From this blog post, you will learn the following about the Top-down distribution (TDD) in Account-based COPA. The blog is intended for CO consultants, Business users, etc. This blog discussed the functionality of Top-down distribution in Account-based COPA. TDD is a functionality that is quite complex due to the nature of distribution which can be based on different characteristics. TDD forms as a critical month-end process in management accounting to have P&L breakdown at the maximum granularity.
Content –
- Introduction to Top-down Distribution
- SAP TDD variant Setup
- Characteristic Processing Action
- Selection Criteria
- TDD execution results
What is Top-Down Distribution
Top-down distribution is functionality in COPA, by which the P&L item can be distributed to the finer level details characteristics values set or market segments. Financial posting arising through direct posting, order settlement, COPA assessment like – expense, freight, or sometimes discount does not carry all the relevant COPA characteristics. During the reporting, these items do not contribute due to the absence of the relevant characteristics values. Top-down distribution helps in distributing these lines item to a detail level of the characteristics values set while retaining the once which is already coming from the posting.
For a Top-down distribution to work we need below
- Actual Data/ Source data – This is the actual data, which has only the limited characteristics set like a discount, freight posting, etc.
- Reference Data – This is the data which have the details characteristics values which form as the basis of the distribution
- Distribution key – This the parameter on which the data gets distributed, this could be for example - transaction figures in local currency in the reference line items
Example –
Below is the
actual data from ACDOCA which is posted to a generic characteristic value like company code, controlling area, Plant, functional area.
Note – I have kept the profit center & segment as intentionally blank.
Actual Data - Discount |
|
GL Account |
Com Cod |
Con Area |
Plant |
Func Area |
Prof Cen |
Segment |
$ value |
Prof Seg |
41003000 |
A |
B |
C |
D |
|
|
100 |
1120 |
41003000 |
A |
B |
C |
D |
|
|
200 |
1120 |
Below is the
reference data from ACDOCA which will serve as the reference for the distribution of the actual data.
Here we can observe some important points
- There are some characteristics that are the same as the actual data like company code, controlling area, plant, etc. It is logical to say, here that when we distribute the source data, we want them to be copied as it.
- There are characteristics like functional area, profit center& segment that are different from that of source/actual data. ( actual data have a profit center & segment as blank). Again logically, as these are part of the FI characteristics it should be copied over from the actual data. So we expect TDD result to have these fields as blank
- There is a characteristic division, which is a reference characteristic from the material master.it would get derived during the posting. We can see it for the material TG22 & SP006 but only material -TG22 has the division for SP006 it has been put manually during the posting. For these characteristics, we would logically ask COPA derivation to work and make the posting correct in case of incorrect values put during the reference data postings.

- The final two characteristics Material group & Product are the key here, as we would like to see the discount distributed on these two characteristics. These characteristics are distributed
Reference Data |
|
GL Account |
Com Cod |
Con Area |
Plant |
Func Ar |
Prof Cen |
Seg |
Division |
Material group |
Product |
$ value |
41000000 |
A |
B |
C |
E |
YB101 |
S1 |
00 |
L001 |
TG22 |
-500 |
41000000 |
A |
B |
C |
E |
YB102 |
S2 |
00 |
L004 |
SP006 |
-700 |
41000000 |
A |
B |
C |
E |
YB103 |
S3 |
|
YBPM01 |
SP004 |
-900 |
Distribution key
The $ values posted on the reference data act as a tracing factor for the distribution. The value on the source data is distributed to these characteristics set in the appropriate ratio.
Here for example – The source data have two-line items, which are posted on the same prof segment, therefore, it will be summarized, and the total value is 300$. This 300$ is distributed to the material group and Production combination in the ration of 5:7:9.
So, the outcome of the TDD should be as below –
TDD Output |
|
|
|
|
|
|
|
|
|
|
GL Account |
Com Cod |
Con Area |
Plant |
Func Ar |
Prof Cen |
Seg |
Division |
Material group |
Product |
$ value |
41003000 |
A |
B |
C |
D |
|
|
|
|
|
300 |
41003000 |
A |
B |
C |
D |
|
|
|
|
|
-300 |
41003000 |
A |
B |
C |
D |
|
|
00 |
L001 |
TG22 |
71.42857 |
41003000 |
A |
B |
C |
D |
|
|
|
L004 |
SP006 |
100 |
41003000 |
A |
B |
C |
D |
|
|
|
YBPM01 |
SP004 |
128.5714 |
Important Observations –
- The Actual data is reversed at the prof segment level, we can see it being summarized.
- Characteristics like company code, controlling area, plant, the functional area got copied
- FI related characteristics like Func area, prof center, segment got copied by default
- Division characteristics got rederived & corrected the incorrect posting on the reference data due to derivation.
- Material group & Product combination receive the 300 in the ration of 5:7:9
L001 + TG22 à -(500)/-(500+700+900) *300 = 71.42
L004 + SP006 à -(700)/-(500+700+900) *300 = 100
YBPM01 + SP004 à -(900)/ -(500+700+900) *300 =128.57
SAP TDD variant Setup
- We need to specify the period for the actual and reference data
- The reference base need to be single v/f
- Click on Processing instruction

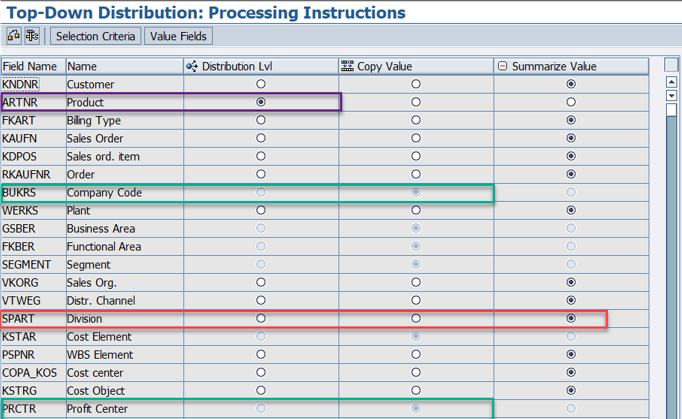
Characteristic Processing Action
We can set up the below characteristics action in TDD
1. Copy – We use this action for the characteristics which we want to carry over to the TDD result from the source posting ex-company code, controlling area, plant
2. Sum – We use this action for the characteristics, which we want to be derived in the TDD results
ex - Division, custom characteristics
3. Distribution – We use this action for the characteristics on which we want to distribute the data
ex- Product, Material group, etc.
Selection criteria
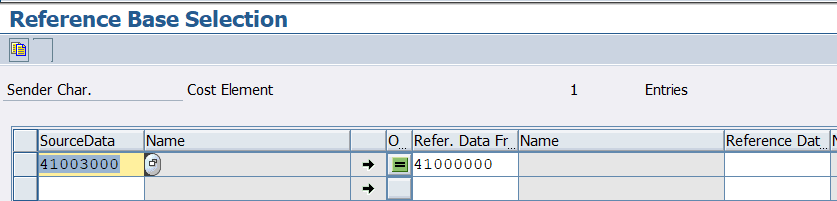
Selection criteria help in selecting the sender/Actual data and the reference data. This help in better performance of the TDD run, as only a selected number of profitability segment, would be selected for the distribution and for the distribution key calculation.
Ex- We can restrict the sender and reference data based on the cost element
We can use * to represent all selection & # for blank selection.

TDD execution results
Source data & reference data

TDD Log

TDD Results

Reference
2236046 - S/4 HANA Finance: Processing instructions in KE28 in account-based CO-PA
