
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Concurrency patterns for Hyperledger Fabric Go cha...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member23
Participant
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-10-2020
5:45 AM
In this blog post, I conducted an experiment, which shows that Go concurrency patterns and parallel execution can be used for Hyperledger chaincode in order to speed up heavy computational operations.
Due to the fact that Hyperledger has a complex architecture, please do not use the code patterns below to play with the ledger state. It might lead to data inconsistencies. Test your code exhaustively before any intentions to migrate it into productive systems.
As you know, Go is a young language, which was purposely designed to support parallel execution of subprograms called 'goroutines' and concurrency patterns natively.
Goroutines are the lightweight threads completely managed by Go runtime. You can easily start those by using the ‘go’ keyword and they will be executed separately from the main flow of the program (perhaps on a different core of your processor), which can possibly give you a higher performance. However, this advantage in speed also brings you additional responsibility in managing those separate threads. Depending on your algorithm, you would need to build communication between your goroutines and main program as well as manage lifecycle of your goroutines.
I hope my intro hasn’t scared you. Let’s see what we can do and have a look at a simple practical example.
Imagine your Hyperledger smart contract needs to perform a heavy computational task and return a response to a requestor in a synchronous way. It could be generation of a cryptographic hash/signature/checksum or perhaps a promo coupon code. Imagine also that this calculation is broken down into several stages so that results of one operation are passed into the next one. Something similar to a Unix pipeline of commands below:
Our task in this article is much simpler as we have a chain of two functions which should be executed in sequence:
If we try to calculate the hashes in a sequence,

then our code wrapped into an invokable Hyperledger method will be looking like below:
A simple unit test run against it will show execution time of about 8 seconds (depending on hardware):

Let's try to implement a quite simple idea - let's run the repeating tasks in their separate subroutines executed simultaneously. We’ll add another API invokable method named ‘runCalcParallel’, which is quite similar to the previous ‘runCalcSeq’ method, but instead it runs a scheduler function distributing calculations among separate goroutines as per picture below:

The 'getSingleHashParallel' function looks like below:
As you see above, we started to use the Go channels for communication between the different functions/subroutines. We create a new channel named 'out' and then passing it into the scheduler function. On the last string we just return a value given to us by the channel.
The 'startSingleHashWorkers' scheduler function executes the left and right parts of the required expression in parallel mode as per below code:
There's a quite important detail though. We used a WaitGroup sync object in order to wait for both goroutines to finish at the 'wg.Wait()' statement. Each WaitGroup instance has an internal counter, which is increased by the 'wg.Add()' method and decreased by the 'wg.Done()' method. So after we created the 'wg' instance above, we increased its internal counter by 2 knowing we'd have to synchronise two simultaneous goroutines afterwards. We use the 'defer' keyword, which guarantees to execute the 'wg.Done()' and decrease the internal counter by one once the goroutine finishes. The 'wg.Wait()' will let the next instruction to be executed only when both the goroutines finish their work. It's implemented the same way inside of the 'startMultiHashWorkers', so that the picture above can be enhanced by the presence of work groups in both schedulers:

Let's try to see if performance has improved.
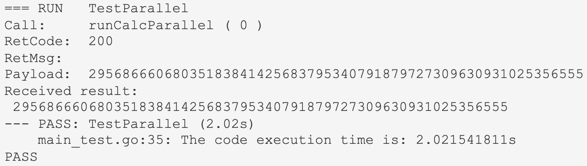
We received the same result of the calculation 4 times faster because of parallelisation.
Once we are satisfied with overall performance of each step of our execution chain, let's try to unify the interface of each step and make some kind of a scheduler to run the sequence like a conveyor of jobs:
The jobs themselves can be stored as an array of functions with a single generic interface 'in, out chan interface{}' declared as type 'job' like below:
Now we can define infinite number of jobs to be run in a sequence. How would a scheduler look like? Let's have a look into the 'runPipeline' function:
The idea here is quite simple: we connect each step's in and out by reusing the channels (out of the 2nd channel is the in for the 3rd channel) and execute the step:

A very important feature here is that the values are passed seamlessly without any interruptions from one step to another.
This is only a simple example not even covering the basics and only opening the door to the endless world of concurrent patterns. If you got interested, I'd recommend you to follow up the materials below:
YouTube - Google I/O 2012 - Go Concurrency Patterns
https://blog.golang.org/race-detector
https://blog.golang.org/pipelines
https://blog.golang.org/advanced-go-concurrency-patterns
http://marcio.io/2015/07/handling-1-million-requests-per-minute-with-golang/
https://go101.org/article/channel.html
Thank you.
Due to the fact that Hyperledger has a complex architecture, please do not use the code patterns below to play with the ledger state. It might lead to data inconsistencies. Test your code exhaustively before any intentions to migrate it into productive systems.
As you know, Go is a young language, which was purposely designed to support parallel execution of subprograms called 'goroutines' and concurrency patterns natively.
Goroutines are the lightweight threads completely managed by Go runtime. You can easily start those by using the ‘go’ keyword and they will be executed separately from the main flow of the program (perhaps on a different core of your processor), which can possibly give you a higher performance. However, this advantage in speed also brings you additional responsibility in managing those separate threads. Depending on your algorithm, you would need to build communication between your goroutines and main program as well as manage lifecycle of your goroutines.
I hope my intro hasn’t scared you. Let’s see what we can do and have a look at a simple practical example.
The task
Imagine your Hyperledger smart contract needs to perform a heavy computational task and return a response to a requestor in a synchronous way. It could be generation of a cryptographic hash/signature/checksum or perhaps a promo coupon code. Imagine also that this calculation is broken down into several stages so that results of one operation are passed into the next one. Something similar to a Unix pipeline of commands below:
grep 127.0.0.1 | awk '{print $2}' | sort | uniq -c | sort -nrOur task in this article is much simpler as we have a chain of two functions which should be executed in sequence:
- 'getSingleHash', which takes data as input and calculates output as crc32(data)+"~"+crc32(md5(data)), where + means concatenation of strings:
// gets a crc32(data) + "~" + crc32(md5(data)) value
func getSingleHash(data string) string {
var result string
crc32Hash1 := getCrc32(data)
md5Hash := getMd5(data)
crc32Hash2 := getCrc32(md5Hash)
result = crc32Hash1 + "~" + crc32Hash2
return result
}
- 'getMultiHash', which returns output as crc32(i+data)), where i is an iteration number ranging from 0 to 6:
// gets a crc32(i + data) where i = 0..5
func getMultiHash(data string) string {
var result string
for i := 0; i < 6; i++ {
sI := strconv.Itoa(i)
result += getCrc32(sI + data)
}
return result
}
Step 1. Sequential mode
If we try to calculate the hashes in a sequence,
then our code wrapped into an invokable Hyperledger method will be looking like below:
func runCalcSeq(stub shim.ChaincodeStubInterface, args []string) peer.Response {
var resAsBytes []byte
var hash1, hash2 string
for _, val := range args {
hash1 = getSingleHash(val)
hash2 = getMultiHash(hash1)
}
resAsBytes = []byte(hash2)
return shim.Success(resAsBytes)
}
A simple unit test run against it will show execution time of about 8 seconds (depending on hardware):
go test -vStep 2. Using parallel execution
Let's try to implement a quite simple idea - let's run the repeating tasks in their separate subroutines executed simultaneously. We’ll add another API invokable method named ‘runCalcParallel’, which is quite similar to the previous ‘runCalcSeq’ method, but instead it runs a scheduler function distributing calculations among separate goroutines as per picture below:
The 'getSingleHashParallel' function looks like below:
// gets a crc32(data) + "~" + crc32(md5(data)) value in parallel mode
func getSingleHashParallel(in string) string {
out := make(chan string)
go func(data string) {
startSingleHashWorkers(data, out)
}(in)
return <-out
}As you see above, we started to use the Go channels for communication between the different functions/subroutines. We create a new channel named 'out' and then passing it into the scheduler function. On the last string we just return a value given to us by the channel.
The 'startSingleHashWorkers' scheduler function executes the left and right parts of the required expression in parallel mode as per below code:
func startSingleHashWorkers(data string, out chan<- string) {
wg := &sync.WaitGroup{}
wg.Add(2)
var left, right string
go func() {
defer wg.Done()
left = getCrc32(data)
}()
go func() {
defer wg.Done()
hash := getMd5(data)
right = getCrc32(hash)
}()
wg.Wait()
result := left + "~" + right
out <- result
}There's a quite important detail though. We used a WaitGroup sync object in order to wait for both goroutines to finish at the 'wg.Wait()' statement. Each WaitGroup instance has an internal counter, which is increased by the 'wg.Add()' method and decreased by the 'wg.Done()' method. So after we created the 'wg' instance above, we increased its internal counter by 2 knowing we'd have to synchronise two simultaneous goroutines afterwards. We use the 'defer' keyword, which guarantees to execute the 'wg.Done()' and decrease the internal counter by one once the goroutine finishes. The 'wg.Wait()' will let the next instruction to be executed only when both the goroutines finish their work. It's implemented the same way inside of the 'startMultiHashWorkers', so that the picture above can be enhanced by the presence of work groups in both schedulers:
Let's try to see if performance has improved.
go test -vWe received the same result of the calculation 4 times faster because of parallelisation.
Step 3. Run the steps as a conveyor
Once we are satisfied with overall performance of each step of our execution chain, let's try to unify the interface of each step and make some kind of a scheduler to run the sequence like a conveyor of jobs:
The jobs themselves can be stored as an array of functions with a single generic interface 'in, out chan interface{}' declared as type 'job' like below:
type job func(in, out chan interface{})
func runCalcParallel(stub shim.ChaincodeStubInterface, args []string) peer.Response {
var resAsBytes []byte
var result string
hashJobs := []job{
job(func(in, out chan interface{}) {
for _, seqNum := range args {
out <- seqNum
}
}),
job(getSingleHashParallel),
job(getMultiHashParallel),
job(func(in, out chan interface{}) {
for input := range in {
data, ok := input.(string)
if !ok {
shim.Error("Can't convert result data to string")
}
fmt.Println("Appending a new hash " + data)
result += data
}
}),
}
runPipeline(hashJobs...)
resAsBytes = []byte(result)
return shim.Success(resAsBytes)
}Now we can define infinite number of jobs to be run in a sequence. How would a scheduler look like? Let's have a look into the 'runPipeline' function:
func runPipeline(funcs ...job) {
var prevChan, currChan chan interface{}
wg := &sync.WaitGroup{}
wg.Add(len(funcs))
for idx, fItem := range funcs {
if idx == 0 {
prevChan = nil
currChan = make(chan interface{})
} else if idx == len(funcs)-1 {
prevChan = currChan
currChan = nil
} else {
prevChan = currChan
currChan = make(chan interface{})
}
go func(f job, in, out chan interface{}) {
defer func(ch chan interface{}) {
wg.Done()
if ch != nil {
close(ch)
}
}(out)
f(in, out)
}(fItem, prevChan, currChan)
}
wg.Wait()
}The idea here is quite simple: we connect each step's in and out by reusing the channels (out of the 2nd channel is the in for the 3rd channel) and execute the step:
A very important feature here is that the values are passed seamlessly without any interruptions from one step to another.
Conclusion
This is only a simple example not even covering the basics and only opening the door to the endless world of concurrent patterns. If you got interested, I'd recommend you to follow up the materials below:
YouTube - Google I/O 2012 - Go Concurrency Patterns
https://blog.golang.org/race-detector
https://blog.golang.org/pipelines
https://blog.golang.org/advanced-go-concurrency-patterns
http://marcio.io/2015/07/handling-1-million-requests-per-minute-with-golang/
https://go101.org/article/channel.html
Thank you.
- SAP Managed Tags:
- Blockchain,
- SAP Business Technology Platform
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
273 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
324 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
402 -
Workload Fluctuations
1
Related Content
- Building a Hyperledger Fabric consortium based on Azure Kubernetes Service (AKS) template in Technology Blogs by SAP
- How to index couch db in hyperledger fabric in Technology Q&A
- Hyperledger Fabric error - Failed to find a ledger for channel in Technology Q&A
- Swagger returns Error 401 - Unathorized in Technology Q&A
- CA configuration and Client user management in Hyperledger Fabric Service in SAP Cloud Platform in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 12 | |
| 9 | |
| 7 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 4 |