
- The join field is not requested in the query.
結合列が、クエリの選択リストに含まれていない
- Only fields from one join partner are requested in the query.
結合するテーブルのうち、一方のテーブルの列のみがクエリの選択リストに含まれている
- The join is an outer join, referential, or text join.
Joinのタイプがouter join, referential join, text joinのいずれかである
- The cardinality to the join partner from which no fields are requested is set to 1
クエリの選択リストに列が含まれていないテーブルのカーディナリティが、n:1の1側である
Optimizing Join Columnsを有効にする際、上記項目が正しく設定されているかどうかに注意する必要があります。これは、機能が有効化できるかどうかという観点においても重要ですが、それだけではなく、クエリ実行結果が意図通りに出力されるかどうか、という観点においても重要です。
また、これら4つの前提条件が正確に設定され、すべてが満たされている場合においても、HANA Viewの構成によっては、設定前後でクエリの実行結果が変わる可能性があります。次の章で例をあげて説明します。
設定前後で実行結果が変わる利用例
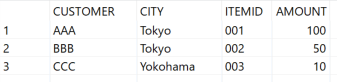
下記のように2つのテーブルを用意します。
CREATE COLUMN TABLE item
(
itemid NVARCHAR(30),
description NVARCHAR(30)
)
;
CREATE COLUMN TABLE salesitem
(
customer NVARCHAR(30),
city NVARCHAR(30),
itemid NVARCHAR(30),
amount DECIMAL(10,2)
)
;
テーブルには下記のデータが格納されています。

これらのテーブルを使用して、下記の要領でHANA Viewを作成します。
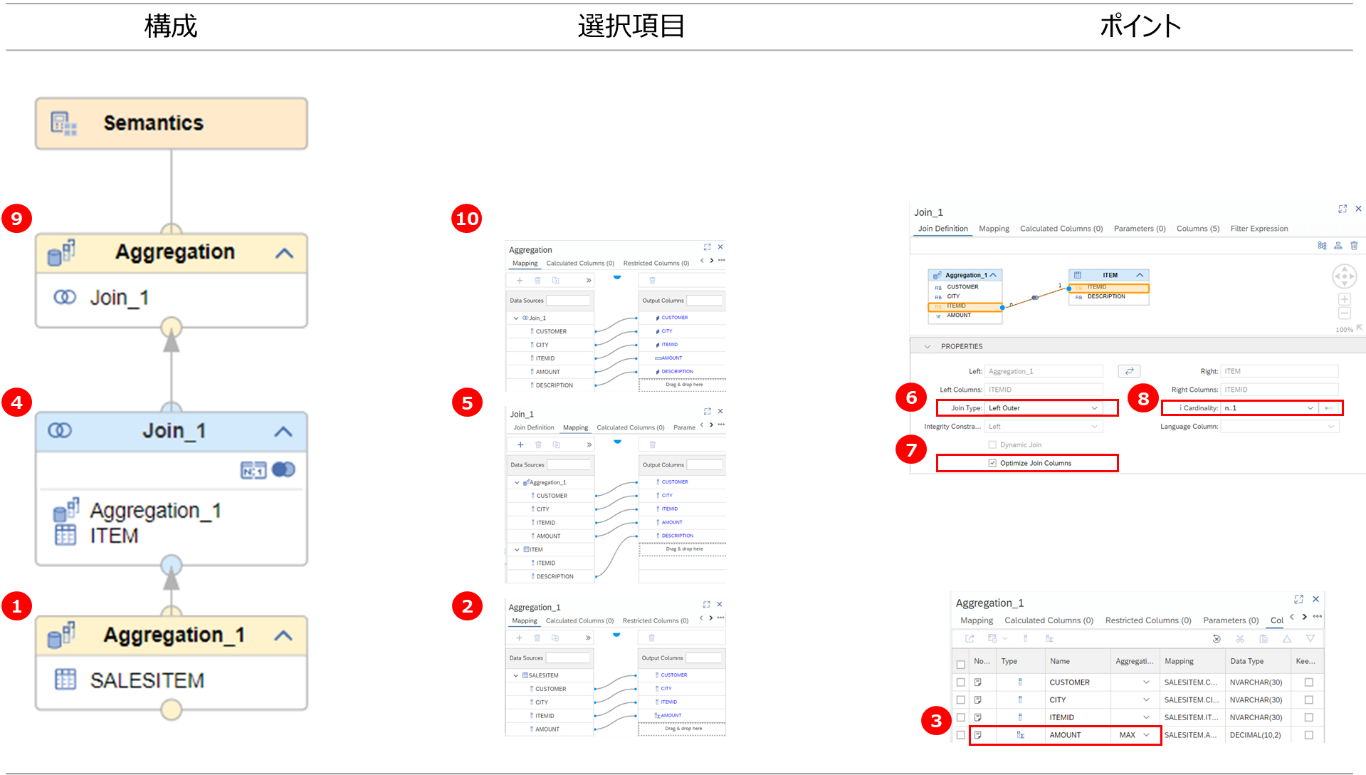
- Aggregationノードを作成、データソースとしてsalesitemを設定
- すべての項目をOutput Columnsに設定
- 項目amountの集計タイプをMAXに設定
- Joinノードを作成、データソースとして、1で作成したAggregationノードとitemを設定
- Itemの項目itemidを除くすべての項目をOutput Columnsに設定
- Joinノードの定義設定:Join TypeをLeft Outerに設定
- Joinノードの定義設定:Optimize Join Columnsを有効化
- Joinノードの定義設定:Cardinalityをn..1に設定
- Aggregationノードを作成、データソースとして4で作成したJoinノードを設定
- すべての項目をOutput Columnsに設定
このHANA Viewを使用して、Cityごとに最大のamountを計算することを考えます。下記のクエリを実行します。
SELECT
"CITY",
"AMOUNT"
FROM "TEST_HDI_1"."OPTIMIZEJOINCOLUMN";
クエリの実行結果は次のようになります。
- 実行結果(Optimize Join Columnsが有効)

一方で、Optimize Join Columnsを使用しない場合を考えます。Optimize Join Columnsを無効化して、このHANA Viewに対して同じクエリを実行します。結果は次のようになります。
- 実行結果(Optimize Join Columnsが無効)

これら結果の差異は、Joinノードより下位のAggregationノードで実行する集計関数(今回の例の場合はmax関数の処理に対応)に、結合列であるitemidが含まれているかどうか、に起因しています。これを確認するために内部処理を比較します。クエリにEXPLAIN PLAN句を付与して、実行計画を取得します。
- Optimize Join Columnを有効化したHANA Viewに対するクエリの実行計画

- Optimize Join Columnを無効化したHANA Viewに対するクエリの実行計画

これらの実行計画から、設定が有効であるとき、集計処理の対象に結合列(itemid)が含まれていないことを確認できます。
まとめ
Optimizing Join Columnsを使用すると、クエリに含まれる集計処理後の中間データ(レコード数)を削減できるため、リソース消費量が削減でき、パフォーマンスを向上させることができます。ただし、使用することで、集計関数を使用する数値項目の実行結果が変わる可能性があります。設定の有無がクエリ実行結果にどのような影響を与えるか十分に検証することで、正確性を失うことなく、クエリのパフォーマンスを向上させてください。
