
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Multi-model in hana_ml 2.6 for Python (part 01): D...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Developer Advocate
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-10-2020
9:19 PM
In the previous post, I showed how I have done the setup of the environment I am planning to use for this series to explain the new multi-model functionality of
The SAP HANA DataFrame is the central concept we need to understand in
If you worked intensively with data wrangling and analysis using programming languages, then you might have worked with dataframes already in R, or in Python thanks to Pandas library, or in Julia thanks to DataFrames.jl package.
In simple terms, these dataframes are two-in-one: (1) a structure storing the data in a client, (2) a rich number of sometimes very sophisticated methods that can be applied to this structure to understand and to manipulate this data.
Now, when it comes to the HANA DataFrame in
It all means that all the heavy lifting, like data processing or ML algorithms, are executed in the SAP HANA database: right where the data is stored. Data is not moved between a DB server and a client where Python code is executed. It follows the SAP HANA principle of bringing a code to the data, not data to the code.
It means as well, that as a developer using
I would recommend checking official Pandas getting started tutorials: https://pandas.pydata.org/pandas-docs/stable/getting_started/intro_tutorials/index.html, but if anyone knows the better place for starters please share in the comments below. Personally, I found "10 Minutes to pandas" the most confusing 60(!) minutes, when I went through this 😄
But what I would certainly recommend to everyone coming from an SQL background is checking: https://pandas.pydata.org/pandas-docs/stable/getting_started/comparison/comparison_with_sql.html.
...before we move on.
Upgrade
The new update of the
which I can run:
in any of the ways mentioned above, e.g. in a Jupyter's terminal.
Install Python
Shapely is a Python package for the manipulation and analysis of planar geometric objects. It is used by
To install
In my environment, I just executed installation using Jupyter's terminal.
JupyterLab is a client I use for this exercise, so I will create a new notebook
In most production scenarios
For my SAP TechEd demo, I wanted data that would be good to show multi-model processing -- spatial and graph -- so I used a dataset provided by Kelvin Lawrence at https://github.com/krlawrence/graph/raw/master/sample-data/ representing a network of connections between airports. At the time of writing this post, the data represents the status from January 2020 -- before the situation changed dramatically for airlines and airports. But let us focus on the data and processing here.
I will use
Let's check the shape (number of columns and rows) of these Pandas dataframes.
Nodes dataframe has 3742 rows with 16 columns, while edges dataframe has 57574 records with 5 columns.
Let's reshape this data before persisting in SAP HANA Cloud and for that, we first need to understand our dataset.
What are the columns and their types in the
Ok, there is a column
As you can see there are some columns (like
Let's fix all these by creating a new Pandas dataframe
And let's do the same for the edges dataset by saving required columns, rows, and data types into a new dataframe
Switch to using
With the new database user
The last statement shows that the schema of
I will use
We can see that two tables have been created in db user's schema in the SAP HANA.
And we can check data in these tables using
I did a few things (intentionally) that should hurt the eyes of programmers using Python and Pandas for a while. If you are one of those, please leave your improvement suggestions in the comments below!
For everyone else, please stay tuned as we will look at dataframes a bit closer in the next post.
Stay healthy ❤️
-Vitaliy (aka @Sygyzmundovych)
hana_ml 2.6 in the context of my demo used in this year's SAP TechEd's DAT108 session.Dataframes -- a bit of the background
The SAP HANA DataFrame is the central concept we need to understand in
hana_ml.If you worked intensively with data wrangling and analysis using programming languages, then you might have worked with dataframes already in R, or in Python thanks to Pandas library, or in Julia thanks to DataFrames.jl package.
In simple terms, these dataframes are two-in-one: (1) a structure storing the data in a client, (2) a rich number of sometimes very sophisticated methods that can be applied to this structure to understand and to manipulate this data.
SAP HANA DataFrame...
Now, when it comes to the HANA DataFrame in
hana_ml:- a dataframe object does not store physical data, but it does store the HANA SQL
SELECTstatement backing the dataframe, - most methods are designed to not bring data from the database to a client unless explicitly requested, e.g. via
collect()method, - HANA DataFrame API is tightly coupled with Pandas: data from Pandas dataframe can be persisted as an SAP HANA database object, and -- on the other hand -- results of running operations on SAP HANA data are usually returned in a format of a Pandas dataframe.
It all means that all the heavy lifting, like data processing or ML algorithms, are executed in the SAP HANA database: right where the data is stored. Data is not moved between a DB server and a client where Python code is executed. It follows the SAP HANA principle of bringing a code to the data, not data to the code.
...and its relationship with Python Pandas
It means as well, that as a developer using
hana_ml you should have some basic understanding of the Pandas module.I would recommend checking official Pandas getting started tutorials: https://pandas.pydata.org/pandas-docs/stable/getting_started/intro_tutorials/index.html, but if anyone knows the better place for starters please share in the comments below. Personally, I found "10 Minutes to pandas" the most confusing 60(!) minutes, when I went through this 😄
But what I would certainly recommend to everyone coming from an SQL background is checking: https://pandas.pydata.org/pandas-docs/stable/getting_started/comparison/comparison_with_sql.html.
Some preparation work...
...before we move on.
Upgrade hana_ml if needed
The new update of the
hana_ml 2.6 has been released since my previous post was published last week. I can see it using:pip search hanawhich I can run:
- from my laptops command line
docker exec hmlsandbox01 pip search hana - from Jupyter notebook's cell
!pip search hana, or - simply using a terminal within Jupyter.
 So, to upgrade the module let's run:
So, to upgrade the module let's run:
pip install --upgrade hana-mlin any of the ways mentioned above, e.g. in a Jupyter's terminal.

Install Python shapely module
Shapely is a Python package for the manipulation and analysis of planar geometric objects. It is used by
hana_ml to support geospatial data manipulation, but must be separately installed manually to avoid errors like "name 'wkb' is not defined" or "ModuleNotFoundError: No module named 'shapely'." It is a known limitation and should be fixed in the next patch of hana_ml.To install
shapely please follow: https://shapely.readthedocs.io/en/stable/project.html#installing-shapely.In my environment, I just executed installation using Jupyter's terminal.
pip install shapely
Ok, it is time for coding!
JupyterLab is a client I use for this exercise, so I will create a new notebook
01 Dataframes.ipynb.Read the files with the data using Pandas
In most production scenarios
hana_ml will be used against some large volumes of data already stored in SAP HANA on-prem or in SAP HANA Cloud. But in our case of starting with the empty trial instance of SAP HANA Cloud, we need to load some data first. Actually, I showed already how to quickly load CSV files into SAP HANA in my post Quickly load data with hana_ml....For my SAP TechEd demo, I wanted data that would be good to show multi-model processing -- spatial and graph -- so I used a dataset provided by Kelvin Lawrence at https://github.com/krlawrence/graph/raw/master/sample-data/ representing a network of connections between airports. At the time of writing this post, the data represents the status from January 2020 -- before the situation changed dramatically for airlines and airports. But let us focus on the data and processing here.
import pandas
pandas.__version__I will use
dfp_ notation for Pandas dataframes.dfp_nodes=pandas.read_csv('https://github.com/krlawrence/graph/raw/master/sample-data/air-routes-latest-nodes.csv')
dfp_edges=pandas.read_csv('https://github.com/krlawrence/graph/raw/master/sample-data/air-routes-latest-edges.csv')Let's check the shape (number of columns and rows) of these Pandas dataframes.
print('Size of nodes dataframe: {}'.format(dfp_nodes.shape))
print('Size of edges dataframe: {}'.format(dfp_edges.shape))
Nodes dataframe has 3742 rows with 16 columns, while edges dataframe has 57574 records with 5 columns.
Data analysis and wrangling with Pandas
Let's reshape this data before persisting in SAP HANA Cloud and for that, we first need to understand our dataset.
What are the columns and their types in the
dfp_nodes dataframes?dfp_nodes.dtypesOk, there is a column
~label, so what are the node labels?dfp_nodes.groupby('~label').size()
As you can see there are some columns (like
type:string) as well as some rows (like those labeled continet or version) that we do not need. Additionally, all columns have either some special characters (like ~) or data types (like :object) as part of their names that we do not need. Plus some of the columns have some data types too generic for their real content. And ideally, we need column names in all capitals for SAP HANA.Let's fix all these by creating a new Pandas dataframe
dfp_ports and check it!dfp_ports=(
dfp_nodes[dfp_nodes['~label'].isin(['airport'])]
.drop(['~label','type:string','author:string','date:string'], axis=1)
.convert_dtypes()
)dfp_ports.columns=(dfp_ports.columns
.str.replace('~','')
.str.replace(':.*','')
.str.upper()
)
And let's do the same for the edges dataset by saving required columns, rows, and data types into a new dataframe
dfp_edges.dfp_edges.dtypesdfp_edges.groupby('~label').size()dfp_routes=dfp_edges[dfp_edges['~label'].isin(['route'])].drop(['~label'], axis=1).copy()dfp_routes.columns=dfp_routes.columns.str.replace('~','').str.replace(':.*','').str.upper()
Switch to using HANAML database user
With the new database user
HANAML created in the previous post let's switch to using it for further exercises.import hana_ml
hana_ml.__version__hana_cloud_endpoint="<uuid>.hana.trial-<region>.hanacloud.ondemand.com:443"hana_cloud_host, hana_cloud_port=hana_cloud_endpoint.split(":")
cchc=hana_ml.dataframe.ConnectionContext(port=hana_cloud_port,
address=hana_cloud_host,
user='HANAML',
password='Super$ecr3t!', #Should be your user's password 😉
encrypt=True
)print(cchc.sql("SELECT SCHEMA_NAME, TABLE_NAME FROM TABLES WHERE SCHEMA_NAME='{schema_name}'"
.format(schema_name=cchc.get_current_schema()))
.collect()
)
The last statement shows that the schema of
HANAML does not have any tables yet. So, let's save the data from Pandas dataframes to SAP HANA tables using hana_ml.dfh_ports=hana_ml.dataframe.create_dataframe_from_pandas(cchc,
dfp_ports, "PORTS",
force=True
)dfh_routes=hana_ml.dataframe.create_dataframe_from_pandas(cchc,
dfp_routes, 'ROUTES',
force=True)I will use
dfh_ notation for HANA DataFrame variables.print(cchc.sql("SELECT SCHEMA_NAME, TABLE_NAME FROM TABLES WHERE SCHEMA_NAME='{schema_name}'"
.format(schema_name=cchc.get_current_schema()))
.collect()
)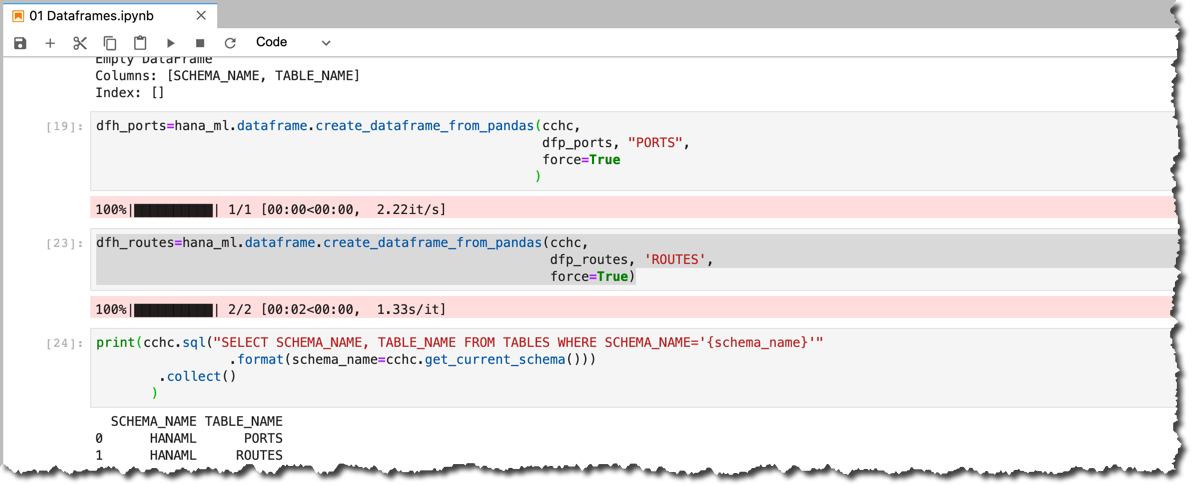
We can see that two tables have been created in db user's schema in the SAP HANA.
And we can check data in these tables using
collect() method of the HANA dataframe.print(dfh_ports.collect())
I did a few things (intentionally) that should hurt the eyes of programmers using Python and Pandas for a while. If you are one of those, please leave your improvement suggestions in the comments below!
For everyone else, please stay tuned as we will look at dataframes a bit closer in the next post.
Stay healthy ❤️
-Vitaliy (aka @Sygyzmundovych)
- SAP Managed Tags:
- SAP HANA Cloud,
- Python,
- SAP HANA,
- Big Data
Labels:
6 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
88 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
65 -
Expert
1 -
Expert Insights
178 -
Expert Insights
280 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
330 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
408 -
Workload Fluctuations
1
Related Content
- Fairness in Machine Learning - A New Feature in SAP HANA Cloud PAL in Technology Blogs by SAP
- Unlocking Data Value #3: Machine Learning with SAP in Technology Blogs by SAP
- Auto-generating HANA ML CAP Artifacts from Python in Technology Blogs by SAP
- How to compare an APL model to a non-APL model ─ Part 2 in Technology Blogs by SAP
- Develop a Machine Learning Application on SAP BTP - Data Science part in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 10 | |
| 9 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 4 |