Introduction:
This blog post will take you through the different steps required to load the data from the file stored in Azure Blob container into the SAP HANA Cloud Data Lake. I will use DB Explorer to load the data from .csv file in Azure Blob into Data Lake.
Steps to load the data:
Below are the two Prerequisites
- SAP HANA Cloud account setup with Data lake
- Microsoft Azure Storage Account with container
- First step is to Create a database user and grant the access which will be used to load the data.Go to the DB explorer and open the SQL console. Run the below commands to create the user USER1 and Grant the required permissions to USER1
CREATE USER USER1 PASSWORD Tutorial123 NO FORCE_FIRST_PASSWORD_CHANGE SET USERGROUP DEFAULT;
GRANT HANA_SYSRDL#CG_ADMIN_ROLE to USER1;
GRANT CREATE SCHEMA to USER1 WITH ADMIN OPTION;
GRANT CATALOG READ TO USER1 WITH ADMIN OPTION;
- In the DB explorer left pane, right click on the already added database of DBADMIN user and choose option of "Add database with different user”

- Create a schema for virtual table. Open SQL Console by clicking the SQL option on the top left corner connecting to database for User1
CREATE SCHEMA TUTORIAL_HDL_VIRTUAL_TABLES;
- Create a physical table in data lake using the remote execute call. It should have the same structure as the columns in the file. SYSRDL#CG is the default schema for Data Lake. User can perform DDL operations using the function call as shown below
CALL SYSRDL#CG.REMOTE_EXECUTE('
BEGIN
CREATE TABLE HIRE_VEHICLE_TRIP (
"hvfhs_license_num" VARCHAR(255),
"dispatching_base_num" VARCHAR(255),
"pickup_datetime" VARCHAR(255),
"dropoff_datetime" VARCHAR(255),
"PULocationID" VARCHAR(255),
"DOLocationID" VARCHAR(255),
"SR_Flag" VARCHAR(255));
END');
- Open the remote source SYSRDL#CG_SOURCE from the catalog and select the schema as SYSRDL#CG to view all the tables in Data Lake.This remote source provides flexibility of executing DML operations through virtual table
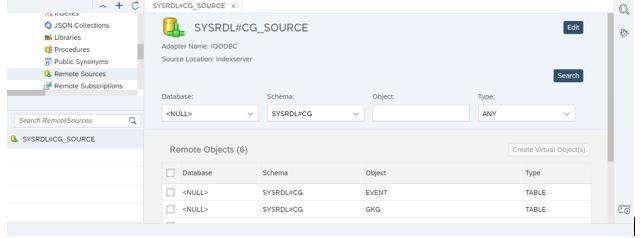
- Select the table HIRE_VEHICLE_TRIP by checking the checkbox and click on create virtual object. Specify the name for virtual object and choose the schema ‘TURORIAL_HDL_VIRTUAL_TABLE’

- Verify that the virtual table has been created in schema TUTORIAL_HDL_VIRTUAL_TABLES. Check the tables from catalog and you would see the virtual table.Also,check the table if its empty before load


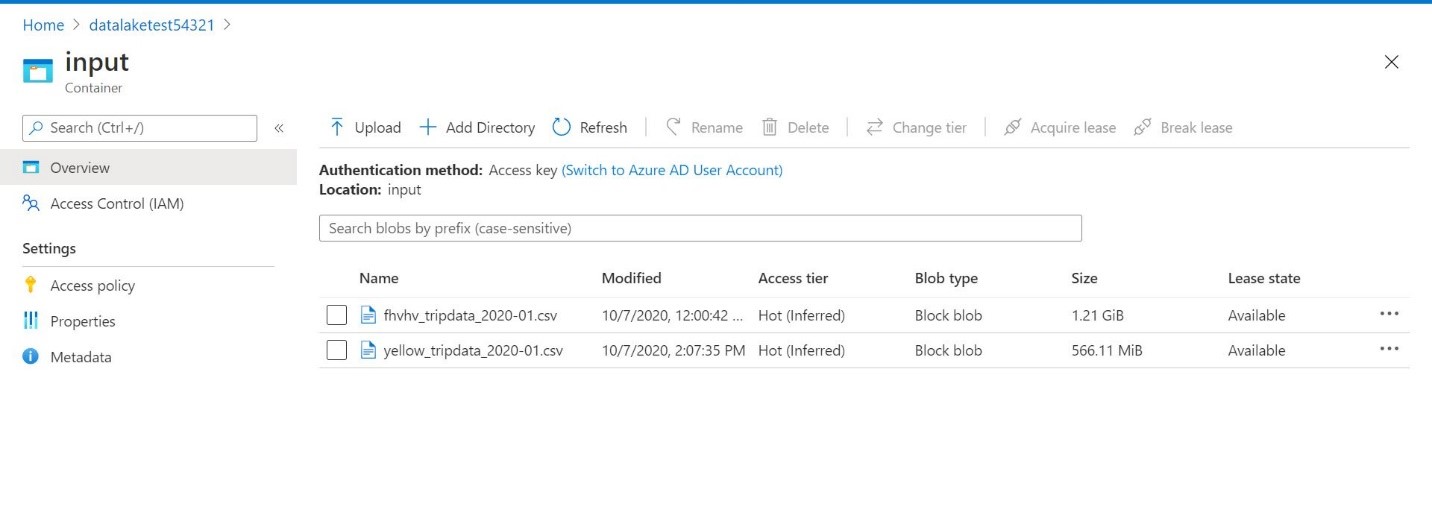
- Now let’s go to Azure to upload the file. Open your storage account from Azure Portal and click on containers

- Upload the csv file in blob container using upload option or by using Azure CLI.I referred the below dataset for this blog post. You can use your dataset https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page
- Switch to DB Explorer and verify the SQL console is still connected to USER1. Load data from the CSV in blob container into data lake physical table by executing the below remote call. Replace <azure_connection_string> of your own azure account by accessing it from the Settings ->Access Keys in Storage Account
CALL SYSRDL#CG.REMOTE_EXECUTE('
BEGIN
SET TEMPORARY OPTION CONVERSION_ERROR=''Off'';
LOAD TABLE HIRE_VEHICLE_TRIP(
"hvfhs_license_num",
"dispatching_base_num",
"pickup_datetime",
"dropoff_datetime",
"PULocationID",
"DOLocationID",
"SR_Flag" )
USING FILE ''BB://input/fhvhv_tripdata_2020-01.csv”
STRIP RTRIM
FORMAT CSV
CONNECTION_STRING ''<azure_connection_string>''
ESCAPES OFF
QUOTES OFF;
END');
It took 115109 ms to upload approx 20 million records from csv file (size of 1.2 GB). If delimiter is comma, you don’t have to specify delimited by option. I have comma separated file so doesn’t require to mention it explicitly
If delimiter is comma, you don’t have to specify delimited by option. I have comma separated file so doesn’t require to mention it explicitly
Otherwise DELIMITED BY option can be used if delimiter is some other character as below
DELIMITED BY ‘’\X09’’ after the using file line
- Verify the loaded data from virtual table


Conclusion:
The SAP HANA Cloud, Data Lake can ingest data from multiple sources like Amazon S3 , Microsoft Azure easily using the Load command. The command is versatile enough to load different file formats. You can explore more on this by going through the documentation link mentioned below
https://help.sap.com/viewer/80694cc56cd047f9b92cb4a7b7171bc2/cloud/en-US
https://help.sap.com/viewer/9f153559aeb5471d8aff9384cdc500db/cloud/en-US
