
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Checking the behavior of SAP HANA Cloud virtual ta...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
05-18-2020
2:01 AM
(Japanese version)
In this blog, I will share you the experience of behaviour check of SAP HANA Cloud Virtual Table Replica feature. I have checked following options.
SAP HANA Cloud can be positioned as "The Single Data Gateway", this means any type of enterprise data can be integrated virtually. Specifically, various data sources can be integrated via virtual tables created on HANA Cloud (Data Federation).
However, it may happen that you want to physically store the data in SAP HANA Cloud from the performance and maintenance point of view.
Although On-Premise SAP HANA can replicate data with ETL functionality like SDI in such cases, SAP HANA Cloud can replicate data (or have snapshot data) only by setting it as an option of virtual tables. (No ETL job required!)
*Of course, data can be replicated to SAP HANA Cloud using SDI (also in batch and real-time linkage). Please refer to this blog for details.
I have referred the information as follows.
* This blog shows the following parts (Online switch federation / caching / replication) of the SAP HANA Cloud overview document.
As a prerequisite, Data Provisioning Agent needs to be set up, please refer to this blog how to set up it.
First, create a virtual table on SAP HANA Cloud. It shows a table in On-Premise SAP HANA.
Virtual Table is created.
Check the number of rows.
Then, execute SELECT statement to the virtual table. The statement is executed on the source system (On-Premise SAP HANA) and only the result set is transferred to the SAP HANA Cloud. It takes a little time due to this.
* On-Premise HANA is running on AWS us-east, SAP HANA Cloud is running on AWS Frankfurt
Next, execute ALTER TABLE statement against the virtual table which was created in the previous step. This statement changes the behavior of the virtual table from data federation to data replication.
By this command, a table which stores replicated data is automatically generated in schema "_SYS_TABLE_REPLICA_DATA".
From the runtime information of the generated table, you can see that the number of record is same as the source table and it physically stores data.
Check the number of records of the virtual table, it is same number as before ALTER TABLE.
Execute the same SELECT statement. The performance is much improved.
Then, update the source table data. In this test, I have added two records.
Check the number of records of the virtual table, you can find 2 records are added.
Also check the auto-generated table and you can see the record count is increased by 2 records. This means that the data updated on the source side has been replicated to SAP HANA Cloud in the near real-time.
Finally, stop and delete the replication by ALTER TABLE statement.
The auto-generated table is dropped.
Next, I will replicate snapshot data. For this execute ALTER Statement against the virtual table.
A table is automatically generated on schema "_SYS_TABLE_REPLICA_DATA" as same as data replication.
Check the runtime information of the table and you can find the table physically stores data.
Execute SELECT statement and the result is returned as fast as the previous replication case.
And then, update the source table. In this case I have added one record.
The source table was updated, however the data in the SAP HANA Cloud snapshot table is not updated.
Check the number of rows of the virtual table, the data is not updated.
Then, update the snapshot data with the following command.
The virtual table data was updated.
The Snapshot table was also updated.
Finally, delete the snapshot with the following command.
The snapshot table was droped.
Executing a SELECT statement against the virtual table now takes a little tame, as before. (Retrieving data from On-Premises SAP HANA)
The above is the introduction of the behaviour check results of the virtual table replication feature.
While virtual data integration can provide data to business users quickly, there are concerns about performance, maintenance and system/network workload.
The virtual table replication feature introduced to SAP HANA Cloud can perform real-time data replication and snapshot data creation simply by changing the virtual table settings with the ALTER TABLE statement. In other words, it is not necessary to create ETL jobs, and it is possible to set it up online, which makes it possible to optimize performance easily and quickly.
By utilizing this feature, first provide data to business users by virtual data integration, and then perform this setting when it is verified to be businessally beneficial and a faster response is required. This means, agile data utilization can be realized.
Overview
In this blog, I will share you the experience of behaviour check of SAP HANA Cloud Virtual Table Replica feature. I have checked following options.
- Federation
- Replication
- Snapshot (Cache)
SAP HANA Cloud can be positioned as "The Single Data Gateway", this means any type of enterprise data can be integrated virtually. Specifically, various data sources can be integrated via virtual tables created on HANA Cloud (Data Federation).
However, it may happen that you want to physically store the data in SAP HANA Cloud from the performance and maintenance point of view.
Although On-Premise SAP HANA can replicate data with ETL functionality like SDI in such cases, SAP HANA Cloud can replicate data (or have snapshot data) only by setting it as an option of virtual tables. (No ETL job required!)
*Of course, data can be replicated to SAP HANA Cloud using SDI (also in batch and real-time linkage). Please refer to this blog for details.
I have referred the information as follows.
- SAP Help - Toggling Between Virtual Tables and Replication Tables
- SAP Help - ALTER VIRTUAL TABLE Statement (Data Definition)
* This blog shows the following parts (Online switch federation / caching / replication) of the SAP HANA Cloud overview document.
As a prerequisite, Data Provisioning Agent needs to be set up, please refer to this blog how to set up it.
1. Data Federation
First, create a virtual table on SAP HANA Cloud. It shows a table in On-Premise SAP HANA.
create virtual table "FVT_LINEITEM" at "OPHANA"."<NULL>"."TPCH"."LINEITEM_2";Virtual Table is created.
Check the number of rows.
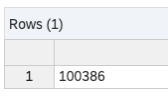
Then, execute SELECT statement to the virtual table. The statement is executed on the source system (On-Premise SAP HANA) and only the result set is transferred to the SAP HANA Cloud. It takes a little time due to this.
* On-Premise HANA is running on AWS us-east, SAP HANA Cloud is running on AWS Frankfurt

2. Data Replication
Next, execute ALTER TABLE statement against the virtual table which was created in the previous step. This statement changes the behavior of the virtual table from data federation to data replication.
alter virtual table "FVT_LINEITEM" add shared replica;By this command, a table which stores replicated data is automatically generated in schema "_SYS_TABLE_REPLICA_DATA".

From the runtime information of the generated table, you can see that the number of record is same as the source table and it physically stores data.
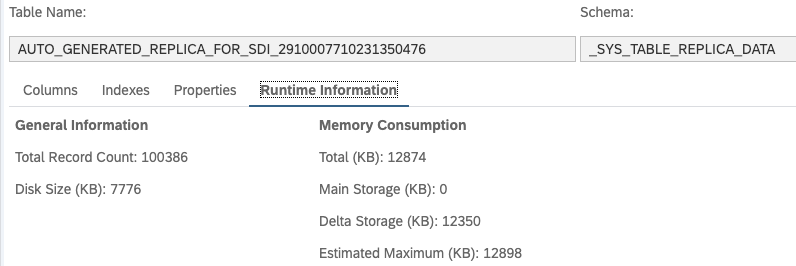
Check the number of records of the virtual table, it is same number as before ALTER TABLE.

Execute the same SELECT statement. The performance is much improved.

Then, update the source table data. In this test, I have added two records.

Check the number of records of the virtual table, you can find 2 records are added.

Also check the auto-generated table and you can see the record count is increased by 2 records. This means that the data updated on the source side has been replicated to SAP HANA Cloud in the near real-time.

Finally, stop and delete the replication by ALTER TABLE statement.
alter virtual table "FVT_LINEITEM" drop replica;The auto-generated table is dropped.

3. Data Snapshot
Next, I will replicate snapshot data. For this execute ALTER Statement against the virtual table.
alter virtual table "FVT_LINEITEM" add shared snapshot replica;A table is automatically generated on schema "_SYS_TABLE_REPLICA_DATA" as same as data replication.
Check the runtime information of the table and you can find the table physically stores data.

Execute SELECT statement and the result is returned as fast as the previous replication case.

And then, update the source table. In this case I have added one record.

The source table was updated, however the data in the SAP HANA Cloud snapshot table is not updated.

Check the number of rows of the virtual table, the data is not updated.

Then, update the snapshot data with the following command.
alter virtual table "FVT_LINEITEM" refresh snapshot replica;The virtual table data was updated.

The Snapshot table was also updated.

Finally, delete the snapshot with the following command.
alter virtual table "FVT_LINEITEM" drop replica;The snapshot table was droped.
Executing a SELECT statement against the virtual table now takes a little tame, as before. (Retrieving data from On-Premises SAP HANA)

Conclusion
The above is the introduction of the behaviour check results of the virtual table replication feature.
While virtual data integration can provide data to business users quickly, there are concerns about performance, maintenance and system/network workload.
The virtual table replication feature introduced to SAP HANA Cloud can perform real-time data replication and snapshot data creation simply by changing the virtual table settings with the ALTER TABLE statement. In other words, it is not necessary to create ETL jobs, and it is possible to set it up online, which makes it possible to optimize performance easily and quickly.
By utilizing this feature, first provide data to business users by virtual data integration, and then perform this setting when it is verified to be businessally beneficial and a faster response is required. This means, agile data utilization can be realized.
- SAP Managed Tags:
- SAP HANA Cloud,
- SAP HANA
Labels:
5 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
273 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
324 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
401 -
Workload Fluctuations
1
Related Content
- Capture Your Own Workload Statistics in the ABAP Environment in the Cloud in Technology Blogs by SAP
- explore the business continuity recovery sap solutions on AWS DRS in Technology Blogs by Members
- SAP Mobile Start leverages Google Chrome's latest Picture-in-Picture (PiP) Mode in Technology Blogs by SAP
- Understanding the Data Review steps in Onboarding and the impact on Employee Central in Technology Blogs by SAP
- Dynamic Derivations using BADI in SAP MDG in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 11 | |
| 10 | |
| 9 | |
| 9 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 5 |