
- SAP Community
- Products and Technology
- Enterprise Resource Planning
- ERP Blogs by Members
- Modern SAP ERP Data Integration using Apache Kafka
Enterprise Resource Planning Blogs by Members
Gain new perspectives and knowledge about enterprise resource planning in blog posts from community members. Share your own comments and ERP insights today!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
werner_daehn
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-10-2019
10:46 AM
The classic way of SAP ERP Data Integration is to use one of the many APIs available, reading the required data and putting it somewhere else. There are many APIs and different tools for that, all with their own pros and cons.
The S/4HanaConnector provided by rtdi.io goes a different route. Its aim is to rather utilize technologies built for Big Data to solve the problem in a flexible, easy, less intrusive and convenient way.
Given the fact that all ABAP tables are transparent tables in S/4Hana, the connection is made on database level for performance reasons.

As a consumer I would like to get Sales Orders, Business Partners, Material Master and the such. Therefore the first step is to define the scope of above objects and where the data comes from. This can be achieved via multiple ways:
For option #3, the most complicated one, the connector provides a UI to define such Business Object Entities.
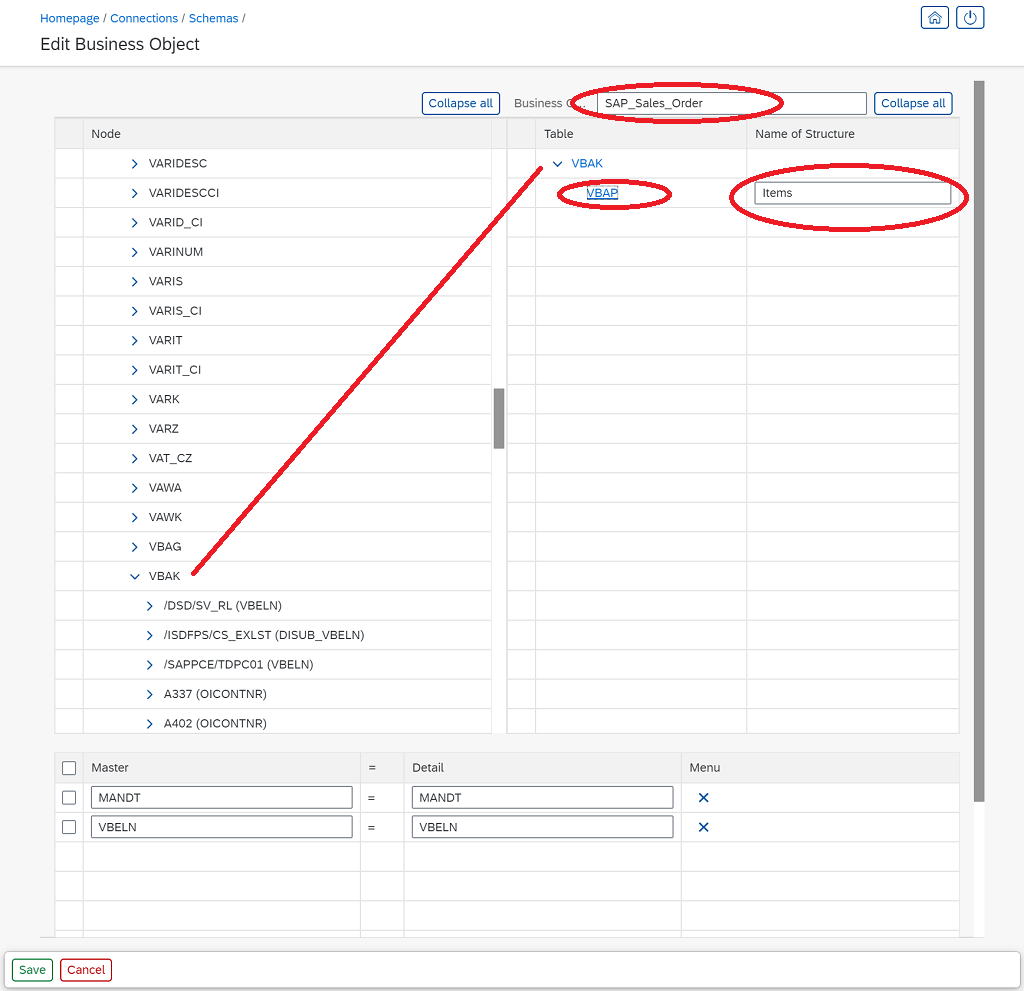
It allows to browse through all the ERP tables, here VBAK containing the Sales Order header data, and to drop that on the output pane. A sales order consists of sales items as well, hence the VBAK table is expanded and shows all relationships to child tables. Dropping the VBAP on the output side adds it as a child and the relationship as defined by SAP is added automatically.
Finally the entire Business Object gets a name "SAP_Sales_Order" and is saved.
With that a Json file with the structure definition of the Sales Order Object got created.
All that is left is assigning above Business Object to a producer.

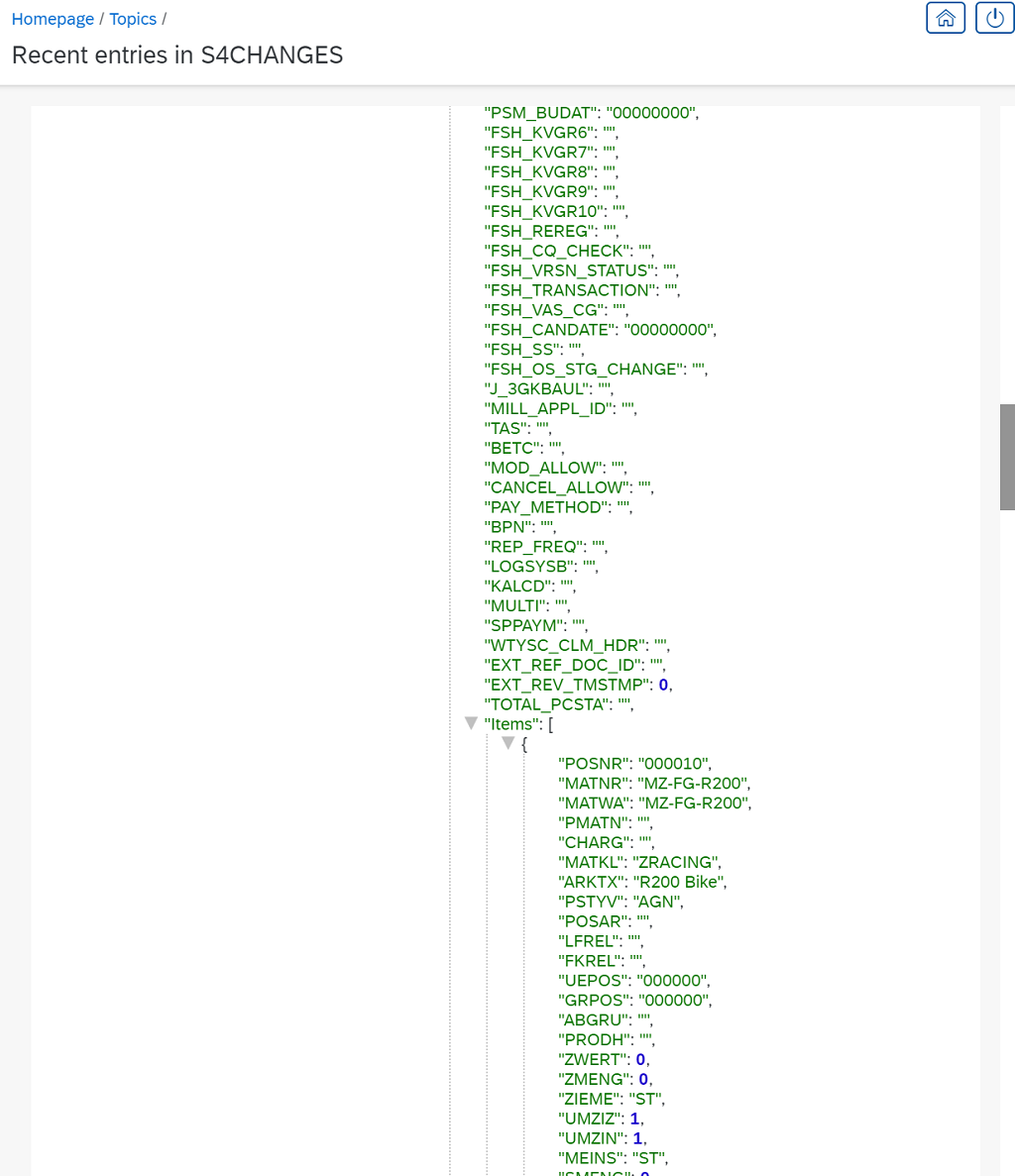
From now on all S/4Hana changes are sent to Apache Kafka and available for further consumption. Every single field of VBAK and VBAP as one object.
Simple, isn't it?
The S/4HanaConnector provided by rtdi.io goes a different route. Its aim is to rather utilize technologies built for Big Data to solve the problem in a flexible, easy, less intrusive and convenient way.
Step 1: Establish the connection
Given the fact that all ABAP tables are transparent tables in S/4Hana, the connection is made on database level for performance reasons.
Step 2: Defining the ERP Business Object
As a consumer I would like to get Sales Orders, Business Partners, Material Master and the such. Therefore the first step is to define the scope of above objects and where the data comes from. This can be achieved via multiple ways:
- Using the ABAP CDS Views, they join all tables belonging together.
- Using predefined Business Objects.
- Using the ABAP data dictionary to define the object scope.
For option #3, the most complicated one, the connector provides a UI to define such Business Object Entities.
It allows to browse through all the ERP tables, here VBAK containing the Sales Order header data, and to drop that on the output pane. A sales order consists of sales items as well, hence the VBAK table is expanded and shows all relationships to child tables. Dropping the VBAP on the output side adds it as a child and the relationship as defined by SAP is added automatically.
Finally the entire Business Object gets a name "SAP_Sales_Order" and is saved.
With that a Json file with the structure definition of the Sales Order Object got created.
Step 3: Configure the Producer
All that is left is assigning above Business Object to a producer.
Result
From now on all S/4Hana changes are sent to Apache Kafka and available for further consumption. Every single field of VBAK and VBAP as one object.
Simple, isn't it?
- SAP Managed Tags:
- SAP ERP,
- SAP S/4HANA
16 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"mm02"
1 -
A_PurchaseOrderItem additional fields
1 -
ABAP
1 -
ABAP Extensibility
1 -
ACCOSTRATE
1 -
ACDOCP
1 -
Adding your country in SPRO - Project Administration
1 -
Advance Return Management
1 -
AI and RPA in SAP Upgrades
1 -
Approval Workflows
1 -
ARM
1 -
ASN
1 -
Asset Management
1 -
Associations in CDS Views
1 -
auditlog
1 -
Authorization
1 -
Availability date
1 -
Azure Center for SAP Solutions
1 -
AzureSentinel
2 -
Bank
1 -
BAPI_SALESORDER_CREATEFROMDAT2
1 -
BRF+
1 -
BRFPLUS
1 -
Bundled Cloud Services
1 -
business participation
1 -
Business Processes
1 -
CAPM
1 -
Carbon
1 -
Cental Finance
1 -
CFIN
1 -
CFIN Document Splitting
1 -
Cloud ALM
1 -
Cloud Integration
1 -
condition contract management
1 -
Connection - The default connection string cannot be used.
1 -
Custom Table Creation
1 -
Customer Screen in Production Order
1 -
Data Quality Management
1 -
Date required
1 -
Decisions
1 -
desafios4hana
1 -
Developing with SAP Integration Suite
1 -
Direct Outbound Delivery
1 -
DMOVE2S4
1 -
EAM
1 -
EDI
2 -
EDI 850
1 -
EDI 856
1 -
EHS Product Structure
1 -
Emergency Access Management
1 -
Energy
1 -
EPC
1 -
Find
1 -
FINSSKF
1 -
Fiori
1 -
Flexible Workflow
1 -
Gas
1 -
Gen AI enabled SAP Upgrades
1 -
General
1 -
generate_xlsx_file
1 -
Getting Started
1 -
HomogeneousDMO
1 -
IDOC
2 -
Integration
1 -
Learning Content
2 -
LogicApps
2 -
low touchproject
1 -
Maintenance
1 -
management
1 -
Material creation
1 -
Material Management
1 -
MD04
1 -
MD61
1 -
methodology
1 -
Microsoft
2 -
MicrosoftSentinel
2 -
Migration
1 -
MRP
1 -
MS Teams
2 -
MT940
1 -
Newcomer
1 -
Notifications
1 -
Oil
1 -
open connectors
1 -
Order Change Log
1 -
ORDERS
2 -
OSS Note 390635
1 -
outbound delivery
1 -
outsourcing
1 -
PCE
1 -
Permit to Work
1 -
PIR Consumption Mode
1 -
PIR's
1 -
PIRs
1 -
PIRs Consumption
1 -
PIRs Reduction
1 -
Plan Independent Requirement
1 -
Premium Plus
1 -
pricing
1 -
Primavera P6
1 -
Process Excellence
1 -
Process Management
1 -
Process Order Change Log
1 -
Process purchase requisitions
1 -
Product Information
1 -
Production Order Change Log
1 -
Purchase requisition
1 -
Purchasing Lead Time
1 -
Redwood for SAP Job execution Setup
1 -
RISE with SAP
1 -
RisewithSAP
1 -
Rizing
1 -
S4 Cost Center Planning
1 -
S4 HANA
1 -
S4HANA
3 -
Sales and Distribution
1 -
Sales Commission
1 -
sales order
1 -
SAP
2 -
SAP Best Practices
1 -
SAP Build
1 -
SAP Build apps
1 -
SAP Cloud ALM
1 -
SAP Data Quality Management
1 -
SAP Maintenance resource scheduling
2 -
SAP Note 390635
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud private edition
1 -
SAP Upgrade Automation
1 -
SAP WCM
1 -
SAP Work Clearance Management
1 -
Schedule Agreement
1 -
SDM
1 -
security
2 -
Settlement Management
1 -
soar
2 -
SSIS
1 -
SU01
1 -
SUM2.0SP17
1 -
SUMDMO
1 -
Teams
2 -
User Administration
1 -
User Participation
1 -
Utilities
1 -
va01
1 -
vendor
1 -
vl01n
1 -
vl02n
1 -
WCM
1 -
X12 850
1 -
xlsx_file_abap
1 -
YTD|MTD|QTD in CDs views using Date Function
1
- « Previous
- Next »
Related Content
- Merging Multiple PDF Attachments into a Single PDF in SAP PI/PO Using Java Mapping in Enterprise Resource Planning Q&A
- Key Takeaways from Rise Into the Future Event: What You Need to Know in Enterprise Resource Planning Blogs by SAP
- [Feature]Side-by-side extensiblity to adjust the received transmission(Java) in Enterprise Resource Planning Blogs by SAP
- SAP S/4HANA Cloud Private Edition | 2023 FPS01 Release – Part 2 in Enterprise Resource Planning Blogs by SAP
- SAP S/4HANA Cloud Public Edition: the Right Cloud ERP Solution for Your Business in Enterprise Resource Planning Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 1 | |
| 1 | |
| 1 |