
- SAP Community
- Products and Technology
- Enterprise Resource Planning
- ERP Blogs by SAP
- Custom CDS Views - Using Multiple Data Sources
Enterprise Resource Planning Blogs by SAP
Get insights and updates about cloud ERP and RISE with SAP, SAP S/4HANA and SAP S/4HANA Cloud, and more enterprise management capabilities with SAP blog posts.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-06-2020
6:19 PM
Bringing data from different data sources together is one of the key features of the Custom CDS Views app. No matter if you just add a field by expanding a given path or if you manually add a data source via the Data Sources tab, you are using this feature. Adding fields is quick & easy, but there are some aspects you should consider. This blog post will explain what you need to know in order to build solid custom CDS views that use multiple data sources.
Although the Custom CDS Views app does not require programming skills, it still produces code: A (custom) CDS view is similar to an SQL view. And when you use multiple data sources, bringing them together requires a definition that describes how the data sources are connected. In CDS terms this is called an association condition. For the techie readers, an association works much like a left outer join in SQL terms. Don't worry, I will not go much deeper here, but the point is that the "code" that connects the data sources has an impact on the result set and may also impact the performance of your view. This is why you should consider some basic rules when dealing with multiple data sources.
You might have seen that there is a so-called cardinality available when you deal with existing associations. The cardinality indicates the potential effect on the result set, when you add fields from the association to your data source. Attention: Bad example ahead! Don't do it this way 🙂
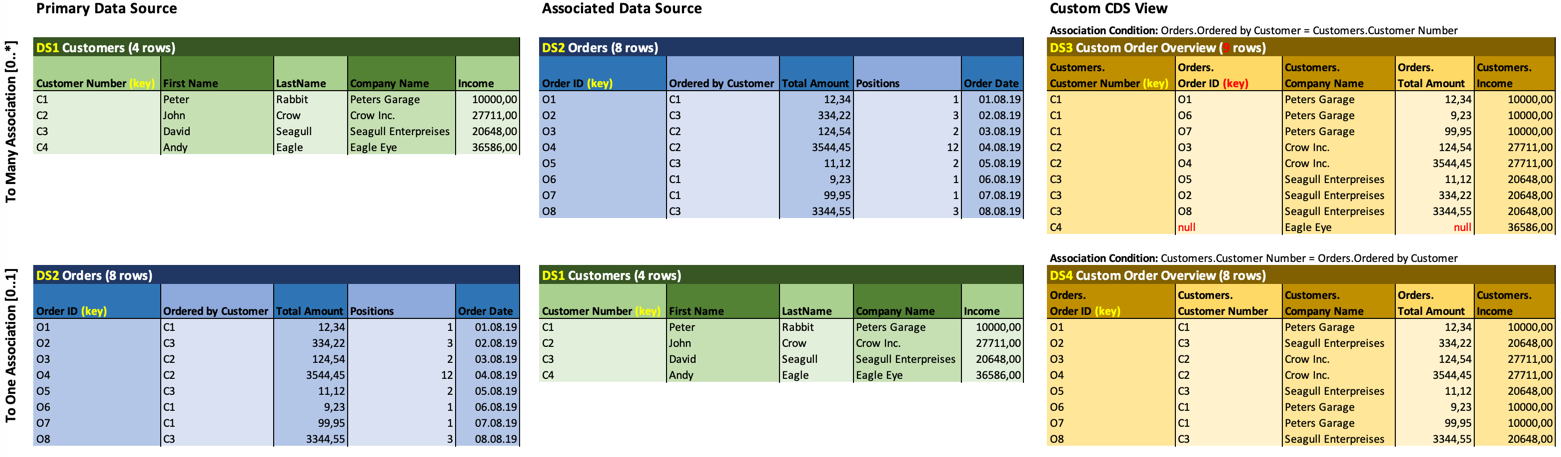
Let's assume your primary data source is about customers. When you preview it, you will see a list of all your customers. If you have 4 customers, you will see 4 lines in the preview. Now you add some fields from the association to the orders: The order number as well as the order date and maybe the amount. As your customers hopefully ordered more than once, your result set will now be let's say 9 lines in the preview. And of course you will see more than one line for some of your customers. Customers that did not order yet will still appear with one line. The association you used is called a "to many" association and is marked as "[0..*]" in your custom CDS view.
It does not make a difference if the association was there in your primary data source or if you added the association manually and choose the fields afterwards. The effect happens when you add fields from the data source!
Now let's have a look at some of the effects in the next chapters.
Associations require that the association condition (see above) is calculated by the database whenever a view is called. The calculation is often more complex to calculate when the association is a "to many" association. Therefore, keep in mind, that such associations can be bad for the performance of your custom CDS view during runtime.
The key uniquely identifies a line or row in your result set. It can consist of one or more fields. If there are multiple rows in your result set that have the same key, something went wrong and you might have unexpected results in the runtime. It might even happen that different runtimes deliver different results. So you should pay attention when setting the "key" property.
Whenever you add a field from a "to many" association you will most likely need to modify the key(s) of your custom CDS view. In the example below (DS3), I had to make sure that the Order Id is set as additional key, because I used fields from my associated "to many" data source Orders (DS2).
So far, we looked at using existing data sources. Now let's have a look at how to manually add a data source to your custom CDS view.
The first thing you need to do after you added the data source is to define the association condition for it. This is done by mapping the fields of both data sources. In our (bad) example with the customers, I used the field that relates to the customer in the sales order (ordered by customer) and the identifier of the customer (customer id).
If you use the customer as primary data source and associated the orders with the association condition orders.orderedBy = customers.customerId, as I did in DS3, you will have a "to many" association.
If you instead used the orders as primary data source and associated the customers with the association condition customers.customerId = orders.orderedBy as in DS4, you will have a "to one" association. To make sure you have a real "to one" association, you need to map all key fields of your target (associated) data source.
As a picture is worth a thousandwords, I have painted the example in two flavors: Once with a "to many", and the once with a "to one" association.
Note, that I used the Orders (DS2) as associated data source in the "to many" example, whereas I switched primary and associated data source in the "to one" example. This is a possible strategy to avoid "to many" associations.
Note that changing the cardinality setting has no effect on the result set at all! The effective cardinality always only results from the field mapping in the association definition:
So why does SAP then at all provide this setting? There are rare cases were you can ensure that you do have a "to one" association even if you did not use all of the key fields in the on condition, e.g. if you used a filter on that field. If you have such a situation, you can use the cardinality setting to document this. If you are not sure, it does not harm to follow the key fields rule above.
One more for the techies: Associations that are marked with a "[0..*]" cardinality are always executed by the database when the view is called. Other "[0..1]" associations are only executed when a field from that association is requested by the client. One more reason to prefer "to one" associations where possible.
Almost all views that SAP delivers, do have an access protection. When you build a custom CDS view, your view is always protected with the access protection of your primary data source. If you now manually add an association to another view and use fields from that view, the access protection of the associated view will not be considered in the resulting access protection of your custom CDS view unless it has already been foreseen by SAP in the access protection of your primary data source. This is most likely the case if you manually add views and it is the reason why you get a warning when you do this. To learn about the access protection of your primary data source, you should have a look at the documentation of the view on help.sap.com.
Using fields from "to many" associations can be dangerous. It can have negative effects on the performance of your view and can sometimes have unwanted effects on the size of your result set. There might be cases when you want to build your view that way, but you should be aware of the effects this can have. Generally, you should try to avoid using fields from "to many" associations.
Note that there are quite some use-cases where you have to use a "to many" association as such in your view, e.g. when you build a cube with dimensions or when you define a value help for a field but these cases do not require using fields from the associations.
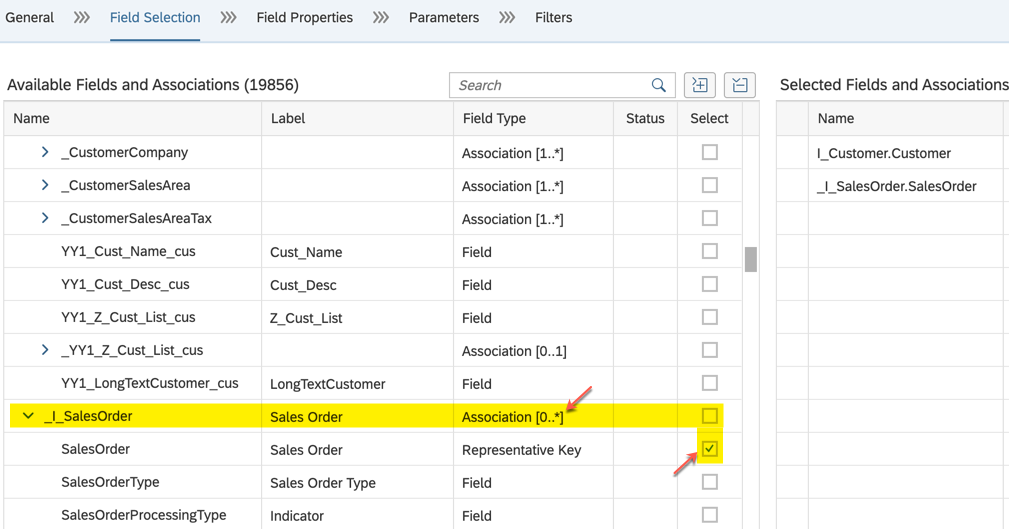
Pay attention when selecting fields. Always check if the field you want to add is already part of your primary data source. If this is the case, consider using it. Whenever you need to expand a tree structure to find a field, understand that this means you are following an association. The deeper you go, the more associations you follow, the more complex it gets, even when all associations are of the type "to one". It gets worse when the associations are "to many".
One option to avoid "to many" associations is to start with a primary data source that has the "finer granularity" and then associate the "smaller" data source. In our example: Start with the sales orders and associate the customers view to it.
Keys are key. There is a warning when you potentially have a wrong key definition, but you can still save and publish. So you should take such warnings serious.
The Technical Perspective
Although the Custom CDS Views app does not require programming skills, it still produces code: A (custom) CDS view is similar to an SQL view. And when you use multiple data sources, bringing them together requires a definition that describes how the data sources are connected. In CDS terms this is called an association condition. For the techie readers, an association works much like a left outer join in SQL terms. Don't worry, I will not go much deeper here, but the point is that the "code" that connects the data sources has an impact on the result set and may also impact the performance of your view. This is why you should consider some basic rules when dealing with multiple data sources.
Understanding the Result Set
You might have seen that there is a so-called cardinality available when you deal with existing associations. The cardinality indicates the potential effect on the result set, when you add fields from the association to your data source. Attention: Bad example ahead! Don't do it this way 🙂
Let's assume your primary data source is about customers. When you preview it, you will see a list of all your customers. If you have 4 customers, you will see 4 lines in the preview. Now you add some fields from the association to the orders: The order number as well as the order date and maybe the amount. As your customers hopefully ordered more than once, your result set will now be let's say 9 lines in the preview. And of course you will see more than one line for some of your customers. Customers that did not order yet will still appear with one line. The association you used is called a "to many" association and is marked as "[0..*]" in your custom CDS view.
It does not make a difference if the association was there in your primary data source or if you added the association manually and choose the fields afterwards. The effect happens when you add fields from the data source!
Now let's have a look at some of the effects in the next chapters.
Possible Effects on the Performance
Associations require that the association condition (see above) is calculated by the database whenever a view is called. The calculation is often more complex to calculate when the association is a "to many" association. Therefore, keep in mind, that such associations can be bad for the performance of your custom CDS view during runtime.
Getting the Keys Right
The key uniquely identifies a line or row in your result set. It can consist of one or more fields. If there are multiple rows in your result set that have the same key, something went wrong and you might have unexpected results in the runtime. It might even happen that different runtimes deliver different results. So you should pay attention when setting the "key" property.
Whenever you add a field from a "to many" association you will most likely need to modify the key(s) of your custom CDS view. In the example below (DS3), I had to make sure that the Order Id is set as additional key, because I used fields from my associated "to many" data source Orders (DS2).
Adding Data Sources
So far, we looked at using existing data sources. Now let's have a look at how to manually add a data source to your custom CDS view.
Defining the Association Condition
The first thing you need to do after you added the data source is to define the association condition for it. This is done by mapping the fields of both data sources. In our (bad) example with the customers, I used the field that relates to the customer in the sales order (ordered by customer) and the identifier of the customer (customer id).
If you use the customer as primary data source and associated the orders with the association condition orders.orderedBy = customers.customerId, as I did in DS3, you will have a "to many" association.
If you instead used the orders as primary data source and associated the customers with the association condition customers.customerId = orders.orderedBy as in DS4, you will have a "to one" association. To make sure you have a real "to one" association, you need to map all key fields of your target (associated) data source.
As a picture is worth a thousandwords, I have painted the example in two flavors: Once with a "to many", and the once with a "to one" association.
Note, that I used the Orders (DS2) as associated data source in the "to many" example, whereas I switched primary and associated data source in the "to one" example. This is a possible strategy to avoid "to many" associations.
Setting the Cardinality
Note that changing the cardinality setting has no effect on the result set at all! The effective cardinality always only results from the field mapping in the association definition:
- Mapped all key fields of the target? Then you have a "to one" association and should
therefore leave the cardinality setting with "[0..1]" - You did not map (all) keys of the target? Now you defined a "to many" association
and should set the cardinality dropdown to "[0..*]"
So why does SAP then at all provide this setting? There are rare cases were you can ensure that you do have a "to one" association even if you did not use all of the key fields in the on condition, e.g. if you used a filter on that field. If you have such a situation, you can use the cardinality setting to document this. If you are not sure, it does not harm to follow the key fields rule above.
One more for the techies: Associations that are marked with a "[0..*]" cardinality are always executed by the database when the view is called. Other "[0..1]" associations are only executed when a field from that association is requested by the client. One more reason to prefer "to one" associations where possible.
Some words on the Access Protection
Almost all views that SAP delivers, do have an access protection. When you build a custom CDS view, your view is always protected with the access protection of your primary data source. If you now manually add an association to another view and use fields from that view, the access protection of the associated view will not be considered in the resulting access protection of your custom CDS view unless it has already been foreseen by SAP in the access protection of your primary data source. This is most likely the case if you manually add views and it is the reason why you get a warning when you do this. To learn about the access protection of your primary data source, you should have a look at the documentation of the view on help.sap.com.
Summary & Key Takeaways
Using fields from "to many" associations can be dangerous. It can have negative effects on the performance of your view and can sometimes have unwanted effects on the size of your result set. There might be cases when you want to build your view that way, but you should be aware of the effects this can have. Generally, you should try to avoid using fields from "to many" associations.
Note that there are quite some use-cases where you have to use a "to many" association as such in your view, e.g. when you build a cube with dimensions or when you define a value help for a field but these cases do not require using fields from the associations.
Pay attention when selecting fields. Always check if the field you want to add is already part of your primary data source. If this is the case, consider using it. Whenever you need to expand a tree structure to find a field, understand that this means you are following an association. The deeper you go, the more associations you follow, the more complex it gets, even when all associations are of the type "to one". It gets worse when the associations are "to many".
One option to avoid "to many" associations is to start with a primary data source that has the "finer granularity" and then associate the "smaller" data source. In our example: Start with the sales orders and associate the customers view to it.
Keys are key. There is a warning when you potentially have a wrong key definition, but you can still save and publish. So you should take such warnings serious.
- SAP Managed Tags:
- SAP S/4HANA Public Cloud
Labels:
19 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
Artificial Intelligence (AI)
1 -
Business Trends
363 -
Business Trends
23 -
Customer COE Basics and Fundamentals
1 -
Digital Transformation with Cloud ERP (DT)
1 -
Event Information
461 -
Event Information
24 -
Expert Insights
114 -
Expert Insights
158 -
General
1 -
Governance and Organization
1 -
Introduction
1 -
Life at SAP
415 -
Life at SAP
2 -
Product Updates
4,684 -
Product Updates
219 -
Roadmap and Strategy
1 -
Technology Updates
1,502 -
Technology Updates
89
Related Content
- SAP Fiori for SAP S/4HANA - Composite Roles in launchpad content and layout tools in Enterprise Resource Planning Blogs by SAP
- Building Low Code Extensions with Key User Extensibility in SAP S/4HANA and SAP Build in Enterprise Resource Planning Blogs by SAP
- Business Rule Framework Plus(BRF+) in Enterprise Resource Planning Blogs by Members
- Futuristic Aerospace or Defense BTP Data Mesh Layer using Collibra, Next Labs ABAC/DAM, IAG and GRC in Enterprise Resource Planning Blogs by Members
- SAP ERP Functionality for EDI Processing: UoMs Determination for Inbound Orders in Enterprise Resource Planning Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 11 | |
| 10 | |
| 7 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 4 | |
| 4 |