
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- HANA Partitioning – 2 billion rows limitation – Pa...
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
jgleichmann
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-09-2020
12:52 AM
last updated: 2022-11-04
It took me nearly two years to write the second part of this partition series. The first one for BW partitioning can be found here.
The main question of this blog: How to determine the best partitioning combination?
In an ERP or S/4 HANA system it is possible that a table is approaching the 2 billion mark. This is a HANA design limit for a column store table (per partition). In this case you have to partition the table. But different than on a BW system there are no standard rules for a partitioning. This means you have to choose a partitioning rule by your own. But how to determine the best partitioning combination?
- Alerts
- Find tables with high amount of records
- Term clarification
- Designing Partitions
- Example BSEG
- Example BSIS
- Example for a Z-Table <tbd>
- Parameter for parallel splitting
- Partitioning process
- Tips
- Partition / Re-partitioning references
- Summary
1. Alerts
At first check if partitioning is needed at all which means check the tables with the most row entries. There is a limit per table/partition of 2 billion rows by the design of HANA.
If your alerting is working correct you will receive an alert (ID 27). It looks like this:
“Record count of column-store table partitions ( ID 27 )
Determines the number of records in the partitions of column-store tables. A table partition cannot contain more than 2,147,483,648 (2 billion) rows.”
- Interval 1 hour
- High: 1,900,000,000
- Medium: 1,800,000,000
- Low: 1,500,000,000
The limitations are described in SAP note 2154870.

Other once:
"Alert ID 20 - Table growth of non-partitioned column-store tables"
"Alert ID 17 - Record count of non-partitioned column-store tables"
2. Find tables with high amount of records
Check all tables by high amount of records. Therefore, you can use the SQL from 1969700 (HANA_Tables_TopGrowingTables_Records_History).
Rule of thumb for the initial partitioning:
- min. 100 mio entries per partition for initial partitioning
- max 500 mio entries per partition for initial partitioning
- if you choose too many partitions you can achieve a bad performance, because one thread per partition have to be triggered (e.g. you have 20 threads as statement concurrency limit and 40 partition have to be scanned which results in waiting for resources)
- if you choose too less partitions, it can be that you have to repartition pretty timely which means another maintenance window / downtime
- recommendation: HASH partitioning on a selective column, typically part of primary key
- making sure that a single partition doesn't exceed a size of 20 to 50 GB due to delta merge performance (SAP Note 2100010)
In our example we determined BSEG and BSIS as tables with high amount of rows. For timely planning of maintenance you should act when the table exceeds 1,5 billion entries.
For our scenario BSEG has 4,5 billion and BSIS has 4,1 billion rows. So, they are already partitioned. But is this partitioning over the time since the initial creation still optimal?
Growth over 30 days:

3. Term clarification
To determine the optimal partitioning combination, we have to clarify some terms:
- Cardinality
- Selectivity
- HASH Partitioning
- Range Partitioning
- Multi-level partitioning
Cardinality
In the context of databases, cardinality refers to the uniqueness of data values contained in a column. High cardinality means that the column contains a large percentage of totally unique values. Low cardinality means that the column contains a lot of “repeats” in its data range. In a customer table, a low cardinality column would be the “Gender” column. This column will likely only have “M” and “F” as the range of values to choose from, and all the thousands or millions of records in the table can only pick one of these two values for this column. Ok, to be accurate nowadays we have to add a third value for diverse “D”.
Source: https://www.techopedia.com/definition/18/cardinality-databases
| Note: Partitioning works better when the cardinality of the partitioning field is not too high |
Selectivity
The selectivity basically is a measure of how much variety there is in the values of a given table column in relation to the total number of rows in a given table. The cardinality is just part of the formula that is used to calculate the selectivity.
| Selectivity = cardinality/(number of rows) * 100 |
Hash Partitioning
Hash partitioning is used to distribute rows to partitions equally for load balancing. The number of the assigned partition is computed by applying a hash function to the value of a specified column. Hash partitioning does not require an in-depth knowledge of the actual content of the table.

Source: openHPI: In-Memory_Data_Management_2017
Range Partitioning
Range partitioning creates dedicated partitions for certain values or value ranges in a table. For example, a range partitioning scheme can be chosen to create a partition for each calendar month. Partitioning requires an in-depth knowledge of the values that are used or are valid for the chosen partitioning column.
Partitions may be created or dropped as needed and applications may choose to use range partitioning to manage data at a fine level of detail, for example, an application may create a partition for an upcoming month so that new data is inserte

Source: openHPI: In-Memory_Data_Management_2017
Advantage: possible dynamic range to use this generic model for 'no maintenance' partitioning. For this feature, which is only supported for range partitioning, partitions will be automatically created if a threshold is reached:

With SPS06 it is also possible to do this for defined time intervals.
ALTER TABLE T ALTER PARTITION OTHERS DYNAMIC INTERVAL 1 YEAR;
ALTER TABLE T ALTER PARTITION OTHERS DYNAMIC INTERVAL 3 MONTH;Multi-Level partitioning
In some scenarios it makes sense to use colums which are not part of the primary key. But with single level partitioning you can only select primary key columns. Multi-level partitioning makes it possible to select on first level a key column and on second level any other column. It is also possible to mix different partitioning methods.
The following combinations are possible [firstlevel-secondlevel]:
- hash-hash
- range-range
- hash-range
- round-robin-range
4. Designing Partitions
Actually the online repartitioning is based on table replication. Tables with the naming convention _SYS_OMR_<source_table>#<id> are used as interim tables during online repartitioning operations. For details please read the “Designing Partitions” section in the documentation.
As summary:
- Use partitioning columns that are often used in WHERE clauses for partition pruning
- If you don’t know which partition scheme to use, start with hash partitioning
- Use as many columns in the hash partitioning as required for good load balancing, but try to use only those columns that are typically used in requests
- Queries do not necessarily become faster when smaller partitions are searched. Often queries make use of indexes and the table or partition size is not significant. If the search criterion is not selective though, partition size does matter.
- Using time-based partitioning often involves the use of hash-range partitioning with range on a date column
- If you split an index (SAP names the CS tables also as index), always use a multiple of the source parts (for example 2 to 4 partitions). This way the split will be executed in parallel mode and also does not require parts to be moved to a single server first.
- Do not split/merge a table unless necessary.
- Ideally tables have a time criterion in the primary key. This can then be used for time-based partitioning.
- Single level partitioning limitation: the limitation of only being able to use key columns as partitioning columns (homogeneous partitioning)
- the client (MANDT/MANDANT) as single attribute for partitioning is not recommended - only useful in multi level partitioning scenarios
5. Example BSEG
We determined that BSEG has 4,5 billion rows. Now we need details on which column the table has to be partitioned.
The recommendation of SAP is to use a HASH partitioning on BELNR in note 2044468.
Note 2289491 describes a range partitioning on BUKRS. As you can see it always depends on how your system is being used. Ok, let’s find it out in a test environment.
Now we know:
- table has to be partitioned (4,5 billion rows)
- most scanned columns
- recommendation for partitioning by SAP
Questions to success:
|
2044468 - FAQ: SAP HANA Partitioning
2418299 - SAP HANA: Partitioning Best Practices / Examples for SAP Tables
2289491 - Best Practices for Partitioning of Finance Tables
To quote the HPI course on the partitioning details (In-Memory_Data_Management_2017):
“There are number of different optimization goals to be considered while choosing a suitable partitioning strategy. For instance, when optimizing for performance, it makes sense to have tuples of different tables, that are likely to be joined for further processing, on one server. This way the join can be done much faster due to optimal data locality, because there is no delay for transferring the data across the network. In contrast, for statistical queries like counts, tuples from one table should be distributed across as many nodes as possible in order to benefit from parallel processing."
To sum up, the best partitioning strategy depends very much on the specific use case.
The main challenge for hash-based partitioning is to choose a good hash function, that implicitly achieves locality or access improvements.
Primary key BSEG:
MANDT
BUKRS
BELNR
GJAHR
BUZEIThe following columns have a particularly high amount of scanned records (SQL: “HANA_Tables_ColumnStore_Columns_Statistics”, MIN_SCANNED_RECORDS_PER_S = 5000000😞

- To achieve this just fill in your table inside the modification section
There are recommendations for the most famous SAP standard tables within note 2044468. If you are close to the standard and don’t use a lot of custom code try this partitioning recommendations first. If you have heavy load with own statement which uses a totally different execution plan you may have to determine your own partitioning columns. Be aware of the partitioning limits!
If you want to check the optimal partitioning combinations use this statement:
select statement_hash, statement_string,
execution_count, total_execution_time from m_sql_plan_cache
where statement_string like '%BSEG%'
order by total_execution_time desc;
From the result you have to analyze the “where” clause and find a common pattern.
Take as few fields as needed. Normally fields like MATNR, BELNR or DOCNR are selective fields and well suited for partitioning.
For a deep dive you can additionally run the DataCollector with the selected statement_hash (HANA_SQL_StatementHash_DataCollector) within the statement collection (1969700).
Additionally, you can use the ColumnStore statistics (HANA_Tables_ColumnStore_Columns_Statistics_2.00.030+ ) which is also part of the SQL collection to analyze how many scans are on which column. If you are using multiple clients, it may be wise to add the field MANDT as partitioning criteria.
HANA_Data_ColumnValueCounter_CommandGenerator
SELECT TOP 100
'BSEG' TABLE_NAME,
S.*
FROM
( SELECT
BUKRS,
LPAD(COUNT(*), 11) OCCURRENCES,
LPAD(TO_DECIMAL(COUNT(*) / SUM(COUNT(*)) OVER () * 100, 10, 2), 7) PERCENT
FROM
( SELECT
BUKRS
FROM
"SAPSCHEMA"."BSEG
)
GROUP BY
BUKRS
ORDER BY
OCCURRENCES DESC
) S


Only 2 values for BUKRS “0010” and “0020”. This means we have a too low cardinality and partitioning won’t work well on this attribute. So, this means both extreme too high and low are bad.
Most scanned columns are PCTR, HKONT and BELNR.
We have about 30 clients in this test system which means it makes sense to use it in the partitioning clause on the first level as entry point.
- MANDT first level hash partitioning
- BELNR second level hash partitioning
With 4,5 billion rows we need about 12-15 partitions which means 300 million rows per partition (rule of thumb: between 100 - 500 million), if we would use only single level partitioning. With multi-level partitioning the fill degree of the partitioning depends on the single column data cardinality of each level.
Note At the end it is just a indication for the given analyzed timeframe and no guarantee for the future. This is a process you should repeat if the application and selections are changing. This can be due user behaviour or new SAP packages or custom code. |
6. Example: BSIS
Primary Key
MANDT
BUKRS
HKONT
AUGDT
AUGBL
ZUONR
GJAHR
BELNR
BUZEIColumn Stats

often executed statements on BSIS

cardinality


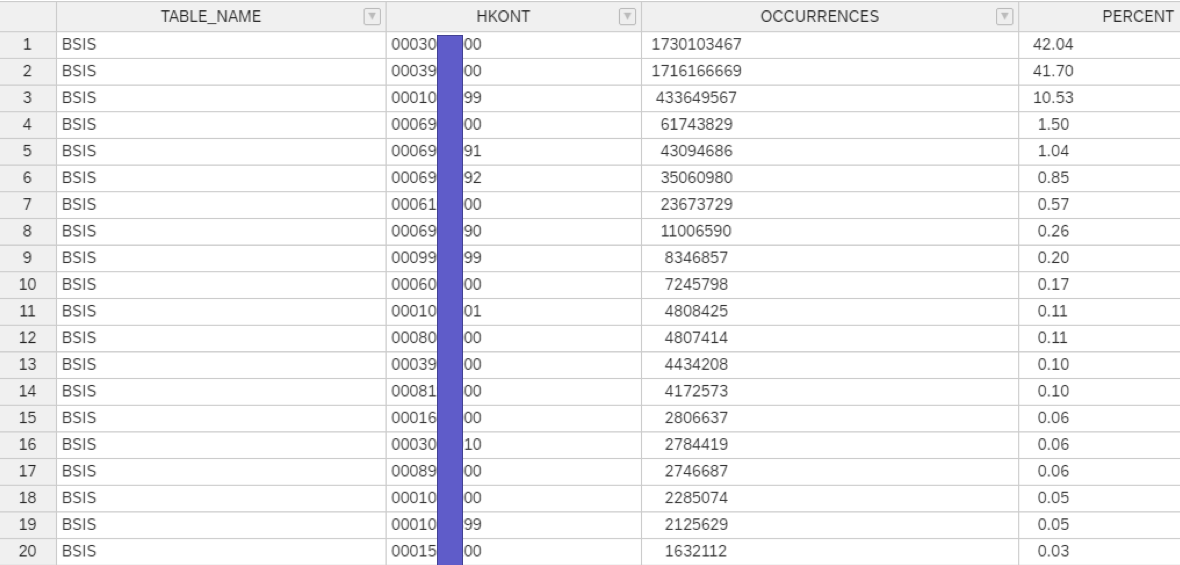

Facts:
- 4,1 billion rows
- About 30 client values
- Only one value for BUKRS
- The top occurrences in BELNR have summed up not 0,001%
The recommendation of SAP is a RANGE partitioning on BUKRS. If RANGE on BUKRS or a similar range partitioning is not possible, use HASH partitions on BELNR.
We can't use BUKRS as partitioning object due too low cardinality. BELNR alone has a high cardinality and could be not efficient enough.
2 recommendation is in this scenario:
- MANDT first level range partitioning
- HKONT second level range partitioning
- MANDT first level hash partitioning
- BELNR second level hash partitioning
With 4,1 billion rows we need about 12-14 partitions which means 300 million rows per partition (rule of thumb: between 100 - 500 million), if we would use only single partitioning. With multilevel partitioning the fill degree of the partitioning depends on the single column data cardinality of each level.
7. Another example for Z-table
<tbd>
8. Parameter for splitting
As already mentioned in the first part of this series, we can optimize the splitting procedure with some parameters which have to be adjusted according your hardware:
indexserver.ini -> [partitioning] -> split_threads (default: 16) [range: 1-128]
indexserver.ini -> [partitioning] -> bulk_load_threads (default: 4) [range: 1-20]
- Under a system with 176 CPU cores, the repartitioning was failed due to this error and completed in 9.18H with settings below.
indexserver.ini -> [partitioning] -> split_threads =50
indexserver.ini -> [partitioning] -> bulk_load_threads = 8
- With 120 CPU cores, it took 14.40H without the error after setting as below.
indexserver.ini -> [partitioning] -> split_threads =95
indexserver.ini -> [partitioning] -> bulk_load_threads = 10Source:
Note 2890332
HANA 2.0 SPS04 Rev. >= 43
indexserver.ini -> [mergedog] -> auto_merge_decision_func = '((DRC*TMD > 3600*(MRC+0.0001)) or ((DMS>PAL/2000 or DMS > 1000 or DCC>100) and (DRC > MRC/100 or INSTR(BASENAME, "_SYS_OMR_") > 0)) or (DMR>0.2*MRC and DMR > 0.001) or (DRC=0 and DMR=0 and MPU=1))'
indexserver.ini -> [table_replication] -> optimize_replica_for_online_ddl_in_log_replay = 'true'
indexserver.ini -> [table_replication] -> optimize_replica_for_online_ddl = 'true'
indexserver.ini -> [persistence] -> logreplay_savepoint_interval_s = '600'Source:
Note 2874176
9. Partitioning process
You can monitor the partitioning process via M_JOB_PROGRESS monitoring view.
master process has in total 7 steps: Mapping, GetDataRanges, PreProcess, RepartitionMain, RepartitionDeltaAndMVCC, PostProcess, DropSources
Each worker group consists of 13 steps: CreateTargets, DeterminepartsMain, DeterminepartsDelta, InitPersistenceMain, InitPersistenceDelta, CheckConsistencyMain, CheckConsistencyDelta, RepartitionMainLocal, RepartitionDeltaLocal, RepartitionMVCCMain, RepartitionMVCCDelta, UpdateRuntime, Finalize
Each thread worker has 3 steps: SplitMergeAttributes, Save, Idle
Example: Table : 80 columns Indexes: PK + 2 secondary indexes => 83 attributes to split (+internal once) CPU threads : 64vCPUs |
If you have configured 60 split threads. One group will be started and use 60 threads. When one column is finished the next one is started. The bulk load threads won't be considered.
Grouping (repartitioning)
If you already have a partition design in place, but it is not fitting any more to your needs, you have to take attention for the repartitioning process to the grouping.
Example same as before only with the fact that is already partitioned with HASH 32.
old design: HASH 32
new design: HASH 4
32 can be divided by 4. This means 4 groups will be started. But if you stay with split threads 60 you will overload the system! So, go with 60/4 = 15. The system will start 4 groups with each 15 threads.
Note
old design / new design or new design = old design / 2 |
bulk_load_threads = old design / new design split_threads = log. CPU / bulk_load_threads |
10. Tips
Duration of a partitioning process
Export the table from production in binary format and import it in a separated system/schema to validate the duration of the partitioning process. Before you begin you should load and merge the table. This will speed up the procedure.
If you want to partition online you should consider the locking phase / delta merge phase. If those phases running long in your test system you should verify the impact with capture&replay or just do it offline (without application workload) or in times with less workload on the system. There are also some known issues regarding merges/partitioning locks. Please check your revision!
Dependency of the runtime
The runtime of the partitioning process depends on different factors:
- number of fields/columns of the table (each column will be processed by one thread)
- data type / length of the field
- delta size
- size of the column
- cardinality of the column
- composition of the PKEY
- concat attributes
- number of threads for partitioning (available CPU cores)
- LOAD attribute PAGE (NSE)
Repartitioning process:
- be sure that your new design is a factor 2 multiple or divider of the current number of partitions
- 4 => 8
- 6 => 3
- 32 => 4
- adjust the parameters in order to the partition grouping
Because only in this case the repartitioning can happen in parallel on different partition groups and hosts (“parallel split / merge”).
You can speed up the procedure with some tuning of parameters or deleting indexes. This should always be tested carefully.
| Attention When you drop unique indexes you can't partition your table online! This would end in duplicate entries!!! |
11. Partition / Re-partitioning references
3234063 - How to partition/re-partition a table
3111531 - SAP HANA - How to convert an existing hash partitioned table to range.
ALTER TABLE Statement (Data Definition)
12. Summary
There is no silver bullet for every customer. It depends always on the usage and the change of values in a table. Additionally the changes of the applications and the different selections. Try different partitioning columns in your test system and check the performance. You should also optimize the compression of those big tables from time to time. The optimize compression will take place automatically as part of a delta merge process, but decided from the system itself. On huge tables it can be that this happens pretty late which results in a bad performance.The partitioning can also have some positive impacts beside come across the record limitation. For instance better delta merge and record change performance.
So, stay tuned and give your system reguarly health checks. SAP provides such services called TPO, but also some well known HANA experts provide such services 😉
18 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
"TypeScript" "Development" "FeedBack"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
2 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
absl
2 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
AEM
1 -
AI
7 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
3 -
API Call
2 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
5 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
2 -
aws
2 -
Azure
1 -
Azure AI Studio
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
bitcoin
1 -
Blockchain
3 -
bodl
1 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
12 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Application Studio
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
1 -
Business Data Fabric
3 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
4 -
CA
1 -
calculation view
1 -
CAP
3 -
Capgemini
1 -
CAPM
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
4 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Consolidation Extension for SAP Analytics Cloud
2 -
Control Indicators.
1 -
Controller-Service-Repository pattern
1 -
Conversion
1 -
Cosine similarity
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
cyber security
3 -
cybersecurity
1 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Flow
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
database tables
1 -
Datasphere
3 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
digital transformation
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
2 -
Exploits
1 -
Fiori
14 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
Flask
1 -
Full Stack
8 -
Funds Management
1 -
General
1 -
General Splitter
1 -
Generative AI
1 -
Getting Started
1 -
GitHub
8 -
Grants Management
1 -
GraphQL
1 -
groovy
1 -
GTP
1 -
HANA
6 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
2 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
HTML5 Application
1 -
Identity cards validation
1 -
idm
1 -
Implementation
1 -
input parameter
1 -
instant payments
1 -
Integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
iot
1 -
Java
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
8 -
Kerberos for JAVA
8 -
KNN
1 -
Launch Wizard
1 -
Learning Content
2 -
Life at SAP
5 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
Loading Indicator
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
2 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MTA
1 -
Multi-Record Scenarios
1 -
Multiple Event Triggers
1 -
Myself Transformation
1 -
Neo
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
2 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Process Automation
2 -
Product Updates
4 -
PSM
1 -
Public Cloud
1 -
Python
4 -
python library - Document information extraction service
1 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
research
1 -
Resilience
1 -
REST
1 -
REST API
2 -
Retagging Required
1 -
Risk
1 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
3 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
8 -
SAP AI Launchpad
8 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
4 -
SAP Analytics Cloud for Consolidation
3 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BTP
21 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
6 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
2 -
SAP CDC
1 -
SAP CDP
1 -
SAP CDS VIEW
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Migration in Retail Industry
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
9 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
3 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
9 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP LAGGING AND SLOW
1 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Master Data
1 -
SAP Odata
2 -
SAP on Azure
1 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP successfactors
3 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP Utilities
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapmentors
1 -
saponaws
2 -
SAPS4HANA
1 -
SAPUI5
5 -
schedule
1 -
Script Operator
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
Self Transformation
1 -
Self-Transformation
1 -
SEN
1 -
SEN Manager
1 -
service
1 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
Slow loading
1 -
soap
1 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
Substring function
1 -
SuccessFactors
1 -
SuccessFactors Platform
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
14 -
Technology Updates
1 -
Technology_Updates
1 -
terraform
1 -
Threats
2 -
Time Collectors
1 -
Time Off
2 -
Time Sheet
1 -
Time Sheet SAP SuccessFactors Time Tracking
1 -
Tips and tricks
2 -
toggle button
1 -
Tools
1 -
Trainings & Certifications
1 -
Transformation Flow
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
2 -
ui designer
1 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Validations
1 -
Vector Database
2 -
Vector Engine
1 -
Visual Studio Code
1 -
VSCode
1 -
Vulnerabilities
1 -
Web SDK
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- SWPSTEPLOG table partitioning in Technology Q&A
- Efficient Memory Storage and Data Loading of SAP HANA Column Tables in Technology Blogs by Members
- Recap — SAP Data Unleashed 2024 in Technology Blogs by Members
- Table Partitioning for two tables in HANA in Technology Q&A
- Replicating table data from an SAP ECC system with SAP Datasphere using Replication Flows in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 8 | |
| 5 | |
| 5 | |
| 4 | |
| 4 | |
| 4 | |
| 4 | |
| 4 | |
| 3 | |
| 3 |