(
English version)
はじめに
SAP HANA Cloudは企業内で"エンタープライズデータのゲートウェイ"として位置付けるべく、データを仮想的に統合することが可能です。具体的には、HANA Cloud上に作成した仮想テーブルを経由して、様々なデータソースを仮想的に統合することが可能です(データフェデレーション)。
ただ、実際に運用してみるとネットワーク速度やソースシステム側のパフォーマンス・負荷からやはりデータをSAP HANA Cloudで保持したい、というケースも発生するかと思います。
オンプレミスのSAP HANAではこのようなケースではSDIなどのETL機能を使用してデータを複製する必要がありますが、SAP HANA Cloudでは仮想テーブルのオプションとして設定するだけでデータを複製する、あるいはスナップショットデータを持つ、ということが可能です。(ETLジョブの作成が不要!)
本ブログでは、このSAP HANA Cloudの仮想テーブルの機能をテストしてみます。
- データ仮想化(フェデレーション)
- データ複製(リプリケーション)
- データスナップショット(キャッシュ)
*もちろんSDIを使用してSAP HANA Cloudにデータを複製(バッチ・リアルタイム連携ともに)することも可能です。
こちらや
こちらのブログをご参照ください。
以下の情報を参考にしています。
SAP HANA Cloudの概要資料にある以下の網掛け部分(Online switch federation / caching / replication)のご紹介です。

なお、前提としてData Provisioning Agentが設定されている必要があります。設定手順は
こちらのブログを参照ください。
1. データ仮想化(フェデレーション)
まずオンプレミスSAP HANAのテーブルを参照する仮想テーブルを作成します。
create virtual table "FVT_LINEITEM" at "OPHANA"."<NULL>"."TPCH"."LINEITEM_2";
仮想テーブルが作成されました。
件数を確認します。
SELECT文を発行します。仮想テーブルですのでデータはSAP HANA Cloudには持たず、オンプレミスのSAP HANAにデータを取得し、結果データのみをSAP HANA Cloudに返します。このため、少し時間がかかっています。(オンプレミスSAP HANAはAWS us-east、SAP HANA CloudはAWS Frankfurtにあります。)

2. データ複製
次に、先ほど作成した仮想テーブルにALTER TABLE文を実行し、データフェデレーションではなくデータを複製にしたいと思います。
alter virtual table "FVT_LINEITEM" add shared replica;
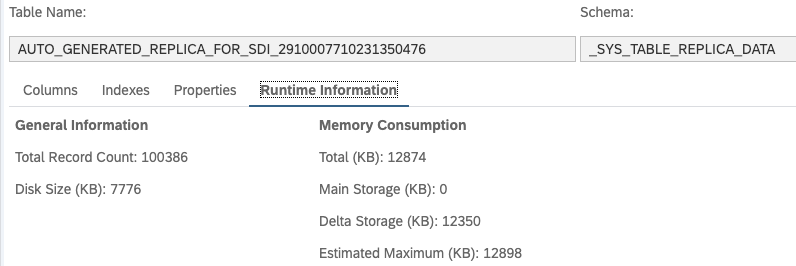
これにより、以下のように複製されたデータを保持するテーブルがスキーマ"_SYS_TABLE_REPLICA_DATA"に自動で生成されます。

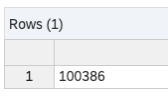
この自動生成されたテーブルの情報を確認すると、ソース側のデータと同じデータ件数であり、サイズからもデータを物理的に保持していることが確認できます。
仮想テーブルに対してデータ件数を確認すると、ALTER TABLEする前と同じデータ件数です。

先ほどと同じSELECT文を実行します。遥かにパフォーマンスが高速化されていることがわかります。

次に、ソース側でデータを更新してみます。今回は2件データを追加しました。

仮想テーブルに対してデータ件数を確認すると、2件データが増えていることが確認できます。

自動生成されたテーブルを確認するとこちらも2件増えていました。つまり、ソース側で更新されたデータがほぼリアルタイムにSAP HANA Cloudに複製されたことが確認できました。

最後に、この複製を削除します。
alter virtual table "FVT_LINEITEM" drop replica;
自動生成されたテーブルが削除されました。

3. スナップショット複製
次に、スナップショット複製を行います。仮想テーブルに対して以下のALTER TABLE文を発行します。
alter virtual table "FVT_LINEITEM" add shared snapshot replica;
こちらも同様に"_SYS_TABLE_REPLICA_DATA"スキーマにテーブルが自動生成されました。
テーブルの情報を確認すると、物理的にデータを保持していることが確認できます。

SELECT文を発行すると、先ほどの複製パターンと同様に高速に結果が返ってきます。

次に、ソースシステム側でデータを更新してみます。今回はデータを1件追加しました。

ソースのデータは更新されましたが、SAP HANA Cloudのスナップショットテーブルのデータは更新されません。

仮想テーブルに対してデータ件数を確認してもデータは更新されていません。

以下のコマンドでスナップショットの更新を行います。
alter virtual table "FVT_LINEITEM" refresh snapshot replica;
仮想テーブルを確認するとデータが更新されました。

自動生成されたスナップショットテーブルを確認すると、こちらもデータが更新されています。

最後に、スナップショットを削除します。
alter virtual table "FVT_LINEITEM" drop replica;
スナップショットが削除されました。
仮想テーブルに対してSELECT文を発行すると、以前のように数秒かかるようになりました。(オンプレミスのSAP HANAからデータを取得しています)

まとめ
以上、SAP HANA Cloudの新機能である仮想テーブルの複製機能の動作確認結果のご紹介でした。
仮想データ統合は業務ユーザーに対して迅速にデータを提供できる一方、パフォーマンスやシステム・ネットワーク負荷などの点で懸念もあります。
今回ご紹介した仮想テーブルの複製機能は仮想テーブルの設定をALTER TABLE文で変更するのみでリアルタイムのデータ複製やスナップショットデータの作成を行うことができます。つまりETLジョブの作成を行う必要はなく、またオンラインで設定を行うこともできるため、容易かつ迅速にパフォーマンスの最適化を図ることが可能となります。
この機能を活用することで、まずは仮想データ統合で業務ユーザーに対して迅速にデータを提供し、業務的に有益であると判断されかつより高速なレスポンスが求められた場合にこの設定を行って業務ユーザーに対してより高速なレスポンスを提供する、というアジャイル的データ活用が実現可能となります。
