
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- HANA Data Strategy: Data Ingestion including Real-...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member22
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-18-2020
8:17 PM
This is part of the HANA Data Strategy series of BLOGs
https://blogs.sap.com/2019/10/14/sap-hana-data-strategy/
HANA Data Ingestion
Product: SAP HANA 2.0 SP04/SP05 and SAP HANA Cloud
Feature: HANA EIM (SDA/SDI/SDQ), HANA SDS
HANA Data Ingestion
Business Value
Simply put HANA data ingestion techniques allow SAP customers to gain immediate access to all of their enterprise and internet data and using HANA real-time virtual modeling techniques easily and quickly get a harmonized well governed enterprise wide view of all of this data to perform advanced analytics and deliver new and advanced insights to the business quicker and more affordably using this single digital business platform.
- Immediate access to all enterprise and internet data,
- Simple, easy and efficient harmonization of data,
- Secure and governed access to data,
- Significant lower time to deliver new advanced insights to the business,
- Lower total cost of ownership of the entire solution,
- Replace costly latency stricken ETL with simple, easy and efficient data replication, and real-time data synchronization.
Sorry about the size of this BLOG. It is more like a whitepaper than a BLOG, but I wanted to try to keep this data ingestion using HANA built in features in one consolidated place and not spread it out over 10 different Blogs.
HANA Data Ingestion Overview
HANA data ingestion can be accomplished by using multiple HANA technologies that are batch and real-time synchronization oriented that included advanced real-time database transaction replication, messaging and application level change data capture. HANA data ingestion can also be accomplished by many other SAP and non-SAP technologies that are not covered in this BLOG. This BLOG will be divided into three basic categories:
- Virtual data access (which was covered in a previous BLOG)
- Batch data movement:
- Batch data movement of applications, models, tables and data using HDI schema export/import
- Batch data movement using Smart Data Access and SQL commands
- Batch data movement and transformation using a HANA SDI Flowgraph
- Batch load of external data lake data into the HANA Data Lake
- New virtual table snapshot and virtual table replication features
- Real-time data synchronization:
- New virtual table snapshot and virtual table replication features
- HANA SDI real-time database transaction replication using the classic workbench replication task tool
- HANA SDI WebIDE HDI schema replication task and PowerDesigner demo
- HANA SDI application level real-time replication using ABAP ODP/ODQ adapter with a WebIDE replication task
- HANA Smart Data Streaming real-time message ingestion and analytics
HANA data ingestion includes many ways of accessing data virtually which allows simple and immediate access to data across the entire enterprise and internet. HANA data ingestion also includes the ability to ingest part of a data set or the entire data set into the HANA data architecture for temporary or permanent access. HANA data ingestion also includes real-time change data capture from database transactions, applications and streaming data.
Where you put the data is also a large part of the HANA Data strategy. This topic is covered in the HANA Data Tiering BLOG referenced below. HANA has three tiers of storage that are invisible to application developers and spans from amazingly fast in-memory storage to extraordinarily affordable high speed query storage of 10s TBs – 10s PBs of storage.
HANA Data Architecture: HANA Data Tiering

https://blogs.sap.com/2020/02/12/hana-data-strategy-hana-data-tiering/
HANA Virtual Data Access
See data virtualization BLOG for more detail :
https://blogs.sap.com/2020/03/09/hana-data-strategy-data-ingestion-virtualization/
HANA Batch Data Movement
Batch movement of applications, models, tables and data using HDI export/import
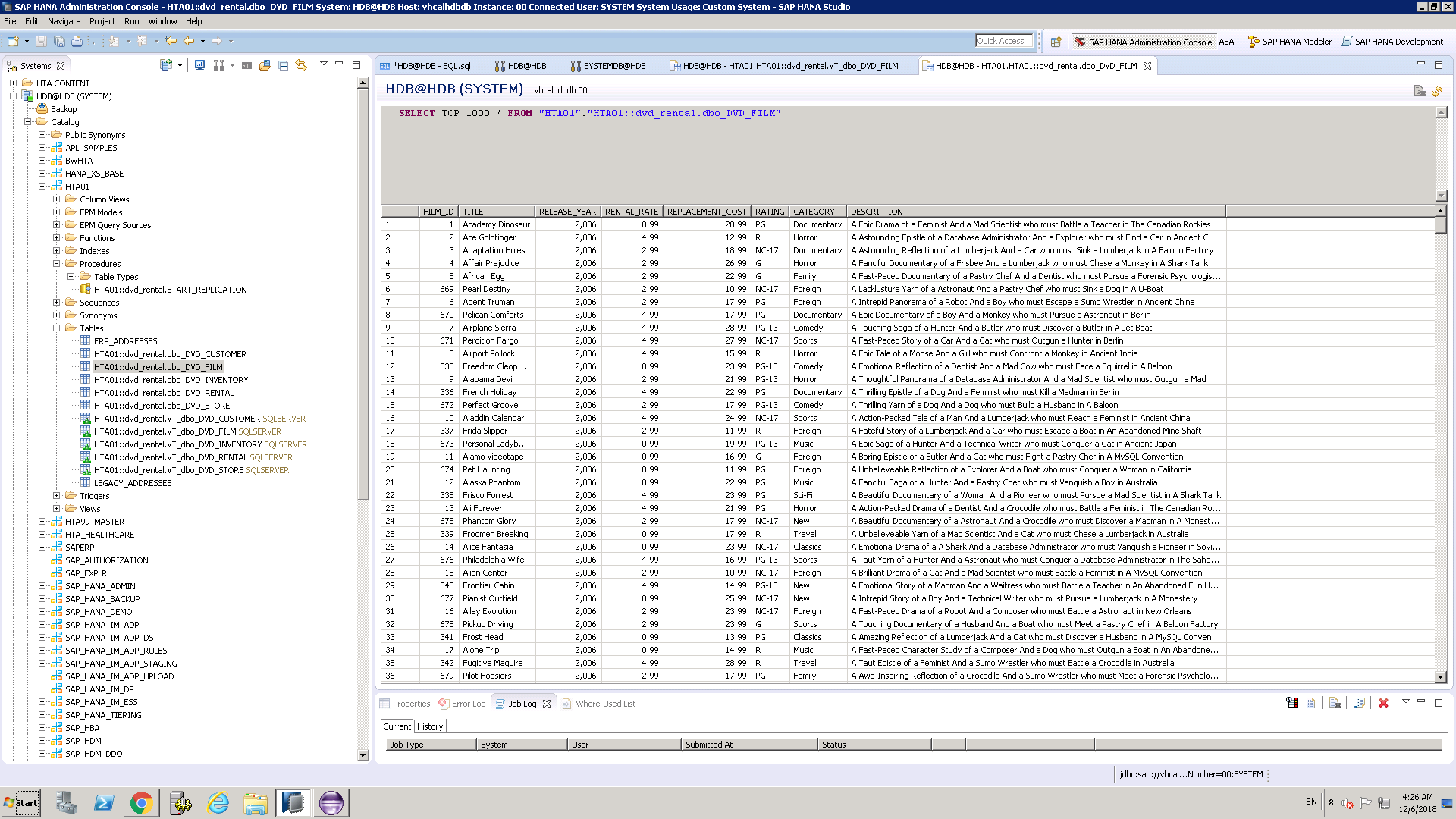
The HANA Deployment Infrastructure (HDI) schema contains all the HANA artifacts for a HANA project. These HANA artifacts include HANA tables, procedures, views, calculation views, replication tasks, SDI flowgraphs, etc. Watch this quick little demo to see how SAP customers can quickly and easily move applications, models, tables and data between HANA instances such as on-premise HANA instances and HANA Cloud systems using HDI export/import.
Migrating HANA On-premise Models to HANA Cloud in 5 minutes Demo:
https://sapvideoa35699dc5.hana.ondemand.com/?entry_id=1_1itpe1u6
Batch data movement using Smart Data Access and SQL commands
Smart Data Access allows HANA users to quickly, easily, efficiently and securely access a large variety of remote data sources (see SDA BLOG above). Once the REMOTE SERVER which is what HANA calls remote connection to the remote source is securely created and optionally virtual tables are created (you can connect to remote tables via a full path name starting with the remote server), you can access the remote tables and simply copy some or all of the data into HANA tables.
Example using command line:
This series of commands will very simply:
Create a connection to a HANA cloud server called HANA_CLOUD,
Create a virtual table called ORDERS_VT,
Create a local HANA table called ORDERS_RT, and
Batch insert all of our orders from 2009 until now.
Create a connection to your remote data source.
CREATE REMOTE SOURCE HANA_CLOUD ADAPTER "hanaodbc"
CONFIGURATION 'ServerNode=abcd1234.hana.prod-us10.hanacloud.ondemand.com:443;
Driver=libodbcHDB.so;dml_mode=readwrite;
encrypt=TRUE; sslTrustStore="-----BEGIN CERTIFICATE----MIIDrz…-----END CERTIFICATE-----"'
WITH CREDENTIAL TYPE 'PASSWORD' USING 'user=DBADMIN;password=YourPassword';
Create a virtual table pointing to remote tables ORDERS.
CREATE VIRTUAL TABLE TPCD.ORDERS_VT AT " HANA_CLOUD "."<NULL>"."SYSTEM"."ORDERS";
Create a local table called ORDERS_RT.
CREATE COLUMN TABLE TPCD.ORDERS_RT LIKE TPCD.ORDERS_VT;
Pull all the ORDERS from 2009 and newer and put them in the local HANA table.
INSERT INTO TPCD.ORDERS_RT SELECT * FROM TPCD.ORDERS_VT WHERE O_ORDERDATE > '2008-12-31'
Example using HANA Database Explorer to create remote server and virtual tables:
In HANA database explorer right click on remote sources folder and choose new. Then fill out the screen with the same information from the create statement above:

Once the remote source HANA_CLOUD is created open it and choose schema TPCD and click search button:
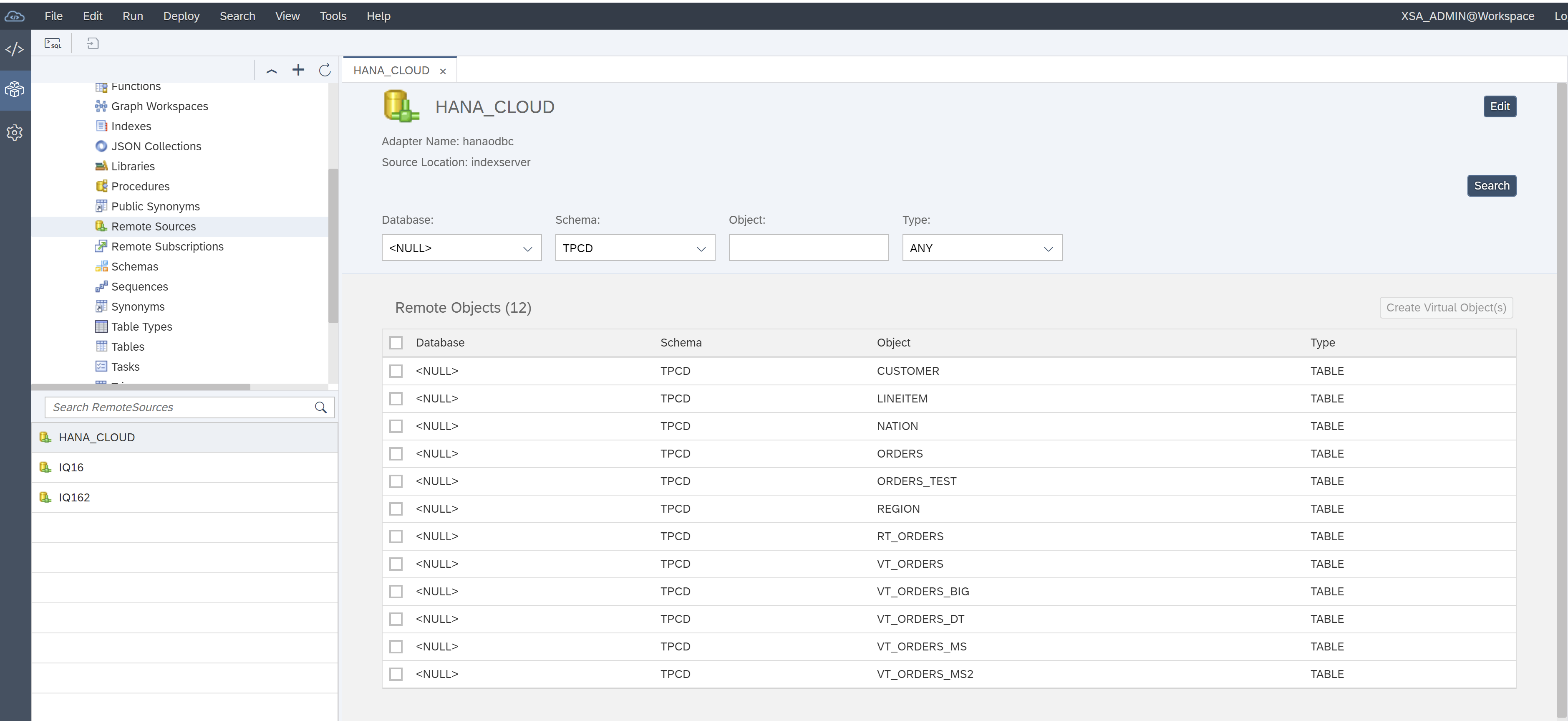
Next select tables: CUSTOMER, LINEITEM, NATION, ORDERS, and REGION. Then click “Create Virtual Object(s)”. Then select TPCD schema and add prefix VT_ and then click Create.
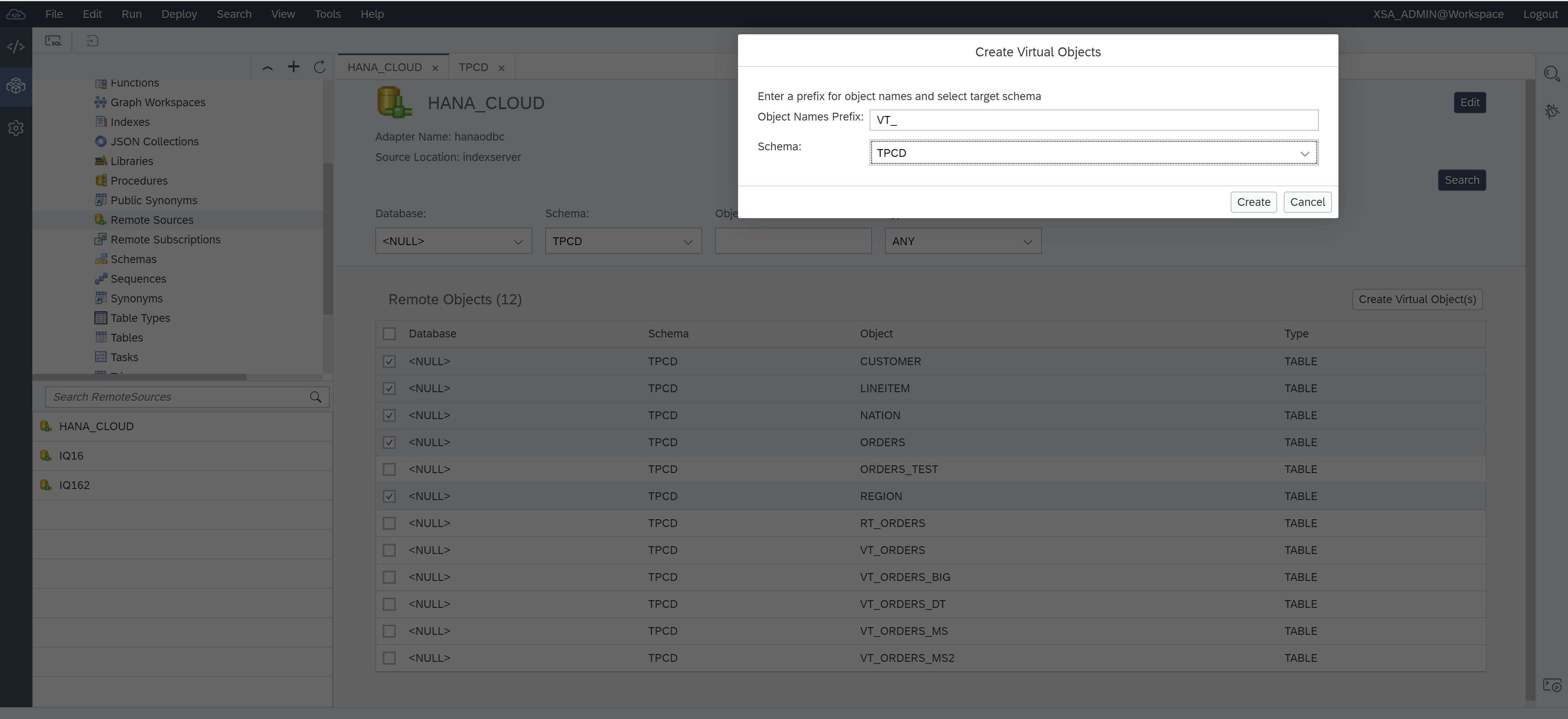
That creates the virtual tables VT_CUSTOMER, VT_LINEITEM, VT_NATION, VT_ORDERS, and VT_REGION in the TPCD schema.
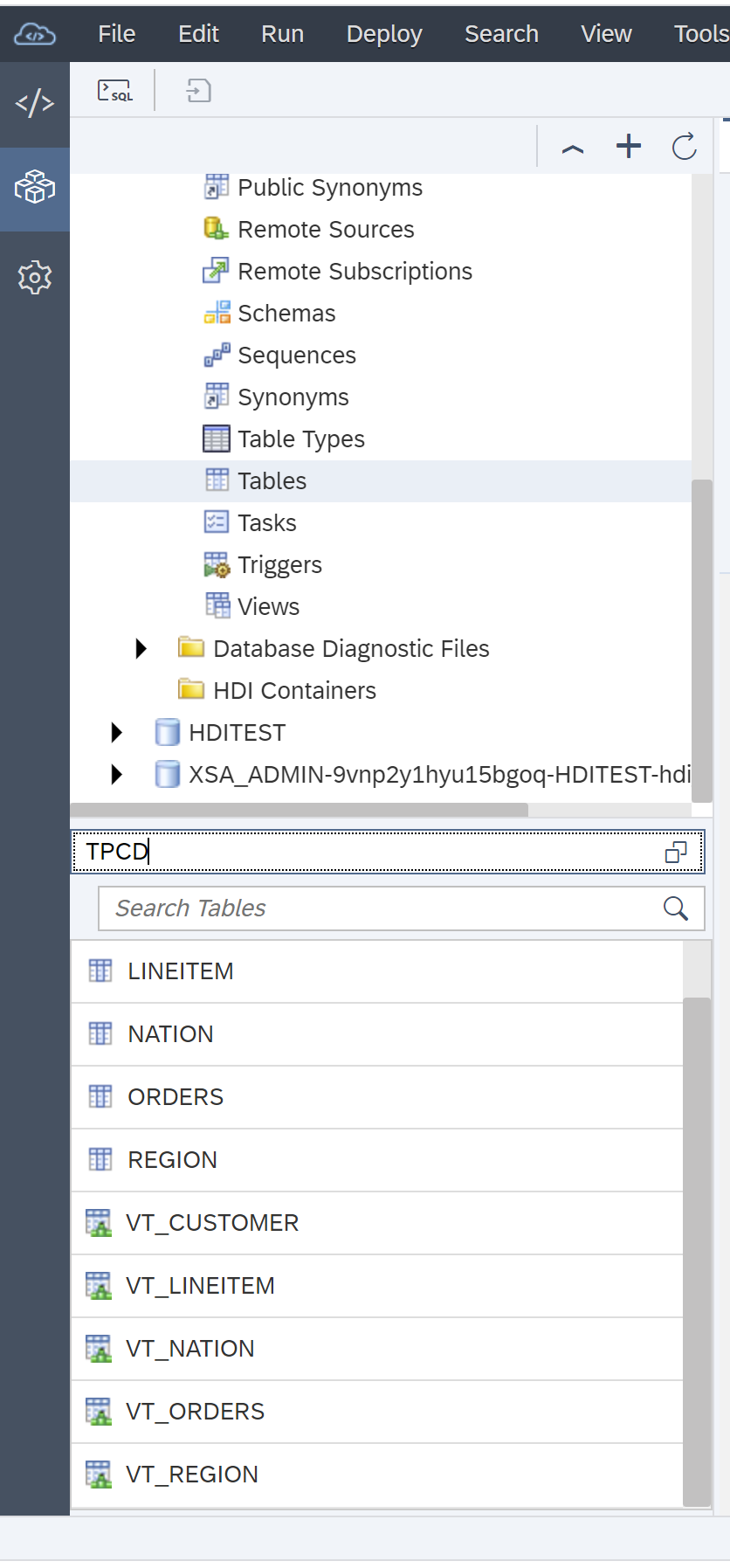
Notice the virtual table icon:
next to each table name.
Using a HANA SDI flowgraph to copy data from a virtual table to HANA table
Using the SDI flowgraph GUI is a very simple and easy way to create very complex export, load, and transform scenarios to meet your business needs. SDI flowgraphs can take advantage of all the HANA features including the features explained in this BLOG such as real-time replication. SDI flowgraphs create tasks that can be scheduled and monitored with SAP HANA Cockpit.
Here is an example of an extremely simple SDI flowgraph to copy the table we did above.
Grant the appropriate permissions on the remote source for the HDI container:
GRANT LINKED DATABASE, CREATE VIRTUAL TABLE ON REMOTE SOURCE HANA_CLOUD TO "HDITEST_1#OO" WITH GRANT OPTION;
Switching from the HANA database explorer to WebIDE development by clicking on in upper left. (To see a demo on how to create a WebIDE project and HDI schema see: https://blogs.sap.com/2019/11/14/sap-hana-data-strategy-hana-data-modeling-a-detailed-overview/ .)
Create a virtual table in the HDI container
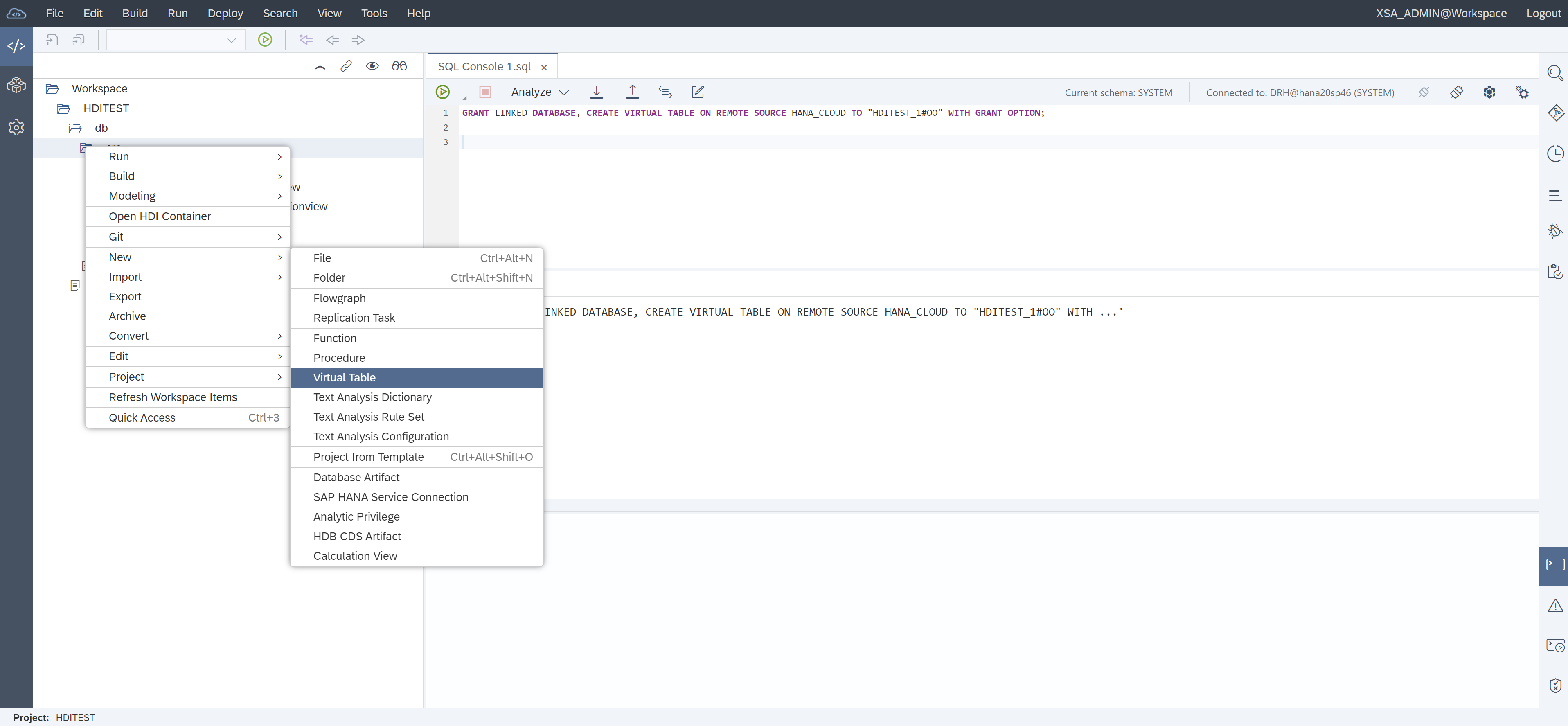
Select new/database artifact/.virtualtable
Enter same information from create virtual table command such as CREATE VIRTUAL TABLE TPCD.ORDERS_VT AT " HANA_CLOUD "."<NULL>"."SYSTEM"."ORDERS";
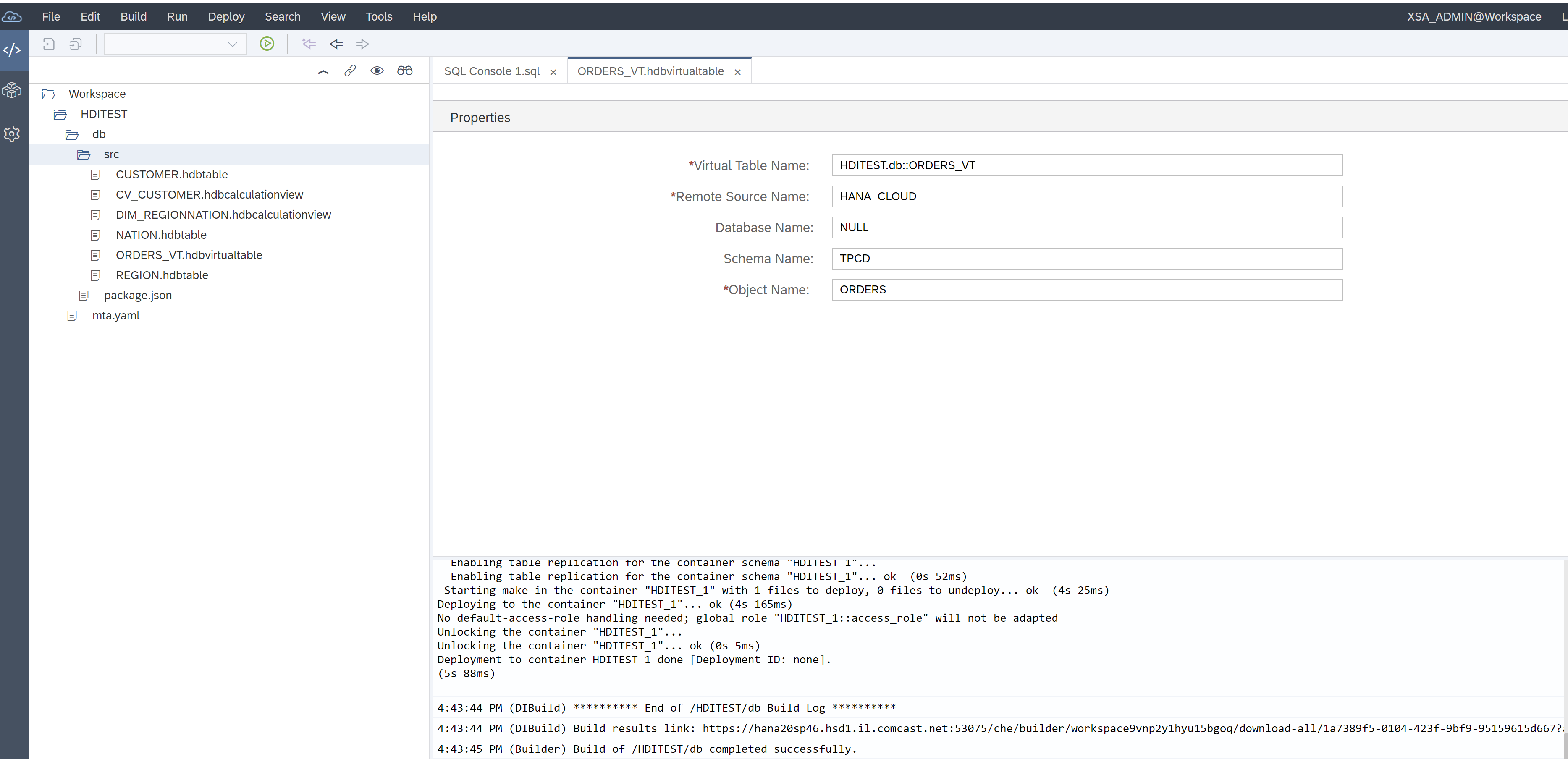
Then save and build.
Then in database explorer preview the data
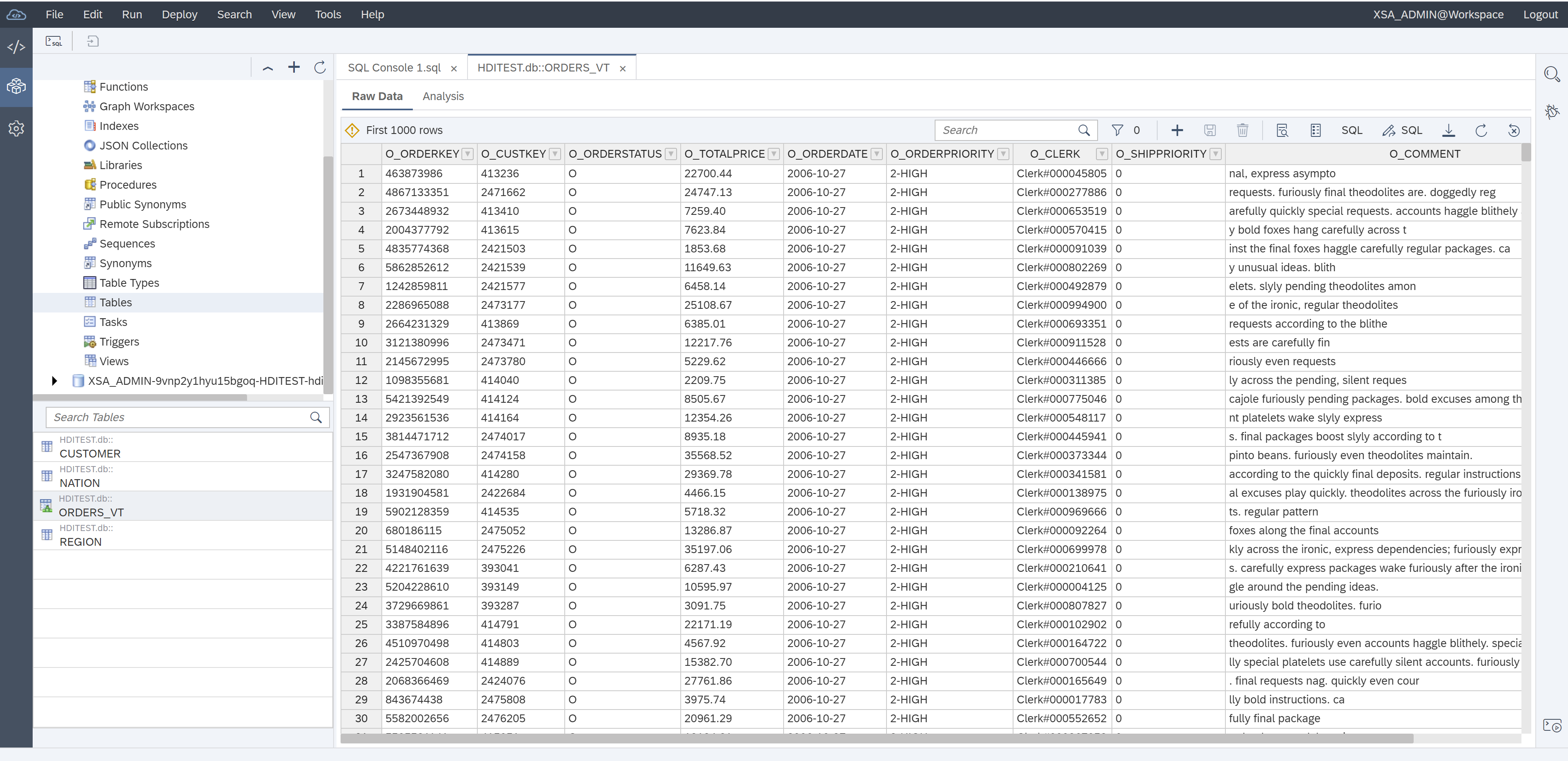
Create the target table
Right click src, choose new DB Artifact, hdbtable
Paste DDL
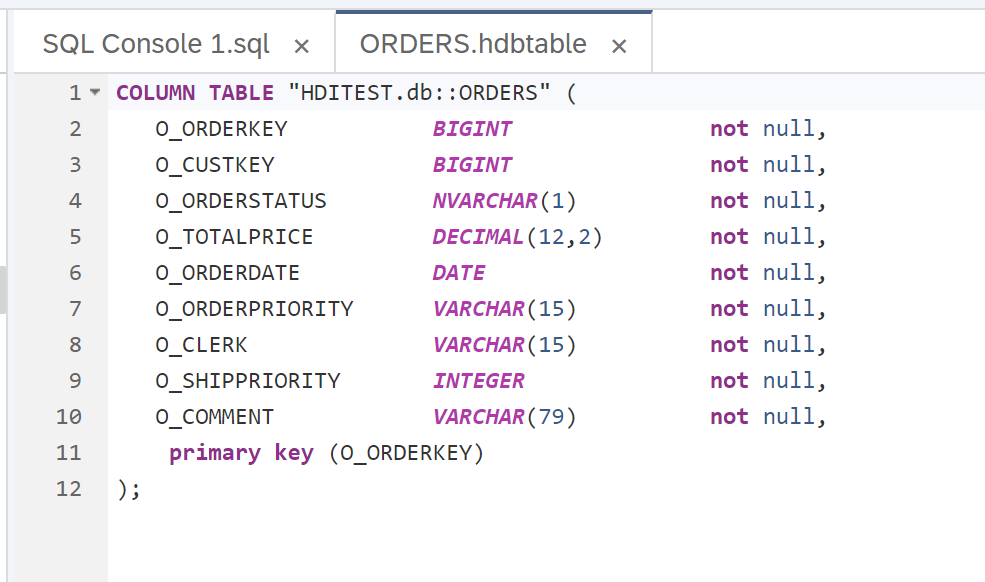
Save and build
2:21:37 PM (Builder) Build of /HDITEST/db completed successfully.
Create the SDI flowgraph in the HDI container
Select the virtual table as the source

Select the ORDERS table in the HDI container as the target

Connect Source to target

Open settings on the target table and choose “Auto Map Columns” by name (normally this is done automatically but I like to double check).

Save and build flowgraph.
Execute the flowgraph from the flowgraph GUI.
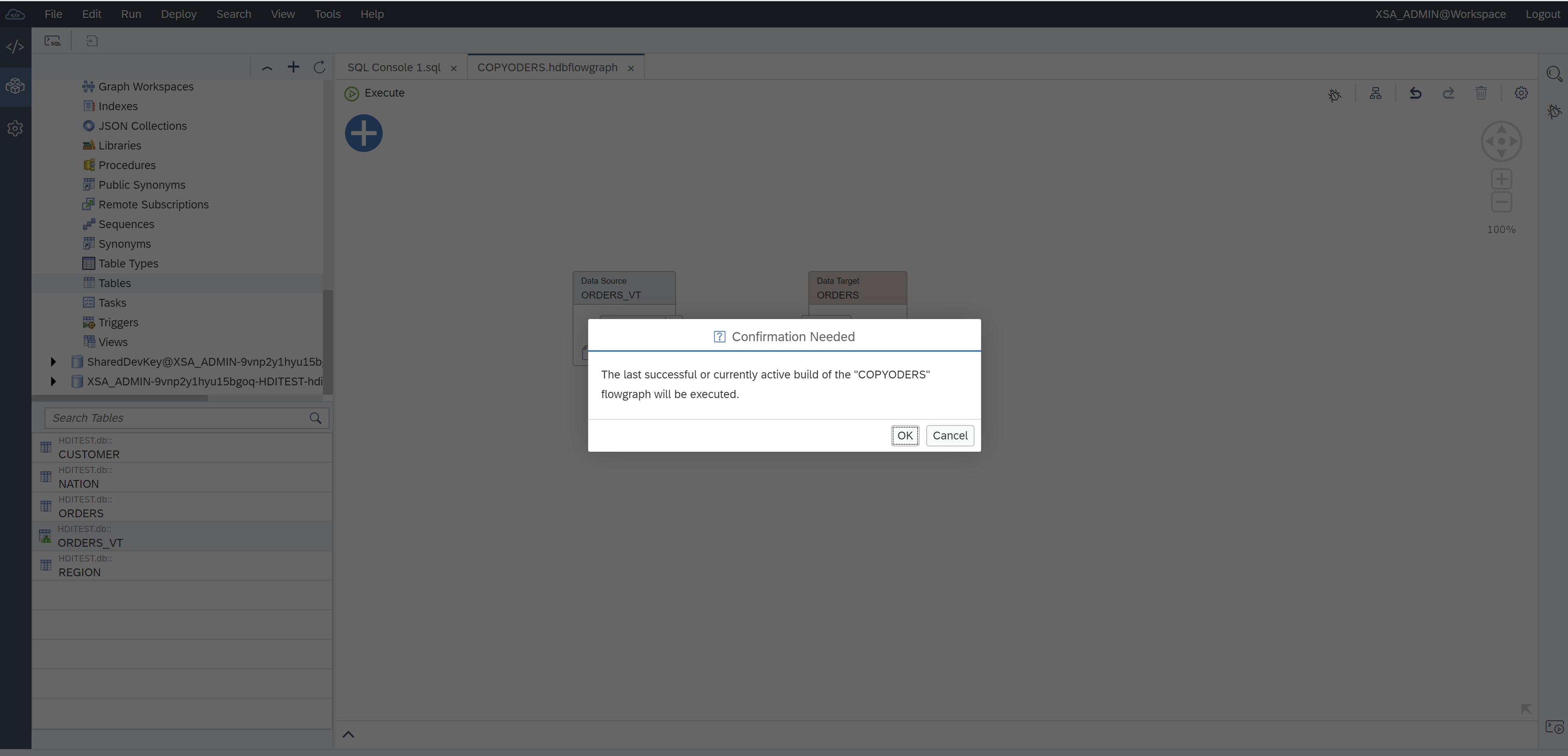
Or execute the flowgraph via command line:
CALL "HDITEST_1"."HDITEST.db::COPYODERS_SP"()
Monitoring flowgraphs from the database explorer
In the database explorer, open the tasks folder and open the flowgraph.


In the database explorer open the tables folder and preview the data in the target table ORDERS.

Compare row counts
There are 28,565,809 rows in the target table.
SELECT COUNT(*) FROM "HDITEST_1"."HDITEST.db::ORDERS"
28,565,809
There are 28,565,809 rows in the source table, therefore a success.
SELECT COUNT(*) FROM "HDITEST_1"."HDITEST.db::ORDERS_VT"
28,565,809
Flowgraphs can do much much more. HANA Enterprise Information Management (EIM) includes Smart Data Access (SDA), Smart Data Integration (SDI) and Smart Data Quality (SDQ). HANA has a very efficient and effective Enterprise Information Management functionality that can leverage all the HANA features including the massively fast columnar in-memory table processing and all the advanced analytic engines such as the Predictive Application Library.
Batch load external data lake data into the HANA Data Lake
The SAP HANA Cloud HANA Data Lake can load data directly from hyperscaler file systems such as Amazon S3, Azure Data Lake or Google files.
So, image your company has standardized on Azure as your data storage platform, but you just merged with another company that standardized on Amazon as their data storage platform and now you want to analyzed all of that data with your SAP data.
What do you do?
Each hyperscaler vendor will simply say copy all that data here and keep it up to date in real-time but from an expense and governance point of view, making many copies of the data is not a affordable or desirable. With HANA or HANA Cloud we can dynamically access that data remotely by creating remote sources in HANA SDA to the different SQL query engines like Azure SQL, Athena and Google Big Query (see next section) but those SQL query technologies require days or weeks to setup analysis of very large datasets and then still do not give analysts the ad-hoc query environment or speeds they require to do their analysis.
The SAP HANA Cloud HANA Data Lake can very quickly load the data required for a specific project directly from hyperscaler file systems such as Amazon S3, Azure Data Lake or Google files and give data analysts a true columnar ad-hoc environment with incredible performance leveraging the HANA Data Lake columnar tables with scalability into the 100s of TBs. These imports can be done quickly and easily into temporary or permanent tables and the data can be analyzed with little or no preparation. Therefore, analysts can get quick and easy access to massive amounts of data and get answers they need in a fraction of the amount of time that it would take using other technologies.
e.g. This is the example command line syntax for loading an S3 file into the HANA Data Lake:
CALL SYSRDL#CG.REMOTE_EXECUTE('
BEGIN
LOAD TABLE FACT_POS (
CALENDAR_DATE ,
ITEM_LOOKUP ,
RETAILER_ITEM_LOOKUP ,
STORE_NUM ,
RETAILER_CD ,
UNIT_RETAIL ,
UNIT_COST ,
SOLD_QTY ,
SOLD_DOLLARS ,
SALES_EXIST ,
ONHAND_QTY ,
ONORDER_QTY ,
INTRANSIT_QTY ,
INWHSE_QTY ,
TOTAL_QTY ,
ONHAND_DOLLARS ,
ONORDER_DOLLARS ,
INTRANSIT_DOLLARS ,
INWHSE_DOLLARS ,
INVENTORY_TOTAL_DOLLARS ,
INVENTORY_EXIST ,
TRAITED ,
VALID ,
LOAD_ID ,
LOAD_DETAIL_ID )
USING FILE ''s3://xxxxx.csv''
DELIMITED BY '',''
STRIP OFF
FORMAT CSV
ACCESS_KEY_ID ''''
SECRET_ACCESS_KEY ''''
REGION ''us-east-1''
ESCAPES OFF
QUOTES ON
;
END');
New virtual table snapshot and virtual table replication features added to HANA 2.0 SP05 available in HANA Cloud
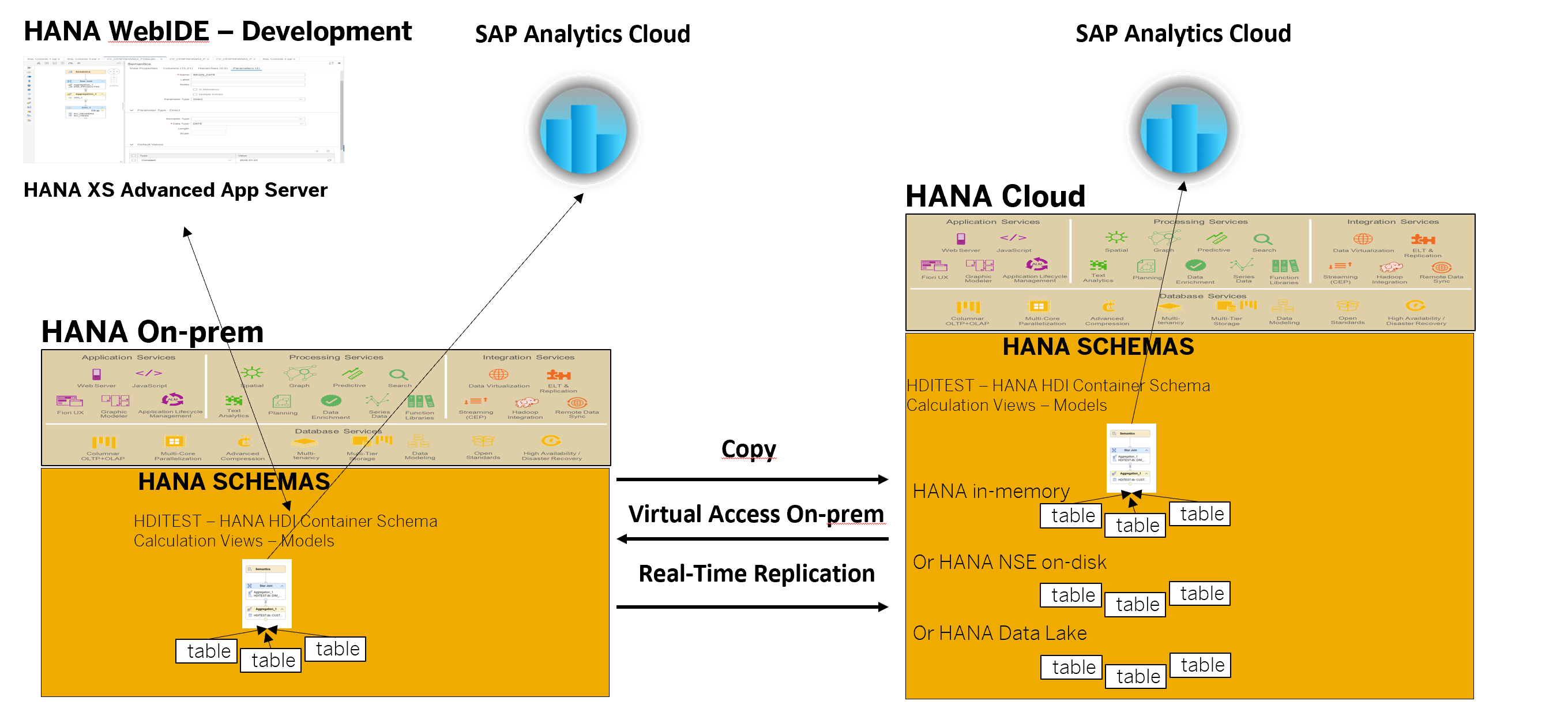
I purposely put this section between batch and real-time data synchronization since these new features cover both. Before this feature was added we typically would create a virtual table i.e. CUSTOMER_VT and being our modeling. Then later for performance or other business reasons we may decide to replicate the remote table data into another HANA table i.e. CUSTOMER_RT. Then to not affect any models we have previously built we may do some table renaming. With these new options to the ALTER VIRTUAL TABLE command this process has become much simpler.
So, image you are a data analyst or a data scientist and your examining local HANA data, Azure SQL data and AWS Athena, using HANA SDA remote sources and virtual tables but then you decide you need to join these datasets or do some advance analytics that would take too long or just not work over remote connections. You can take days or weeks trying to do your analysis across remotely distributed data sets using slower row-based architectures or in just minutes pull the data into HANA columnar in-memory or on-disk or HANA Data Lake tables and then start getting your answers in seconds.
With the new options to the ALTER VIRTUAL TABLE command we have the option to change a virtual table:
- To a local snapshot,
- To refresh a snapshot, or
- To a local replicate with real-time updates.
Basically, promoting a virtual table to a snapshot or a real-time replicated table with one simple command.
DEMO:
Create a remote source:
CREATE REMOTE SOURCE HANA_CLOUD ADAPTER "hanaodbc"
CONFIGURATION 'ServerNode=testtesttest.hanacloud.ondemand.com:443;
Driver=libodbcHDB.so;dml_mode=readwrite;
encrypt=TRUE; sslTrustStore="-----BEGIN CERTIFICATE----MIIDrz…-----END CERTIFICATE-----"'
WITH CREDENTIAL TYPE 'PASSWORD' USING 'user=DBADMIN;password=YourPassword';
Create a virtual table:
CREATE VIRTUAL TABLE TPCD.ORDERS_VT AT " HANA_CLOUD "."<NULL>"."SYSTEM"."VT_CUSTOMER";
At this point you have access to all the remote data through the network connection to the remote source.
Promote table to a snapshot:
ALTER VIRTUAL TABLE VT_CUSTOMER ADD SHARED SNAPSHOT REPLICA;
--executed in 63674 ms.
In just over a minute the local table is populated with millions of rows of data
If you don’t want the table in your hot in-memory data, you can also place it into an on-disk NSE technically called a PAGE LOADABLE table:
ALTER VIRTUAL TABLE VT_CUSTOMER ADD SHARED SNAPSHOT REPLICA PAGE LOADABLE;
If you later need to refresh your local copy of the data with your remote copy you can simply run a refresh command:
ALTER VIRTUAL TABLE VT_CUSTOMER REFRESH SNAPSHOT REPLICA;
Or if you want the table to have changes applied in real-time promote the table to a real-time replica.
ALTER VIRTUAL TABLE VT_CUSTOMER ADD SHARED REPLICA;
This works for all remote sources that support the HANA SDI real-time replication.
Or you can turn off the snapshot and real-time replication and convert the table back to standard virtual table with a DROP command:
ALTER VIRTUAL TABLE VT_CUSTOMER DROP REPLICA;
Real-time Data Synchronization
HANA SDI real-time database transaction replication using the replication task tool
The easiest way to explain HANA SDI real-time database replication is by walking step by step through some detailed examples and demos. The examples below are using the replication task which currently comes in two flavors:
SAP HANA Workbench replication task which is used for replication and real-time database level synchronization of tables from remote databases to HANA classic schema tables. The SAP HANA Workbench runs in the HANA XS classic application server and is no longer being updated.
SAP HANA WebIDE replication task which is used for replication and real-time database level synchronization of tables from remote databases to HANA HDI schema tables. The SAP HANA WebIDE runs in the HANA XS advanced application server and is the current HANA development tool.
For an overview of HANA classic and HANA Deployment Infrastructure (HDI) architectures and tools see: https://sapvideoa35699dc5.hana.ondemand.com/?entry_id=0_px25z63a
For an overview of HANA modeling see: SAP HANA Data Strategy: HANA Data Modeling a Detailed Overview - https://blogs.sap.com/2019/11/14/sap-hana-data-strategy-hana-data-modeling-a-detailed-overview/
There are HANA SDI installation and setup steps before a replication task can be used. There are two different types of HANA SDA remote servers. The first is a basic ODBC connection from HANA directly to the remote source. The second is a connection to the SDI DPAgent and then the SDI DPAgent connects (via JDBC or APIs) to the remote source. Other than HANA to HANA replication in SP05, all other heterogeneous database replication is supported through the SDI DPAgent adapters. The DPAgent should be installed as close to the source database as possible. The DPAgent adapters must be enabled in the DPAgent configuration tool. Also, database transaction reading must be configured in each source database.
Setup remote database log reading for the first time:
See SDI Installation Guide - Data Provisioning Adapters - Microsoft SQL Server Log Reader - Remote Database Setup for SQL Server Realtime as an example.
https://help.sap.com/viewer/7952ef28a6914997abc01745fef1b607/1.0_SPS12/en-US/012e4b3269714a5493513e9...
Data Provisioning Agent Configuration tool

- Connect DPAgent to HANA - When SAP HANA is deployed in the cloud or behind a firewall, the Data Provisioning Agent connects to SAP HANA using the HTTPS protocol or JDBC WebSockets.
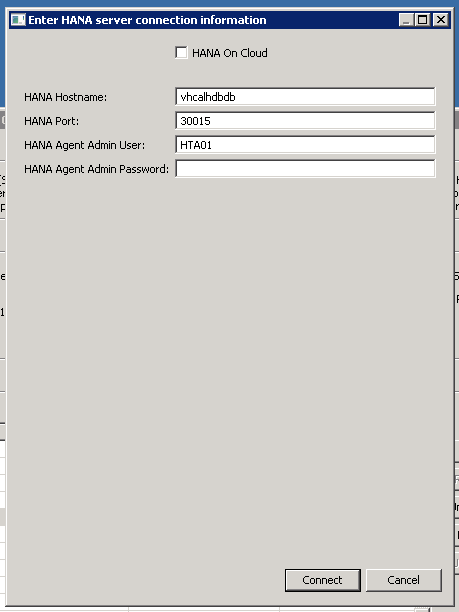
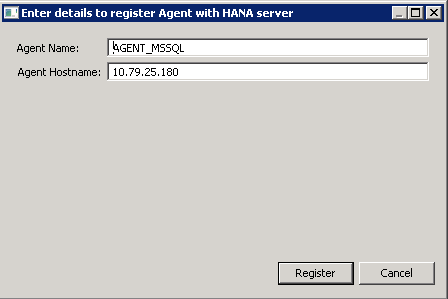
- Register DPAgent with HANA
- Enable adapters – The appropriate client API must be installed on the DPAgent system before you can enable the adapter. For MS SQL Server this meant copying the MS SQL Server JDBC 7.2 driver JAR file (mssql-jdbc-7.2.2.jre8.jar) to \usr\sap\dpagent…\lib. See SDI PAM for supported clients for each remote source (current location: https://support.sap.com/content/dam/launchpad/en_us/pam/pam-essentials/TIP/PAM_HANA_SDI_2_0.pdf).
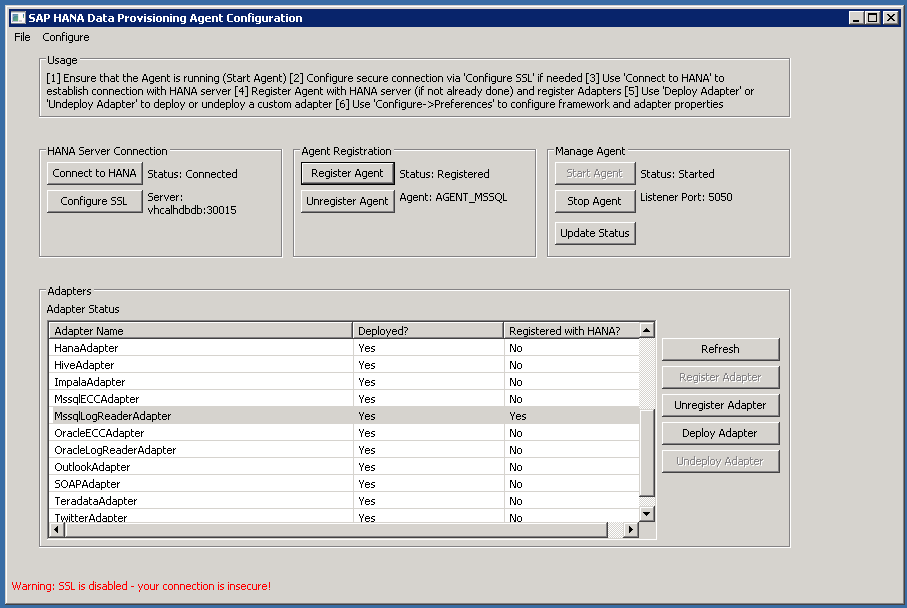
- Create remote server in HANA using the SDI DPAgent adapter
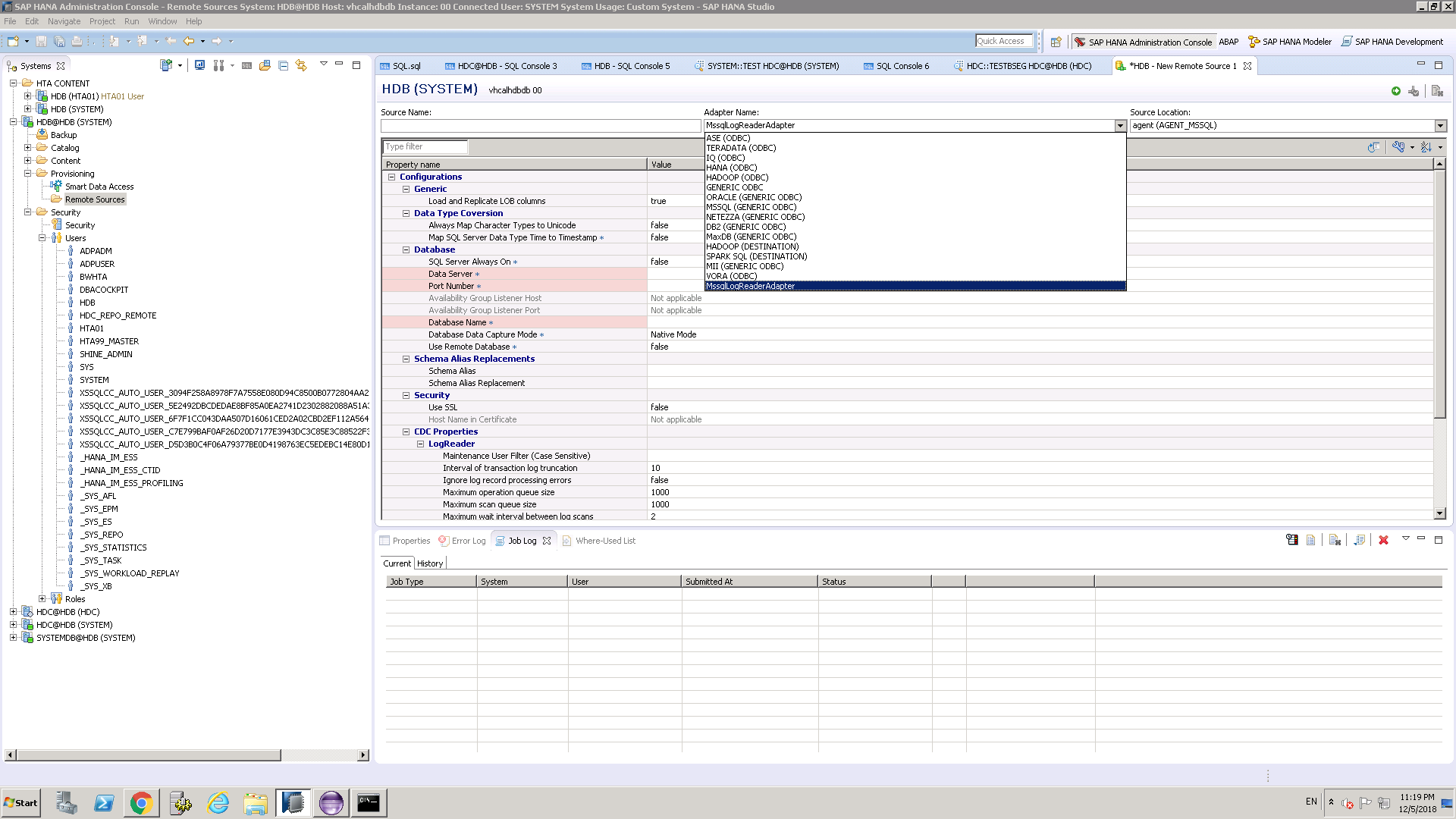
On top line choose MssqlLogReader.
Notice source is registered agent we did above. There can be many DPAgents.
In HANA Workbench example
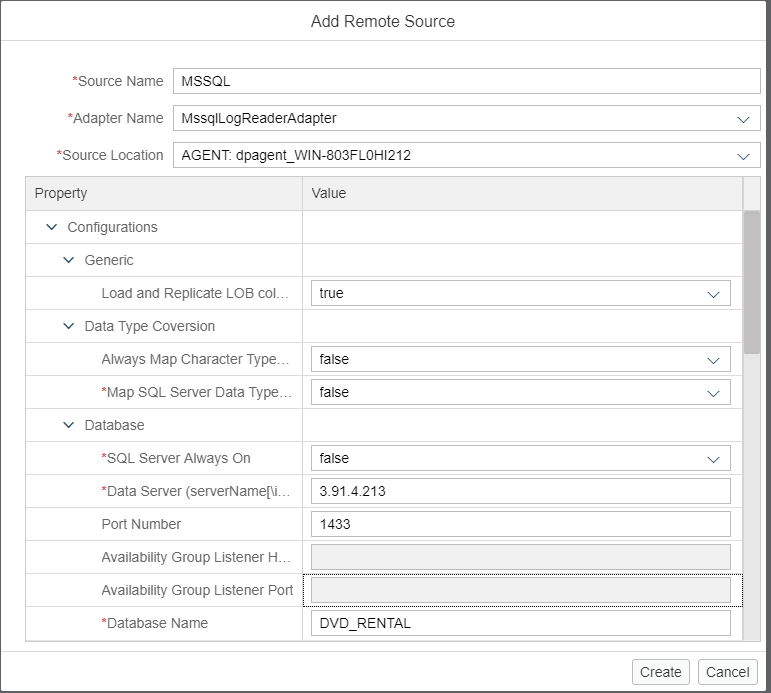
Why MssqlLogReaderAdapter
DPagent supports as many as three different adapters for any remote source. The naming convention is normally sourceAdapater, sourceLogReaderAdapater, and sourceECCAdapater:
- sourceAdapater supports creation of virtual tables with reading and writing features,
- sourceLogReaderAdapater additionally supports database log reading for real-time data synchronization,
- sourceECCAdapater additionally supports the decomposition of ECC clustered and pool tables into standard HANA tables.
(See SDI Installation and Configuration Guide - Data Provisioning Adapters for features of each adapter.
https://help.sap.com/viewer/product/HANA_SMART_DATA_INTEGRATION/2.0_SPS04/en-US)
What is a replication task
A replication task is a GUI tool that browses remote databases and allows customers to easily and quickly select some or all the remote database tables. The replication task also allows customers to select some or all the columns and rows of the tables. Then the replication task generates and executes all the HANA commands to create virtual tables and target tables. Lastly it generates and executes commands to copy the data from the remote tables into the local tables and turns on transactional replication to keep the HANA table in sync with the remote tables in real-time.
Replication Task: Replication load behavior choices
You can choose to perform a combination of initial load, real-time replication, and table-level structure (DDL) replication depending on if change data capture (CDC) is supported, and if you are using a table or virtual table.
- Initial load only: Performs a one-time data load without any real-time replication. Always available.
- Initial + Realtime: Performs the initial data load and enables real-time replication. Available when CDC is supported for tables, virtual tables or other APIs (such as ABAP ODP/ODQ).
- Realtime: Enables real-time replication without performing an initial data load. Available when CDC is supported for tables and virtual tables.
- No data transfer: Replicates only the object structure without transferring any data. Always available.
- Initial + realtime with structure: Performs the initial data load, enables real-time replication, and tracks object level changes. Available when CDC is supported and for tables.
- Realtime only with structure: Enables real-time replication and tracks object-level changes without performing an initial data load. Available when CDC is supported and for tables.
The last two are the most commonly used. The most common reason to choose realtime only with structure would be for extremely large tables where there was a more efficient way to do the original materialization of the table versus an INSERT from a SELECT over the network.
With structure is also referred to as Data Definition Language (DDL) replication.
If the replication behavior is set to realtime, click Load Behavior to enable one-to-one replication, actual tables, or change log tables as targets. Select one of these options:
- Replicate: Replicates changes in the source one-to-one in the target.
- Replicate with logical delete: UPSERTS rows and includes CHANGE_TYPE and CHANGE_TIME columns in the target.
- Preserve all: INSERTS all rows and includes CHANGE_TYPE, CHANGE_TIME, and CHANGE_SEQUENCE columns in the target. This option creates what is sometimes referred to as staging tables.
Replication Task: Partition Data
Partitioning data can be helpful when you are initially loading a large data set because partitioning can improve performance and assist in managing memory usage.
Data partitioning separates large data sets into smaller sets based on defined criteria. Some common reasons for partitioning include:
- You want the performance to be faster.
- You receive “out of memory” errors when you load the data.
- You have reached the limit for the maximum number of rows within a single partition in a column store.
You can partition data at the Input level and at the Task level:
- Input partitioning affects only the process of reading the remote source data.
- Task-level partitioning partitions the entire replication task, from reading the data from the remote source to loading the data in the target object and everything in between. These partitions can run in serial or in parallel.
Replication Task: Configuring target table to include some or all the columns and rows of the remote table
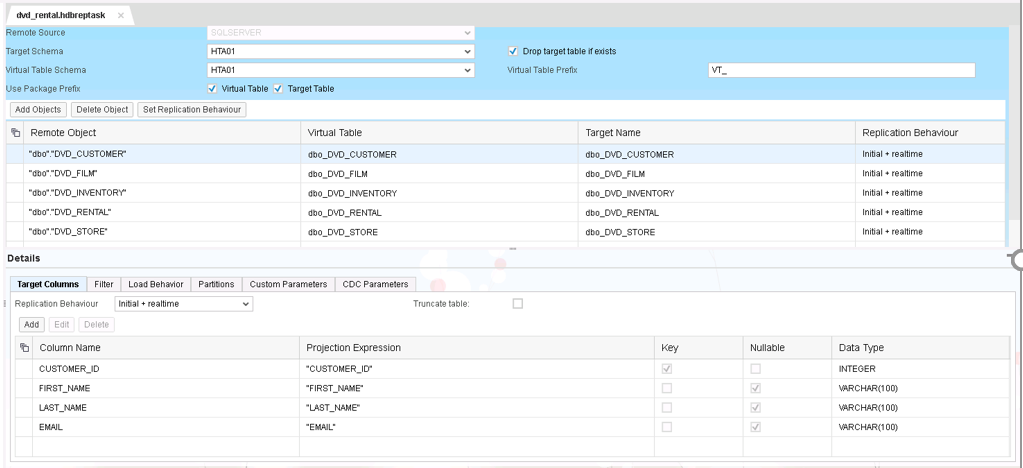
The target columns can be all or any subset of the remote objects columns as long as the primary key is kept intact. Also, customers can filter the rows in the target table by selecting the filter tab and entering SQL like filter such as REGION = ‘CENTRAL’.
HANA Workbench Replication Task
Below are screen shots of HANA SDI real-time database replication from MS SQL Server tables to HANA Classic schema tables. This is based on an old lab in the HANA technical academy.
Before you create a RepTask you must have permissions to do so for the particular REMOTE SOURCE that you created earlier.
GRANT LINKED DATABASE, CREATE VIRTUAL TABLE, CREATE REMOTE SUBSCRIPTION ON REMOTE SOURCE SQLSERVER TO "_SYS_REPO" WITH GRANT OPTION
Logon to HANA Workbench: http://xxxxx:8000/sap/hana/ide/
Switch to Editor and create Replication Task

For HTA01 project choose New – Replication Task

Name it dvd_rental.hdbreptask
Fill out header:
- Source SQLSERVER
- Schema HTA01
- Virtual Table prefix VT_
Select add Tables
- Select all or a subset of tables from the remote source
- Select Replication Behavior: Initial Load and Replication

Define target columns and filters if required

SAVE Replication Task
Notice it created all Virtual Tables and Target Tables.
You can browse data in Virtual Tables but there is no data in Target Tables yet.

Invoke Replication Procedure created
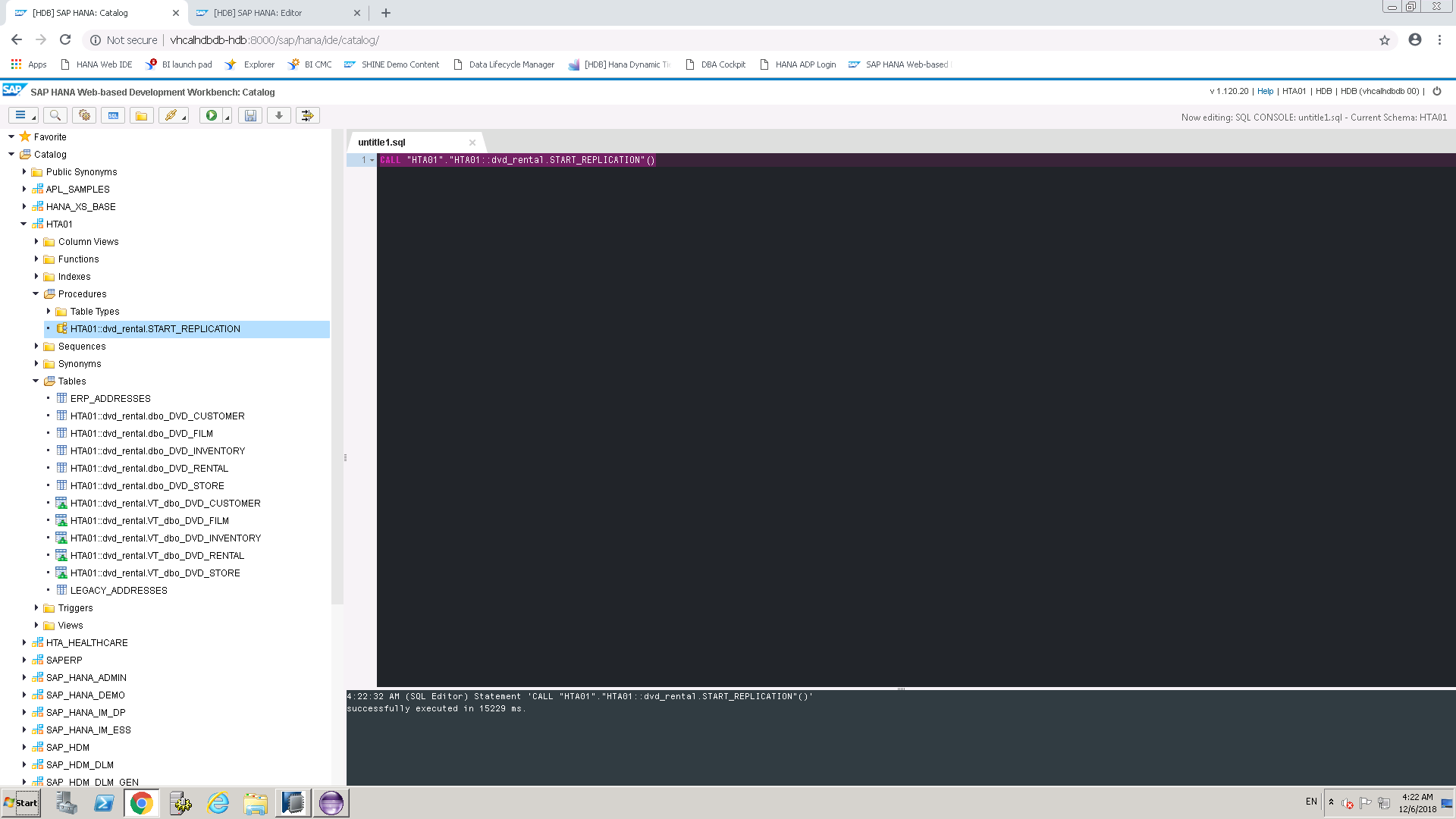
CALL "HTA01"."HTA01::dvd_rental.START_REPLICATION"()
4:22:32 AM (SQL Editor) Statement 'CALL "HTA01"."HTA01::dvd_rental.START_REPLICATION"()'
successfully executed in 15229 ms.
Now Data is populated in Target Tables
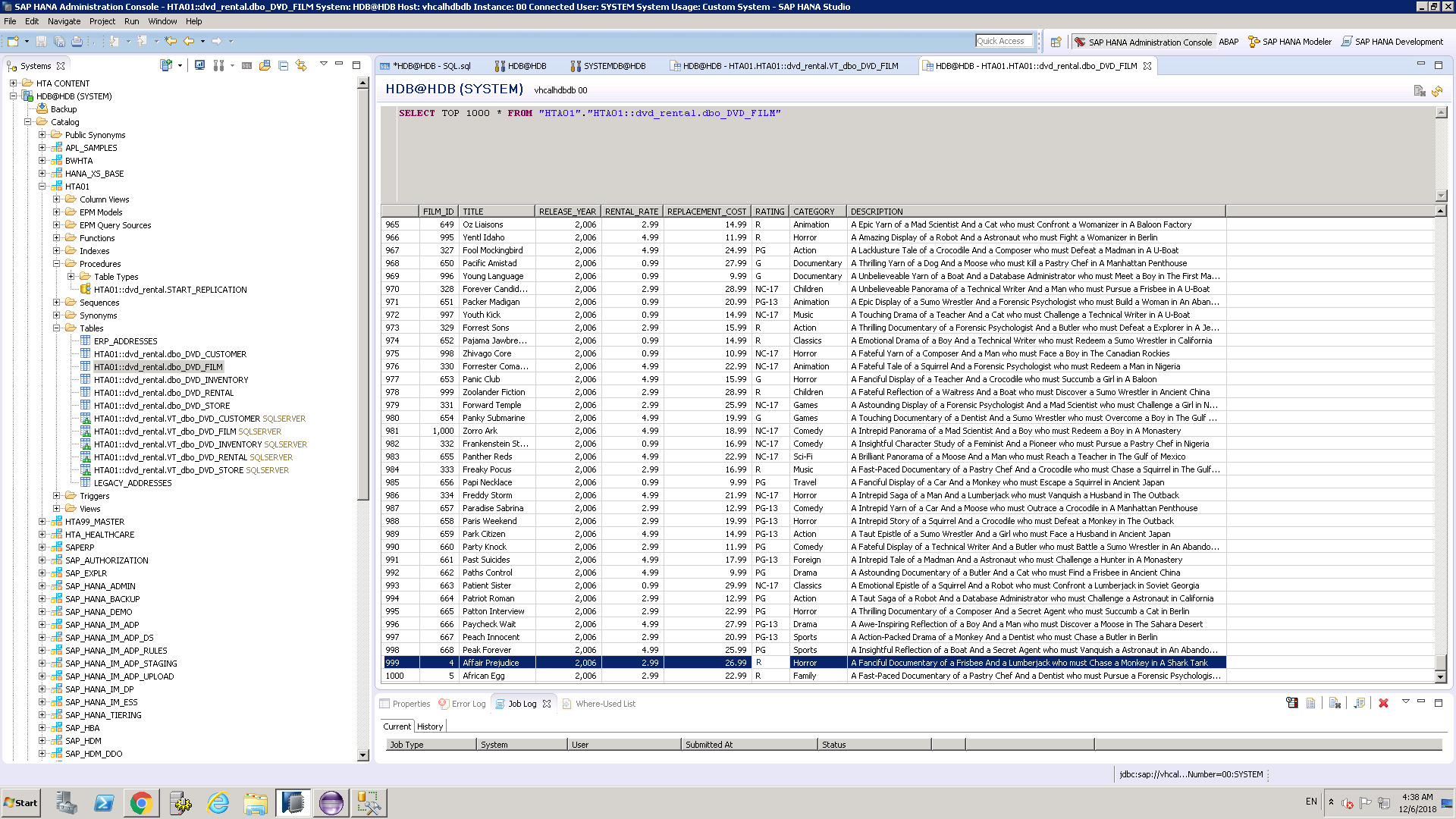
Test change data replication from SQL Server to HANA
Go to SQL Server and change rows…
Change Film 4 and 5 to R rating…

See Changes in HANA
HANA WebIDE Replication Task Demo
Below is a demo of HANA SDI real-time database replication from MS SQL Server to HANA. This demo is also using the PowerDesigner tool to simply and easily reverse engineer the MS SQL Server table definitions and convert them to HANA HDI schema CDS views.
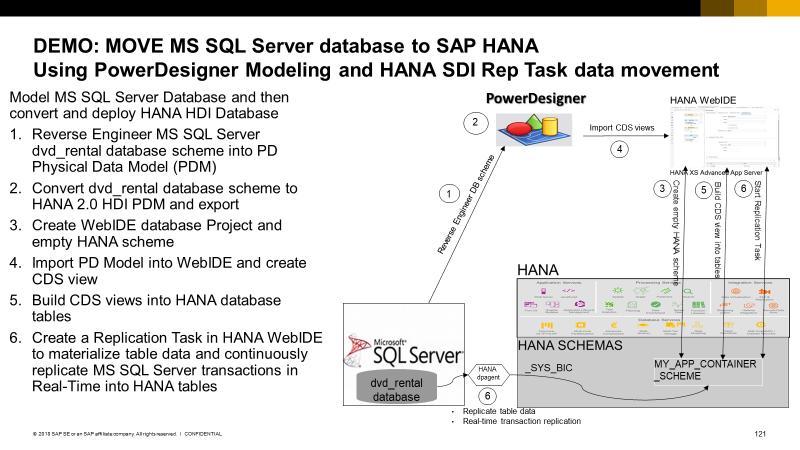
The primary focus for this BLOG is step 6 where a WebIDE replication task tool is used to browse remote SQL Server database and easily and quickly select some remote database tables (demo part 3 below). Then the replication task generates and executes all the HANA commands to create virtual tables but uses PowerDesigner model in WebIDE to generate target tables. Lastly it generates and executes commands to copy the data from the remote tables into the local tables and turns on transaction replication to keep the HANA table in sync with the remote tables in real-time.
Steps 1 through 5 use the PowerDesigner tool to reverse engineer the MS SQL Server database tables into a PowerDesigner database model. Then with the PowerDesigner tool the MS SQL Server model is converted to a HANA HDI schema CDS views database model and exported to a WebIDE import file. This file is then imported into HANA WebIDE environment and used to generate the HANA HDI schema and tables that are then used as target tables in the replication task.
This is a best practices way of creating models to represent the source and target databases from an enterprise modeling point of view. These models can be used as a data management layer to govern the architecture and do impact analysis of anything else added to or modified in this environment going forward from this point on.
Demo Part 1: Using the PowerDesigner modeling tool to reverse engineer the MS SQL Server dvd_rental database scheme into a PowerDesigner database physical data model (PDM) and then generate a HANA HDI database physical data model and generate a WebIDE import file from this model:
MS SQL Server to HANA Replication using PowerDesigner Demo Part 1 Model Creation
Demo Part 2: Using HANA WebIDE development tool to create a project and an empty HANA HDI scheme. Then import the PD Model which contains the HANA CDS views into HANA WebIDE and build the CDS views which creates the empty HANA database tables which will be the target tables for the replication task.
https://sapvideoa35699dc5.hana.ondemand.com/?entry_id=1_njmdz0wi
Demo Part 3: Using the HANA WebIDE replication task tool in HANA WebIDE to create virtual tables, materialize table data into target tables and continuously replicate MS SQL Server transactions in real-time into HANA HDI tables.
https://sapvideoa35699dc5.hana.ondemand.com/?entry_id=1_yg2o295i
HANA SDI Replication Task accessing SAP ERP Application using ABAP (ODP/ODQ) Adapter
In his “Access SAP ERP data from SAP HANA through SDI ABAP Adapter” BLOG, Maxime Simon walks through the steps for setting up a WedIDE Replication Task that accesses an ABAP view and replicates the data into a target table in HANA which is synchronized in real-time using the ABAP ODP/ODQ interface and the HANA SDI ABAP adapter. For details see Maxime Simon’s BLOG “Access SAP ERP data from SAP HANA through SDI ABAP Adapter”:
https://blogs.sap.com/2020/03/16/access-sap-erp-data-from-sap-hana-through-sdi-abap-adapter-2/
The steps are very similar to the previous Replication Task setup:
- Create a remote source using HANA SDI ABAP adaoter
- Select remote source objects
- Execute RepTask
- View both virtual table and local replicate table containing data
Create Remote ABAP Source:

Select remote source objects:
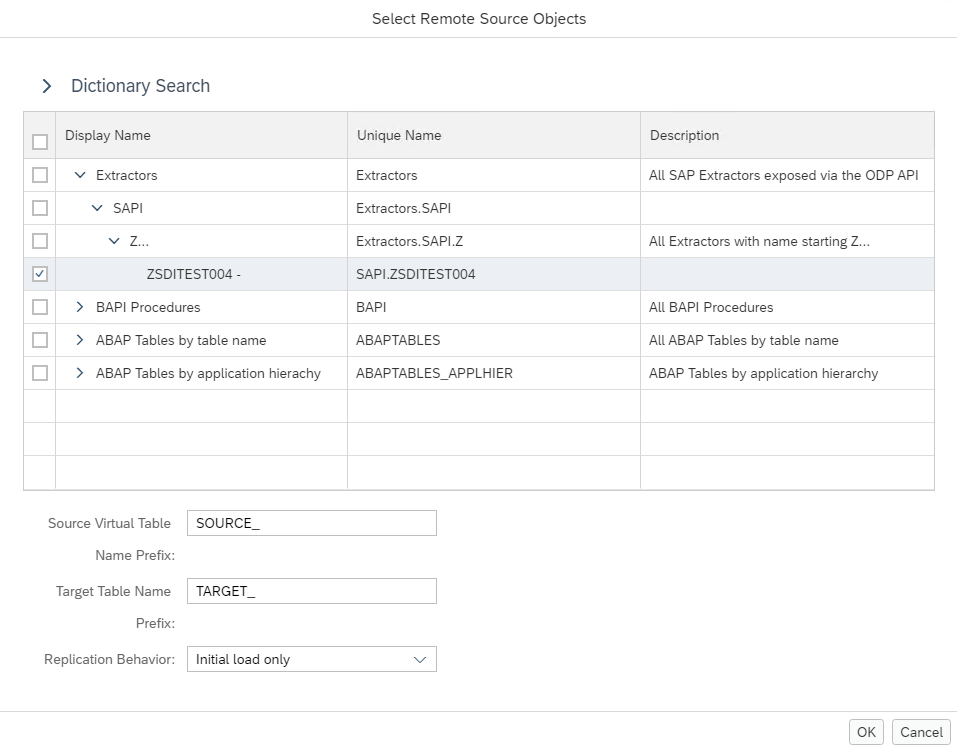
This replication task will create 2 tables on SAP HANA: a virtual table for the remote object and a physical target table. Set the replication behavior to Initial + real time if you want to replicate data in real time from your ERP system.

View replicate table containing data:
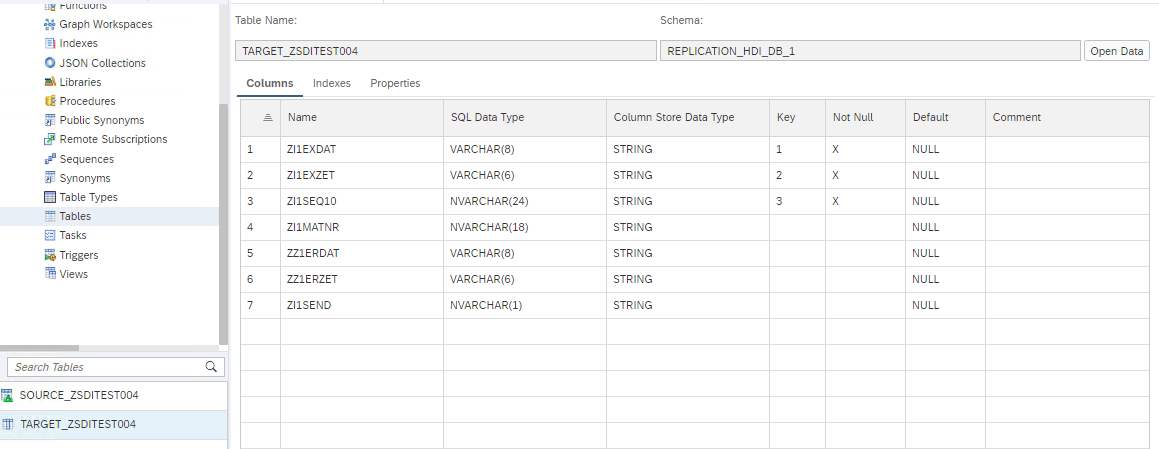
HANA Smart Data Streaming real-time message ingestion
This is an older but still very simple and concise overview of HANA Smart Data Streaming:
SAP HANA Academy - Streaming Analytics: An Introduction
https://www.youtube.com/watch?v=9XVIXFSImHc&list=PLkzo92owKnVz6jyluKi9S7WRKMIqLvM2w&index=2&t=0s

This is part of an entire playlist of over 60 videos about Smart Data Streaming and HANA Streaming Analytics produced by HANA Academy:
https://www.youtube.com/playlist?list=PLkzo92owKnVz6jyluKi9S7WRKMIqLvM2w
This is an older but very quick example of the steps required to simply and easily load messaging data into HANA. This is using the HANA Workbench tool.
SAP HANA Academy - Smart Data Streaming: A Quick Demo [SPS 09]
https://www.youtube.com/watch?v=Bulk-ODNMlE&list=PLkzo92owKnVz6jyluKi9S7WRKMIqLvM2w&index=3

SAP HANA Academy - Streaming Analytics: What’s New? [2.0 SP 04]
https://www.youtube.com/watch?v=F7Ij-H9frK8&list=PLkzo92owKnVz6jyluKi9S7WRKMIqLvM2w&index=68
The target of this BLOG is just simple data ingestion. SAP HANA Streaming Analytics is capable of much much more than just simple data ingestion: SAP HANA streaming analytics processes streams of incoming event data in real time and collects and acts on this information.
Streaming analytics is ideally suited for situations where data arrives as events happen, and where there is value in collecting, understanding, and acting on this data right away. Some examples of data sources that produce streams of events in real time include:
- Sensors
- Smart devices
- Web sites (click streams)
- IT systems (logs)
- Financial markets (prices)
- Social media
Data flows into streaming projects from various sources, typically through adapters, which connect the sources to the streaming analytics server. The streaming projects contain business logic, which they apply to the incoming data, typically in the form of continuous queries and rules. These streaming projects are entirely event-driven, turning the raw input streams into one or more derived streams that can be captured in the SAP HANA database, sent as alerts, posted to downstream applications, or streamed to live dashboards
Conclusion
These presentations and demonstrations show how the HANA platform can give you immediate access to all your enterprise and internet data and the ability to simply, easily and efficiently access or replicate remote data into local HANA tables. The HANA digital business platform access to the data is secure and governed. This will significant lower time and cost to deliver new advanced insights to the business and lower total cost of ownership of the entire solution. The value of such a solution includes:
- Immediate access to all enterprise and internet data,
- Simple, easy and efficient harmonization of data,
- Secure and governed access to data,
- Significant lower time to deliver new advanced insights to the business,
- Lower total cost of ownership of the entire solution,
- Replace costly latency stricken ETL with simple, easy and efficient data replication, and
- Real-time data synchronization.
After watching these presentations and demos customers should be able to easily setup routines to copy remote data from tables and applications and to keep that data up to date in real-time.
SAP HANA Data Strategy BLOGs Index
SAP HANA Data Strategy
- SAP HANA Data Strategy: HANA Data Modeling a Detailed Overview
- HANA Data Strategy: Data Ingestion including Real-Time Change Data Capture
- Access SAP ERP data from SAP HANA through SDI ABAP Adapter by Maxime Simon
- The fastest way to load data from HANA Cloud, HANA to HANA Cloud, HANA Data Lake
- HANA Data Strategy: Data Ingestion – Virtualization
- HANA Data Strategy: HANA Data Tiering
- SAP Managed Tags:
- SAP HANA Cloud,
- SAP HANA,
- SAP HANA smart data integration,
- SAP HANA streaming analytics,
- Big Data
Labels:
1 Comment
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
85 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
269 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
10 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,578 -
Product Updates
318 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
390 -
Workload Fluctuations
1
Related Content
- How to test a Windows Failover cluster? in Technology Blogs by SAP
- Harnessing Generative AI Capabilities with SAP HANA Cloud Vector Engine - Part 1 [Architecture] in Technology Blogs by SAP
- SAP Datasphere with Confluent --> Part 2 in Technology Blogs by SAP
- SAP HANA Cloud, HANA データベースから SAP HANA Cloud, data lake リレーショナルエンジンへの最速のデータ移動方法と移動速度テスト結果 in Technology Blogs by SAP
- LangChain vs LlamaIndex: Enhancing LLM Applications on SAP BTP in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 11 | |
| 11 | |
| 10 | |
| 9 | |
| 9 | |
| 9 | |
| 9 | |
| 8 | |
| 7 | |
| 7 |