
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP Cloud Platform Integration - Splitter
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member84
Active Participant
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-08-2019
2:01 PM
A Splitter step allows you to break you message into smaller parts, which can be processed independently.
Cloud Platform Integration has 4 types of Splitters:
Examples with non-XML inputs:
Example with XML input message:
Standard Splitter camel headers: We have 3 standard headers that can be used for getting additional details of the split:

Header value in the trace for my test message containing 10 split messages:

Working Integration Flows can be found at:
WebUI --> Discover View --> Cloud Integration - Exemplars --> Artifacts --> General Splitter – 2 integration flows are embedded here. The Subject of the outgoing mail will help you identify which mail belongs to which integration flow as both will get triggered when you deploy this flow.
WebUI --> Discover View --> Cloud Integration - Exemplars --> Artifacts --> Iterating Splitter – 5 integration flows are embedded here. The Subject of the outgoing mail will help you identify which mail belongs to which integration flow as all 5 will get triggered when you deploy this flow.
WebUI --> Discover View --> Cloud Integration - Exemplars --> Artifacts --> PKCS Splitter
WebUI --> Discover View --> Cloud Integration - Exemplars --> Artifacts --> IDoc Splitter
More details at https://help.sap.com/viewer/368c481cd6954bdfa5d0435479fd4eaf/Cloud/en-US/83e2022f9c014bebab63cb933e6...
Cloud Platform Integration has 4 types of Splitters:
- General Splitter – A splitter that divides a message containing multiple messages into individual messages. This splitter preserves the context of the root nodes with each split message. For clarification, please refer to the example below.

- Name – can be any name for the Splitter
- Expression Type – defines how to split the message. It can have 2 value:
- XPath – XPath of the node that needs to be split. Is relevant for XML messages.
- Line Break – each line is a new split message. Split when a new line character is encountered. It works on both XML and non-XML inputs.
- XPath Expression – XPath of the node that marks each split message.
- Grouping – How many nodes are clubbed together under 1 split message. If this is blank, each node will form 1 split message.
- Streaming - Enable this if you want to start splitting before the entire big message is loaded into memory. The system will first divide the message into chunks and starts splitting the chunks into split messages. This is only relevant if the splitter is the first step after the step that fetches data – otherwise, the content would have already loaded in memory.
- Parallel Processing – check this if you want to process the split messages parallelly. If this is not checked, all split messages shall be processed serially and the order shall be maintained.
- Stop on Exception – check this if you want to stop processing, the moment a split message encounters an exception. In case Parallel Processing is chosen along with Stop on Exception, then the system will not be able to terminate the threads that are already processing – however, no new threads shall be spawned.
- Iterating Splitter – A splitter that divides a message containing multiple messages into individual messages. This splitter considers only the split entity and does not preserve the context of the root nodes. For clarification, please refer to the example below.

This variant supports an additional Expression Type Token. This splits the message (which should be an XML) based on the Keyword mentioned as a token.
- PKCS Splitter – Separates the payload from its signature and provides them as split messages.

- Name – can be any name for the Splitter
- Payload File Name – Name given to the payload part of the message.
- Signature File Name – Name given to the signature part of the message.
- Wrap by Content Info - if you want to wrap signature that is stored as a signed data type into a content info type. The result will be a signature wrapped in signed data type which in turn is wrapped in content info type.
- Payload first – check this to ensure that the payload is the first split message.
- Base64 Payload – check this if you want to encode the payload before returning it.
- Base64 Signature – check this if you want to encode the signature before returning it.
- IDoc Splitter – Divides a group of IDocs into individual IDocs. It only works if either the sender or the receiver channel is an IDoc channel. Here there is no chance to continue processing in case of an exception.

- Name – can be any name for the Splitter
Examples with non-XML inputs:
Input Message: A B C D 1 2 3 4 2 3 4 5 3 4 5 6 4 5 6 7 | Splitter | Special Settings | Output |
| General | 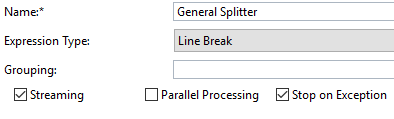 | Following 4 records: · A B C D 1 2 3 4 · A B C D 2 3 4 5 · A B C D 3 4 5 6 · A B C D 4 5 6 7 | |
| Iterating |  | Following 5 records: · A B C D · 1 2 3 4 · 2 3 4 5 · 3 4 5 6 · 4 5 6 7 |
Example with XML input message:
Input Message: <Students> <Student> <Id>1</Id> <Name>Amit</Name> <Class>10</Class> </Student> <Student> <Id>10</Id> <Name>Rahul</Name> <Class>11</Class> </Student> <Student> <Id>2</Id> <Name>Varun</Name> <Class>10</Class> </Student> <Student> <Id>3</Id> <Name>Vijay</Name> <Class>4</Class> </Student> <Student> <Id>4</Id> <Name>Raj</Name> <Class>12</Class> </Student> <Student> <Id>5</Id> <Name>Arjun</Name> <Class>9</Class> </Student> <Student> <Id>6</Id> <Name>Aditya</Name> <Class>5</Class> </Student> <Student> <Id>7</Id> <Name>Arun</Name> <Class>11</Class> </Student> <Student> <Id>8</Id> <Name>Naveen</Name> <Class>1</Class> </Student> <Student> <Id>9</Id> <Name>Akhil</Name> <Class>7</Class> </Student> </Students> | Special Settings | Output |
General  | 10 records of the following format: <?xml version="1.0" encoding="UTF-8"?> <Students> <Student> <Id>7</Id> <Name>Arun</Name> <Class>11</Class> </Student> </Students> | |
General  | 5 records of the following format: <?xml version="1.0" encoding="UTF-8"?> <Students> <Student> <Id>1</Id> <Name>Amit</Name> <Class>10</Class> </Student> <Student> <Id>10</Id> <Name>Rahul</Name> <Class>11</Class> </Student> </Students> | |
Iterating  | 10 records of the following format: <?xml version="1.0" encoding="UTF-8"?> <Student xmlns=""> <Id>10</Id> <Name>Rahul</Name> <Class>11</Class> </Student> | |
Iterating  | 5 records of the following format: <?xml version="1.0" encoding="UTF-8"?> <Student xmlns=""> <Id>4</Id> <Name>Raj</Name> <Class>12</Class> </Student> <Student xmlns=""> <Id>5</Id> <Name>Arjun</Name> <Class>9</Class> </Student> | |
Iterating  | 10 records like: <Student> <Id>5</Id> <Name>Arjun</Name> <Class>9</Class> </Student> |
Standard Splitter camel headers: We have 3 standard headers that can be used for getting additional details of the split:
Header value in the trace for my test message containing 10 split messages:
Working Integration Flows can be found at:
WebUI --> Discover View --> Cloud Integration - Exemplars --> Artifacts --> General Splitter – 2 integration flows are embedded here. The Subject of the outgoing mail will help you identify which mail belongs to which integration flow as both will get triggered when you deploy this flow.
WebUI --> Discover View --> Cloud Integration - Exemplars --> Artifacts --> Iterating Splitter – 5 integration flows are embedded here. The Subject of the outgoing mail will help you identify which mail belongs to which integration flow as all 5 will get triggered when you deploy this flow.
WebUI --> Discover View --> Cloud Integration - Exemplars --> Artifacts --> PKCS Splitter
WebUI --> Discover View --> Cloud Integration - Exemplars --> Artifacts --> IDoc Splitter
More details at https://help.sap.com/viewer/368c481cd6954bdfa5d0435479fd4eaf/Cloud/en-US/83e2022f9c014bebab63cb933e6...
- SAP Managed Tags:
- Cloud Integration
Labels:
4 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
299 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
345 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
427 -
Workload Fluctuations
1
Related Content
- Expanding Our Horizons: SAP's Build-Out and Datacenter Strategy for SAP Business Technology Platform in Technology Blogs by SAP
- Supporting Multiple API Gateways with SAP API Management – using Azure API Management as example in Technology Blogs by SAP
- SAP Build Process Automation Pre-built content for Finance Use cases in Technology Blogs by SAP
- Consuming SAP with SAP Build Apps - Mobile Apps for iOS and Android in Technology Blogs by SAP
- How to use AI services to translate Picklists in SAP SuccessFactors - An example in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 41 | |
| 25 | |
| 17 | |
| 14 | |
| 9 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 6 |