
- SAP Community
- Groups
- Interest Groups
- Artificial Intelligence and Machine Learning
- Blogs
- Retrain your own Customisable Similarity Search in...
Artificial Intelligence and Machine Learning Blogs
Explore AI and ML blogs. Discover use cases, advancements, and the transformative potential of AI for businesses. Stay informed of trends and applications.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-18-2019
7:09 AM
This is the second part of my series blogs about retraining your own Customisable Similarity Search in SAP Leonard Machine Learning Foundation
In this part, we will learn how to retrain a Customisable Similarity Search with your own dataset.
Please follow the steps below for preparation before retraining.
Instead of submitting the retraining job with sapml cli, I would like to use the built-in Swagger UI of the Training Service for Customisable Similarity Search(certainly, you can do the same with any REST client tool, such as POSTMAN or programming. Here I just walk you through the retraining process with the built-in swagger UI, where you can find out the technical details about the service and try it out. And every functional service of mlf embeds its own swagger UI. Next time, if you would like to use a functional service in MLF, and find no much documentation, you can simply use its swagger tool).
Simply, found out the NN_SEARCH_RETRAIN_API_URL from the service key of your mlf instance in SCP CF.

For instance, my NN_SEARCH_RETRAIN_API_URL in my service key of mlf trial instance is https://mlftrial-retrain-ann-api.cfapps.eu10.hana.ondemand.com/api/v2/tabular/ann/indexing. Open this url with browser, its built-in swagger UI shows up as below about this training service.(This is the only public information I can find about this service at the point of writing this blog)

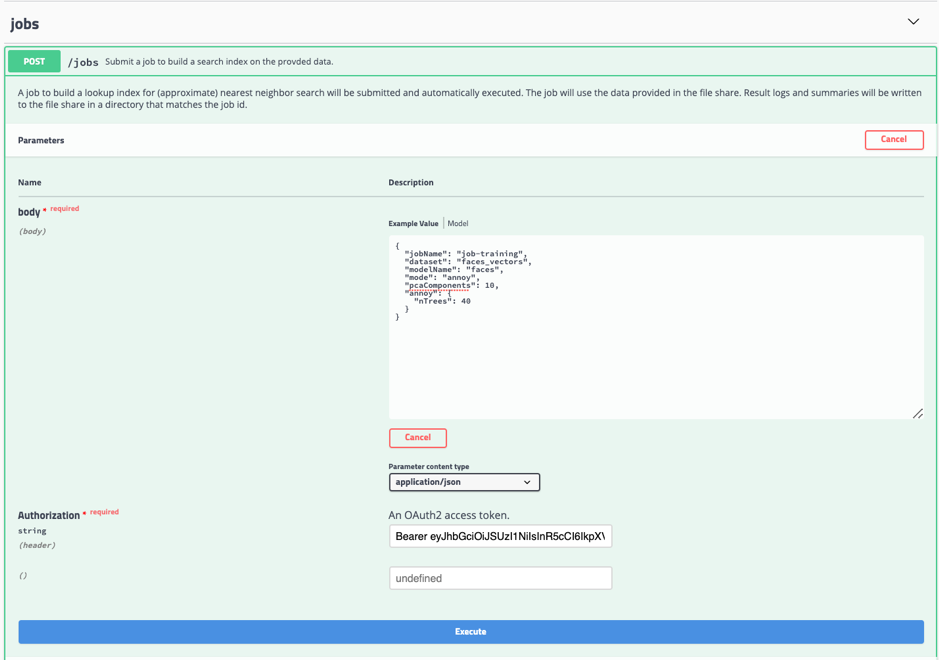
To submit a training job for Customisable Similarity Search, you can make a post to the /jobs endpoint.

Click the Model, you can find the description of parameters for the job. The following are critical parameters for the memory, lookup speed and accuracy.
-mode: exact or annoy
-pcaComponents: Please refer to this blog about Principal Component Analysis.
-annoy.nTree

Click Try it out

In my example, each face feature vector has 128 dimensions, around 400 faces in total, therefore I use the following initial configuration for training. You may need to tune the parameters to find out the best fit of your requirement about lookup speed and accuracy.
And copy the access token("Bearer *******") you have obtained from step 8 to the Authentication field. Then click execute button to submit the job.
As a result, if the retraining job is submitted successfully, the response will return the job id. For any non 202 response code, please refer to the error message for troubleshooting.
With job id, now you can check the job status by make a GET http request the end point /Jobs/{id}. The training job may take some time to complete upon to the size of training dataset, in our case, it is the number of faces and the dimension number of each face feature vector.
Alternatively, you can monitor the job status with the command:

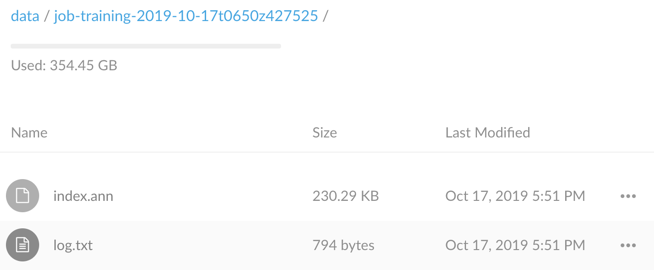
Until the job status become successful, then the deployable artefact index.ann is generated in the job folder in your s3 bucket. Now the model is ready for deployment.
For example, the output of the training job.
To deploy your retrained Similarity Search model to your MLF instance, you can make a POST http request to the /Deployments endpoint.
The request body requires the modelName and modeVersion, for example.

If the deployment request has been submitted successfully, it will return the deployment id.
To monitor the status of deployment, make a GET http request to the /Deployments/{id} endpoint.

When the model deployment status becomes succeeded, then your customisable similarity search model is ready for inference.
In next blog(part 3), we will see how to inference the customisable similarity search.
- Part 1: An overview introduction to Customisable Similarity Search
- Part 2: How to retrain a Customisable Similarity Search?(this blog)
- Part 3: How to inference your Customisable Similarity Search?
- Part 4: Put the pieces together to create a FaceID solution for customer
In this part, we will learn how to retrain a Customisable Similarity Search with your own dataset.
Prepare for the retraining
Please follow the steps below for preparation before retraining.
- Get a Free Trial Account on SAP Cloud Platform
- Install the Cloud Foundry Command Line Interface (CLI)
- Install the Machine Learning foundation plugin for SAP Cloud Platform CLI
- Create a Machine Learning Foundation service instance on the Cloud Foundry environment
- Prepare your environment for retraining
- Prepare a text file of vectors one comma-separated vector per line. The vector could be face or image or document feature vector, which could be extracted from MLF face/image/document feature extraction services, or any vector set with the identical number of dimensions that you want to build the search index.For example, you have extracted a list of face feature vector from customer profile images, each line represents a face with 128-dimension feature vector with comma separator.
folder structure as
face_vectors
-face_vectors.txt
- Upload the feature vector file to your MLF instance bucket
command:
cf sapml fs put <local_path> <remote_path>
#for example:
cf sapml fs put face_vectors/ face_vectors/
- Get your OAuth Access Token using a REST Client
Retrain your own Customisable Similarity Search
Instead of submitting the retraining job with sapml cli, I would like to use the built-in Swagger UI of the Training Service for Customisable Similarity Search(certainly, you can do the same with any REST client tool, such as POSTMAN or programming. Here I just walk you through the retraining process with the built-in swagger UI, where you can find out the technical details about the service and try it out. And every functional service of mlf embeds its own swagger UI. Next time, if you would like to use a functional service in MLF, and find no much documentation, you can simply use its swagger tool).
Get started with the built-in Swagger UI of training service
Simply, found out the NN_SEARCH_RETRAIN_API_URL from the service key of your mlf instance in SCP CF.
For instance, my NN_SEARCH_RETRAIN_API_URL in my service key of mlf trial instance is https://mlftrial-retrain-ann-api.cfapps.eu10.hana.ondemand.com/api/v2/tabular/ann/indexing. Open this url with browser, its built-in swagger UI shows up as below about this training service.(This is the only public information I can find about this service at the point of writing this blog)
Submit a training job for Customisable Similarity Search
To submit a training job for Customisable Similarity Search, you can make a post to the /jobs endpoint.
Click the Model, you can find the description of parameters for the job. The following are critical parameters for the memory, lookup speed and accuracy.
-mode: exact or annoy
-pcaComponents: Please refer to this blog about Principal Component Analysis.
-annoy.nTree
Click Try it out
In my example, each face feature vector has 128 dimensions, around 400 faces in total, therefore I use the following initial configuration for training. You may need to tune the parameters to find out the best fit of your requirement about lookup speed and accuracy.
{
"jobName": "job-training",
"dataset": "faces_vectors",
"modelName": "faces",
"mode": "annoy",
"pcaComponents": 10,
"annoy": {
"nTrees": 40
}
}And copy the access token("Bearer *******") you have obtained from step 8 to the Authentication field. Then click execute button to submit the job.
As a result, if the retraining job is submitted successfully, the response will return the job id. For any non 202 response code, please refer to the error message for troubleshooting.
Checking the status and logs of the training job
With job id, now you can check the job status by make a GET http request the end point /Jobs/{id}. The training job may take some time to complete upon to the size of training dataset, in our case, it is the number of faces and the dimension number of each face feature vector.
Alternatively, you can monitor the job status with the command:
#checking the job status
cf sapml job status
#output the log of job the stdout
cf sapml job logs <job-id> -f
#list the folder structure of your s3 bucket, and find out your job folder
cf sapml fs list
#download the log file
cf sapml fs get /<Your_job_fodler>/log.txt <local_path>
#for example, download the log file of the job to my currect working directory
cf sapml fs get job-training-2019-10-17t0650z427525/log.txt ./
Outputs of the training job
Until the job status become successful, then the deployable artefact index.ann is generated in the job folder in your s3 bucket. Now the model is ready for deployment.
For example, the output of the training job.
Deploy your retrained Similarity Search model
To deploy your retrained Similarity Search model to your MLF instance, you can make a POST http request to the /Deployments endpoint.
The request body requires the modelName and modeVersion, for example.
{
"modelName": "faces",
"modelVersion": "1"
}If the deployment request has been submitted successfully, it will return the deployment id.
To monitor the status of deployment, make a GET http request to the /Deployments/{id} endpoint.
When the model deployment status becomes succeeded, then your customisable similarity search model is ready for inference.
In next blog(part 3), we will see how to inference the customisable similarity search.
- SAP Managed Tags:
- Machine Learning
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
Agents
3 -
AI
5 -
AI Launchpad
2 -
Artificial Intelligence
2 -
Artificial Intelligence (AI)
3 -
Brainstorming
1 -
BTP
1 -
Business AI
2 -
Business Trends
1 -
Cloud Foundry
1 -
Data and Analytics (DA)
1 -
Design and Engineering
1 -
forecasting
1 -
GenAI
1 -
Generative AI
4 -
Generative AI Hub
4 -
Graph
1 -
Language Models
1 -
LlamaIndex
1 -
LLM
2 -
LLMs
2 -
Machine Learning
1 -
Machine learning using SAP HANA
1 -
Mistral AI
1 -
NLP (Natural Language Processing)
1 -
open source
1 -
OpenAI
1 -
Python
2 -
RAG
2 -
Retrieval Augmented Generation
1 -
SAP Build Process Automation
1 -
SAP HANA
1 -
SAP HANA Cloud
1 -
User Experience
1 -
user interface
1 -
Vector Database
3 -
Vector DB
1 -
Vector Similarity
1