
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- NSE(Native Storage Extension) Data Tiering Options
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member66
Discoverer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-20-2020
8:32 AM
NSE Whitepaper
What is NSE ?
HANA SPS 04 version has introduced the NSE. NSE is used to store the warm data. HANA was used to store the hot data in memory but as data growth occurred in some of the organization the need for another store came into picture and SAP came out with a solution to introduce the another store called as warm store which in turn called as NSE.
Please refer the below block diagram by SAP :

Customers implementing the SAP NSE solution:
Customers who are planning to think about implementing the NSE should closely monitor the data growth. They need to compare the total memory size vs the used size.

In our system we found the database growth of 61.91% per year so we moved towards implementing the NSE.
In-Memory/Hybrid/On-Disk - NSE has the feature to store the data in disk-based column store and Hana has the feature to store the data in in-Memory column store.So it has a hybrid column store approach.
NSE integration is based on the Hana Persistence layer in close connection to Page Access and Resource Manager.
Buffer Cache ( BC ) is required for performance access to pages on disk.The buffer cache should avoid redundant I/O operations by keeping pages which are access frequently in memory rather than reading them from the disk repeatedly.The Buffer Cache uses LRU (Last Recently Used) and HBL (Hot Buffer List) strategies and reuses the pages from the internal pools instead of allocating/deallocating pages via HANA memory management.

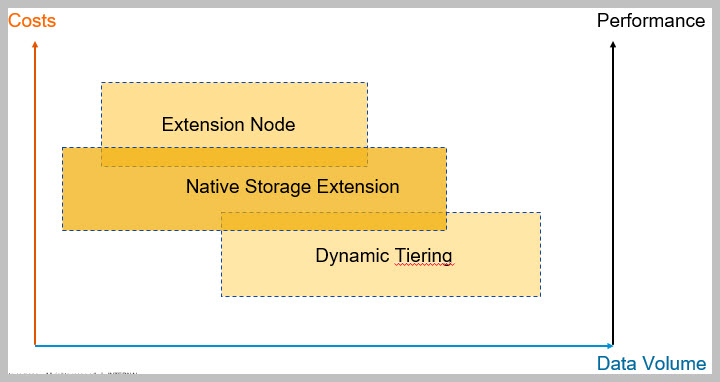
Hana Data Tiering Options are as follows:
- Persistent Memory
- Native Storage Extension , Extension Node, Dynamic Tiering
- Spark Controller

NSE Value Proposition and Use Case:
Specifying data as “page loadable”

NSE Technical Overview:

Tooling:
HANA Cockpit:
Data Lifecycle Manager (DLM):
Web IDE:
On-premise sizing

SAP HANA Extension Node – Whats New in SPS04
Common characteristics:
New Features:
–range-hash partitioning scheme
–“pinning” tables on fixed HANA nodes
–partition grouping
Warm Store Options – Getting Started
Cold Store:

Which Data Tier Should I Use ?

I tried to explain the best way of handling the NSE and also show case how to Select the NSE for each customers.In my next article I will try to articulate all the technical changes required for the NSE and also introduce the data aging concepts which is key to NSE.
Summary:
SAP HANA offers with NSE another warm data tiering option which is completely integrated and can be seamlessly used out of the box since SP40.
While adapting existing column store persistence building blocks to handle the new advanced page attribute behavior compared to the already existing PA every other component in Hana is able to work as designed.
As NSE will serve under warm data high query performance KPIs will logically not be reached. Since loading data from Disk to Memory will take its time.
Data will be held in the so-called Buffer Cache with an initial value of 10 % of the HANA memory and NSE Advisor will help to find objects which should be converted to page loadable.
What is NSE ?
HANA SPS 04 version has introduced the NSE. NSE is used to store the warm data. HANA was used to store the hot data in memory but as data growth occurred in some of the organization the need for another store came into picture and SAP came out with a solution to introduce the another store called as warm store which in turn called as NSE.
Please refer the below block diagram by SAP :
Customers implementing the SAP NSE solution:
Customers who are planning to think about implementing the NSE should closely monitor the data growth. They need to compare the total memory size vs the used size.
In our system we found the database growth of 61.91% per year so we moved towards implementing the NSE.
In-Memory/Hybrid/On-Disk - NSE has the feature to store the data in disk-based column store and Hana has the feature to store the data in in-Memory column store.So it has a hybrid column store approach.
NSE integration is based on the Hana Persistence layer in close connection to Page Access and Resource Manager.
Buffer Cache ( BC ) is required for performance access to pages on disk.The buffer cache should avoid redundant I/O operations by keeping pages which are access frequently in memory rather than reading them from the disk repeatedly.The Buffer Cache uses LRU (Last Recently Used) and HBL (Hot Buffer List) strategies and reuses the pages from the internal pools instead of allocating/deallocating pages via HANA memory management.
NSE Advisor:
With the help of the NSE Advisor the objects (tables, partitions or columns) that a
re suitable to be converted to page loadable (to save the memory space) or to column loadable (to improve the performance) can be identified within the recommendations result view.
NSE Functional Restriction:2
Consider the following when storing large data sets in NSE on servers with limited memory capacity
- • HANA as an in-memory database executes queries with allocating transient data and interim results in memory. Queries do not page interim results or parts of interim results from memory to disk.
• HANA keeps NSE data in memory in a buffer cache. Low hit rates in the buffer cache can cause insufficient query performance due to high number of disk reads.
• SAP provides general guidelines about the buffer cache sizing in the SAP HANA Administration Guide for SAP HANA Platform. Deviations from the guidelines require application based sizing or proof of concepts with workload simulations.
• Users can store warm data in NSE instead of on Dynamic Tiering. In contrast to Dynamic Tiering, the query execution in the HANA service, storing the NSE data, creates transient data and interim result in memory only. Thus, the memory requirement for a comparable workload can be higher with NSE. A solution to migrate data from Dynamic Tiering to NSE in on the road map for SAP HANA.
• SAP HANA NSE is for scale-up systems. For scale-out systems, SAP HANA does not check if users create tables with page-loadable columns or convert tables to page-loadable.
• SAP HANA NSE supports partition load units for heterogeneous partitions but does not support partition load unit for non-heterogeneous partitions.
• Specifying partition-level load unit is supported for the following partitioning schemes:
-Unbalanced range
-Unbalanced range-range
For all other partitioning schemes used in SAP NSE tables, load units can be specified only on column, table, and index.
NSE Advisor Usage:
1. Identify representative workload of your system
2. Optionally configure the NSE Advisor
3. Enable the NSE Advisor
4. Run the representative workload
a. Monitor the performance of statements
b. Monitor the memory usage
c. Monitor the duration of processes
5. Disable the NSE Advisor
6. Evaluate and save the recommendations of the NSE Advisor
7. Migrate the objects selected from the recommendations
8. Run the representative workload
a. Monitor performance of statements
b. Monitor the memory usage
c. Monitor the duration of processes
9. Iterate your tests, e.g. restart from step 2, until you have a proven set-up, which fits your requirements.
Configure NSE Advisor :
ALTER SYSTEM ALTER CONFIGURATION ( 'indexserver.ini' , 'SYSTEM' ) SET ( 'cs_nse_advisor', 'min_object_size' ) = 'XXX' WITH RECONFIGURE ; --
default value 1048576 = 1 MiB
Enable NSE Advisor:
ALTER SYSTEM ALTER CONFIGURATION ( 'indexserver.ini' , 'system' ) SET ( 'cs_access_statistics','collection_enabled' ) = 'true' WITH RECONFIGURE;
Disable NSE Advisor:
ALTER SYSTEM ALTER CONFIGURATION ( 'indexserver.ini' , 'system' ) SET ( 'cs_access_statistics','collection_enabled' ) = 'false' WITH RECONFIGURE;
Evaluate and save the NSE advisor run.
Hana Data Tiering Options are as follows:
- Hot Store
- Persistent Memory
- Warm Store
- Native Storage Extension , Extension Node, Dynamic Tiering
- Cold Store
- Spark Controller
NSE Value Proposition and Use Case:
- Value proposition:
- Increase HANA data capacity at low TCO
- Deeply integrated warm data tier, with full HANA functionality
- Will support all HANA data types and data models
- Simple system landscape
- Scalable with good performance
- Supported for both HANA on-premise and HANA-as-a-Service (HaaS)
- Available for any HANA application
- Complements, without replacing, other warm data tiering solutions (extension nodes, dynamic tiering)
- Use cases:
- Any customer built or SAP built HANA application that is challenged by growing data volumes
- S/4HANA data aging (NSE is an evolution of “paged attributes”)
- BW team currently uses extension nodes, but they communicated in TECH ED 2019 that NSE is certified for BW/4HANA
Specifying data as “page loadable”
- Data may be specified as “page loadable” at table level, partition level, and column level
- Data may be converted between “page loadable” and “column loadable”
- NSE supports range, range-range, and hash partitioned tables
- For hash partitioning the entire table or column must be page loadable or column loadable
NSE Technical Overview:
- The HANA column store and row store each have a buffer cache.
- Column loadable data is fully loaded into memory from disk.
- Page loadable data is loaded from disk into the buffer cache, page by page as needed.
- Converting column/row loadable data to page loadable format moves the data into the buffer cache.
- When buffer cache is full, it will eject pages intelligently based on user access patterns.
- Warm and hot data are written together from main store to disk during normal save point operations. The write-optimized store is not paged
Tooling:
HANA Cockpit:
- Configure buffer cache size (on-premise only; HaaS will configure this for the user)
- Configure tables, columns, and partitions as “page loadable”
- Monitor buffer cache usage and capacity
- Report on resident memory status for page loadable data
- Includes rule-based “recommendation engine” to monitor user data access patterns.
- Based on statistics, the engine will advise user on which tables, columns, or partitions would benefit from being converted to “page loadable”
Data Lifecycle Manager (DLM):
- DLM tool will allow user to convert tables, columns, and table partitions between “column loadable” and “page loadable”
Web IDE:
- Visualized query plan will display when warm data is accessed from NSE in order to satisfy the query
On-premise sizing
- HANA system must be scale up (first release)
- Determine volume of warm data to add to the HANA database
- May add as much warm storage as desired - up to 1:4 ratio of HANA hot data in memory to warm data on disk
- NSE disk store should be no larger than 10TB for first release of NSE
- Divide volume of warm data by 8 – this is size of memory buffer cache required to manage warm data on disk
- Either add more HANA memory for buffer cache, or use some of existing HANA memory for buffer cache (will reduce hot data volume)
- Work area should be same size as hot data in memory (equivalent to HANA with no NSE)
SAP HANA Extension Node – Whats New in SPS04
Common characteristics:
- HANA node in the scale-out landscape is reserved for warm-data storage and processing
- Supports all HANA operations and data management features
- Allows larger data footprint of up to 200% of the node DRAM size
- HANA persistent memory is supported
New Features:
- Benefits from new partitioning and scale-out features in SPS04:
–range-hash partitioning scheme
–“pinning” tables on fixed HANA nodes
–partition grouping
Warm Store Options – Getting Started
Cold Store:
Which Data Tier Should I Use ?
I tried to explain the best way of handling the NSE and also show case how to Select the NSE for each customers.In my next article I will try to articulate all the technical changes required for the NSE and also introduce the data aging concepts which is key to NSE.
Summary:
SAP HANA offers with NSE another warm data tiering option which is completely integrated and can be seamlessly used out of the box since SP40.
While adapting existing column store persistence building blocks to handle the new advanced page attribute behavior compared to the already existing PA every other component in Hana is able to work as designed.
As NSE will serve under warm data high query performance KPIs will logically not be reached. Since loading data from Disk to Memory will take its time.
Data will be held in the so-called Buffer Cache with an initial value of 10 % of the HANA memory and NSE Advisor will help to find objects which should be converted to page loadable.
- SAP Managed Tags:
- Sports and Entertainment,
- SAP HANA,
- SAP HANA Live
17 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
"TypeScript" "Development" "FeedBack"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
2 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
absl
2 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
AEM
1 -
AI
7 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
3 -
API Call
2 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
5 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
2 -
aws
2 -
Azure
1 -
Azure AI Studio
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
bitcoin
1 -
Blockchain
3 -
bodl
1 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
12 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Application Studio
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
1 -
Business Data Fabric
3 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
4 -
CA
1 -
calculation view
1 -
CAP
3 -
Capgemini
1 -
CAPM
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
4 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Consolidation Extension for SAP Analytics Cloud
2 -
Control Indicators.
1 -
Controller-Service-Repository pattern
1 -
Conversion
1 -
Cosine similarity
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
cyber security
3 -
cybersecurity
1 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Flow
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
database tables
1 -
Datasphere
3 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
digital transformation
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
2 -
Exploits
1 -
Fiori
14 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
Flask
1 -
Full Stack
8 -
Funds Management
1 -
General
1 -
General Splitter
1 -
Generative AI
1 -
Getting Started
1 -
GitHub
8 -
Grants Management
1 -
GraphQL
1 -
groovy
1 -
GTP
1 -
HANA
6 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
2 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
HTML5 Application
1 -
Identity cards validation
1 -
idm
1 -
Implementation
1 -
input parameter
1 -
instant payments
1 -
Integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
iot
1 -
Java
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
8 -
Kerberos for JAVA
8 -
KNN
1 -
Launch Wizard
1 -
Learning Content
2 -
Life at SAP
5 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
Loading Indicator
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
2 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MTA
1 -
Multi-Record Scenarios
1 -
Multiple Event Triggers
1 -
Myself Transformation
1 -
Neo
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
2 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Process Automation
2 -
Product Updates
4 -
PSM
1 -
Public Cloud
1 -
Python
4 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
research
1 -
Resilience
1 -
REST
1 -
REST API
2 -
Retagging Required
1 -
Risk
1 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
3 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
8 -
SAP AI Launchpad
8 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
4 -
SAP Analytics Cloud for Consolidation
3 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BTP
21 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
6 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
2 -
SAP CDC
1 -
SAP CDP
1 -
SAP CDS VIEW
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Migration in Retail Industry
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
9 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
3 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
9 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP LAGGING AND SLOW
1 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Odata
2 -
SAP on Azure
1 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP successfactors
3 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP Utilities
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapmentors
1 -
saponaws
2 -
SAPS4HANA
1 -
SAPUI5
5 -
schedule
1 -
Script Operator
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
Self Transformation
1 -
Self-Transformation
1 -
SEN
1 -
SEN Manager
1 -
service
1 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
Slow loading
1 -
soap
1 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
Substring function
1 -
SuccessFactors
1 -
SuccessFactors Platform
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
14 -
Technology Updates
1 -
Technology_Updates
1 -
terraform
1 -
Threats
2 -
Time Collectors
1 -
Time Off
2 -
Time Sheet
1 -
Time Sheet SAP SuccessFactors Time Tracking
1 -
Tips and tricks
2 -
toggle button
1 -
Tools
1 -
Trainings & Certifications
1 -
Transformation Flow
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
2 -
ui designer
1 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Validations
1 -
Vector Database
2 -
Vector Engine
1 -
Visual Studio Code
1 -
VSCode
1 -
Vulnerabilities
1 -
Web SDK
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- Accelerate Business Process Development with SAP Build Process Automation Pre-Built Content in Technology Blogs by SAP
- ABAP Cloud Developer Trial 2022 Available Now in Technology Blogs by SAP
- When to Use Multi-Off in 3SL in Technology Blogs by SAP
- Kyma Integration with SAP Cloud Logging. Part 2: Let's ship some traces in Technology Blogs by SAP
- AutoGen with SAP AI Core in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 5 | |
| 4 | |
| 4 | |
| 4 | |
| 3 | |
| 3 |