
- SAP Community
- Groups
- Interest Groups
- Application Development
- Blog Posts
- Refactoring an ABAP Include Monolith
Application Development Blog Posts
Learn and share on deeper, cross technology development topics such as integration and connectivity, automation, cloud extensibility, developing at scale, and security.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
nothafts
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
09-02-2019
2:39 PM
Motivation
Usually, in R/3 you see a common pattern: Spaghetti-Code within of program includes of a certain function group. Especially, in case of extensions of SAP standard this was required and caused the creation of big monoliths, whereby more than 10.000 lines of code was not rarely.
In addition, another problem as consequence is that only one developer could do a change of the source code, because the whole function group was locked. I would also assume that those changes could not be tested very well. Therefore, the developer would not be aware of any side effects.
This document tries to help you solving that problem.
Objectives
I would like to define the following objectives:
- Code has to be changeable
- The developers have to be enabled to implement requirements w/o any risk of side effects to existing functionality and also to work in parallel
- Not all user have to be affected by the refactoring è reduce risk of complete failure
Non-Objectives:
- The creation of micro services
- Leverage (S/4)HANA features
- Only refactor code, which is really being used (see SCMON/simplification process)
Context
- Users (also machines, sensors) use the coding in production. We have to be careful!
- Probably, the quality of the source code is very low. I would expect there:
- Bad identifiers for variables/constants
- Commented coding
- Literals
- Spaghetti-Code / redundant coding
- Call of subroutines (PERFORM)
- Use of “dirty-assign” to other function groups
- Direct database accesses
Procedure
Apparently, step „zero“ is to get the permission and the budget/time for such a big refactoring.
Also mission-critical is the moment to begin with the refactoring: I would recommend starting before the conversion to S/4HANA, because the conversion could rise syntax errors or other incompatibilities. Unfortunately, not every feature of ABAP unit will be supported on lower NetWeaver releases. However, if you could transfer the old coding w/o any problems to S/4HANA, you can start there as well.
Generally, I recommend as IDE the ABAP Development Tools (ADT) to perform the refactoring, as it is superior to classic SAP GUI.
- Freeze coding: Only very urgent hotfixes are allowed. Further development is prohibited
- Create a backup: You should create a snapshot of the current coding (e.g. via git). With that you have a “plan B” and maybe can go back, if something goes completely wrong
- Do simple refactoring: Rename variables, introduce constants, delete commented code à should be possible w/o any risk
- Prepare test data:
- Create a testgroup with appropriate test user: In the best case, you have a wide diversity and involve several departments of the company to achieve a good test data quality
- Create a clone of the include in an ABAP OO class (let’s call it simply “agent”)
- Provide a simple entry method, like “execute” to call it from the original function group
- Encapsulate all dependent data of the original function group. I would recommend to create a dedicated class for that (name: “Origin Function Group API”)
- Calls to local subroutines also have to be extracted to the Origin Function Group API. Reason: Probably they would operate on the data of the function group
- Encapsulate external accesses in the agent: Calls of the same function modules (incl. dirty assigns) and access to database tables should be refactored into appropriate classes. Let us call them “DB Access”, respectively “Other Function Modules API”.
In order to avoid a direct coupling you should work with ABAP OO interface. You could also create the instances of the classes by using a “Dependency Lookup” - Integrate a “Test Spy” into the classes: The spy is an additional class, which logs the input- and output parameter of the method calls. I would recommend to use one Spy for all classes, because you can also log the sequence of method calls. The log data should be stored into particular database tables or in an eCATT-test data container; I prefer the eCATT-container.
- Integrate agent into origin function group with a user parameter:
- Once the users of the test group have activated their user parameter, they should do their usual business
- In addition I also recommend to activate the code coverage analyzer for the test group in order to find also some blind spots
- Dependent of the program include, you should record the test data appropriately. For example, if the coding is only relevant at year end closing, you should consider this time period in your recording
- Until now, some coding already has been changed, so there could be a small risk, that you have made some mistakes. Therefore, the test group should also keep an eye on the functional correctness. Of course, in case of any errors, they have to be fixed immediately.
Intermediate result:
- There is no chaotic read to the function group’s data. Instead you use an API
- Also other accesses (database tables, other function modules) are (well) defined now
- You are able to create test data for the automatic testing. This is the fundament for a more complex refactoring, which we want to perform in the next steps
Class diagram (high level):
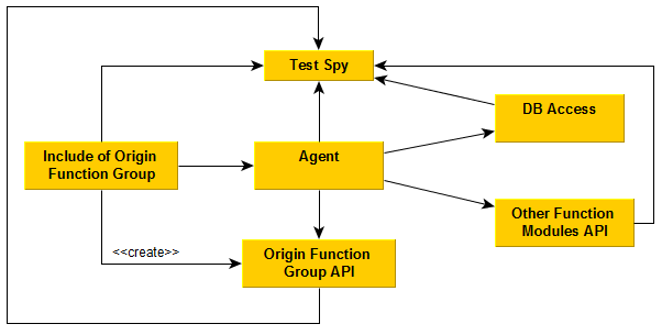
Hint: During the recording, you as a developer could already think about, how to split this big agent class into appropriate business function classes. Surely, you could start with the first test data a prototype in a local copy of the agent. (see also the next steps)
- Provide unit test infrastructure for the agent class: Dependencies have to be „mocked“ and provided with the data from the test spy (expected input/output data, calling sequence)
- The unit test should be successfully at the first time: If not, maybe you need to adjust the unit test infrastructure or one of the other classes
- Start the complex refactoring: Extract method/classes (see also „Separation of Concerns“-principle). You should also use ABAP OO interfaces to decouple from the concrete classes. Recommendation: Start first with extracting some method. By the name of the methods, you could see if there are common aspects (e.g. country specific) and extract them to new classes, so called business functions
- Extract parts of the “global” test data from the spy to the business function: At the agent, all test data for all business functions are maintained, but this raises also the complexity. Moreover, you would not be able to implement new requirements in parallel. Therefore, you have to extract the relevant test data also the business functions unit test. Usually, the redundant test data is obsolete and you can remove them from the eCATT test data container.
- The agent only orchestrates calls to the business functions: The unit test infrastructure should only test the agent, not the business functions itself
- Adapt test spy, if required. I recommend, to create after step 5 to create a new test data container, as a preparation for the next phase
- Extend your test user group with further participants / departments: Now, you can act iteratively and repeat the relevant steps from before
- Finalize refactoring and clean up: After the previous step, where you could extend the test group as long as you would like to do (dependent on risk estimation, personal security feeling, time), you have to remove the test spies. At this moment, you do not record any test data. Moreover, you have to activate the new logic for all user
Final Result

- Classes with clear defined responsibilities: Better to understand the coding
- Modularization allows testing with ABAP Unit: Fearless change of existing code
- Further development in parallel mode possible due to separation of concerns into multiple OO classes
- Also an additional benefit: Eases conversion to S/4HANA due to a better code base, because of automated tests, understandable coding and elimination of redundant code
What do you think? Do you have other ideas/best practices? Please share your remarks in the comments. Thanks a lot.
- SAP Managed Tags:
- ABAP Development
27 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
A Dynamic Memory Allocation Tool
1 -
ABAP
8 -
abap cds
1 -
ABAP CDS Views
14 -
ABAP class
1 -
ABAP Cloud
1 -
ABAP Development
4 -
ABAP in Eclipse
1 -
ABAP Keyword Documentation
2 -
ABAP OOABAP
2 -
ABAP Programming
1 -
abap technical
1 -
ABAP test cockpit
7 -
ABAP test cokpit
1 -
ADT
1 -
Advanced Event Mesh
1 -
AEM
1 -
AI
1 -
API and Integration
1 -
APIs
8 -
APIs ABAP
1 -
App Dev and Integration
1 -
Application Development
2 -
application job
1 -
archivelinks
1 -
Automation
4 -
BTP
1 -
CAP
1 -
CAPM
1 -
Career Development
3 -
CL_GUI_FRONTEND_SERVICES
1 -
CL_SALV_TABLE
1 -
Cloud Extensibility
8 -
Cloud Native
7 -
Cloud Platform Integration
1 -
CloudEvents
2 -
CMIS
1 -
Connection
1 -
container
1 -
Debugging
2 -
Developer extensibility
1 -
Developing at Scale
4 -
DMS
1 -
dynamic logpoints
1 -
Eclipse ADT ABAP Development Tools
1 -
EDA
1 -
Event Mesh
1 -
Expert
1 -
Field Symbols in ABAP
1 -
Fiori
1 -
Fiori App Extension
1 -
Forms & Templates
1 -
IBM watsonx
1 -
Integration & Connectivity
10 -
JavaScripts used by Adobe Forms
1 -
joule
1 -
NodeJS
1 -
ODATA
3 -
OOABAP
3 -
Outbound queue
1 -
Product Updates
1 -
Programming Models
13 -
Restful webservices Using POST MAN
1 -
RFC
1 -
RFFOEDI1
1 -
SAP BAS
1 -
SAP BTP
1 -
SAP Build
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP CodeTalk
1 -
SAP Odata
1 -
SAP UI5
1 -
SAP UI5 Custom Library
1 -
SAPEnhancements
1 -
SapMachine
1 -
security
3 -
text editor
1 -
Tools
16 -
User Experience
5
Top kudoed authors
| User | Count |
|---|---|
| 6 | |
| 5 | |
| 3 | |
| 3 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 1 | |
| 1 |