
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Connecting to custom sources with a JavaBean
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
davidmobbs
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
07-01-2020
3:10 PM
Executive summary
The SAP BusinessObjects BI Platform implements support for a wide variety of datasources. However, there is always a datasource for which a connector is not available.
JavaBean is one of the solutions to connect the BI Platform to such datasouces. It enables customers or partners to write their connectors using the Java language. These connectors can then be used as datasources to fuel WebI reports.
The JavaBean features described in this blog are shipped with SAP BusinessObjects BI Platform 4.3 (see BI 4.3 new data sources). If you are using a previous release, please upgrade before attempting to replicate this article.
This document aims to :
- Help you identify situations where writing a JavaBean is the right solution for you
- Demonstrate how to write a JavaBean, based on a real-world example
- Explain how to integrate the JavaBean into the product, and create a report consuming it.
Identifying the right solution
Before jumping head-first into writing code, it is best to ensure that the right solution is chosen.
The BI Platform was built for relational datasources. In this world a database can expose a set of tables, which can be queried using the SQL language. Using this language the BI Platform filter, joins and aggregates data from different tables.
Connecting to a relational datasource assumes the datasource implements all these features, including a runtime for the SQL language. This can be very costly to implement.
JavaBean, on the other hand, is designed to be simple to implement. As a consequence support for a query language or query constructs is deliberately not part of this technology. A JavaBean’s goal is to return a table to WebI. Any extra filtering, joining or calculations should be implemented using the WebI calculator directly in the report.
So, when connecting to a relational datasource, it is best to check out relational connectivity options. If the datasource is supported in the SAP BI Platform PAM, it is a no brainer and the supported connector should be used. For other relational datasources, it is possible to tweak configuration files to obtain a custom relational connector.
However, this leaves out the world of non-relational datasources: files, custom servers, machines, web services… These can provide valuable data, but not a full relational implementation. JavaBean is the right choice for these:
- If it can be accessed in Java, then a developer can implement a JavaBean
- Implementation cost is reduced by lowering the feature set we expect to the bare minimum: a table
Writing a JavaBean
To demonstrate how to write a JavaBean, it is best to rely on a real-world example. Source code extracts from this chapter are from a working bean Full source code can not be copied here as it would be too lengthy, but key points are demonstrated.
Introduction and goal
We are currently living a crisis where the COVID-19 has grown into a pandemic. Major health organizations are now publishing data about the state of the pandemic, and it would be interesting to be able to analyze this data using our usual BI tools.
The dataset we are going to analyze is the data published by the European CDC, at https://www.ecdc.europa.eu/en/publications-data/download-todays-data-geographic-distribution-covid-1.... Our goal is to connect to the data live from WebIntelligence
The data is available in JSON, unfortunately the BI platform cannot connect to JSON datasets. Being able to connect to the data using the URL would enable live reports on the latest data.
The dataset is basically a table, is not accessible through a relational database, but can be accessed through code. This fits nicely within the scope for a JavaBean.
In order to make the bean reusable, it would be better to enable it to access data at other locations. However, if we attempt to build this, we may encounter any kind of JSON data, which would be a huge task to undertake. So our approach is to expect the datasource to return an array of JSON objects that have the same flat structure (no nested objects), but instead of downloading directly from the URL, we invoke a script (through a scripting engine) whose purpose is to reformat the JSON for the bean.

As a consequence, the bean can be used to access a much broader set of data sources than just the COVID dataset we started our investigation with.
To summarize the requirements for our bean are :
- It can call a scripting engine and request execution of a script.
- The output of this execution is written to the console, and is expected to be a JSON array of objects that share the same flat structure.
- The bean converts this array into the relevant structures for ConnectionServer use.
General JavaBean structure
Before starting to write a bean, we shoud understand how it is structured and how it is consumed by ConnectionServer and the BI Platform consume it.
A JavaBean is basically a Java class. The name JavaBean is mostly historical: our previous implementation of the connector relied heavily on the JavaBean specification. This dependency has been lifted, but the name remained. For the sake of simplicity, the rest of this document uses the “bean” term to refer to the Java class consumed by the JavaBean driver.
The goal of the JavaBean driver is to expose methods from the bean as stored procedures. If the method has parameters, then these are exposed as stored procedure parameters (only scalar types are supported, ie strings, numerics and date/time).
In order to return data to ConnectionServer, methods are expected to return a tabular ResultSet (as defined in the JDBC specification).
Finally, in order to enable ConnectionServer to instanciate and initialize the class, the bean must implement a constructor with no arguments and the initialize method (described later).
The schema below summarizes the requirements to enable a class to be exposed through the JavaBean driver :

Arguments can be passed to the bean in 2 locations: at initialization time through the initialize method, or to each stored procedure when it is being called. These calls are associated to different artefacts (and so, called in different circumstances):
- Initialize is associated with the connection object. As such it is called when the bean-based connection is called or loaded.
- Stored procedure arguments are associated with the stored procedure, and so are passed only when the user consumes the corresponding stored procedure.
Each bean writer is free to have the user communicate arguments to his bean the way he prefers. In our case, we will associate a connection with a scripting engine (for instance NodeJS), and have the desired script passed to the stored procedure that actually invokes the script.
These design choices are made, so we are now ready to start writing our bean :
public class ScriptingBean {As can be seen, there are no specific constraints on the bean class itself: it does not have to derive from a specific class, or implement interfaces(s). So, in our case, it can simply be a class.
Constructor with no arguments
The bean class must implement a constructor with no arguments, which will be used by ConnectionServer to create an instance of the bean at runtime :
public ScriptingBean() {
}
The code to initialize the bean can reside in the constructor, in the initialize method, or split between them. The advantage of the initialize method is that it receives information from ConnectionServer, so in our case our initialization code resides in the initialize method.
The initialize method
Once ConnectionServer has created an instance of the bean (using the constructor we just wrote), it initializes it. The bean is going to be used as a connection (as in “connection in Information Design Tool), and, as such, the initialize method has arguments that enable the bean to retrieve configuration and connection information:
public void initialize(Context context, String initString, Properties properties) throws ScriptingBeanException {
loadEngine(initString);
}
This is the only method a bean must implement: the name is imposed, as well as the argument list. It is worth noting that the Context class is part of the ConnectionServer jar (located in SAP BusinessObjects Enterprise XI 4.0\java\lib), so bean implementors must include it in their projects.
Arguments for the initialize method are:
- Context, which is basically ConnectionServer configuration information for the JavaBean driver. In the vast majority of cases it is of no use and can be ignored.
- initString is the bean initialization string. This parameter is exposed in the Connection UI (in Information Design Tool), and is passed as is to the bean. Bean implementors are free to define the contents and format of this string for their beans… and document it.
- Properties contains the set of connection parameters that have been entered by the user in the Connection in Information Design Tool. Most notably, it contains the user and password if authentication is used. If credentials mapping is used, the mapping takes place before the bean is called, and the properties contain the actual database user and password.
In our case, a connection is simply a pointer to a scripting engine. This is configurable, so the initialization string simply contains the name of the target scripting engine, and the initialize method loads the relevant information from the configuration file.
It makes sense to store bean configuration in the ConnectionServer folder structure, so beans may need to identify where ConnectionServer is installed. This is possible by reading the businessobjects.connectivity.directory environment variable, using code that may look like this :
String fileName = System.getProperty("businessobjects.connectivity.directory") + separator + "javabean" + separator + "scriptengines.json";Finally, the bean may throw exceptions (in our case, ScriptingBeanException). The BI Platform products handle such exceptions and display them to the end user. In case of issues exceptions also get logged, so it is recommended to make use of exceptions to raise issues when they occur.
At this stage our bean can be loaded in the BI Platform, but it is not able to expose any data.
Methods as stored procedures
Writing a method that is exposed as a stored procedure is quite easy: any method matching the requirements is exposed as a stored procedure, under the method’s name.
The requirements are :
- Be public
- Have only scalar parameters (strings, numerics, dates/times/timestamps
- Return a ResultSet object (as defined in the JDBC specification)
So, in order to be able to invoke a script and return its results, we can simply write:
public ResultSet runScript(String script) throws ScriptingBeanException {
// execute the script and . . .
// everything went fine, now return a result set
return new JsonResultSet(data);
}
The crucial part resides in implementing the ResultSet (our JsonResultSet object) to transform original data into the expected tabular format. This is explained in the next chapter.
The method will be exposed as a runScript stored procedure.
It is also worth noting that throwing exceptions is possible from these methods as well. Again, the BI Platform would raise them to the end user. It is good practice to take advantage of this feature as it improves usability for the bean.
ResultSet and its metadata
Methods that are to be exposed as stored procedures must return an object that implements the ResultSet interface. As can be seen in the code snippet above, we have implemented it under our class JsonResultSet.
This may seem a very tedious task as the ResultSet interface describes dozens of methods. In addition to this, the BI Platform also relies on the ResultSet to return its metadata, which means implementing the ResultSetMetaData interface.
So it is best to start from an existing implementation and replace it with your own rather than trying to rewrite this class. Full source code to the bean described here is provided, and the product ships with a sample for Google BigQuery (different from the full BigQuery connector, for which source code is not provided).
Bean implementors should also keep in mind that the BI Platform only uses a small subset of the ResultSet interface, so attempting to implement all methods is essentially waste. If in doubt about whether or not to implement a specific method, it is possible to raise an exception stating the method is not implemented: if the BI Platform requires that method, the exception will surface during a workflow.
Parts of the ResultSet interface that must be implemented are:
- metadata (the ResultSetMetadata class)
- column list, with names and datatypes
- ability to position at the beginning or end of the result set, and move forward in the result set. Other iteration types need not be implemented:
- first(), isFirst() and beforeFirst()
- afterLast() and isAfterLast()
- next()
- ability to read data from the current row. All get methods for scalar types the bean implements. For instance, if metadata returns only string types, then only string getters need to be implemented. It is also worth noting that the BI Platform only handles scalar types, so streams, blobs, refs, etc can be safely ignored
At this stage the bean implementation is complete. In our case the bean should expose one stored procedure named runScript, taking one argument: the script to be run.
Testing and packaging a JavaBean
At this stage the bean can (and should!) be tested.
The workflow that should be tested is:
- create an instance of the bean using the constructor with no arguments
- call initialize with the desired parameters on the instance
- call the method(s) of the JavaBean that would be consumed in the BI Platform
- check the contents of the resultsets, knowing that the BI Platform will retrieve the most accurate data possible for each column: if a column is declared as numeric, the BI Platform will do its best to read numbers from it.
The testing code provided with the ScriptingBean implements this workflow, and handles all datatypes the BI Platform may expect.
To be consumed by the BI Platform, the bean needs to be packaged as a JAR file. It is possible to ship multiple JAR files for a bean, but they should all be provided together. Bean implementors should simply make sure that a bean and all its dependencies can be provided as a set of JAR files.
For its consumption, bean implementors must also provide:
- the bean class name (where the methods to be consumed reside). This should be the fully qualified class name, including the package
- format of the implemented initialization string (refer to the initialize method chapter)
Consuming a bean in the BI Platform
In order to deploy a bean, administrators just need to go to the SAP BusinessObjects Enterprise XI 4.0\dataAccess\connectionServer\javabean folder, and create a folder in which the bean’s JAR files are stored (all JAR files required by the bean must be stored in this same folder). The folder name should be simple, and consistent across deployments as it is needed to create connections.
Any configuration files can be deployed as well, so in our case we are copying the files as below:
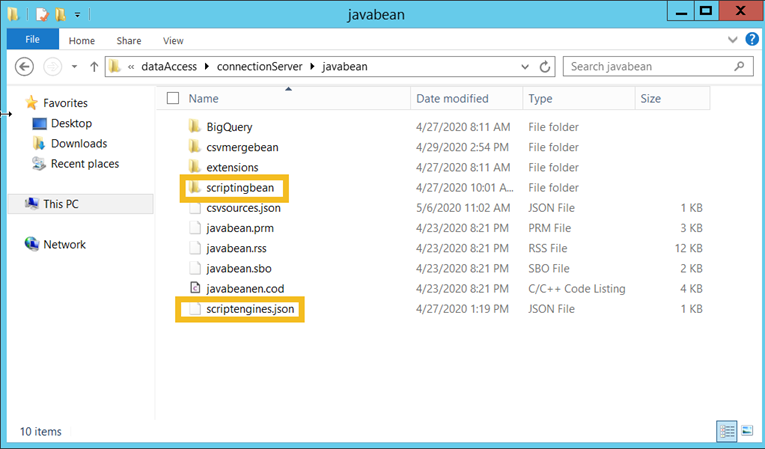
As always, the files need to be copied on all systems where the bean is to be used, ie clients and servers. Once the copy is complete, client tools and servers should be restarted.
Once the copy is complete, it is possible to create a connection using the Generic JavaBean connector in Information Design Tool. The connection wizard slightly differs from the usual relational connectors:
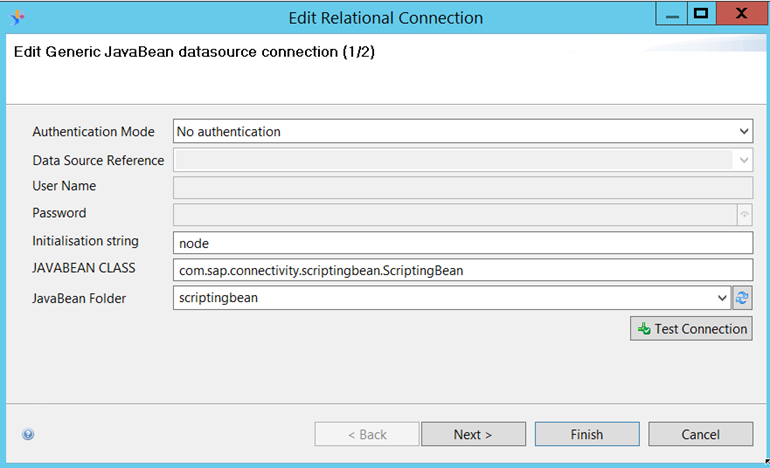
This dialog can be read with the contents of the initialize method in mind :
- authentication mode, datasource reference, user and password are the authentication parameters for the datasource. In our case, authentication is not needed so these can be set to no authentication.
- Initialization string is the initialization string, passed directly to the initialize method. This example is a simple value, but bean implementors are free to implement specific formats and parsers to pass multiple values.
- JavaBean class is the name of the fully qualified name of the class to be consumed through this connector.
- JavaBean folder is the name of the folder containing our JavaBean. The folder must contain all the required JARs to load the JavaBean class from the previous parameter.
Once the connection is created, it can be consumed in a data foundation. The data foundation exposes one database which has the class name, and a stored procedure for each of the methods the bean exposes :
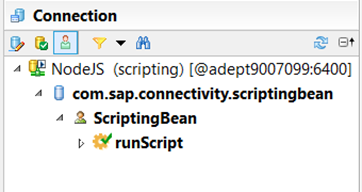
When a user drags the stored procedure unto the universe structure, he is prompted for parameters, which match the method parameters :
public ResultSet runScript(String script)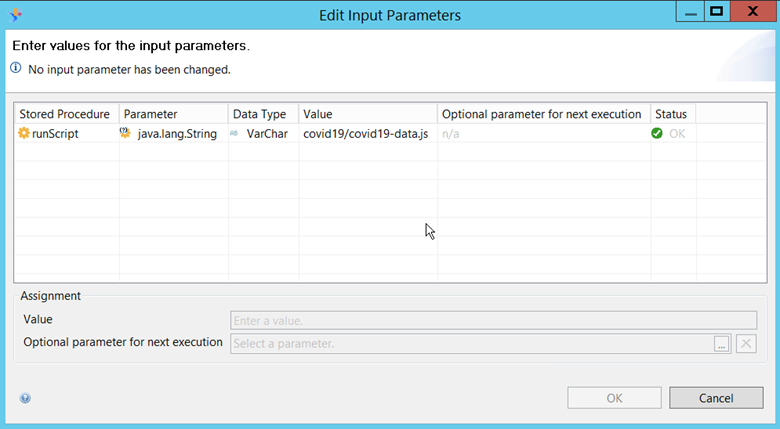
Once the parameters are confirmed, the method is run and the resulting table is inserted in the universe structure.

The table is just like another table, with the limitations that come from stored procedures:
- It cannot be joined to other tables
- Calculations, aggregations and filters cannot be used on the table
Since the WebI calculation engine implements these features, the end-user can benefit from the same feature set as with other datasources. Universe and report designers should simply take these limits into account :
- Result set size limit should be switched off at the universe level to enable the calculation engine to retrieve and process the entire data set.
- WebI reports based on JavaBeans are likely to rely heavily on variables if they need to compute measures.
Other features should work as usual, and so the JavaBean should open a world of possibilities for data access:
- Self-sufficient datasources, like the scripting bean this article relied on.
- Datasources that extend existing datasets: for instance a WebI report designer could add a JavaBean-based data provider to add a detail about a dimension present in his WebI report.
For instance, this is the kind of report that was generated on COVID-19 data using the bean described in this post :

Full sources to the bean described here, including the universe and webi document, are available on this page .
The BI Platform also ships with a sample demonstrating a JavaBean connecting to Google BigQuery, for which sources are available at <install folder>\SAP BusinessObjects\SAP BusinessObjects Enterprise XI 4.0\dataAccess\connectionServer\DDK\examples\BigQueryJavabean.
Enjoy !
Labels:
5 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
273 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
324 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
401 -
Workload Fluctuations
1
Related Content
- 10+ ways to reshape your SAP landscape with SAP BTP - Blog 4 Interview in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
- Possible Use Cases Of ECC & S/4HANA Connection With SAP Datasphere. in Technology Q&A
- SAP Datasphere - Space, Data Integration, and Data Modeling Best Practices in Technology Blogs by SAP
- Taking Data Federation to the Next Level: Accessing Remote ABAP CDS View Entities in SAP HANA Cloud in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 11 | |
| 10 | |
| 9 | |
| 9 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 5 |