
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- 04 Naïve Sherpa : Gathering Data
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
09-09-2019
9:29 PM
Prior Post: https://blogs.sap.com/2019/08/14/03-naive-sherpa-tasking-your-minion/
Next Post: In about a week. (Sorry with TechEd and related activities I've been delayed, try this!)
Side Excursion: https://blogs.sap.com/2019/10/11/the-legend-of-the-headless-chrome-man/
In our last episode we talked about the importance of getting your continuous integration system set up sooner than later. This is important for two reasons. First, so that you can know as soon as possible when your build has broken so that you can address the issue when it's still fresh in mind. The second is so that start thinking about how your solution will propagate from development into production. Until it's in production, you can't charge for it and until you can charge for it, you haven't really tested your value proposition in the real market.
It's important to periodically ask the question. "Is what I'm building going to provide enough value that my customers will be willing to spend X for it?" The quicker you can convince yourself that it is, the better. Along the way, you should be thinking about how much it will cost to not only develop the solution, but also to offer it at scale. The costs for hosting a solution on SAP's Cloud Platform can differ significantly during development and testing as opposed to production. Now is a good time to meet with you SAP sales person/Partner contact to find out what the costs will be in the future once primary development is finished. If you solution is heavy on machine learning, be sure to include budget and resources for monitoring and retraining your algorithm due to the inevitable data drift. Of course with machine learning the question is "How good a result is good enough?" and that's where domain experts come it.
With machine learning being such a hot topic, I hear of aspiring partners that survey the business landscape looking for a pain point where they can apply some machine learning and turn a quick buck. Once of the problems they face is that they are applying a technology to a domain that they don't have a lot of depth in. Think of a production floor manager that has worked up the ranks for 30 years in order to reach their current position. What sort of concerns keep them up at night? What about someone who's job it is to manage a 1000 acre forest in order to optimize yield for a timespan that will stretch beyond that of their grandchildren. How much pesticide should be used on this years seedlings? What fashion trend has the best potential to boost sales next year? What's the risk of a material supplier going out of business and affecting inventories?
You can certainly dream up many others on your own, but the common need is to have someone, or a group of specialized domain experts be able to tell you if your solution is "good enough". Nothing is perfect and when you add machine learning into the mix, you always end up settling for something less than 100%,
The challenge of this series it to find a domain where all the readers are immediately domain experts already.
Back when I was running my own consultancy, I found one of the most frustrating things to do was to create invoices for my clients at the end of the month. There is nothing like spending a full workday combing through notes and emails and your calendar to figure out how many hours I worked on project A on the 3rd of last month. If you bill for your time or not, eventually we've all had the requirement to report on how long it took us to accomplish project B or how long to you think project C will take? I don't know about you, but I tend to focus on the task at hand (to the detriment of all waiting tasks) until I switch to the next task. The problem is that we're thinking about the task and not the time accounting of the task. I got pretty good of keeping hand written notes so that I wouldn't drive my self to crazy once a month, but how often are you working on project A and project B's client/manager calls for a update on their project and you end up talking to them for a while and then when you hand up you do some follow up work and or email and then it's lunch and suddenly you're wondering how many hours was project A and how many for project B? It's not fair to charge client A for time you spent on client B's project or vise-versa. In this day and age, there has got be a better way.
So one big assumption here is that we're all information workers and that much of our "billable" time is spent sitting at a computer or otherwise that what we're doing is mostly trackable. If you are part of a landscaping crew, this may not apply as neatly.
Computers and devices we interact with and the services they connect to are always gathering information about our every action. Shouldn't there be a way to look at those actions and find out when we're working on project A or project B automatically? If I can have a high confidence that my system can determine when I'm working on a particular project, then I can have it automatically account for time I otherwise may have missed. Time spent working on something but never billed is literally money out the window.
Now I can build my own agent that sits on my computer and watches what I'm doing, but what I really want to do is quickly get the root of my value proposition. "Will people be wiling to pay for this?" So for licensing and IP reasons, I can go back and spend the time to write such an agent later if I can find a reasonable proxy now. Enter RescueTime.
I've been using RescueTime for years to keep a general sense of how much time I'm spending on what. I encourage you to check out their offering at RescueTime.com. Now you can say, "Hey they are already doing what you're proposing?" Which is true, but my main reason for using them is to hijack their client agent. The point is that I wanted the domain we're working in to be familiar to everyone and to start gathering data early in the process. This give you something real to work with and mull over while you work on other things.
If you're interested in following my accompanying example project, sign up for a RescueTime account and download and install the agent. (Note: as I write this I'm on a Mac and have had success with the Mac agent. I tried to use the windows agent but had some issues with it working with my proxy setup. I intended to go back and figure out why this is, but for now I'm able to get data with my Mac so it isn't holding me up).

Grab the desktop app for your platform and any browser plugins for browsers that you use regularly.

Follow the directions to get things installed. Once the agent is running, click the preferences to bring up this window.

The agent uses https to communicate to it's backend and provides a way to specify a proxy server where the data can be relayed. If you're behind a firewall or on a corporate network, you'll need to use these settings to point to you own corporate proxy server for things to work. Problem is that you won't be able to capture your date for your own use. You can get it after the fact by using the RescueTime APIs but that doesn't give you timely reporting or the kind of granularity we're looking for. Again, this is a bit of a trick and isn't going to work in all circumstances. When you know the data you can get is enough and worthwhile, you can go back and create your own agent(you'll want to anyway so that you can control it's lifecycle). If you click on the Proxy label, it will expand to show the settings.
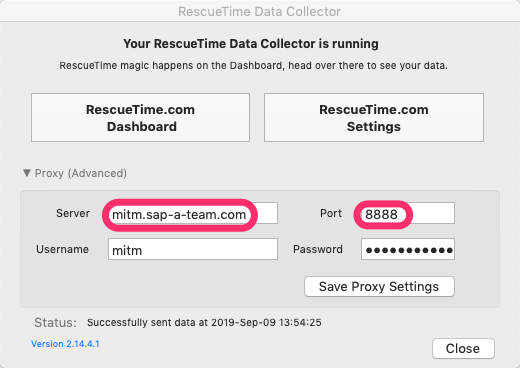
Notice that the server and port have been specified at a minimum and that the proxy requires a user and password. It's been my experience that open proxy servers attract hackers like moths to a flame so it's best not open yourself to that sort of headache.
On the proxy server side, I'm using an open source package called Man In The Middle(mitm) Proxy. You can find details here. https://mitmproxy.readthedocs.io/en/v2.0.2/
This proxy server is written in Python and allows you to extend it with Python as well. I've created a separate git repo to manage the server portion of this project. You can find it here.
https://github.com/alundesap/tap_rescuetime
It's really just a single python script that modifies some things coming back from the server and taps into the event stream being send to the server so that we can send it to our own HANA server.
You can look at the details in the repo, but one thing that may be confusing is that I abstract all the server connection info into the script's environment and then read it from there. The reason I do this in this way is so that my code is similarly structured to my code running in Cloud Foundry. One thing we'll talk more on later is which HANA Deploy Infrastructure(HDI) container/schema is being targeted. As I deploy to more than one space it's important to control which one is getting the live data. More on this later. Check out the README file for details on how to set the environment and call mitmdump with the script. If you are using mitmproxy to monitor the action, make sure to use the linux screen tool to make sure your proxy stays running when your terminal detaches.
While the WebIDE Full-Stack has a convenient interface for doing simple queries, there is a more capable tool for doing some initial analysis in HANA Studio (or Eclipse with the HANA plugins). I'm not going to describe all the setup here, but instead jump to some screen shots in eclipse.
I have a DB user named ML_USER that I've granted access to my CONCILE_V0_DEV container by calling the following stored procedure.
This allows me to see that container in Eclipse. I've browsed to the view RESCUETIME_SLICES_DURATION and right clicked on it to "Open Data Preview". From here click on the Analysis tab and dragged the Numeric DURATION to the Values axis and DOCUMENT to the Lables axis.


If you zoom in on the data you see there are a couple of applications where I'm spending a significant amount of time. The point here is to start to get a "feel" for your data. Again, since this is your own data and you're the domain expert of yourself, the data should confirm what you already know(spending too much time on Twitter?). I encourage you to play around with this if you've got it set up. For a more detailed analysis, we should look at the data within SAP Analytics Cloud which is the topic of the next episode.
Since our last episode, I've been working on making sure that the accompanying application is set up for real-world mutltenant use. This includes find an easy way for a user of the service to train against their own data set. In order to keep things simple, I intend to use a websocket connection to a browser based client. They way, if a new scoring is performed, the client can get update without any user input(or polling). While I'm still working out the details, I have a simple chat application ported and with some message parsing logic, it will become the basis for this 2-way functionality. If you look at the code under the post04 tag you'll see a chat folder that contains this module's code.
One of the things I'm looking at in parallel to this blog series is how to utilize SAP Data Intelligence. While this new offering has been announced, more detail will come in a couple weeks after SAP's TechEd conference and the Strata conference. Since I know I'll want to use Python to drive my machine learning, I'm looking at Data Intelligence as a platform to manage various ML/AI jobs for me. In the meantime I've set up Jupyter Notebooks in the application under the jupyter folder. More on this as details emerge. Again, a major decision about our service offering is if people will pay for the advantage it's offering at a price that's less that what it costs to provide. Keeping the landspace simpler helps to keep costs down.
If all goes as planned, I'd like to make this service offering available as a self service offering. This means that customers should be able to provide some account information, create their own subaccount(and subdomain), link their custom domain name, and enter their billing information(and get billed) all without any need for manual steps. I'm looking at two things that might fit this need. The first is SAP Intelligent Robotic Process Automation(iRPA). The second is a scriptable headless browser function called PhantomJS. I've gotten PhantomJS installed in the phantom folder but it's currently not building with the rest of the application since it's sourced from a Docker container.
As mentioned above I'd like to get into the benefits of using SAP Analytic Cloud for doing an initial look at the data we've captured. Since we're using live data, I will hook up a HANA Live Connection but that required implementing another interface(INA). For the curious, look at the HANA Analytic Adapter.
Or check out Phil's videos.
https://www.youtube.com/watch?v=V0XL8x_1Pcs&list=PLkzo92owKnVxm3TMoUliy5b5UO1G5GP50&index=16
Until then...
-Andrew (Your Naïve Sherpa)
GitHub Project:
https://github.com/alundesap/conciletime
https://github.com/alundesap/conciletime/tree/post03
Prior Posts:
https://blogs.sap.com/2019/07/22/00-naive-sherpa-meet-the-naive-sherpa/
https://blogs.sap.com/2019/08/02/01-naive-sherpa-the-journey/
https://blogs.sap.com/2019/08/07/02-naive-sherpa-project-conciletime/
https://blogs.sap.com/2019/08/14/03-naive-sherpa-tasking-your-minion/
Next Post: In about a week.
Next Post: In about a week. (Sorry with TechEd and related activities I've been delayed, try this!)
Side Excursion: https://blogs.sap.com/2019/10/11/the-legend-of-the-headless-chrome-man/
In our last episode we talked about the importance of getting your continuous integration system set up sooner than later. This is important for two reasons. First, so that you can know as soon as possible when your build has broken so that you can address the issue when it's still fresh in mind. The second is so that start thinking about how your solution will propagate from development into production. Until it's in production, you can't charge for it and until you can charge for it, you haven't really tested your value proposition in the real market.
Value Proposition.
It's important to periodically ask the question. "Is what I'm building going to provide enough value that my customers will be willing to spend X for it?" The quicker you can convince yourself that it is, the better. Along the way, you should be thinking about how much it will cost to not only develop the solution, but also to offer it at scale. The costs for hosting a solution on SAP's Cloud Platform can differ significantly during development and testing as opposed to production. Now is a good time to meet with you SAP sales person/Partner contact to find out what the costs will be in the future once primary development is finished. If you solution is heavy on machine learning, be sure to include budget and resources for monitoring and retraining your algorithm due to the inevitable data drift. Of course with machine learning the question is "How good a result is good enough?" and that's where domain experts come it.
Importance of being and expert in your domain.
With machine learning being such a hot topic, I hear of aspiring partners that survey the business landscape looking for a pain point where they can apply some machine learning and turn a quick buck. Once of the problems they face is that they are applying a technology to a domain that they don't have a lot of depth in. Think of a production floor manager that has worked up the ranks for 30 years in order to reach their current position. What sort of concerns keep them up at night? What about someone who's job it is to manage a 1000 acre forest in order to optimize yield for a timespan that will stretch beyond that of their grandchildren. How much pesticide should be used on this years seedlings? What fashion trend has the best potential to boost sales next year? What's the risk of a material supplier going out of business and affecting inventories?
You can certainly dream up many others on your own, but the common need is to have someone, or a group of specialized domain experts be able to tell you if your solution is "good enough". Nothing is perfect and when you add machine learning into the mix, you always end up settling for something less than 100%,
The challenge of this series it to find a domain where all the readers are immediately domain experts already.
Everyone is an expert on themselves.
Back when I was running my own consultancy, I found one of the most frustrating things to do was to create invoices for my clients at the end of the month. There is nothing like spending a full workday combing through notes and emails and your calendar to figure out how many hours I worked on project A on the 3rd of last month. If you bill for your time or not, eventually we've all had the requirement to report on how long it took us to accomplish project B or how long to you think project C will take? I don't know about you, but I tend to focus on the task at hand (to the detriment of all waiting tasks) until I switch to the next task. The problem is that we're thinking about the task and not the time accounting of the task. I got pretty good of keeping hand written notes so that I wouldn't drive my self to crazy once a month, but how often are you working on project A and project B's client/manager calls for a update on their project and you end up talking to them for a while and then when you hand up you do some follow up work and or email and then it's lunch and suddenly you're wondering how many hours was project A and how many for project B? It's not fair to charge client A for time you spent on client B's project or vise-versa. In this day and age, there has got be a better way.
Hijacking RescueTime.
So one big assumption here is that we're all information workers and that much of our "billable" time is spent sitting at a computer or otherwise that what we're doing is mostly trackable. If you are part of a landscaping crew, this may not apply as neatly.
Computers and devices we interact with and the services they connect to are always gathering information about our every action. Shouldn't there be a way to look at those actions and find out when we're working on project A or project B automatically? If I can have a high confidence that my system can determine when I'm working on a particular project, then I can have it automatically account for time I otherwise may have missed. Time spent working on something but never billed is literally money out the window.
Now I can build my own agent that sits on my computer and watches what I'm doing, but what I really want to do is quickly get the root of my value proposition. "Will people be wiling to pay for this?" So for licensing and IP reasons, I can go back and spend the time to write such an agent later if I can find a reasonable proxy now. Enter RescueTime.
I've been using RescueTime for years to keep a general sense of how much time I'm spending on what. I encourage you to check out their offering at RescueTime.com. Now you can say, "Hey they are already doing what you're proposing?" Which is true, but my main reason for using them is to hijack their client agent. The point is that I wanted the domain we're working in to be familiar to everyone and to start gathering data early in the process. This give you something real to work with and mull over while you work on other things.
Getting Data early.
If you're interested in following my accompanying example project, sign up for a RescueTime account and download and install the agent. (Note: as I write this I'm on a Mac and have had success with the Mac agent. I tried to use the windows agent but had some issues with it working with my proxy setup. I intended to go back and figure out why this is, but for now I'm able to get data with my Mac so it isn't holding me up).
Grab the desktop app for your platform and any browser plugins for browsers that you use regularly.
Follow the directions to get things installed. Once the agent is running, click the preferences to bring up this window.
The agent uses https to communicate to it's backend and provides a way to specify a proxy server where the data can be relayed. If you're behind a firewall or on a corporate network, you'll need to use these settings to point to you own corporate proxy server for things to work. Problem is that you won't be able to capture your date for your own use. You can get it after the fact by using the RescueTime APIs but that doesn't give you timely reporting or the kind of granularity we're looking for. Again, this is a bit of a trick and isn't going to work in all circumstances. When you know the data you can get is enough and worthwhile, you can go back and create your own agent(you'll want to anyway so that you can control it's lifecycle). If you click on the Proxy label, it will expand to show the settings.
Notice that the server and port have been specified at a minimum and that the proxy requires a user and password. It's been my experience that open proxy servers attract hackers like moths to a flame so it's best not open yourself to that sort of headache.
On the proxy server side, I'm using an open source package called Man In The Middle(mitm) Proxy. You can find details here. https://mitmproxy.readthedocs.io/en/v2.0.2/
This proxy server is written in Python and allows you to extend it with Python as well. I've created a separate git repo to manage the server portion of this project. You can find it here.
https://github.com/alundesap/tap_rescuetime
It's really just a single python script that modifies some things coming back from the server and taps into the event stream being send to the server so that we can send it to our own HANA server.
You can look at the details in the repo, but one thing that may be confusing is that I abstract all the server connection info into the script's environment and then read it from there. The reason I do this in this way is so that my code is similarly structured to my code running in Cloud Foundry. One thing we'll talk more on later is which HANA Deploy Infrastructure(HDI) container/schema is being targeted. As I deploy to more than one space it's important to control which one is getting the live data. More on this later. Check out the README file for details on how to set the environment and call mitmdump with the script. If you are using mitmproxy to monitor the action, make sure to use the linux screen tool to make sure your proxy stays running when your terminal detaches.
Start looking at it (what's available now) defer SAC for later.
While the WebIDE Full-Stack has a convenient interface for doing simple queries, there is a more capable tool for doing some initial analysis in HANA Studio (or Eclipse with the HANA plugins). I'm not going to describe all the setup here, but instead jump to some screen shots in eclipse.
I have a DB user named ML_USER that I've granted access to my CONCILE_V0_DEV container by calling the following stored procedure.
CALL "CONCILE_V0_DEV"."db_grant_role"(
IN_USER => 'ML_USER',
IN_ROLE => 'conciletime_admin',
EX_MESSAGE => ?
);This allows me to see that container in Eclipse. I've browsed to the view RESCUETIME_SLICES_DURATION and right clicked on it to "Open Data Preview". From here click on the Analysis tab and dragged the Numeric DURATION to the Values axis and DOCUMENT to the Lables axis.
If you zoom in on the data you see there are a couple of applications where I'm spending a significant amount of time. The point here is to start to get a "feel" for your data. Again, since this is your own data and you're the domain expert of yourself, the data should confirm what you already know(spending too much time on Twitter?). I encourage you to play around with this if you've got it set up. For a more detailed analysis, we should look at the data within SAP Analytics Cloud which is the topic of the next episode.
Training in a Multitenant World.
Since our last episode, I've been working on making sure that the accompanying application is set up for real-world mutltenant use. This includes find an easy way for a user of the service to train against their own data set. In order to keep things simple, I intend to use a websocket connection to a browser based client. They way, if a new scoring is performed, the client can get update without any user input(or polling). While I'm still working out the details, I have a simple chat application ported and with some message parsing logic, it will become the basis for this 2-way functionality. If you look at the code under the post04 tag you'll see a chat folder that contains this module's code.
SAP Data Intelligence (Undecided)
One of the things I'm looking at in parallel to this blog series is how to utilize SAP Data Intelligence. While this new offering has been announced, more detail will come in a couple weeks after SAP's TechEd conference and the Strata conference. Since I know I'll want to use Python to drive my machine learning, I'm looking at Data Intelligence as a platform to manage various ML/AI jobs for me. In the meantime I've set up Jupyter Notebooks in the application under the jupyter folder. More on this as details emerge. Again, a major decision about our service offering is if people will pay for the advantage it's offering at a price that's less that what it costs to provide. Keeping the landspace simpler helps to keep costs down.
Scripting Subscriber Lifecycle tasks.
If all goes as planned, I'd like to make this service offering available as a self service offering. This means that customers should be able to provide some account information, create their own subaccount(and subdomain), link their custom domain name, and enter their billing information(and get billed) all without any need for manual steps. I'm looking at two things that might fit this need. The first is SAP Intelligent Robotic Process Automation(iRPA). The second is a scriptable headless browser function called PhantomJS. I've gotten PhantomJS installed in the phantom folder but it's currently not building with the rest of the application since it's sourced from a Docker container.
Next time. Value of live data and SAC.
As mentioned above I'd like to get into the benefits of using SAP Analytic Cloud for doing an initial look at the data we've captured. Since we're using live data, I will hook up a HANA Live Connection but that required implementing another interface(INA). For the curious, look at the HANA Analytic Adapter.
Analytics adapter for SAP HANA extended application services, advanced model
Or check out Phil's videos.
https://www.youtube.com/watch?v=V0XL8x_1Pcs&list=PLkzo92owKnVxm3TMoUliy5b5UO1G5GP50&index=16
Until then...
-Andrew (Your Naïve Sherpa)
GitHub Project:
https://github.com/alundesap/conciletime
https://github.com/alundesap/conciletime/tree/post03
Prior Posts:
https://blogs.sap.com/2019/07/22/00-naive-sherpa-meet-the-naive-sherpa/
https://blogs.sap.com/2019/08/02/01-naive-sherpa-the-journey/
https://blogs.sap.com/2019/08/07/02-naive-sherpa-project-conciletime/
https://blogs.sap.com/2019/08/14/03-naive-sherpa-tasking-your-minion/
Next Post: In about a week.
- SAP Managed Tags:
- Machine Learning,
- SAP BTP, Cloud Foundry runtime and environment,
- Research and Development
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
92 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
298 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
344 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
421 -
Workload Fluctuations
1
Related Content
- Convert multiple xml's into single Xlsx(MS Excel) using groovy script in Technology Blogs by Members
- Setup of Synthetic User Monitoring in SAP Cloud ALM in Technology Blogs by Members
- Asset Manager 2210 Extend SAMXXXX_WORKORDER_GENERIC by new entity - zombie entries in List in Technology Q&A
- Workload Analysis for HANA Platform Series - 1. Define and Understand the Workload Pattern in Technology Blogs by SAP
- Workload Analysis for HANA Platform Series - 2. Analyze the CPU, Threads and Numa Utilizations in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 39 | |
| 25 | |
| 17 | |
| 13 | |
| 7 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |