
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Spatial Data Science powered by SAP HANA
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-08-2020
10:22 PM

Learn how to handle spatial data in SAP HANA. This blog covers data loading, preparation, basic analytics as well as the training of a machine learning model for predicting travel times.
In the field of Data Science, spatial data gets more and more relevant. Thus, (Geo-)Spatial Data Science or Advanced (Geo-)Spatial Analytics is expected to be one of the trending topics in 2020. Due to its seamless integration of multi-model data with embedded machine learning, SAP HANA is the platform of choice for this evolving discipline.
To enable Data Scientists in their daily work, SAP HANA has been offering Python integration for quite a while. The SAP HANA Python Client API for Machine Learning Algorithms even enables the in-database ML algorithms to be called from Python. With this integration a Data Scientist can build a machine learning model purely in Python, while at the same time the algorithms are applied in the database without actual data transfer to the client.
In this blog, I would like to show some basic geospatial analytics as well as the integration with SAP HANA Embedded Machine Learning. I will take on the perspective of a Data Scientist and use a Jupyter Notebook for modelling.
Despite the fact, that "Spatial is more than maps" it is always a good idea to visualize the results of a spatial analysis. There are a variety of libraries offering geospatial visualizations in Jupyter Notebooks, with Folium being one of the most famous ones. Still, after playing with a few of those libraries, I decided to use kepler.gl for this blog. kepler.gl is an open source application for geospatial analytic visualizations, which is available for Jupyter Notebooks. It is especially suitable for large amounts of data and has a rather low-touch experience when it comes to coding (which was my primary reason to pick kepler.gl).

The full Jupyter Notebook including the reproducible analysis can be downloaded from GitHub. It is designed to run on a vanilla SAP HANA Express instance. If you feel confident with the Jupyter Notebook itself, you can also jump right into it and skip the rest of the blog:
https://github.com/mkemeter/public/blob/master/TaxiTrajectories.ipynb
Update 2021-09-28: Please find an updated version of the notebook, that reflects the latest API changes in OSMnx.
If you are not into Python or prefer a more verbose description, I will show you the most important steps and ideas below.
The Data Set
When looking for a suitable dataset for a geospatial analysis, I stumbled upon this nice dataset on Kaggle:
https://www.kaggle.com/crailtap/taxi-trajectory
The dataset contains taxi trajectories in the city of Porto in the format of linestrings. The fact, that it does not simply contain point data made it especially interesting. The data itself can be downloaded as a CSV file, which we will import to SAP HANA via our Jupyter Notebook.
To understand the context of the data better, we will also incorporate point-of-interest (POI) data from OpenStreetMap since we anticipate that pick-up locations of taxis correlate with a high density of POIs.

Setup and Configuration
To start with our geospatial analysis in Jupyter, we need to setup and import the required libraries. These are the major packages that we will use:
- Pandas and GeoPandas for managing data within Python. Whilst most people are familiar with Pandas, GeoPandas is only known to developers dealing with spatial data. It can be understood as Pandas enhanced with geospatial capabilities.
- SQLAlchemy for database communication. There is a SAP HANA dialect available for SQLAlchemy. Please follow these instructions to do the initial setup.
- OSMnx is a comfortable library for downloading OpenStreetMap data. We will use this library to load POI data to SAP HANA as described in this blog.
- kepler.gl for visualizing geospatial data. KeplerGL is an open source application for geospatial analytic visualizations, which has been embedded into Jupyter Notebooks. To visualize the geometries from a DataFrame is essentially a one-liner as you will see later.
- hana_ml for calling in-database machine learning algorithms. Here you will have to be careful to choose the correct version for your APL installation. Andreas Forster's blog (in particular the APL4 addendum) helped setup the correct version for my HANA Express instance.
The full list of imports:
# dealing with datasets in Python
import pandas as pd
import geopandas as gpd
# db connectivity
import sqlalchemy
# load osm data
import osmnx as ox
# visualization of spatial data
from keplergl import KeplerGl
from shapely import wkt
# embedded ML and visualization of model charts
from hana_ml import dataframe
from hana_ml.algorithms.apl import regression
from matplotlib import pyplotWorth mentioning, that there is some inline SQL cell magic based on SQLAlchemy for Jupyter Notebooks, which I made use of. The cell magic enables writing SQL statements more or less directly into a cell without Python overhead.
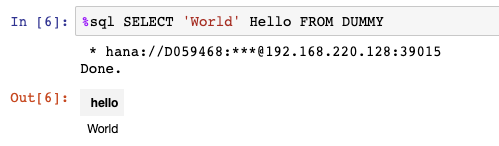
For more details please refer to this blog:
https://towardsdatascience.com/jupyter-magics-with-sql-921370099589
Persist and Enhance Trajectory Data
We would like to load our CSV file into Python and persist it in SAP HANA for further processing. Using Pandas the import of the CSV into a DataFrame is just one line of code:
df_csv = pd.read_csv('train.csv')Once the data has been loaded into a DataFrame, we need to get some datatypes straight (e.g. converting the timestamp into a proper DateTime field) and filter out line items, that do not contain trajectory data. There are a certain number of taxi rides with no or only one GPS coordinate.
Persisting the data in SAP HANA is a two-fold process:
- First, we are going to persist the plane data without the geospatial datatype.
hdb_connection = sqlalchemy.create_engine(connection_string).connect()
df_csv.to_sql(name = 'taxi', con = hdb_connection, if_exists = 'replace', chunksize = 500)
- Second, we are going to generate the geospatial column from its text representation in the database.
ALTER TABLE TAXI ADD (SHAPE ST_GEOMETRY($srid))
UPDATE TAXI SET SHAPE = ST_GEOMFROMTEXT(POLYLINE, 4326).ST_TRANSFORM($srid)
ALTER TABLE TAXI DROP (POLYLINE)
The initial dataset simply provides a trajectory column with a certain number of points. From the data description we know that there is a GPS coordinate each 15 seconds. A trip containing 10 GPS coordinates would have lasted 150 seconds.
We can derive this feature and other spatial and non-spatial properties from our dataset. Following statements will add start point, end point, duration, start time, end time, distance and average speed of the trip.
ALTER TABLE TAXI ADD (STARTPOINT ST_GEOMETRY($srid), ENDPOINT ST_GEOMETRY($srid))
UPDATE TAXI SET STARTPOINT = SHAPE.ST_STARTPOINT(), ENDPOINT = SHAPE.ST_ENDPOINT()
ALTER TABLE TAXI ADD (DURATION INTEGER)
UPDATE TAXI SET DURATION = (SHAPE.ST_NUMPOINTS() - 1) * 15
ALTER TABLE TAXI ADD (STARTTIME TIMESTAMP, ENDTIME TIMESTAMP)
UPDATE TAXI SET STARTTIME = TIMESTAMP, ENDTIME = ADD_SECONDS(TIMESTAMP, DURATION)
ALTER TABLE TAXI ADD (DISTANCE INTEGER)
UPDATE TAXI SET DISTANCE = TO_INTEGER(SHAPE.ST_LENGTH())
ALTER TABLE TAXI ADD (SPEED_AVG INTEGER)
UPDATE TAXI SET SPEED_AVG = TO_INTEGER(DISTANCE/DURATION * 3.6)The HANA Spatial function we used above are the following:
We can use the enhanced properties to check our data for inconsistencies. For example, we will find a certain number of trips with a very(!) high average speed. With the presumption of innocence, we will treat this as a "data quality issue".
DELETE FROM TAXI WHERE
SHAPE.ST_ISEMPTY() = 1 OR
SHAPE.ST_ISVALID() = 0 OR
DISTANCE < 200 OR
SPEED_AVG > 150 OR
MISSING_DATA > 0We suppose that we now have a rather clean dataset waiting for our analysis!
Choosing the Right Spatial Reference System
You may have noticed above that I transformed the data into another Spatial Reference System (SRS). In my code I used the variable '$srid', which I preconfigured with a planar SRS. The reason for switching to a planar projection is the increased computing performance in comparison to round-earth calculations.

In our days the most used SRS for map visualizations is the so called Web Mercator Projection (SRID 3857). We got used to the fact, that Greenland appears to be as big as Africa, whilst in reality the size of Greenland is only a fraction of the size of Africa:
https://takeitscienceblog.wordpress.com/2016/08/31/how-big-is-your-country/
The distortion of the projection is increasing with the distance to the equator. What is not necessarily an issue for web maps, may become an issue when doing spatial analytics. For my analysis I chose the SRS with SRID 5018, which is suitable for Portugal (meaning the distortion is minimized in the area of Portugal). GPS coordinates use SRID 4326, which is a round-earth model enabling precise calculation at the cost of computing power.
So why not simply choose 3857? All the web maps use it and eventually Portugal is way closer to the equator than Greenland is. To illustrate the error that we would introduce in our calculation, I compared the average travel distance of our taxis within the different Spatial Reference Systems:

It turns out that the average travel distance in SRS 3857 is more than 30% higher(!) than the exact round-earth calculation. Doing the same comparison with SRS 5018, which is suitable for Portugal gives an error of only 0.01%, which is maintainable given the gain in performance that we win.
Always keep this in mind when choosing a Spatial Reference System for you analysis!
Include Point of Interest Data
Recently, I published a blog on how to load point-of-interest data from OpenStreetMap to SAP HANA using OSMnx:
Where to (NOT) Charge my Car? – OpenStreetMap POIs in SAP HANA
Essentially I have done the same to retrieve the POI data for Porto with one interesting difference: Instead of querying the POI data for the search string 'Porto' I analyzed the area, that my trajectory data is covering. There are also some trips going to Lisbon and I may also be interested in the POIs close to these destinations. I applied ST_CONVEXHULLAGGR to calculate the convex hull over all trajectories and used the resulting polygon to query the POIs with OSMnx.
sql_result = %sql SELECT ST_CONVEXHULLAGGR(SHAPE).ST_TRANSFORM(4326).ST_ASWKT() FROM TAXI
df_poi_shape = sql_result.DataFrame()A quick visualization unveils the size of the convex hull.

To generate the above visualization with kepler.gl comes down to one line of code, where the DataFrame (df_poi_shape) gets passed to the map. The interactive kepler.gl client will appear when executing the cell code.
KeplerGl(height=500, data={'poi_shape':df_poi_shape})The DataFrame containing the WKT representation of the polygon, that covers all trajectories can now be passed to OSMnx.
gdf_poi = ox.pois_from_polygon(
df_poi_shape[df_poi_shape.columns[0]].apply(wkt.loads).iloc[0],
amenities=[
'taxi', 'car_rental', 'bus_station', #transportation
'bar', 'restaurant', 'pub', 'cafe', #sustenance
'university', 'college', #education
'clinic', 'doctors', 'hospital', 'pharmacy' #healthcare
'cinema', 'nightclub', 'stripclub', 'theater', #entertainment
'conference_centre'
]
)Finally, we store the GeoDataFrame containing the point-of-interests to a HANA table (named OSM_POI in my case). We can leverage spatial joins to incorporate this data in our analysis.
Add Reference Grid
For some analysis (i.e. applying ML algorithms) it might be advantageous to get rid of the geospatial dimension and instead have a grid index to reference and aggregate certain data points. A hexagonal grid has certain advantages over other grids (e.g. rectangular). We persist a reference grid spanning 250 hexagonal cells in width for later usage.
INSERT INTO REFGRID
(
SELECT
'HEXID-'|| ST_CLUSTERID() AS HEXID,
ST_CLUSTERCELL() AS HEXCELL,
ST_CLUSTERCELL().ST_CENTROID() AS HEXCENTROID
FROM ((SELECT STARTPOINT AS PT FROM TAXI) UNION (SELECT ENDPOINT AS PT FROM TAXI))
GROUP CLUSTER BY PT USING HEXAGON X CELLS 250
)The grid covers only start and end points of the taxi trajectories, which will be sufficient for the analysis we are doing. We also added the centroids of each grid cell by using ST_CENTROID.
Basic Spatial Analysis
After doing all the prep work, we are now ready for some very basic spatial analysis. How about calculation a few aggregated measures?
SELECT AVG(DISTANCE)/1000 AS DISTANCE_KM FROM TAXI
-- 5.5km
SELECT AVG(DURATION)/60 AS DURATION_MINUTES FROM TAXI
-- 12.5 minutes
SELECT AVG(SPEED_AVG) AS SPEED_KMH FROM TAXI
-- 26.2 km/hThat does not look "Spatial" enough to you? Remember that all those measures (distance, duration and speed) have been derived from the raw trajectory data using spatial database functions. We are just reaping the benefits of our thorough data preparation.
Also we can quickly fetch some sample trajectories and visualize them together with POI data. Please note that kepler.gl requires the transformation back to SRID 4326 as well as a representation as WKT or GeoJSON. For this preparation we use ST_TRANSFORM and ST_ASWKT (alternatively ST_ASGEOJSON).
SELECT TOP 1000
INDEX,
SHAPE.ST_TRANSFORM(4326).ST_ASWKT() as SHAPE
FROM TAXI
ORDER BY RAND();
SELECT
OSMID,
SHAPE.ST_TRANSFORM(4326).ST_ASWKT() AS SHAPE,
AMENITY,
NAME
FROM OSM_POIVisualizing the results, we can also spot that our "Points" of interest do not only contain point data, but also polygons like large hospital buildings.

Analyze Pick-up Locations
In a city you would expect to see patterns when looking at the pick-up locations of taxis. Certainly you would expect a high demand at the airport as well as a high demand in nightlife neighbourhoods at night or during the early morning hours.
Pick-up locations are not always identical. To aggregate them in a meaningful way, we again apply a hexagonal clustering, which counts the number of taxi pick-ups per location cluster on a logarithmic scale (to make the visualization more meaningful).
SELECT
ST_CLUSTERID(),
ST_CLUSTERCELL().ST_TRANSFORM(4326).ST_ASGEOJSON() AS HEXCELL,
LOG(10, COUNT(*)) AS QUANTITY
FROM TAXI
GROUP CLUSTER BY STARTPOINT USING HEXAGON X CELLS 500This time we not only visualize the cluster polygons, but also color the polygons according to the quantity of pick-ups. Furthermore we introduce a third dimension and also scale the height of each hexagonal area with the quantity of pick-ups.
Yes, that is redundant to the color coding. So why do we do this? Just because we can!

We can immediately spot the airport in the suburb of Porto. It is the area with high pick-up density at the left. However, the areas with the highest pick-up rates are in the very center of Porto.
We can retrieve the top 3 cells and the POIs within those cells by using a spatial join with ST_INTERSECTS.
SELECT B.OSMID, B.SHAPE.ST_TRANSFORM(4326).ST_ASWKT() AS OSMSHAPE, B.AMENITY, B.NAME, A.HEXCELL.ST_TRANSFORM(4326).ST_ASWKT() AS HEXSHAPE
FROM
(
SELECT TOP 3 ST_CLUSTERCELL() AS HEXCELL
FROM TAXI
GROUP CLUSTER BY STARTPOINT USING HEXAGON X CELLS 500
ORDER BY COUNT(*) DESC
) A LEFT JOIN OSM_POI B ON A.HEXCELL.ST_INTERSECTS(B.SHAPE) = 1We can see that the top locations are the historic center of Porto (near São Bento station; left cells) as well as the main train station (Campanhã; right cell), which has a huge taxi stand next to it.

So far we have seen the overall count of pick-ups. Of course, as mentioned earlier there is also a time component to this. Certain areas may have higher traffic at certain times. To analyze this behaviour we introduce a second binning dimension. Earlier we built a location binning using hexagonal clustering, now we add a temporal binning by aggregating all taxi rides within the same hour.
SELECT
CLUSTERID,
CLUSTERCELL.ST_TRANSFORM(4326).ST_ASGEOJSON() AS CLUSTERCELL,
HOURBIN,
LOG(10, COUNT(*)) AS QUANTITY
FROM
(
SELECT
TO_TIMESTAMP(YEAR(STARTTIME) || '-' || MONTH(STARTTIME) || '-' || DAYOFMONTH(STARTTIME) || ' ' || LPAD(HOUR(STARTTIME) - MOD(HOUR(STARTTIME),2), 2, '0') || ':00:00') AS HOURBIN,
ST_CLUSTERID() OVER (CLUSTER BY STARTPOINT USING HEXAGON X CELLS 250) AS CLUSTERID,
ST_CLUSTERCELL() OVER (CLUSTER BY STARTPOINT USING HEXAGON X CELLS 250) AS CLUSTERCELL,
TRIP_ID
FROM TAXI
)
GROUP BY CLUSTERID, CLUSTERCELL, HOURBIN
HAVING COUNT(*) > 1This dataset can be handed over to kepler.gl, which has a feature to generate an animation over time. The video shows the expected rush hours as well as a certain irregularity during Christmas and New Year.
The Route to the Airport
We identified with our earlier analysis that the airport plays a special role when looking at taxi rides. This is by no means surprising. Let's dig a bit deeper and look at the relations between pick-up and drop-off locations. Where are trips to a certain location typically originating?
We do not answer this question on a location base, but rather on a grid base using the reference grid, that we have created earlier. So the question we want to answer is: "In which hexagonal cell are trips typically originating when arriving at a certain other cell?". The following statement calculates the count of trips for all observed combination of start and end cells in the reference grid.
Again, we need to some more transformations (ST_X, ST_Y) to accomodate the visualization framework, which seem to require individual latitude and longitude values for this kind of visualization.
SELECT
START_HEXID,
START_CENTROID.ST_TRANSFORM(4326).ST_X() AS START_CELL_LON,
START_CENTROID.ST_TRANSFORM(4326).ST_Y() AS START_CELL_LAT,
END_HEXID,
END_CENTROID.ST_TRANSFORM(4326).ST_X() AS END_CELL_LON,
END_CENTROID.ST_TRANSFORM(4326).ST_Y() AS END_CELL_LAT,
COUNT(*) AS CNT
FROM
(
SELECT
TRIP_ID,
a.HEXID AS START_HEXID,
a.HEXCENTROID AS START_CENTROID,
b.HEXID AS END_HEXID,
b.HEXCENTROID AS END_CENTROID
FROM TAXI
LEFT JOIN REFGRID a ON STARTPOINT.ST_WITHIN(a.HEXCELL) = 1
LEFT JOIN REFGRID b ON ENDPOINT.ST_WITHIN(b.HEXCELL) = 1
)
GROUP BY START_HEXID, START_CENTROID, END_HEXID, END_CENTROID
HAVING COUNT(*) > 100This result can be visualized with a 3d flow. We can easily spot that most trips to the airport departed from the area around São Bento station. (the second most is the main station of Porto, Campanhã)
But what is the best way to go from São Bento station to the airport? To answer this question we could look at the duration of all trips starting at the respective grid cell and ending at the grid cell containing the airport. Let's do this!
SELECT
INDEX,
TRIP_ID,
CALL_TYPE,
TAXI_ID,
STARTTIME,
ENDTIME,
SPEED_AVG,
DURATION,
DISTANCE,
SHAPE.ST_TRANSFORM(4326).ST_ASWKT() as SHAPE,
a.HEXCELL.ST_TRANSFORM(4326).ST_ASWKT() AS START_HEXCELL,
b.HEXCELL.ST_TRANSFORM(4326).ST_ASWKT() AS END_HEXCELL
FROM TAXI t
LEFT JOIN REFGRID a ON STARTPOINT.ST_WITHIN(a.HEXCELL) = 1
LEFT JOIN REFGRID b ON ENDPOINT.ST_WITHIN(b.HEXCELL) = 1
WHERE a.HEXID = 'HEXID-86826' AND b.HEXID = 'HEXID-90071' AND DISTANCE < 2 * a.HEXCENTROID.ST_DISTANCE(b.HEXCENTROID)In the data we can observe some weird trips, which we filtered out by allowing only trips, which are shorter than 2 times the straight distance between the station and the airport. On our abstraction level this corresponds to the ST_DISTANCE between the centroids of the respective hexagonal cells.
For the visualization we color the trajectories depending on the overall trip duration (green is fast; red is slow).

We can spot that there are 3 access roads to the airport. Most traffic is using the major road in the middle, whereas some (presumably smart) drivers use smaller access roads. The distance of those trips is higher, of course. However many of the trips using the smaller access roads result in a rather short trip duration.
Predicting the Duration of a Trip
Well, so far we have built up a pretty good understanding of the underlying dataset. We primarily dealt with geospatial functions and visualizations. How do we incorporate this knowledge into a machine learning model? And how do we adjust the model to understand geospatial data?
The answer to the ladder one is: Given the right preprocessing, there is no need for our machine learning model to actually understand geospatial data! Using our reference grid, spatial joins and aggregations, we may as well feed the id of the respective grid cells as a categorical variable into our model.
Only we know that this id represents a location and we can map it back on a map - our ML model does not have to care about those tedious details.
To predict the duration of a trip, we train a regression model using the Automated Predictive Library (APL) of SAP HANA. The APL can be conveniently called using the Python Client API for Machine Learning Algorithms. With this approach the model training will be pushed down to the database level. We will only transfer data to the Python client, that is required for reviewing the model performance!
First, we are going to gather the training data.
hdf_trajectories = conn.sql('''
SELECT
INDEX,
STARTTIME,
R1.HEXID AS HEXID_START,
R2.HEXID AS HEXID_END,
DURATION
FROM TAXI
LEFT JOIN REFGRID R1 ON STARTPOINT.ST_WITHIN(R1.HEXCELL) = 1
LEFT JOIN REFGRID R2 ON ENDPOINT.ST_WITHIN(R2.HEXCELL) = 1
''')The HANA DataFrame 'hdf_trajectories' looks and behaves similar to a Pandas DataFrame with the exception, that the data is not transferred to the client unless 'collect()' gets called.
As an example the first five entries can be transferred to the client with this statement.
hdf_trajectories.head(5).collect()
We now pass this HANA DataFrame to the model training function to train a regression model with 'duration' as dependent variable.
model = regression.AutoRegressor(conn_context = conn, variable_auto_selection = True)
model.fit(hdf_trajectories, label='DURATION', features=['STARTTIME', 'HEXID_START', 'HEXID_END'], key='INDEX')We only allow STARTTIME, HEXID_START and HEXID_END as input variables. As mentioned earlier the IDs of our grid cells are not geometries. The APL will handle the timestamp automatically and also generate features for Hour of Day, Day of Week, Day of Month, etc.
For the remainder of the blog I am focusing on looking at the model debriefing results itself rather than on the code to visualize it. Take a look at the full Jupyter Notebook, if you are interested in more details.
The main indicators for model performance are Predictive Power and Predictive Confidence. The below figures suggest that we trained a stable model having some predictive power (a value of 0 would be guessing; 1 would be visionary).

Which factors influence the outcome of the model? Plotting the contributing variables we can see that the spatial dimension has the highest contribution. This is evident has the duration increases the further start and target are away from each other.
Also we can spot that the Hour of Day has the second largest contribution and finally also the Day of Week is part of the model. Please note that we enabled Automatic Feature selection, which allowed the model to disregard non-contributing dimensions.

For the Hour of Day we would expect to see rush hours where traffic is slower and the trip duration increases. We can verify this by plotting the category significance.

The above chart tells us, that we expect the largest delays between 5pm and 6pm (positive contribution to 'duration') and that we expect to have the shortest travel durations between 2am and 3am (negative contribution to 'duration').
Yeah, that makes sense! So, our model carries some truth in it!
Finally, we can use our model to actually predict a travel time. We already know São Bento station and the airport - so what else should we choose?
hdf_predict = conn.sql('''
SELECT
0 INDEX,
'2020-02-10 20:00:00' as STARTTIME,
'HEXID-86826' AS HEXID_START,
'HEXID-90071' AS HEXID_END
FROM DUMMY
''')
model.predict(hdf_predict).collect()Our model suggests that a taxi ride on Monday Feb 10th at 5 am would last 966 seconds (~16 minutes).

The same ride at 5pm would take us ~21 minutes.

Does this sound reasonable? Let's compare it with some trusted source and let our favourite web routing service have a guess (at the time of writing Feb 10th is a future date).

This is actually pretty close to our prediction! Remember that our prediction is based on some 2013 taxi data and the web prediction is based on bazillions of smartphone users submitting their travel geo location and travel speed.
How about also predicting the actual destination of the taxi? You can find more information in my follow-up blog: Predicting Taxi Destinations with SAP HANA
Summary
First of all, I have to admit that I have never been to Porto. In the course of writing this blog, I had the feeling I should try the taxi trip from the airport to the historic center myself. I definitely added this to my bucket list.

On the technical side of things we have seen the following:
- Downloading and persisting a geospatial dataset
- Preparing and enhancing a geospatial dataset with basic calculations
- Joining datasets with spatial predicates
- Creating a reference grid to abstract from geospatial specifics
- Visualizing geospatial data in Jupyter Notebooks
- Applying a Machine Learning model to predict travel times on a dataset that actually did not contain any column with a geometrical datatype
There is a general pattern behind what we did, which holds true for many usecases:
Prepare, Enhance, Abstract, Visualize and last but not least Generate Insight.
This value chain does not necessarily have to be executed by one person or department. It may involve IT, GIS, Data Science and Business Departments at the same time. The integration of (Geo-)Spatial Data Science into SAP HANA enables you to break down silos and opens the full 360 view on your data instead of moving partial information between departments.
One last thing: My favourite web routing service also has a web search featuring some autocompletion. This is the first suggestion I got for "porto sao b":

- SAP Managed Tags:
- Machine Learning,
- SAP HANA,
- SAP HANA, express edition,
- SAP HANA multi-model processing,
- SAP HANA Spatial
Labels:
5 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
107 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
72 -
Expert
1 -
Expert Insights
177 -
Expert Insights
340 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
14 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
384 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,872 -
Technology Updates
472 -
Workload Fluctuations
1
Related Content
- Explore the SAP HANA Cloud vector engine with a free learning experience in Technology Blogs by SAP
- SAP HANA Cloud Vector Engine: Quick FAQ Reference in Technology Blogs by SAP
- Deliver Real-World Results with SAP Business AI: Q4 2023 & Q1 2024 Release Highlights in Technology Blogs by SAP
- Revolutionizing Business through the Power of SAP’s Artificial Intelligence Superheroes in Technology Blogs by SAP
- Unraveling the SAP DataSphere: Insights in bite-sized pieces in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 17 | |
| 14 | |
| 13 | |
| 10 | |
| 9 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 |