SAP Data Intelligence provides multiple options when it comes to data management capabilities. In this blog post we will explain and compare the different features of ML Data Manager and Metadata Explorer apps.
What is SAP Data Intelligence ML Data Manager
ML Data Manager delivered as part of SAP Data Intelligence enables users to arrange datasets meant for Machine Learning (ML) into folder-based hierarchies of data workspaces and data collections. This ensures you get a framework within which you can guarantee the traceability and reproducibility of your ML pipelines. A workspace correlates to an ML or customer user-case you are working on. Within the workspace, ML Data Manager allows you to create multiple data collections. A data collection is a logical group of data that is consumed or produced by a notebook or a pipeline. As your experimentation moves along, you might morph your data into cleaner and well-structured datasets which you would then write to another data collection within the workspace. ML Data Manager allows you to specify the hierarchy of these data collections for easy identification of their relationships.
 What is SAP Data Intelligence Metadata Explorer?
What is SAP Data Intelligence Metadata Explorer?
Metadata Explorer helps users to govern and manage metadata assets that are spread across diverse systems and disparate sources. Metadata Explorer enables user to connect to data sources with the ability to automatically crawl their metadata structures, create references on data and store them in the Metadata Catalog. It has out of the box support for SAP HANA, SAP Vora, Object Stores (S3, GCS, etc.), HDFS, SAP BW, Oracle.
 Comparison between ML Data Manager and Metadata Explorer
Comparison between ML Data Manager and Metadata Explorer
- Separation of Concerns: Metadata Explorer is oriented towards discovery, movement and preparation of data from remote locations. In contrast, ML Data Manager is targeted for users having Machine Learning as their primary use case and who want to manage multiple dataset versions using a hierarchy-based approach. While ML Data Manager works on a copy of the data stored on data lake, Metadata Explorer works on the metadata only and references the data source.
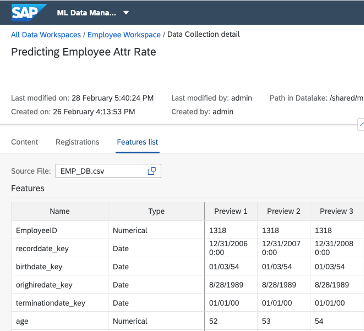 2. Dataset Operations:
2. Dataset Operations: Metadata Explorer provides you capabilities to profile and index data, as well as to create and maintain references to datasets in a catalog. ML Data Manager is providing specific ML functionalities like feature modelling and splitting of data into train, test and validation datasets.
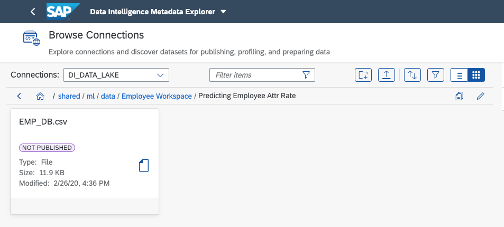 3. Dataset Consumption:
3. Dataset Consumption: Metadata Explorer allows to manage connections to SAP HANA, SAP Vora, Object Stores (S3, GCS, etc.), HDFS, SAP BW, Oracle, thus enabling to use the connections in a wider scope in their business applications. ML Data Manager has a limited usage scope compared to Metadata Explorer. Currently, data collections created in ML Data Manager can be consumed in an AutoML experiment or programmatically in a Jupyter Notebooks.
Conclusion
If your persona is more closely related to a Data Engineer and your use case involves managing metadata within distributed landscapes and to track the data lineage like how the data may have changed and which areas might be consuming the data then Metadata Explorer within SAP Data Intelligence would be prefect choice for you.
If you are a Data Scientist and your use case for using SAP Data Intelligence is Machine Learning based where you would be using datasets in an AutoML scenario or alternatively using it programmatically in a Jupyter Notebook then you should go with ML Data Manager.
To get a better understanding regarding implementation of ML Data Manager, you can have a look at
ML Data Manager in action video or the blog post
Accessing Data Lake in Jupyter notebooks using Data Manager.
