
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Balancing between model performance and automation...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Employee
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
08-05-2020
8:18 AM
There are very few real-world data which have the quality for training a Machine Learning (ML) model that can accurately classify hundreds of categories to a granular level. In this blog post, find out how you can make use of Service Ticket Intelligence's model performance simulation feature to help find the right balance between category granularity and model performance, such that your business will still benefit from the automation of triaging tickets.
In most scenarios, ticket distribution across categories tend to be imbalanced, where dominant categories take up 70-80% of the dataset.
The typical result after training a classification model on real-world service tickets is that dominant categories tend to have better prediction accuracies. In contrast, the model almost always mis-classifies minority classes as one of the dominant categories, resulting in false positives.
If we can get ML to predict and classify the dominant categories well enough, it would already have made a significant impact on automating business workflows. As such, the decision lies in balancing between category granularity and model performance, such that the business still benefits from automation in triaging tickets.
In order to decide on what confidence threshold to set, Service Ticket Intelligence has released a model performance simulation feature in 2007, whereby a subset of training data is used to simulate and arrive at the prediction accuracy and automation rate given various prediction thresholds.
Results of the simulation can be retrieved by making a call to Service Ticket Intelligence's GET /model/accuracy endpoint and by providing a confidence threshold query option from 0.0 to 1.0 as follows.
Details such as accuracy, precision, recall, f1 scores, probability of exceed threshold (automation rate) confusion matrix, etc. will be returned given a confidence threshold.
Given results from the simulation, decide on the following:
Based on the outcome of the above questions, identify a confidence threshold value that aligns with a satisfactory model performance and automation rate.
In the example below, we used 4000 test tickets to generate the confusion matrix at no threshold and at 0.7 threshold setting. Without a threshold setting, the overall accuracy of the model is 64%. With a threshold setting of 0.7, prediction accuracy increases to 83% a trade-off in terms of automation rate, where 54% of tickets would have automated predictions.
Service Ticket Intelligence provides a confidence score (probability that the predicted category is correct) with each category prediction. An application/client retrieving predictions can make use of the confidence score as a basis to accept or reject the prediction based on the identified confidence threshold to adopt.
Using the example below, if the decision has been made adopt a confidence threshold of 0.5, the application will accept and populate the category field automatically based on the prediction returned by Service Ticket Intelligence. For predictions with confidence score < 0.5, the prediction will be rejected and category field will not be populated.
In the following C/4 Service Cloud example, this setting would ensure that predictions would be populated into the ticket service category field only when the confidence score is higher than or equal to 0.6.
Classification of categories at the finest level of granularity does not always yield the highest business outcome. There is a need to strike a balance between model performance and level of automation to get maximum business benefit with Service Ticket Intelligence.
Service Ticket Intelligence is also available on SAP Cloud Platform as a free trial. Find out how you can set up your own trial account with Service Ticket Intelligence here and give the model performance simulation feature a try today!
Get Model Accuracy input parameters
Get Model Accuracy object
Get Model Accuracy validation results
Real world ticketing data
In most scenarios, ticket distribution across categories tend to be imbalanced, where dominant categories take up 70-80% of the dataset.

The typical result after training a classification model on real-world service tickets is that dominant categories tend to have better prediction accuracies. In contrast, the model almost always mis-classifies minority classes as one of the dominant categories, resulting in false positives.
Category granularity for business to benefit from automation
If we can get ML to predict and classify the dominant categories well enough, it would already have made a significant impact on automating business workflows. As such, the decision lies in balancing between category granularity and model performance, such that the business still benefits from automation in triaging tickets.
Deciding on confidence thresholds
In order to decide on what confidence threshold to set, Service Ticket Intelligence has released a model performance simulation feature in 2007, whereby a subset of training data is used to simulate and arrive at the prediction accuracy and automation rate given various prediction thresholds.
Execute GET /model/accuracy with confidence threshold query
Results of the simulation can be retrieved by making a call to Service Ticket Intelligence's GET /model/accuracy endpoint and by providing a confidence threshold query option from 0.0 to 1.0 as follows.

Details such as accuracy, precision, recall, f1 scores, probability of exceed threshold (automation rate) confusion matrix, etc. will be returned given a confidence threshold.
Given results from the simulation, decide on the following:
- Which categories are important for ML to pick out accurately, at the expense of having some false positives? (prioritize recall rate over precision)
- Which categories are important for ML to be very precise, at the expense of not being able to always recall these tickets? (prioritize precision rate over recall)
- f1 score is a harmonic mean of the precision and recall score, representing a balanced score between the two. (balancing between recalling categories and being accurate)
Based on the outcome of the above questions, identify a confidence threshold value that aligns with a satisfactory model performance and automation rate.
Example
In the example below, we used 4000 test tickets to generate the confusion matrix at no threshold and at 0.7 threshold setting. Without a threshold setting, the overall accuracy of the model is 64%. With a threshold setting of 0.7, prediction accuracy increases to 83% a trade-off in terms of automation rate, where 54% of tickets would have automated predictions.
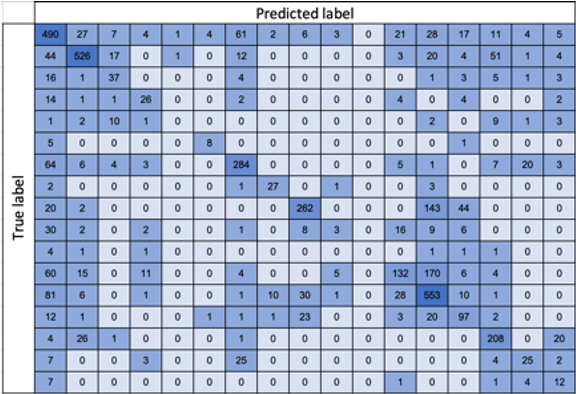
- No confidence threshold setting
- 64% accuracy
- 100% automation rate

- 0.7 confidence threshold setting
- 83% accuracy
- 54% automation rate
Making use of the identified confidence thresholds during predictions
Service Ticket Intelligence provides a confidence score (probability that the predicted category is correct) with each category prediction. An application/client retrieving predictions can make use of the confidence score as a basis to accept or reject the prediction based on the identified confidence threshold to adopt.
Using the example below, if the decision has been made adopt a confidence threshold of 0.5, the application will accept and populate the category field automatically based on the prediction returned by Service Ticket Intelligence. For predictions with confidence score < 0.5, the prediction will be rejected and category field will not be populated.
In the following C/4 Service Cloud example, this setting would ensure that predictions would be populated into the ticket service category field only when the confidence score is higher than or equal to 0.6.

Conclusion
Classification of categories at the finest level of granularity does not always yield the highest business outcome. There is a need to strike a balance between model performance and level of automation to get maximum business benefit with Service Ticket Intelligence.
Service Ticket Intelligence is also available on SAP Cloud Platform as a free trial. Find out how you can set up your own trial account with Service Ticket Intelligence here and give the model performance simulation feature a try today!
Additional details on usage
Get Model Accuracy input parameters
Get Model Accuracy object
Get Model Accuracy validation results
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
299 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
344 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
423 -
Workload Fluctuations
1
Related Content
- Start page of SAP Signavio Process Insights, discovery edition, the 4 pillars and documentation in Technology Blogs by SAP
- Introducing Blog Series of SAP Signavio Process Insights, discovery edition – An in-depth exploratio in Technology Blogs by SAP
- Unify your process and task mining insights: How SAP UEM by Knoa integrates with SAP Signavio in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP BTP - Blog 4 Interview in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 40 | |
| 25 | |
| 17 | |
| 14 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |