In this scenario we are going to work into the creation of a simple (and simplistic) Covid19 risk calculator for Mexico, using
Mexico government open data. Using this data, we will train a logistic classification model so we can predict death risk based on Mexican pandemic behavior.
We start going to our Data Intelligence Launchpad so we can create a new connection on Connection Management tile. We put our data in an S3 bucket, so we have to create an S3 connection. In addition, we create a connection to our HANA system.



Now, we are going to put that a CSV file from S3 bucket to a HANA table using Data Intelligence Modeler capabilities. You can find this Data Intelligence Modeler from Data Intelligence Launchpad too.
We create a new graph to define this pipeline where we are reading a file from S3 and putting that file content into a HANA new table. You may want to use and make proper configurations for "Structured File Consumer" and "Table Producer" operators.

Now, this is how that CSV it looks on a HANA table.

This CSV file contains information for every person that has been in touch with mexican government. Mexican government registrates several features and descriptors like age, gender, from where is the patient coming from (another hospital, private institution, etc), if the patient has obesity, pneumonia, smokes, etc.
Now, we need to make some adjustments to the data and perform a creation for some new variables as we want to model those people that unfortunately died. We can identify this people with "FECHA_DEF" column distinct to '9999-99-99'. New variables are calculated based on how many days has been between feeling sick and going to the hospital, and how many days has been this person on the hospital before dying. With this data set we are going to create a new table that will be used to train a classification model.
To start with training tasks we go to Machine Learning Scenario Manager from Data Intelligence Launchpad and create a new scenario.


Once that the scenario is created, we can go directly to create a new pipeline.

This pipeline creation is going to take us to Data Intelligence Modeler again; we can configure HANA ML Training operator where you can choose which algorithm you want, where is your training data set, where is your system connection configuration, etc. Every configuration relays completely on each Predictive Analytics Library that you can choose.
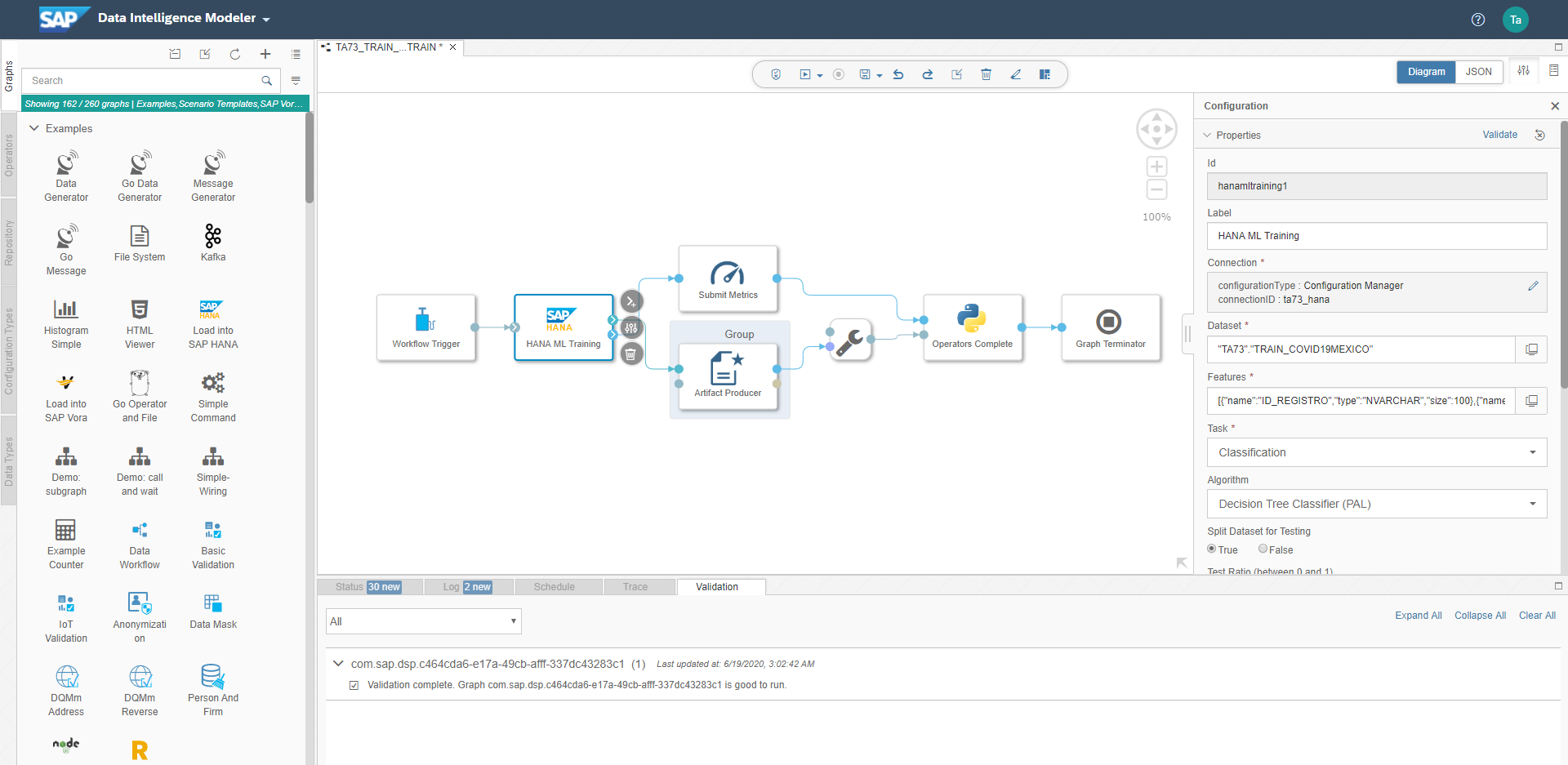
After configuring and saving that graph, we can go back to Machine Learning Scenrio Manager to execute our pipeline and complete execution wizard. This completion lets you save the trained model.



To complete this scenario, we need to define the inference pipeline that will use our trained model. It is basically the same process that creates the training pipeline, and a similar configuration.

You are going to see the Modeler UI, and you have to set configurations for HANA ML Inference operator.

After this configuration, just as training execution, you have to deploy your pipeline from Machine Learning Scenario Manager and follow wizard assistance to select your trained model.


When everything finises, you are going to have an URL where you can make REST requests to test this inference service.

For example, we can use Postman to create a new POST request and copy service URL from Machine Learning Scenario Manager.

Watch for the "v1/inference" text that we added to copied URL. Go to "Auth" tab on Postman and select "Basic Auth" to define your connection credentials. These credentials are Data Intelligence credentials including tenant name.

Define this header so you don't get an CORS error.

Our system is ready to inference but we need some values to calculate the response. Imagine the next scenario:
Patient: Carlos, 75 years old, living in state "09", he is a man, he has been hospitalized by 3 days, he begun with symptoms 4 days before going to the hospital, he has not related symptoms but pneumonia, he hav had contact with someone that was Covid19 positive, and he is not yet in intensive care unit. What is his prediction given these conditions?
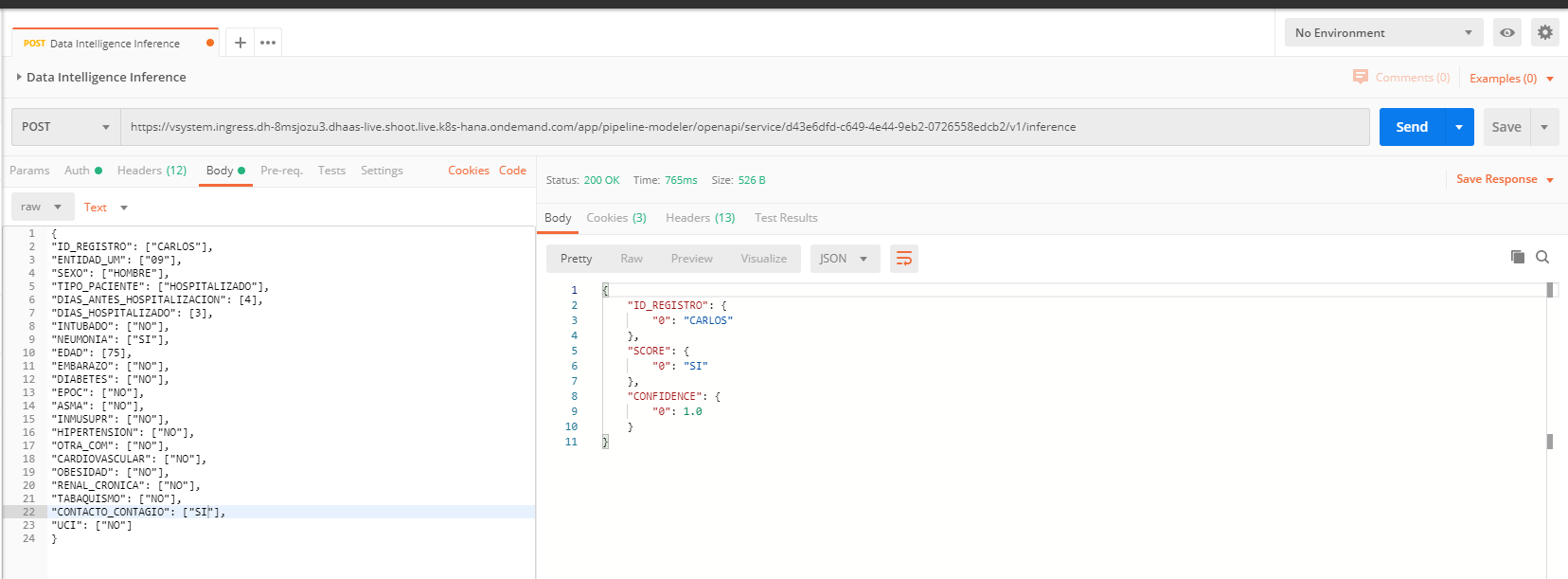
Unfortunately, given these conditions, he has a lot of probabilities to die. Of course, this is just a model, and you can train a lot of models and compare them to see which one gives you a better behavior.
Here we were working with a very simplistic model that sometimes trend to trivialize the conditions and to give a very radical "yes/no" answers.
