
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- How to Build a Strong Dataset for Your Chatbot wit...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member70
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-20-2020
4:21 PM
Why data is key to train your chatbot?
Data is key to a chatbot if you want it to be truly conversational. Therefore, building a strong data set is extremely important for a good conversational experience.
Fundamentally, a chatbot turns raw data into a conversation. The two key bits of data that a chatbot needs to process are (i) what people are saying to it and (ii) what it needs to respond to.
For example, in the case of a simple customer service chatbot, the bot will need an idea of the type of questions people are likely to ask and the answers it should be responding with. To work out those answers, it will use data from previous conversations, emails, telephone chat transcripts, and documents, etc. This is the training data. Where no training data exists, we use the crowdsourcing method and ask representative users to ask the bot questions they would like their bot to meaningfully respond. That’s how we build the training data.
Chatbots are only as good as the training data they are given. You can’t just launch a chatbot with no data and expect customers to start using it. A chatbot with little or no training is bound to deliver a poor conversational experience. Knowing how to train and actual training isn’t something that happens overnight. Building a data set is complex, requires a lot of business knowledge, time, and effort. Often, it forms the IP of the team that is building the chatbot.
In this article, we will understand how, using the SAP Conversational AI platform, we can build a good base data (aka training data) to train the chatbot, make sense of the data by efficient labeling, and the broad methods to develop a well-performing data set.
1. What are the core principles to build a strong dataset?
It is pertinent to understand certain generally accepted principles underlying a good dataset.
Firstly, always place yourself in the users’ shoes. Imagine his/her world. Understand his/her universe including all the challenges he/she faces, the ways the user would express himself/herself, and how the user would like a chatbot to help. This is fundamental.
Secondly, we recommend a single owner for the data set, that is in charge of monitoring and enhancing the bot dataset. If multiple owners exist, it could get tricky and challenging.
If you have joint owners, both owners need to fully understand and know the data set – intents, expressions, labeling of entities (free or restricted), and the evolution (i.e. incremental changes that were made to the data set and how it led to the improved performance levels).
2. What are the best practices to build a strong dataset?
For a chatbot to deliver a good conversational experience, we recommend that the chatbot automates at least 30-40% of users’ typical tasks. What happens if the user asks the chatbot questions outside the scope or coverage? This is not uncommon and could lead the chatbot to reply “Sorry, I don’t understand” too frequently, thereby resulting in a poor user experience.
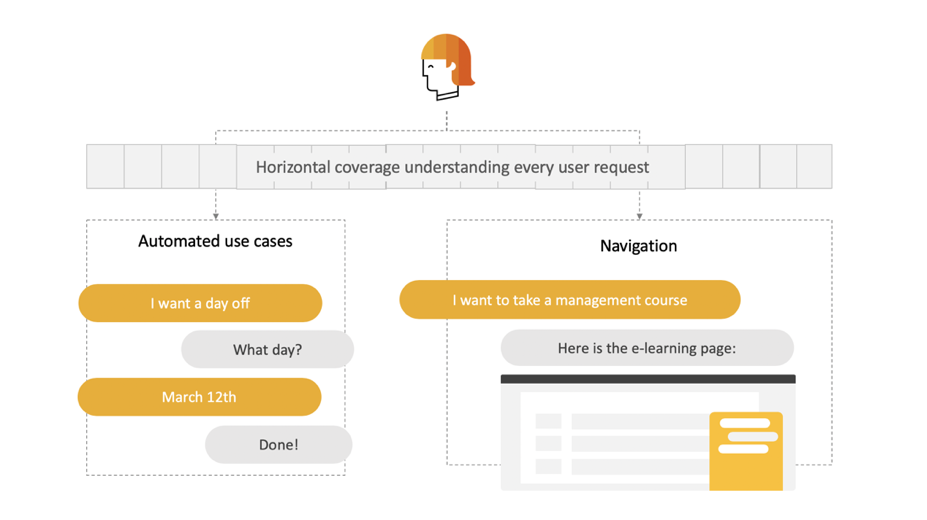
We, therefore, recommend the bot-building methodology to include and adopt a horizontal approach. Building a chatbot horizontally means building the bot to understand every request; in other words, a dataset capable of understanding all questions entered by users.
Creating a great horizontal coverage doesn’t necessarily mean that the chatbot can automate or handle every request. However, it does mean that any request will be understood and given an appropriate response that is not “Sorry I don’t understand” – just as you would expect from a human agent.
After you build horizontal coverage, the bot is able to understand the question and take one of the following actions:
- Handle the request autonomously with a fully automated conversation
- Guide the user to the right webpage to help them get the information
2.1 Build your horizontal coverage
Stage 1: Conversation logs
The key to building effective horizontal coverage is to efficiently collect conversation logs and feedback from your users. Surveys are a great way to gather user data, and user data is the core of powerful horizontal coverage.
Start by creating an online survey to ask your potential users how they will interact with your chatbot.
You will be able to collect valuable insights into queries made by your users, which will help you to identify strategic intents for your chatbot.
It is good to have at least a few thousand user sentences to build a great horizontal coverage. You can go up to 50,000 or more!
Stage 2: Intent clustering
Once you’ve collected feedback from your users, you’ll be able to identify the following different types of intents:
- New intents that have not yet been integrated into your bot training: these need to be created on the SAP Conversational AI platform and enriched with expressions.
- Intents that have already been integrated into your bot training: These need to be enriched with new expressions.
- Intents not related to the scope of your chatbot: These give you the opportunity to maximize your chatbot’s understanding by covering other use cases, enabling the bot to propose alternative solutions for the end-user.
Stage 3: Train your chatbot
Try to improve the dataset until your chatbot reaches 85% accuracy – in other words until it can understand 85% of sentences expressed by your users with a high level of confidence.
Stage 4: Build a concierge bot
Now that you’ve built a first version of your horizontal coverage, it is time to put it to the test. This is where we introduce the concierge bot, which is a test bot into which testers enter questions, and that details what it has understood.
Testers can then confirm that the bot has understood a question correctly or mark the reply as false. This provides a second level of verification of the quality of your horizontal coverage.
Stage 5: Train again
The results of the concierge bot are then used to refine your horizontal coverage. Use the previously collected logs to enrich your intents until you again reach 85% accuracy as in step 3.
Additional best practices:
- Ensure you have a minimum of 50 sentences per intent.
- Use predefined intents (small talk) when you create your bot (greetings, goodbye, help, ask-feeling, etc)
- Do not create intent for buttons triggering skills
- Entities: Create entities only if you need to extract information
To learn more about the horizontal coverage concept, feel free to read this blog.
3. What is Training Analytics?
Training Analytics (TA) is a very powerful tool available in the “Monitor” tab of the SAP Conversational AI platform. It is like a resident Data Scientist within your chatbot that tells you how well your bot is performing!

Why is this important? It is because it helps you to understand what new intents and entities you need to create and whether to merge or split intents, also provides insights into the next potential use cases based on the logs captured.
It is therefore important to understand how TA works and uses it to improve the data set and bot performance.
Let’s begin with understanding how TA benchmark results are reported and what they indicate about the data set.
- Precision
It indicates how precisely a particular intent is correctly recognized. A precision score for Intent A of 0.80 means 80% was correct and 20% incorrect.
- Recall
A recall of 0.9 means that of all the times the bot was expected to recognize a particular intent, the bot recognized 90% of the times, with 10% misses.
- F1 score
F1 is the harmonic mean of ‘Precision’ and ‘Recall’ and a better representation of the overall performance than the normal mean/average.

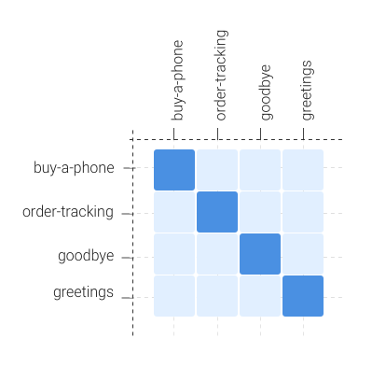
- Confusion matrix
The confusion matrix is another useful tool that helps understand problems in prediction with more precision. It helps us understand how an intent is performing and why it is underperforming. It also allows us to build a clear plan and to define a strategy in order to improve a bot’s performance.
How to interpret the confusion score?
A score of say 7.5% between intents A and B means 7.5% of sentences belonging to Intent A were wrongly classified as Intent B.
This provides a useful starting point to analyze sentences in each intent and reannotate as required to the right intent.
A perfect data set would have a confusion matrix with a perfect diagonal line, with no confusion between any two intents, like in the screenshot below:
Part 4: Improve your chatbot dataset with Training Analytics
While there are several tips and techniques to improve dataset performance, below are some commonly used techniques:
Remove expressions
We can detect that a lot of testing examples of some intents are falsely predicted as another intent. Moreover, we check if the number of training examples of this intent is more than 50% larger than the median number of examples in your dataset (it is said to be unbalanced). As a result, the algorithm may learn to increase the importance and detection rate of this intent. To prevent that, we advise removing any misclassified examples.
Avoid duplicates
Machine learning algorithms are excellent at predicting the results of data that they encountered during the training step. Duplicates could end up in the training set and testing set, and abnormally improve the benchmark results.
Add expressions
We check if some intents have a low recall. Since there is no balance problem in your dataset, our machine learning strategy is unable to capture the globality of the semantic complexity of this intent. You may be able to solve this by adding more training examples.
Merge intents
Two intents may be too close semantically to be efficiently distinguished. A significant part of the error of one intent is directed toward the second one and vice versa. Merging them may help improve the bot’s flow.
Split intents
If an intent has both low precision and low recall, while the recall scores of the other intents are acceptable, it may reflect a use case that is too broad semantically. Try splitting this intent into several intents.
Additional tips to eliminate intent overlap and confusion
- Look for words/phrases common across intents and analyze how many times such words/phrases appear across overlapping intents. Rebalance as required.
- Ensure a minimum of 10% of sentences within an intent have keywords/phrases. Example: ‘Address’ intent could have a minimum of 10% sentences with keywords such as ‘location’ or ‘headquartered’.
- Look for sentence structures and similar patterns across overlapping intents. Rebalance by adding and/or editing sentences.
- Edit sentences (if required) and move sentences from one intent to another as appropriate.
- If there is heavy overlap across multiple intents, group together all sentences from the intents. View it afresh and logically categorize it into clusters.
- Overlap across intents could also be caused by an imbalance in the number of sentences. Wherever possible, it is recommended to have a similar number of sentences across intents.
Conclusion
Constant and frequent usage of Training Analytics will certainly help you in mastering the usage of this valuable tool. As you use it often, you will discover through your trial and error strategies newer tips and techniques to improve data set performance.
Feel free to read our documentation for more information about the Training Analytics feature.
For more information about SAP Conversational AI:
- Visit our web page
- Create your account on our platform
- Engage with our SAP Community
- Read our blogs, follow our tutorials and earn your badge on openSAP
- Ask your questions on SAP Answers
- Read our product documentation
- What our users say
- Follow us on LinkedIn, Twitter, and YouTube
- SAP Managed Tags:
- Machine Learning,
- SAP Conversational AI,
- Artificial Intelligence
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
88 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
65 -
Expert
1 -
Expert Insights
178 -
Expert Insights
280 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
330 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
408 -
Workload Fluctuations
1
Related Content
- Unify your process and task mining insights: How SAP UEM by Knoa integrates with SAP Signavio in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP BTP - Blog 4 Interview in Technology Blogs by SAP
- Deep dive into Q4 2023, What’s New in SAP Cloud ALM for Implementation Blog Series in Technology Blogs by SAP
- ML- Linear Regression definition , implementation scenarios in HANA in Technology Blogs by Members
- SAP Sustainability Footprint Management: Q1-24 Updates & Highlights in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 10 | |
| 9 | |
| 8 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 |