
- SAP Community
- Products and Technology
- Enterprise Resource Planning
- ERP Blogs by Members
- The Critical Need for SAP ERP High Availability Pr...
Enterprise Resource Planning Blogs by Members
Gain new perspectives and knowledge about enterprise resource planning in blog posts from community members. Share your own comments and ERP insights today!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
harryaujla
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
05-22-2020
4:50 AM
Meeting Availability SLA's for SAP Can be Challenging
Meeting high availability Service Level Agreements (SLAs) is essential to ensure the key components of the IT infrastructure and application are protected and that services to end users, customers, and vendors can be recovered as rapidly as possible in the event of an outage. Many companies set specific recovery time objectives (RTO), and recovery point objectives(RPO) as part of their formal SLA process.
While high availability (HA) can address various parts of an IT infrastructure, with SAP, high availability predominantly refers to the application and the associated data—regardless of whether the application runs in a physical, virtual or cloud infrastructure. Availability is usually expressed as a percentage of downtime in a 12 month period, which relates to the acceptable amount downtime for the application.
For example, availability technologies can range from simple backup that provides 99.9% availability, (approximately nine hours of downtime per year) to continuous availability solutions that ensure fewer than five minutes of application downtime per year. A wide range of solutions provide various levels of high availability based on the figures in table 1: The higher the level of availability, the higher the cost.
For most mission-critical applications like SAP, solutions that provide (99.99%) availability is the most common balance of cost and uptime protection, because it can be delivered via technologies, such as clustering, at a suitable price point.

Disaster recovery (DR) protection is another concern. Companies often want to ensure their SAP environment is protected not only from application or server failures, but also from sitewide downtime (data center power outage), and even regional disasters (hurricane, flood).
Key Components of an HA/DR Solution for SAP
Any high-availability solution for SAP needs to achieve four core goals:
- Minimize downtime
- Eliminate data loss
- Maintain data integrity
- Enable flexible configuration
While building HA into the SAP application allows for core application-level intelligence to be developed within the solution itself, it does not protect the rest of the infrastructure. In contrast, an application-aware solution that is built into the infrastructure allows for a wider level of protection across multiple platforms, operating systems, applications and databases—thus providing transparent application recovery and data replication.
This approach also enables complete flexibility for configuring a HA/DR cluster in a variety of ways—active-active, active-passive, and a wide range of multi-node options—to best meet your needs.
Two key components of the solution should be considered:
- Health of the Application - From an application standpoint, the solution needs to monitor the health of various components and services, detect failures, recover failed services as quickly as possible, and continue running the application. The time allowed by a company to detect an issue, failover, and then recover the service, is referred to as the Recovery Time Objective (RTO). Meeting a fast RTO requires a solution with application awareness to migrate the services to backup node(s) as smoothly as possible during a failover scenario. Many data protection solutions only monitor and detect whether a server is operational, but do not detect whether the application running on it is operational. As a result, serious application downtime issues can go undetected. For critical ERP systems like SAP, the clustering solution needs to be deeply application-aware.
- Health of the Data – Many companies set recovery point objectives (RPOs) for the age of the data at the point of recovery. RPOs are also a measure of how much data loss is acceptable in a downtime incident. In most clustering solutions, all cluster nodes use the same shared storage – typically a SAN – to ensure that after failover, the secondary node(s) are accessing the most recent data. This configuration introduces a single point of failure. In addition, it enables clustering in several cases in which shared storage is not possible or practical, such as in a cloud environment. To ensure the best RPO in these cases, use a “SANless” clustering solution that uses a highly efficient host-based, block-level replication engine to synchronize and mirror local storage in the cluster nodes.
Providing High Availability for Multiple SAP Components
SAP ERP solutions comprise multiple components and services that interact with each other to form a comprehensive network of functions, including but not limited to:
- ABAP Central Services (ASCS)
- Java Central Services (SCS)
- Enqueue Replication Server (ERS)
- Primary Application Server (PAS)
In addition to these services, the SAP landscape relies on a database element, such as SAP HANA, which also needs to be considered for HA protection. Your SAP environment may also include NetWeaver, and S4/HANA.
To be effective, an HA solution must monitor the health of all these services, and in the event that a service does not perform as expected—or even fails completely—the high-availability solution will take the appropriate action to recover that service as quickly as possible. Further, the solution will bring the services online in the secondary node(s) and in the correct order to ensure SAP functions resume quickly and that data is not corrupted.
The service restart may occur on the same node or if necessary, on an alternative node within the cluster. In the latter case, IT has used clustering software to configure secondary node(s) are kept on standby as ready-to-start-services that will continue operating if there is an issue with the primary node.
As discussed earlier, to meet stringent recovery point objectives (RPOs), this failover cluster should also be configured so that either the primary and secondary nodes share the same storage (e.g. SAN), or so that the storage for the primary node and secondary nodes are mirrored with efficient replication. Synchronized (mirrored) storage has several key advantages. It allows you to create a failover cluster in cloud environments where shared storage is not an option. It also allows you to use local solid-state drives (SSD) for cost-efficient, high-performance storage.
Failover clustering protection ensure minimal downtime of that service, and thus minimal impact to end-users. In parallel, the database is protected by replicating the data to be available on the secondary node within the same HA cluster, eliminating the SAN single point of failure. This data replication protection can be applied regardless of the type of database, including MaxDB, DB2, and SAP HANA.
Also consider the need to geographically separate the nodes in the cluster for protection from site-wide or regional disasters. Use a clustering solution that allows failover between cluster nodes on different cloud subnets or in different geographically separated locations.
Advanced High-Availability Clustering Features
The SIOS LifeKeeper for Linux meets SAP’s stringent testing requirements to provide SAP-certified high-availability support for the SAP S/4HANA platform. This designation comes via the SAP High-Availability Clustering Certification S/4-HA-CLU-1.0. SIOS products also provide certified support for both NetWeaver, version 2 of the SAP Standalone Enqueue Server, and Replication Server Framework.
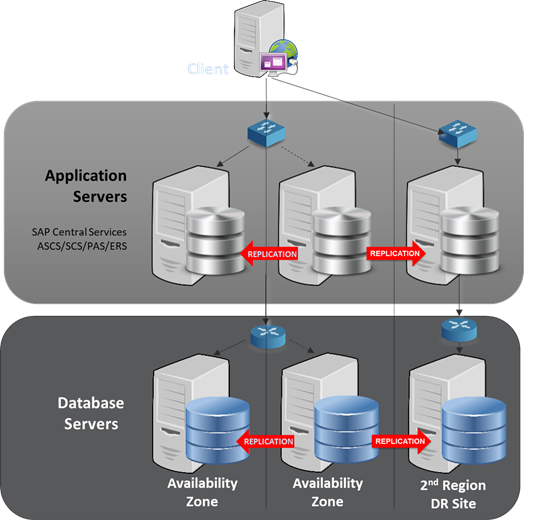
The updated SAP Enqueue Server Framework provides enhanced high-availability features by allowing the ABAP Central Services (ASCS) instance to failover to any cluster node—rather than limiting it to the node where the corresponding Enqueue server instance is running.
To facilitate these new high-availability features in the SAP software, the ERS resource type in SIOS LifeKeeper failover clustering software enables the resource hierarchy to failover independently of the corresponding ASCS resource hierarchy. This provides greater flexibility in various recovery scenarios. When possible, SIOS LifeKeeper automatically locates the ERS resource away from the ASCS resource. This provides redundancy for the Enqueue lock table data across cluster nodes.
Finally, SIOS applies several enhancements to the SIOS SAP HA Cluster Connector, which allows the SAP front-end management software to communicate with SIOS LifeKeeper. This interface ensures that any administrative actions performed on SAP instances throughout the cluster will be redirected back through LifeKeeper. The status of cluster resources is thus kept up-to-date, even when changes are made outside of the LifeKeeper user-interface. The result: efficient, application-aware clustering protection for the entire SAP platform.
As your IT team implements or checks to confirm high availability capabilities for SAP ERP, here are nine key steps to follow to make sure your system is fully protected:
#1 - ELIMINATE SINGLE POINTS OF FAILURE
Any high-availability topology for mission-critical applications such as SAP needs to be architected to eliminate single points of failure, such as connecting your cluster nodes to a single SAN or other shared storage. If you are running SAP in the cloud, take advantage of geographically-separated availability zones and/or regions. Although a high-availability cluster can be deployed within a single availability zone, the zone itself presents a single-point-of-failure. That is, if the zone becomes unavailable, customers can potentially lose access to the entire high-availability cluster and associated data.
The best practice in this scenario is to separate the SAP cluster nodes across availability zones, such as Node1 in Zone1, Node2 in Zone2, and a witness or quorum node in Zone3. If necessary, the SAP application can then failover from one availability zone to another. Customers can also address any disaster recovery requirements by adding a third node to the high-availability cluster in an additional availability zone or region.
#2 – ENSURE PERFORMANCE IS NOT AFFECTED BY RESOURCE ALLOCATION CONSTRAINTS
When designing a high-availability cluster, ensure that the performance of the SAP software is not affected by resource allocation constraints across the cluster nodes. To meet this need, a common practice is to deploy separate high-availability clusters for the protected SAP instances (ASCS/ERS, PAS, AAS) and the associated database. Applying this practice allows for maximum performance for both the SAP software and the database—rather than forcing them to fight over system resources if running on the same cluster nodes. This is especially important when using a memory-intensive database solution such as SAP HANA.
#3 - UPGRADE TO SAP ENQUEUE SERVER FRAMEWORK VERSION 2
In the past, in a configuration using version 1 of the SAP Standalone Enqueue Server (ENSA) Framework, after a failure event the Central Services instance always needed to be started on the cluster node where the ERS instance was running. This was necessary to retrieve the replicated lock table from local shared memory on that node, and it created a requirement for the Central Services resource to be brought online immediately following the ERS resource on failover.
In a two-node cluster, this does not pose an issue, since there is only one backup node available for failover. However, in clusters with three or more nodes, making sure that the Central Services resource always fails over to the correct node can be difficult, depending on the cluster architecture.
Version 2 of the Standalone Enqueue Server Framework eliminates this issue by assigning a dedicated virtual IP/hostname to the ERS instance, and then directing traffic to the cluster node currently hosting the ERS instance. Because of this dedicated virtual IP for ERS, the corresponding Central Services instance can failover to any cluster node and retrieve its replicated lock table through the network. This eliminates the <ASCS must follow ERS on failover> requirement and creates more independence between the ASCS and ERS resources in a high-availability cluster environment.
#4 - DETERMINE THE ENQUEUE REPLICATION SERVER VERSION ON THE SAP CLUSTER
If the SAP system was initially installed using SAP kernel 7.53 or later, version 2 of the Standalone Enqueue Server Framework is installed by default. To determine which version is currently used in the cluster, look at the <sapcontrol GetProcessList webmethod> output for each instance.
Switch to the SAP administrative user <sid>adm, where <sid> is the lower-case SAP System Identifier for the SAP installation:
- su - <sid>adm
- 2. Call…
- sapcontrol -nr <Instance #> -function GetProcessList
- Here are the process-name outputs for each version of the Enqueue Server for the ASCS instance:
- ENSAv1: enserver, EnqueueServer
- ENSAv2: enq_server, EnqueueServer 2
- Here are the process-name outputs for each version of the Replication Server for the ERS instance:
- ERSv1: enrepserver, EnqueueReplicator
- ERSv2: enq_replicator, EnqueueReplicator 2
- The version for the Enqueue Server should be the same as the version for the Replication Server. The processes used for each version are not compatible with the processes used for the other version.
#5 - UPGRADE TO VERSION 2 OF THE STANDALONE ENQUEUE SERVER FRAMEWORK
When upgrading to version 2 of the Standalone Enqueue Server Framework, there are two important SAP Notes to follow that are accessible through <support.sap.com>.
SAP Note 2711036 (Usage of the Standalone Enqueue Server 2 in an HA Environment) and the ENSAv2 documentation linked to in that note.
SAP Note 2854919 (Upgrading from ENSAv1 to ENSAv2 when using SIOS Protection Suite for Linux).
Here are the high-level basic steps:
- Perform a rolling kernel switch to a version of the SAP kernel that supports version 2 of the Standalone Enqueue Server Framework (i.e., SAP kernel 7.51 or later).
- If the ERS instance was previously installed locally on each cluster node, a new shared
- ERS file system may need to be created. The details of this step will depend on the file-sharing mechanisms in use.
- Edit the ASCS and ERS instance profiles as documented by SAP to use the new binaries and instance parameters for enqueue server and replication server version 2.
- Upgrade SIOS Protection Suite for Linux to a version (9.4.0 or later) that supports enqueue server version 2.
- If you already have a LifeKeeper ASCS resource, edit the LifeKeeper ASCS resource info file on each cluster node and set SAPENQ_VERSION=2; otherwise, follow the SIOS Protection Suite for Linux documentation to create an ASCS resource hierarchy.
- If you already have a LifeKeeper ERS resource, delete any dependencies that involve it; then delete the ERS resource and recreate it in LifeKeeper 9.4.0 or later. If you do not have an existing LifeKeeper ERS resource, follow the SIOS Protection Suite for Linux documentation to create an ERS resource hierarchy.
- Edit the LifeKeeper ERS resource info file on each cluster node and set SAPENQREP_ VERSION=2.
#6 - SET UP SHARED FILE SYSTEMS FOR ASCS AND ERS
To set up shared file systems for ASCS and ERS, many SIOS customers use an NFS configuration in which the current host for each resource acts as the NFS server for the corresponding SAP instance file system. This means that the file system for each SAP instance is accessible via the virtual IP associated with that instance.
In this configuration, the Central Services (SCS/ASCS) resource host will also typically host the NFS share for the SAP Mount file system. One benefit of this configuration is that it only requires resources within the existing cluster, which can cut down on costs.
While this is the most common configuration, others are possible:
- A dedicated external NFS server or cluster to host all SAP-related shared file systems.
- Cloud-based file sharing solutions such as Amazon Web Services (AWS) Elastic File System (EFS) and Microsoft Azure Files.
- In these cases, the SAP file systems can be mounted on each cluster node using the <autofs> service. This in turn can be protected with a corresponding LifeKeeper Quick Service Protection resource on each cluster node.
- The primary advantages of hosting the shared file systems on a server outside the cluster or with a cloud-based file sharing solution are improved failover times as well as improved availability of the file systems when servers within the cluster fail. The primary downside to this approach is the additional cost associated with either the additional servers or cloud service.
#7 - TEST ASCS/CRS CLUSTERS FOR ENQUEUE LOCK TABLE CONSISTENCY
To ensure data integrity and failovers will happen quickly and with minimal disruption, follow the following steps for verifying enqueue lock table consistency on failovers and switchovers for an ASCS/ERS cluster:
- Bring the ASCS resource in-service on the primary cluster node, and bring the ERS resource in-service on a backup cluster node.
- Write a collection of dummy locks to the enqueue server in the ASCS instance.
- For ENSAv1, this will require the use of the <enqt> utility with opcode 11.
- For ENSAv2, use the <enq_admin> utility with the <--set_locks> argument.
- Replace <# Locks> by the number of locks you want to write (e.g., 100) and <Path to ASCS Profile> by the full path to the ASCS instance profile (typically located at /usr/ sap/<SID>/SYS/profile/<SID>_ASCS<##>_<ASCS Virtual Host Name>).
- ENSAv1: su - <sid>adm -c “enqt pf=<Path to ASCS Profile> 11 <# Locks>”
- ENSAv2: su - <sid>adm -c “enq_admin --set_locks=<# Locks>:X:DIAG::TAB:%u pf=<Path to ASCS Profile>”
- Verify that the correct number of locks was written to the enqueue server lock table. This can be done by looking at the <locks_now> field in the output of the following sapcontrol command on the cluster node where the ASCS resource is currently in-service:
- su - <sid>adm -c “sapcontrol -nr <ASCS Instance #> -function EnqGetStatistic
- To test machine failover, power down the primary node currently hosting the ASCS instance.
- To test resource hierarchy switchover, manually bring the ASCS resource in-service on a backup node.
- Once the ASCS resource has successfully completed failover or switchover, check that the enqueue lock table was successfully rebuilt by verifying that the value of the <locks_now> field is the same as in Step 3 when the following sapcontrol command is run on the cluster node that the ASCS resource is now in-service on:
- su - <sid>adm -c “sapcontrol -nr <ASCS Instance #> -function EnqGetStatistic”
- After the test and when appropriate, release the dummy locks written to the enqueue server lock table by using one of the following commands for the version of the enqueue server installed on the system:
- ENSAv1: su - <sid>adm -c “enqt pf=<Path to ASCS Profile> 12 <# Locks>”
- ENSAv2: su - <sid>adm -c “enq_admin --release_locks=<# Locks>:X:DIAG::TAB:%u pf=<Path to ASCS Profile>”
- Once it has been verified that the enqueue server can successfully rebuild its lock table on switchover and failure, the ASCS/ERS cluster setup has been validated.
#8 – MANAGE INSTANCES CAREFULLY
It is important for any HA solution to carefully manage the instances in the SAP environment so that they are brought online and configured to communicate with one another in a coordinated manner. For example, the enqueue server in the Central Services (SCS/ASCS) instance maintains the current database lock table, which helps prevent database collisions by concurrent users and is a single point of failure in the SAP system.
If the enqueue server is down, no database transactions can take place. And if the lock table can’t be recovered after a failure event, all database transactions that were in progress during the failure will be lost.
As a result, it is important to maintain an Enqueue Replication Server instance on a separate cluster node from the Central Services instance. This node will hold a replicated back-up copy of the lock table that the Enqueue Server can use to recover its active locks after a failure.
In a scenario such as this, the high-availability software must keep the ASCS and ERS instances running on separate nodes (when possible) in order to ensure data redundancy. It’s also important to orchestrate failover in such a way that the lock table data can be recovered. This makes it possible for all previous in-progress database transactions to pick up where they left off.
#9 – ESTABLISH CLEAR SLAS AND AVOID SINGLE POINTS OF FAILURE IN THE CLOUD
If your SAP ERP platform operates in the cloud, or if you are considering migrating from on-premises to the cloud, there are two key considerations for implementing high-availability clusters for a heavy-hitting application like SAP:
Establish clear SLAs with your cloud provider and agree on which levels of availability are required around your mission-critical applications. Identify whether you require three, four, or five 9’s of application availability. Note that service level policies for many cloud providers address instance availability but do no guarantee application availability.
From an availability standpoint, design the SAP landscape to avoid any single points-of-failure in a way to prevent any impact on application performance, thus operating within the agreed-upon SLAs.
The other key aspects that impact the SLA are instance sizing, infrastructure design, security, and network requirements. Be sure to discuss these with your cloud provider as well.
Minimizing High-Availability Complexity
As you take on the challenge of high-availability—whether on-premises or in the cloud—realize that high-availability is complex. SIOS LifeKeeper and SIOS DataKeeper reduce that complexity by eliminating single points of failure and adding configuration flexibility.
Practice patience and carefully follow the documentation for setup and upgrades and test any new configurations extensively before deploying into production. By doing so, you can ensure that SAP ERP—the heart of your business operations—will continue to run smoothly no matter what type of disaster may strike.
- SAP Managed Tags:
- SAP HANA,
- SAP S/4HANA
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"mm02"
1 -
A_PurchaseOrderItem additional fields
1 -
ABAP
1 -
ABAP Extensibility
1 -
ACCOSTRATE
1 -
ACDOCP
1 -
Adding your country in SPRO - Project Administration
1 -
Advance Return Management
1 -
AI and RPA in SAP Upgrades
1 -
Approval Workflows
1 -
Ariba
1 -
ARM
1 -
ASN
1 -
Asset Management
1 -
Associations in CDS Views
1 -
auditlog
1 -
Authorization
1 -
Availability date
1 -
Azure Center for SAP Solutions
1 -
AzureSentinel
2 -
Bank
1 -
BAPI_SALESORDER_CREATEFROMDAT2
1 -
BRF+
1 -
BRFPLUS
1 -
Bundled Cloud Services
1 -
business participation
1 -
Business Processes
1 -
CAPM
1 -
Carbon
1 -
Cental Finance
1 -
CFIN
1 -
CFIN Document Splitting
1 -
Cloud ALM
1 -
Cloud Integration
1 -
condition contract management
1 -
Connection - The default connection string cannot be used.
1 -
Custom Table Creation
1 -
Customer Screen in Production Order
1 -
Data Quality Management
1 -
Date required
1 -
Decisions
1 -
desafios4hana
1 -
Developing with SAP Integration Suite
1 -
Direct Outbound Delivery
1 -
DMOVE2S4
1 -
EAM
1 -
EDI
3 -
EDI 850
1 -
EDI 856
1 -
edocument
1 -
EHS Product Structure
1 -
Emergency Access Management
1 -
Energy
1 -
EPC
1 -
Financial Operations
1 -
Find
1 -
FINSSKF
1 -
Fiori
1 -
Flexible Workflow
1 -
Gas
1 -
Gen AI enabled SAP Upgrades
1 -
General
1 -
generate_xlsx_file
1 -
Getting Started
1 -
HomogeneousDMO
1 -
IDOC
2 -
Integration
1 -
Learning Content
2 -
LogicApps
2 -
low touchproject
1 -
Maintenance
1 -
management
1 -
Material creation
1 -
Material Management
1 -
MD04
1 -
MD61
1 -
methodology
1 -
Microsoft
2 -
MicrosoftSentinel
2 -
Migration
1 -
mm purchasing
1 -
MRP
1 -
MS Teams
2 -
MT940
1 -
Newcomer
1 -
Notifications
1 -
Oil
1 -
open connectors
1 -
Order Change Log
1 -
ORDERS
2 -
OSS Note 390635
1 -
outbound delivery
1 -
outsourcing
1 -
PCE
1 -
Permit to Work
1 -
PIR Consumption Mode
1 -
PIR's
1 -
PIRs
1 -
PIRs Consumption
1 -
PIRs Reduction
1 -
Plan Independent Requirement
1 -
Premium Plus
1 -
pricing
1 -
Primavera P6
1 -
Process Excellence
1 -
Process Management
1 -
Process Order Change Log
1 -
Process purchase requisitions
1 -
Product Information
1 -
Production Order Change Log
1 -
purchase order
1 -
Purchase requisition
1 -
Purchasing Lead Time
1 -
Redwood for SAP Job execution Setup
1 -
RISE with SAP
1 -
RisewithSAP
1 -
Rizing
1 -
S4 Cost Center Planning
1 -
S4 HANA
1 -
S4HANA
3 -
Sales and Distribution
1 -
Sales Commission
1 -
sales order
1 -
SAP
2 -
SAP Best Practices
1 -
SAP Build
1 -
SAP Build apps
1 -
SAP Cloud ALM
1 -
SAP Data Quality Management
1 -
SAP Maintenance resource scheduling
2 -
SAP Note 390635
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud private edition
1 -
SAP Upgrade Automation
1 -
SAP WCM
1 -
SAP Work Clearance Management
1 -
Schedule Agreement
1 -
SDM
1 -
security
2 -
Settlement Management
1 -
soar
2 -
Sourcing and Procurement
1 -
SSIS
1 -
SU01
1 -
SUM2.0SP17
1 -
SUMDMO
1 -
Teams
2 -
User Administration
1 -
User Participation
1 -
Utilities
1 -
va01
1 -
vendor
1 -
vl01n
1 -
vl02n
1 -
WCM
1 -
X12 850
1 -
xlsx_file_abap
1 -
YTD|MTD|QTD in CDs views using Date Function
1
- « Previous
- Next »
Related Content
- SAP Signavio Process Navigator turning 1-year old today! in Enterprise Resource Planning Blogs by SAP
- SAP S/4HANA Cloud Public Edition: Security Configuration APIs in Enterprise Resource Planning Blogs by SAP
- What You Need to Know: Security and Compliance when Moving to a Cloud ERP Solution in Enterprise Resource Planning Blogs by SAP
- Futuristic Aerospace or Defense BTP Data Mesh Layer using Collibra, Next Labs ABAC/DAM, IAG and GRC in Enterprise Resource Planning Blogs by Members
- How to Create Outbound Delivery With order reference in SAP VL01N in Enterprise Resource Planning Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 5 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 1 | |
| 1 | |
| 1 |