
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Data ingestion from SAP HANA cubes into SAP Analyt...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-30-2020
3:49 PM
Abstract.
In this article I would like to share some insight into the data ingestion techniques from SAP HANA cubes into SAP Analytics Cloud data wranglers.
When it comes to SAP HANA the focus will be on using different SAP HANA cloud services available on SAP Cloud Platform [SCP] Cloud Foundry [CF].
In this instalment, I shall start with SAP PSA (Persistence Service) HANA service on Azure CF.
Next will follow the HaaS CF and eventually the tally will culminate with the latest HANA Cloud service on [CF].
When it comes to SAP Analytics Cloud the product features I will be making use of are described in the Feature Scope Description (FSD) document.
Let's go.
Every analytical tool has its sweet spot. SAP Analytics Cloud [SAC] supports natively direct connectivity to a number of SAP Applications as data sources. SAP HANA is one of them.
However, it has been brought to my attention that there are use cases where the live connectivity is not desirable especially with business applications that require data be fully vetted and curated at all times and where the content providers need to impose stricter controls over the data/content being delivered to the consumers.
The live SAP HANA connection has been an outspoken advantage that SAC has had over its competition.
Live or direct connectivity means not only there is no data replication but it also implies a semantic knowledge of the data source.
But, and this is maybe of a less common knowledge, with SAC one can create queries and acquire data directly from SAP HANA cubes with no ETL tool required.
(This resembles a lot the universe/query paradigm found with WebIntelligence for example.)
How is it possible ?
SAC sports a long list of so-called acquired data sources. Again, SAP HANA is one of them.
SAC is a cloud appliance sitting in its own SAP Cloud Platform [SCP] sub-account (on either Cloud Foundry or SAP Neo).
And this is where the SAP Cloud Connector [SCC] comes into the mix as it allows to leverage the cloud to on premise connectivity through the SCP connectivity service.
Question. But SCC provides the secure communication tunnel only. So what about the data itself? How do one gets connected to a data source?
Answer. That's where the SAC Cloud Agent [C4A] comes into play.
The C4A is essentially a connectivity broker - "the connection server" - a witty piece of middleware that understands the semantics of the underlying data sources.
C4A is provided as a ready-to-deploy servlet. It is best deployed on the on-premise side together with SCC.
Let's have closer look on how to acquire data from SAP HANA Service (PSA) available on SCP Cloud Foundry on Azure .
As a quick reminder all SAP HANA services on Cloud Foundry come without application runtime (no XSA). And with the exception of the PSA-based HANA service they do not offer XSC either.
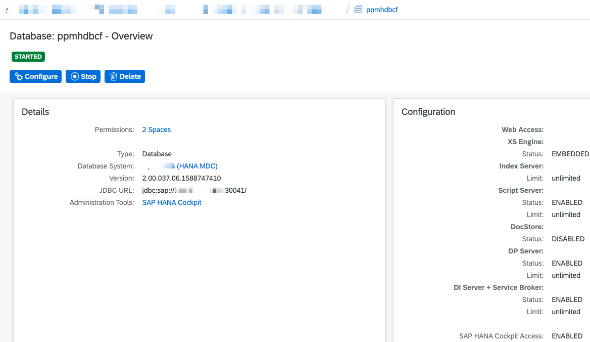
That makes live connectivity a little bit more cumbersome because it implies the deployment of the HANA Analytical Adapter [HAA] which is a dedicated java application that implements the SAP Information Access (InA) REST protocol required to establish the live connectivity.
But if the data acquisition is a viable option it may help simplify the data ingestion process and help keep the cost low (by eliminating the need of using the CF application runtime for HAA deployment)
JDBC endpoint
In a nutshell, all that has to be done is to expose the jdbc SQL endpoint of the SAP HANA service.
With PSA HANA Service the jdbc SQL endpoint is already exposed on CF. However, in order to be able to use it one would need to create and bind a CF application to the service first.
This is beyond the scope of this article but if there is interest from the readers to cover this approach I might do it in one of the next episodes. so please do vote:).
Alternatively, one can use the SCC to connect to the CF sub-account where the HANA PSA-based service has been provisioned to and then create a service channel to the HANA instance.
As we have already made use of SCC to enable cloud to on premise connectivity from SAC side we shall re-use the same SCC for the service channel sake.
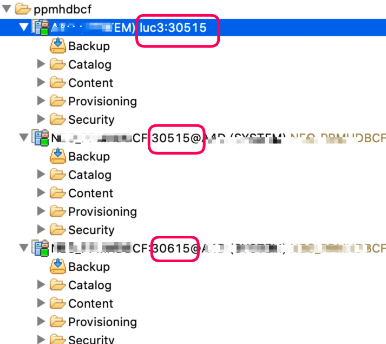
We can create several service channels to the same [tenant] database as depicted below.

service channels
For instance, this is how it looks like with SAP HANA Studio.
There are 3 different variants of connections definitions using two different service channels ports (30515 and 30615).
It is worth noticing is that all 3 connections point to one same tenant database (the system database is managed by SAP and cannot be accessed via the service)
SAP HANA Studio
OK. From now on one can attempt to create a SAP HANA import connection with SAC.
We shall focus on the two following options:
- connect to _SYS_BIC schema and get access to the cubes there [with a "classic" database user]
- connect to a HDI container and acquire data from the container's cubes [using the user access details from the service key of the HDI container service instance.]
The first option may be very convenient; when it comes to migrating from on-premise HANA development into Cloud Foundry universe.
The latter (and preferred) option allows to fully unleash the power of hardware deployment infrastructure with the focus on container shipment as opposed to package delivery.
[_SYS_BIC]
In order to demonstrate the first approach I uploaded a well known HANA SHINE package into the database.
This mimics a typical SAP HANA development paradigm where developers would work on packages that may contain a number of cubes each.
(on a side note: the data would be loaded into HANA tables either via HANA SDI engine or any other ETL tool (SAP SLT, SAP Data Services, SAP DataHub etc) - this is not in scope of this article)

Let's try to connect the dots.
Next step is with SAC and all that has to be done there is to create a new SAP HANA connection. (That may require having an administration profile granted to your SAC user.)

Once we have a working connection it is time to create a model [that will contain business information required for story telling.]

You may pick up any cube available for this connection and then build a query to further refine the data you are about to bring into SAC model.

Once your query is built you will execute it.
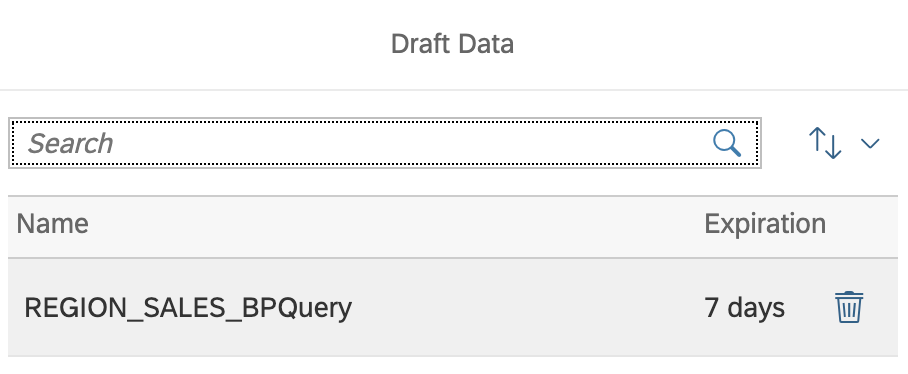
This will start data acquisition into a new data wrangler that will be securely kept by SAC for a period of up to 7 days:
Data wrangler
Data wrangler is an important concept. It holds the acquired data.
All the subsequent operations will be performed on the SAC tenant itself.
Data wrangler
Data model and smart discovery.
From now the data can be further curated and eventually a model will be created.
The data in the model can be periodically refreshed through scheduling.
The model can be used to build stories either manually or automatically leveraging the the smart discovery functionality.
For instance you may have decided to run a smart discovery based on Netamount measure.
SAC will then generate a story with 4 pages containing the overview, the influencers, the outliers and an interactive simulation page.
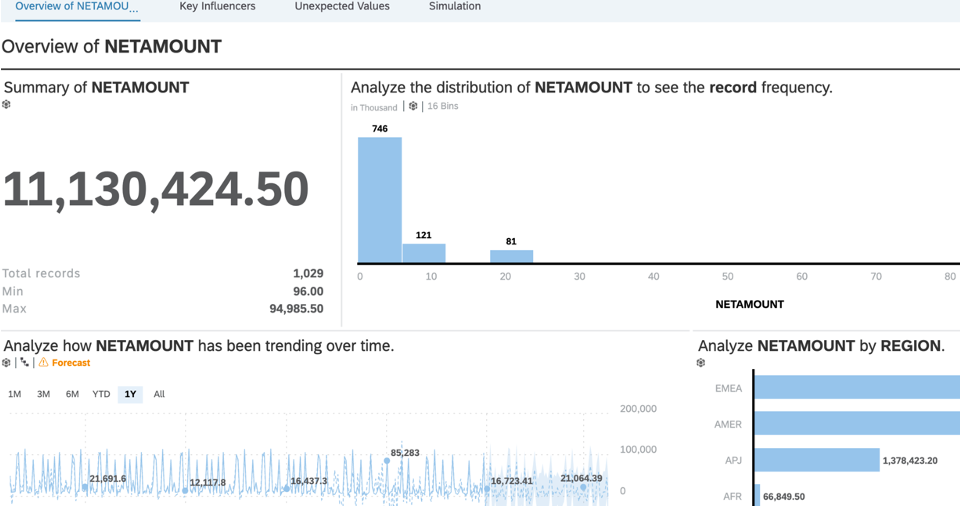
SmartDiscovery
OK. That concludes the part 1. I hope you have enjoyed reading it. Looking forward to comments.
best wishes
Piotr Tesny
PS.
In the second instalment I shall demonstrate how to import data from an HDI container (option 2 above)
Labels:
1 Comment
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
273 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
324 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
402 -
Workload Fluctuations
1
Related Content
- Extracted SAP Ariba Analytical Reporting API Data Using SAP Integration Suite and Imported into SAP Datasphere in Technology Blogs by Members
- Deliver real-life use cases with SAP BTP - Sustainable Waste Management Solution for Healthcare - Part2 (deep-dive) in Technology Blogs by SAP
- Deliver real-life use cases with SAP BTP - Sustainable Waste Management Solution for Healthcare - Part1 (overview) in Technology Blogs by SAP
- OUT NOW: SAP Signavio November 2023 release - Build a future-ready organization with value accelerators, faster analysis, and increased usability. in Technology Blogs by SAP
- JETZT VERFÜGBAR: SAP Signavio November 2023 Release - Bauen Sie ein zukunftsfähiges Unternehmen auf - mit Value Accelerators, schnelleren Analysen und verbesserter Benutzerfreundlichkeit in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 12 | |
| 9 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 6 | |
| 4 |