
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Dancing with SAP Data Intelligence
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member21
Participant
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
01-08-2020
2:46 PM
In the blog post written by ingo.peter, we can see how SAP Data Intelligence can leverage SAP HANA PAL to create predictive models by using custom code in Python Operators. In this article, we will show a new way (available as of DI 1911) of using PAL models by using out-of-the-box operators.
As the end-of-the-year party approaches, your manager gives you, an important data scientist in the company, a critical job: to make sure the music playlist is as fun as possible. This is of extreme importance so that all employees enjoy the party. You think to yourself: how on earth you will do that? After all, you are no DJ. So, you decide to put your machine learning skills to work and create a model to figure that out for you. But that brings up another question: where will you do that? It would be good if this model could be integrated with your in-house software that manages events. You then remember reading about a platform called SAP Data Intelligence in an SAP blog post and decide to use it to tackle this problem as well.
As usual, you need to gather some data to train a model. Luckily, you find on the Internet a dataset containing a list of the top 50 Spotify songs of 2019 and some features associated to each of them. You upload the csv file to your company datalake on AWS S3.
You open up the Modeler app to create a pipeline that will load the data from the csv into HANA DB. Also, you take the opportunity to clean it up a bit. As you would like to keep things simple (at least for now), you decide to use only some of the features available on the dataset.
The pipeline for that is also simple. Just an operator to read the file, a Python script to pre-process the data, and ultimately a HANA client operator to insert the data into the database. It looks like this:

For the Read File operator, the configuration was quite simple:

For the Python operator, you wrap it with a group by right clicking it and selecting "Add group". On the settings of that group, you add tag "pandas". That will allow you to import pandas package, which makes it so much easier to deal with csv files. Also, you create an input port on the operator called "file" of type "message.file" and an output port called "data" of type "message. The Python code then looks like this:
You then configure the SAP HANA client operator, which is also simple:

Last, you connect the operators and run the pipeline. Success! The data is in HANA now. You are off to a great start in this endeavor!
Well, SAP Data Intelligence has an app for that. Without second guessing, you open up ML Scenario Manager (MLSM), and create a new scenario:


In the scenario, you click on the + sign on the Pipelines section, choose the template HANA ML Training and give it a name.


When created, you are taken to the Modeler UI.

Here you do some configurations on the pipeline. In this case, you configure the HANA ML Training operator by selecting a connection, specifying the training and test datasets, select the task and algorithm, and inform the key and target columns. Additionally, hyperparameters could be provided to fine-tune the algorithm in JSON format. They can be found in the HANA ML documentation page and are algorithm specific. For example, these are the hyper parameters for a neural network.
When ready, the configurations look like the following:

That's it! Going back to MLSM, you select that pipeline and click on execute. Since there were changes to the pipeline, MLSM asks you to create a new version:



After that, you execute the pipeline once again. This time, MLSM takes you through some steps in which you can provide a description of the current execution and provide global pipeline configurations. In this case, the name of the artifact (model) that is going to be created. You give it a name and click Save.



Then, the training begins:
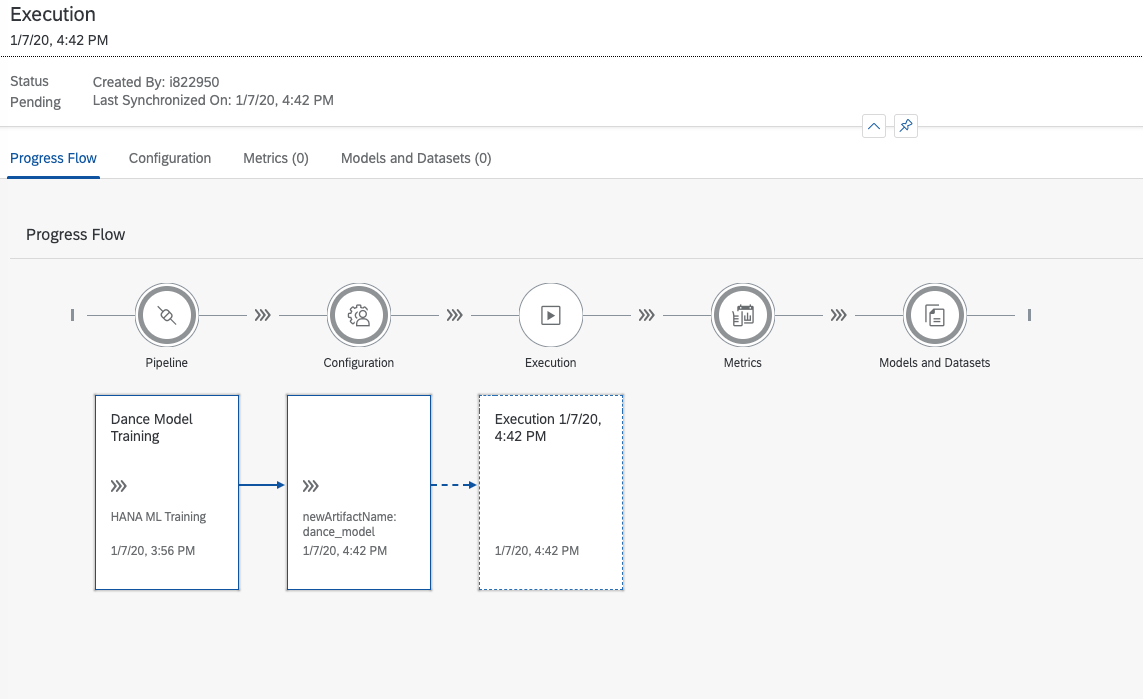
... and in a few moments, you have yourself a shiny new model. Excellent!

Once again in MLSM, you create a new pipeline, but this time you select the HANA ML Inference template.

Just like before, you are then taken to the Modeler:

This time you configure the HANA ML Inference operator to connect to a HANA system. That's right, any HANA system! Not necessarily the one in which the model was trained. The configuration looks like the following:

Back to MLSM, you select the pipeline and deploy it:

Once again, you create a new version, since you modified the pipeline.
The wizard takes you to the point where you need to specify a model that will be used. Here, you select the recently trained model and continue.

At the end, you get a URL that you can use as a REST endpoint exposing your model.

Time to see what this thing can do! To simplify things, you do a regular curl by providing the features of a song you want to determine whether people will enjoy:
And the response for that one is:
Great! That is it! You did it! Now, you just have to let your boss know the job is done, enjoy the party and get the well deserved promotion! 🙂
Introduction
As the end-of-the-year party approaches, your manager gives you, an important data scientist in the company, a critical job: to make sure the music playlist is as fun as possible. This is of extreme importance so that all employees enjoy the party. You think to yourself: how on earth you will do that? After all, you are no DJ. So, you decide to put your machine learning skills to work and create a model to figure that out for you. But that brings up another question: where will you do that? It would be good if this model could be integrated with your in-house software that manages events. You then remember reading about a platform called SAP Data Intelligence in an SAP blog post and decide to use it to tackle this problem as well.
The dataset
As usual, you need to gather some data to train a model. Luckily, you find on the Internet a dataset containing a list of the top 50 Spotify songs of 2019 and some features associated to each of them. You upload the csv file to your company datalake on AWS S3.
Loading the data into SAP HANA DB
You open up the Modeler app to create a pipeline that will load the data from the csv into HANA DB. Also, you take the opportunity to clean it up a bit. As you would like to keep things simple (at least for now), you decide to use only some of the features available on the dataset.
The pipeline for that is also simple. Just an operator to read the file, a Python script to pre-process the data, and ultimately a HANA client operator to insert the data into the database. It looks like this:
For the Read File operator, the configuration was quite simple:
For the Python operator, you wrap it with a group by right clicking it and selecting "Add group". On the settings of that group, you add tag "pandas". That will allow you to import pandas package, which makes it so much easier to deal with csv files. Also, you create an input port on the operator called "file" of type "message.file" and an output port called "data" of type "message. The Python code then looks like this:
from io import StringIO
import pandas as pd
def on_file(message):
content = StringIO(message.body.decode('iso-8859-1'))
df = pd.read_csv(content, sep=",")
dataset = df[['Genre','Beats.Per.Minute','Popularity','Length.','Danceability']]
dataset['Genre'] = dataset['Genre'].astype('category').cat.codes
danceability_col = dataset['Danceability']
danceability_col_cat = danceability_col.copy()
fun_threshold = 70
danceability_col_cat[danceability_col < fun_threshold] = 'No Fun'
danceability_col_cat[danceability_col >= fun_threshold] = 'Fun'
dataset['Danceability'] = danceability_col_cat
api.send('data', api.Message(body=dataset.to_csv(header=None)))
api.set_port_callback('file', on_file)You then configure the SAP HANA client operator, which is also simple:
Last, you connect the operators and run the pipeline. Success! The data is in HANA now. You are off to a great start in this endeavor!
Training the model
Well, SAP Data Intelligence has an app for that. Without second guessing, you open up ML Scenario Manager (MLSM), and create a new scenario:
In the scenario, you click on the + sign on the Pipelines section, choose the template HANA ML Training and give it a name.
When created, you are taken to the Modeler UI.
Here you do some configurations on the pipeline. In this case, you configure the HANA ML Training operator by selecting a connection, specifying the training and test datasets, select the task and algorithm, and inform the key and target columns. Additionally, hyperparameters could be provided to fine-tune the algorithm in JSON format. They can be found in the HANA ML documentation page and are algorithm specific. For example, these are the hyper parameters for a neural network.
When ready, the configurations look like the following:
That's it! Going back to MLSM, you select that pipeline and click on execute. Since there were changes to the pipeline, MLSM asks you to create a new version:
After that, you execute the pipeline once again. This time, MLSM takes you through some steps in which you can provide a description of the current execution and provide global pipeline configurations. In this case, the name of the artifact (model) that is going to be created. You give it a name and click Save.
Then, the training begins:
... and in a few moments, you have yourself a shiny new model. Excellent!
Deploying an inference pipeline
Once again in MLSM, you create a new pipeline, but this time you select the HANA ML Inference template.
Just like before, you are then taken to the Modeler:
This time you configure the HANA ML Inference operator to connect to a HANA system. That's right, any HANA system! Not necessarily the one in which the model was trained. The configuration looks like the following:
Back to MLSM, you select the pipeline and deploy it:
Once again, you create a new version, since you modified the pipeline.
The wizard takes you to the point where you need to specify a model that will be used. Here, you select the recently trained model and continue.
At the end, you get a URL that you can use as a REST endpoint exposing your model.
Consuming the REST endpoint
Time to see what this thing can do! To simplify things, you do a regular curl by providing the features of a song you want to determine whether people will enjoy:
curl --location --request POST 'https://<host>/app/pipeline-modeler/openapi/service/<deploy id>/v1/inference' \
--header 'Content-Type: application/json' \
--header 'If-Match: *' \
--header 'X-Requested-With: Fetch' \
--header 'Authorization: Basic 00000000000000000' \
--data-raw '{
"ID": [1],
"GENRE": ["6"],
"BEATSPERMINUTE": [117],
"POPULARITY": [79],
"LENGTH":[121]
}'And the response for that one is:
{"ID":{"0":1},"SCORE":{"0":"Fun"},"CONFIDENCE":{"0":0.5990922485}}Great! That is it! You did it! Now, you just have to let your boss know the job is done, enjoy the party and get the well deserved promotion! 🙂
- SAP Managed Tags:
- Machine Learning,
- SAP Data Intelligence,
- SAP HANA
Labels:
5 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
273 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
327 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
403 -
Workload Fluctuations
1
Related Content
- 10+ ways to reshape your SAP landscape with SAP BTP - Blog 4 Interview in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
- Top Picks: Innovations Highlights from SAP Business Technology Platform (Q1/2024) in Technology Blogs by SAP
- Experiencing Embeddings with the First Baby Step in Technology Blogs by Members
- Understanding AI, Machine Learning and Deep Learning in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 10 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 5 | |
| 4 |