
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP HANA Data Strategy: HANA Data Modeling a Detai...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member22
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-14-2019
5:53 PM
This is part of the HANA Data Strategy series of BLOGS
https://blogs.sap.com/2019/10/14/sap-hana-data-strategy/
Why talk about HANA Data Modeling?
HANA data modeling is what drives real-time analytics while lowering the total cost of ownership (TCO) and time to deliver (TDL) business insights using SAP HANA digital business platform.
Another reason for talking about HANA data modeling at this time is that many customers are making the transition from HANA 1.0 to HANA 2.0. These customers need a deeper understanding of the newer HANA Deployment Infrastructure (HDI) architecture to take advantage of the advanced features added here. Also, there are no comprehensive HANA data modeling sources, and virtual calculation view models are at the heart of HANA Intelligent Digital Business Platform.
Once customers begin to adopt all of the HANA virtual data modeling features, they will drive out all of the latency from their traditional approaches to analytics, creating a true real-time environment and at the same time significantly lower the TCO of the solution by eliminating the need for tradition ETL, change data capture, data streaming and modeling infrastructures. The real-time aspect of this solution means that as soon as an event (order, meter reading, phone call) occurs anywhere in any system in a company’s enterprise, the HANA Intelligent Digital Business Platform will analyze and deliver insight based on that event to the business.
In this blog, I will give a detailed overview of HANA data modeling with a set of recorded presentations and demos that will not only explain all the aspects of HANA data modeling from harmonization with calculation views to data replication with replication tasks, but I will also share demos of how to do the basics. I will follow this up with more advanced modeling presentation and demos in future blogs.
I will also give a detailed overview of the old HANA repository and the new HANA Deployment Infrastructure (HDI) architectures and the development tools used to build models in each. I will then explain the basics of the HDI architecture and demo how to:
- build a project,
- access classic schema tables from HDI using synonyms,
- access HDI artifacts like calculation views from external users (SAC),
- build a calculation view with a star join,
- union and join distributed tables in calculation views.
Introduction to HANA Data Modeling
This presentation is an overview of all aspects of HANA data modeling and data access. It explains all the different types of models that we use in HANA to:
- Ingest the enterprise data in real-time,
- Harmonize and analyze data in real-time, and
- Deliver business insights in real-time.
Throughout these presentations I refer to HANA classic modeling as HANA 1 modeling and HDI modeling as HANA 2 modeling.

Recorded presentation:
https://sapvideoa35699dc5.hana.ondemand.com/?entry_id=1_ggrqr432
Overview of HANA classic and HANA Deployment Infrastructure (HDI) architectures and tools
This presentation is an overview of the differences between the HANA classic modeling and its development tools Studio and Workbench. Compared to the newer HDI modeling and its tool WebIDE. Also an architectural overview of the new HDI containers.

Recorded presentation:
https://sapvideoa35699dc5.hana.ondemand.com/?entry_id=0_px25z63a
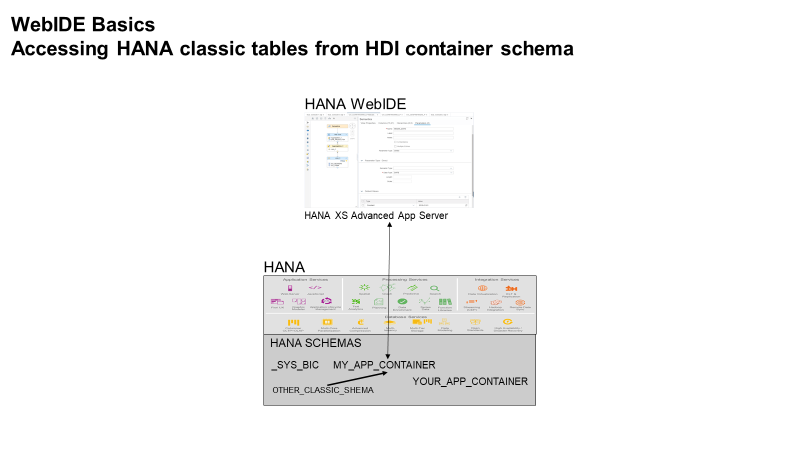
Creating an HDI container and accessing a HANA classic schema from HDI container
This presentation covers the steps for creating an HDI container via a WebIDE database project and then walks through the steps of granting access to HANA classic schema and tables to an HDI container and then how to create a simple calculation view to access those tables.
In the new HDI container architecture developers can store views, calculation views, procedures and tables. This is unlike the classic HANA repository (_SYS_BIC schema) which only stored calculation views and older analytic views and then stored tables in other (classic) schema. All of the SAP application data is still being stored in classic schema and tables, therefore a customers calculation views being created in HDI containers will need access to tables being stored in HANA classic schema.
The basic steps are:
- grant permissions for HDI container#OO user to access HANA classic tables,
- create an external HANA service in your HDI container schema,
- create .hdbsynonym file to setup local synonyms for each external table, and
- use these synonyms in a calculation view.
Recorded presentation:
https://sapvideoa35699dc5.hana.ondemand.com/?entry_id=0_ys0w7uae
This is a demonstration of all of this in action.
https://sapvideoa35699dc5.hana.ondemand.com/?entry_id=0_asjxg001
Granting access for SYSTEM HANA user id to HDI calculation views and tables
This presentation and demo will show how to now grant access to the calculation view we just created in the HDI container to the SYSTEM user id which is external to the HDI environment.
The basic steps to grant SYSTEM user id SELECT access to the GYDEMO_HDI_DB_1 container schema:
- Open an Admin SQL Console of container GYDEMO_HDI_DB_1
- Then grant permissions with these 4 steps:
- set schema "GYDEMO_HDI_DB_1#DI";
- create local temporary column table "#PRIVILEGES" like "_SYS_DI"."TT_SCHEMA_PRIVILEGES";
- insert into "#PRIVILEGES" ("PRIVILEGE_NAME", "PRINCIPAL_SCHEMA_NAME", "PRINCIPAL_NAME") values ('SELECT', '', 'SYSTEM');
- call "GYDEMO_HDI_DB_1#DI"."GRANT_CONTAINER_SCHEMA_PRIVILEGES"("#PRIVILEGES", "_SYS_DI"."T_NO_PARAMETERS", ?, ?, ?);

Recorded presentation and demo:
https://sapvideoa35699dc5.hana.ondemand.com/?entry_id=0_c2vf32t0
HDI supported calculation views
This presentation and demo will cover the following topics:
- Discuss the supported HDI calculation views: CUBE, CUBE with star join and table function
- Discuss differences between classic scripted calculation view and a table function
- Demo the creation of a table function
- Demo the creation of a CUBE calculation view with a star join
More on this subject will be covered in a later BLOG focused completely on the migration tools used to migrate the HANA classic artifacts to HANA HDI artifacts.

Recorded presentation and demo:
https://sapvideoa35699dc5.hana.ondemand.com/?entry_id=0_fdw51dsc
Creating calculation views using remote tables in multiple servers
This presentation and demo will cover the following topics:
- Discussion and demo of running calculation views using virtual tables from multiple remote servers,
- Demo how to build a UNION of calculation views built on remote tables using trusted techniques, and
- Discuss the issues of joining remote tables and techniques to make it work.


Recorded presentation and demo:
https://sapvideoa35699dc5.hana.ondemand.com/?entry_id=0_7whm6ks6
Conclusion
After watching these presentations and demos customers should be able to explain the differences between the HANA classic modeling and the newer HDI modeling. Customers should be able to create an HDI architecture accessing HANA classic schemas and tables and be able to access those tables from HDI calculation views. Customers should also understand some of the basic techniques for using calculation views with star joins in a distributed environment.
The knowledge in this and future BLOGs will allow customers to quickly and easily create powerful models harmonizing their multiple silos of application data into a single enterprise view that can deliver insights to their business users in real-time.
SAP HANA Data Strategy BLOGs Index
SAP HANA Data Strategy
- SAP HANA Data Strategy: HANA Data Modeling a Detailed Overview
- HANA Data Strategy: Data Ingestion including Real-Time Change Data Capture
- HANA Data Strategy: Data Ingestion – Virtualization
- HANA Data Strategy: HANA Data Tiering
- SAP Managed Tags:
- SAP HANA,
- SAP HANA dynamic tiering,
- SAP HANA smart data integration,
- SAP HANA streaming analytics
Labels:
11 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
299 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
344 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
422 -
Workload Fluctuations
1
Related Content
- Start page of SAP Signavio Process Insights, discovery edition, the 4 pillars and documentation in Technology Blogs by SAP
- QM Notification Configuration from DMC to ERP in Technology Blogs by Members
- Exploring Integration Options in SAP Datasphere with the focus on using SAP extractors - Part II in Technology Blogs by SAP
- Accelerate Business Process Development with SAP Build Process Automation Pre-Built Content in Technology Blogs by SAP
- Analyze Expensive ABAP Workload in the Cloud with Work Process Sampling in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 40 | |
| 25 | |
| 17 | |
| 13 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 |