
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- Hacer backups en HANA (estilo antiguo) para SAP Bu...
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
dotpablo
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-30-2020
7:57 PM
Sinopsis
Al arrancar con la operatividad de un entorno de SAP Business One on HANA 10, a veces te encuentras con que no existen las posibilidades de instalar un SAP HANA Cockpit para la administración de HANA 2.0 o simplemente “no se presupuesto” en el alcance del proyecto.
Por las características de este tipo de proyectos (y el target de algunos clientes), muchas veces estos no cuentan con la infraestructura necesaria y el personal técnico calificado para la administración de HANA como “debería ser" siguiendo las buenas prácticas que recomienda SAP.
Esto pasa principalmente en entornos On-Premise en donde el cliente tiene que velar por la seguridad e integridad de sus datos, independientemente que la solución sea instalada bajo un hyperscaler o no.
La mayoría de los hyperscalers ofrecen soluciones de replicación, resguardo de datos, etc para garantizar los datos de los productos que podremos utilizar en ellos, pero estos a veces no son productos optados por algún perfil de clientes “muy chicos”.
En este tipo de clientes, mucho menos existe un personal disponible para realizar las políticas mínimas de respaldo/administración que requiere un sistema que utilice HANA, por lo que de alguna manera (y posterior a la instalación) hay que asegurar la operatividad del mismo ante eventos intempestivos durante su ciclo de vida.
Una forma rápida de hacerlo y con pocos recursos involucrados, es mediante la implementación de scripts que ejecuten los backups de forma programada, borren los viejos y se copien a otro sitio fuera del servidor Linux.
Nota del autor: Existen mil formas de hacer esta “tarea administrativa” (y que lo mejor es usar el HANA Cockpit de eso estamos claros) para garantizar las políticas mínimas de backup de la forma más económica posible. Esta es simplemente otra solución más que les puede servir a los consultores técnicos que implementan SAP Business One o tengan que administrar soluciones de este tipo con bases de datos HANA.
La solución
1. Tener el sistema correctamente instalado y andando (sin problemas, puede ser obvio pero es bueno cerciorarse antes de arrancar con esta tarea).
2. Una vez que hayamos cumplido con todo lo básico para tener andando B1 (en mi pasado artículo hablo de muchos tips al respecto) podemos arrancar con los siguientes pasos. Haber lanzado un backup de sistema y tenant por primera vez es clave para que arranquen los backups de log.
3. Revisar que los file systems de la instalación de HANA hayan quedado bien.
4. Crear un drive, (unidad de disco, SAN o similar) sobre algún Windows que tenga acceso al servidor Linux en donde instalamos HANA para replicar los respaldos que sacaremos desde Linux para de esta manera evitar que si perdemos esta instancia HANA perdamos toda la información del sistema.
Este drive deberá contar con al menos unas 5-10 veces el tamaño de nuestro backup completo de HANA, la idea es tener holgura para entren los backups de varios días y así tener unas políticas mínimas de resguardo de datos. A este drive lo llamaremos SAPBackups.
5. Crear una carpeta sobre /mnt (podríamos llamarla /SAPBK)

6. Una vez tengamos creada la unidad en Windows esta deberá ser “montada” en Linux también. Para esto deberíamos primero crear un usuario a nivel de la instancia local de Windows al cual llamaremos “montaje” con una clave determinada con los siguientes permisos. Algo así debería quedar:

7. Editamos con vim el archivo /etc/fstab y escribiríamos la línea necesaria para el montaje de este disco compartido y sea accesible desde Linux. Un ejemplo que funciona sería este:
//EC2AMAZ-XXXXX/BackupsB1 /mnt/SAPBK cifs user=montaje,pass=123XXX,rw,users 0 0
Al hacer un cat sobre el archivo nos debería devolver algo así:

8. Al hacer un mount debería aparecer como un file system:

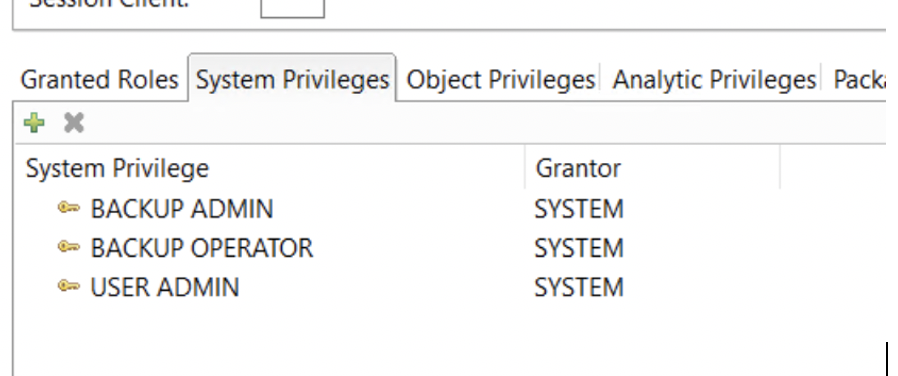
9. Vamos al HANA Studio y creamos el usuario que realizara los respaldos programados. Lo llamaremos ZBACKUP y contará con estos privilegios :
10. Crearemos 2 scripts con el usuario root que se encargarán de los problemas de "archivos" para evitar la infame "situación de disco lleno" y otras cosas desafortunadas más que suceden cuando el cliente no tiene o no lo logra implementar una "buena" estrategia de backups.
Los scripts hacen lo siguiente:
a. El primer script lo llamaremos ZSYNCLOGS.sh. Este script se encarga de planificar cada 15 minutos en cron, entre las 5am y 23 horas (en horario nocturno se ejecutan los backups de data). En este caso se hará el borrado de los archivos "viejos" y la limpieza estará en otro script planificado con root también y que sincronizará el backup de data efectuado en el script de ejecución de backup de HANA. Se coloca el delete en el script para que limpie también los archivos viejos generados en el destino ya que normalmente solo copiara los archivos de logs recientes.
b. El Segundo script lo llamaremos ZSYNC-LIMPIEZA.sh este es un script de limpieza de backup de SYSTEMDB y del tenant NDB (en este caso nombramos el SID de HANA como NDB) y sus backups de logs - para HANA lo planificamos en el crontab de root también, ya que sincroniza el backup de data efectuado en el script de ejecución de backup de HANA. Dependiendo del espacio en el /hana/shared y del tamaño de cada juego de files de backup, dejamos n cantidad días de backup en el server Linux.
ZSYNCLOGS.sh
#!/bin/sh
rsync -avu --delete "/hana/shared/NDB/HDB00/backup" "/mnt/BACKUP/"
# the end
ZSYNC-LIMPIEZA.sh
#!/bin/sh
find /hana/shared/NDB/HDB00/backup/data/DB_NDB -type f -mtime +2 -exec rm -fv {} +
find /hana/shared/NDB/HDB00/backup/data/SYSTEMDB -type f -mtime +2 -exec rm -fv {} +
find /hana/shared/NDB/HDB00/backup/log/DB_NDB -type f -mtime +2 -exec rm -fv {} +
find /hana/shared/NDB/HDB00/backup/log/SYSTEMDB -type f -mtime +2 -exec rm -fv {} +
find /mnt/BACKUP/backup/data/DB_NDB -type f -mtime +2 -exec rm -fv {} +
find /mnt/BACKUP/backup/data/SYSTEMDB -type f -mtime +2 -exec rm -fv {} +
find /mnt/BACKUP/backup/log/DB_NDB -type f -mtime +2 -exec rm -fv {} +
find /mnt/BACKUP/backup/log/SYSTEMDB -type f -mtime +2 -exec rm -fv {} +
rsync -avu --delete "/hana/shared/NDB/HDB00/backup" "/mnt/BACKUP"
# the end
11. Con el usuario root habilitamos vía crontab -e los 2 scripts que creamos a continuación los dejamos programados para que se ejecuten a esas horas. Esto es referencial, depende de las particularidades del negocio.
0,15,30,45 5-23 * * * /hana/shared/NDB/HDB00/ZSYNCLOGS.sh
0 20 * * * /hana/shared/NDB/HDB00/ZSYNC-CLEAN.sh
12. Ahora crearemos el script que ejecuta los backups en HANA con el usuario ZBACKUP que creamos anteriormente. Para esto creamos un script llamado sh el cual se encargará de realizar los backups del tenant del SYSTEMDB y el tenant NDB (este es el tenant en donde instalamos SAP Busines One). Este script lo ejecutará el usuario ndbadm (<SIDadm>) y por lo tanto será programado con el crontab de este usuario. Los backups por defecto, van a parar a la ruta estándar de cada tenant y de esa manera (para no complicar) se dejará así. Entonces tendremos 2 juegos de backup en estas rutas y mas abajo se puede ver como quedaría el script llamando a realizar el backup:
ZBACKUP.sh
#!/bin/sh
time="$(date +"%Y-%m-%d-%H-%M-%S")"
/usr/sap/NDB/HDB00/exe/hdbsql -i 00 -n localhost:30015 -d NDB -u ZBACKUP -p 12345 "backup data using file ('$time')"
/usr/sap/NDB/HDB00/exe/hdbsql -i 00 -n localhost:30013 -d SystemDB -u ZBACKUP -p 12345 "backup data using file ('$time')"
# the end
The defaults paths:
/hana/shared/NDB/HDB00/backup/data/DB_NDB
/hana/shared/NDB/HDB00/backup/data/SYSTEMDB
13. Ahora lo que queda es programar el script con el usuario ndbadm mediante un crontab -e y ya de esa manera tendremos la planificación de los backups en HANA “automatizados”:
0 19 * * * /hana/shared/NDB/HDB00/ZBACKUP.sh
14. Los diferentes scripts deben tener permisos para que sean ejecutados a nivel de los usuarios correspondientes (root y ndbadm en cada caso).
15. Los backups se generarán de esta manera en Linux en el caso de data y log siempre tendrán el mismo juego de carpetas en relación a la cantidad de tenants que existan o se estén haciendo backups de ellos:

16. Si entramos a la locación del backup de data del tenant de SAP Business One (DB_NDB), se puede ver el juego de backups de 3 días seguidos que se ejecutaron de acuerdo a las políticas establecidas en los scripts que utilizamos (para SYSTEMDB tendríamos igual juego de archivos):

Y lo mismo para logs los cuales se ejecutan cada 15 minutos (tiempo por defecto determinado por HANA) :

17. Una vez que arranquen los backups también podremos ver como se sincroniza con Windows en el drive que destinamos para tal fin:

De esta manera tendremos replicado, al menos en 2 locaciones distintas, los juegos de backup de nuestro sistema HANA / SAP Business One. La idea es que el cliente tenga la posibilidad de copiar esos juegos de backups desde Windows y los guarde a su vez en otra locación, con el fin de resguardar los datos y así evitar eventos anómalos.
El Fin.
- SAP Managed Tags:
- SAP Business One, version for SAP HANA,
- SAP HANA,
- Basis Technology
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
"TypeScript" "Development" "FeedBack"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
2 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
absl
1 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
AEM
1 -
AI
7 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
3 -
API Call
2 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
4 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
1 -
aws
2 -
Azure
1 -
Azure AI Studio
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
bitcoin
1 -
Blockchain
3 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
11 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Application Studio
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
1 -
Business Data Fabric
3 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
1 -
CA
1 -
calculation view
1 -
CAP
3 -
Capgemini
1 -
CAPM
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
4 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Consolidation Extension for SAP Analytics Cloud
1 -
Controller-Service-Repository pattern
1 -
Conversion
1 -
Cosine similarity
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
cyber security
2 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
database tables
1 -
Datasphere
2 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
digital transformation
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
1 -
Fiori
14 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
Flask
1 -
Full Stack
8 -
Funds Management
1 -
General
1 -
Generative AI
1 -
Getting Started
1 -
GitHub
8 -
Grants Management
1 -
groovy
1 -
GTP
1 -
HANA
5 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
1 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
HTML5 Application
1 -
Identity cards validation
1 -
idm
1 -
Implementation
1 -
input parameter
1 -
instant payments
1 -
Integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
Java
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
8 -
Kerberos for JAVA
8 -
Launch Wizard
1 -
Learning Content
2 -
Life at SAP
1 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
2 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MTA
1 -
Multi-Record Scenarios
1 -
Multiple Event Triggers
1 -
Neo
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
2 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Process Automation
2 -
Product Updates
4 -
PSM
1 -
Public Cloud
1 -
Python
4 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
Research
1 -
Resilience
1 -
REST
1 -
REST API
1 -
Retagging Required
1 -
Risk
1 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
3 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
8 -
SAP AI Launchpad
8 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
4 -
SAP Analytics Cloud for Consolidation
2 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BTP
20 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
5 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
2 -
SAP CDC
1 -
SAP CDP
1 -
SAP CDS VIEW
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Migration in Retail Industry
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
9 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
2 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
9 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Odata
2 -
SAP on Azure
1 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP SuccessFactors
2 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP Utilities
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapmentors
1 -
saponaws
2 -
SAPS4HANA
1 -
SAPUI5
4 -
schedule
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
SEN
1 -
SEN Manager
1 -
service
1 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
soap
1 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
Substring function
1 -
SuccessFactors
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
1 -
Technology Updates
1 -
Technology_Updates
1 -
Threats
1 -
Time Collectors
1 -
Time Off
2 -
Tips and tricks
2 -
Tools
1 -
Trainings & Certifications
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
2 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Validations
1 -
Vector Database
1 -
Vector Engine
1 -
Visual Studio Code
1 -
VSCode
1 -
Web SDK
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- Workload Analysis for HANA Platform Series - 1. Define and Understand the Workload Pattern in Technology Blogs by SAP
- What’s New in SAP Analytics Cloud Release 2024.05 in Technology Blogs by SAP
- Effective Disaster Recovery Strategies for SAP Systems in Technology Blogs by Members
- Navigating the depths of Data Aging in S/4 HANA in Technology Blogs by Members
- Top 10 Technical Best Practices for Achieving 100% Customer Satisfaction in SAP Basis Services in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 11 | |
| 10 | |
| 7 | |
| 6 | |
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 3 |