Part 3 of 5 in the What Is Data Intelligence blog series.
Apart from the recent hype around Machine Learning (ML), many companies are seeing ML as a lever to optimize their business. Predicting customer churn, making intelligent product recommendations, forecasting product quality or completing visual product recognition are just a few typical use cases of enterprise ML. On the other hand, many enterprises struggle with ML and the various pitfalls, as outlined in this
article. According to analysts it takes roughly 2 months just to get a single predictive model from research to production.
But why is it so hard to scale ML across an organization? This often depends on three cohesive capabilities:
- Managing the data
- Managing the design
- Managing the deployment
Let’s focus on the latter two and let’s take a closer look at how ML models are typically developed.
Crafting ML models is a highly iterative process, as illustrated by the Cross-Industry Standard Process for Data Mining (
CRISP-DM) approach. You prepare data, do experiments and then come up with an initial model version. Until you have created the ideal model, you might have generated many versions of data, experiments and models. Keeping track of all this is often a huge challenge. On the other hand, transparency (“which models exist in my organization”) and auditability (“which model and data lead to a prediction”) represent key necessities for enterprise machine learning.
Deploying and maintaining ML models is also not an easy task at all. How can you easily provide a model, for instance via an API, so that it can be consumed by applications in a scalable and secure manner? How can you monitor the quality of models and trigger a re-training in case needed? How can you manage the hand-over from data scientists to IT operations back and forth without frictions?
SAP Data Intelligence is aimed at solving these tricky hurdles. It represents a unified and integrated tool to cover the entire process: from connecting, understanding and preparing data to creating, deploying and operating ML models.
[caption id="attachment_1014845" align="aligncenter" width="660"]
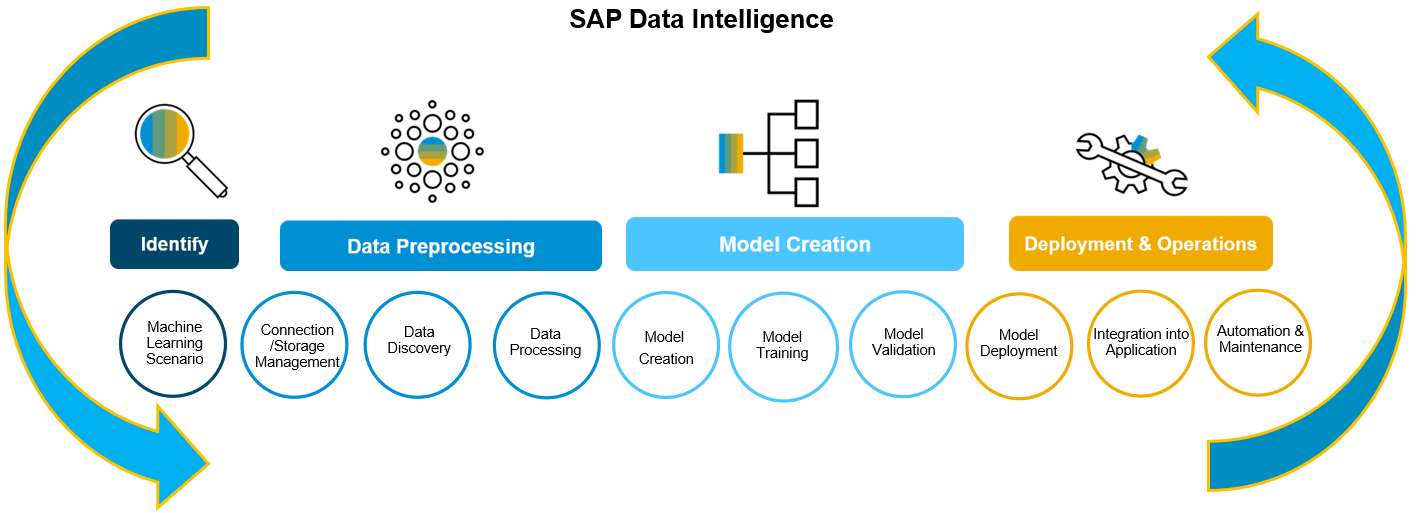
SAP Data Intelligence covers the entire ML lifecycle from end-to-end[/caption]
You also benefit from the unique and deep integration into the existing SAP landscape. Systems such as a SAP Business Warehouse or S/4HANA can easily be connected and embedded into data flows. This is crucial, since those often represent the IT backbone to power the core business processes of many organizations. We are also working on capabilities to manage ML scenarios directly from within SAP applications such as S/4HANA. This will enable further simplification and standardization. Use Data Intelligence as a common repository and execution engine, but control all that with ease from the business application.
SAP Data Intelligence provides specific support among others for data engineers, data architects, data scientists and IT operations:
- Data engineers and architects can connect, discover and process any type of data (e.g. structured, unstructured, streaming) and volume. Furthermore, they can visually build data flows and data pipelines to orchestrate distributed data landscapes.
- Data scientists can use their ML framework of choice (e.g. Python, TensorFlow, R or HANA ML) and design models with interactive Jupyter Notebooks. They can manage all the different ML elements e.g. data sets, pipelines and model versions in one central place.
- IT operations can easily deploy, monitor and re-train all models from within a unified control center and at scale.
[caption id="attachment_1014847" align="aligncenter" width="660"]

SAP Data Intelligence provides a comprehensive view on all ML-related assets, such as data sets, notebooks, and models.[/caption]
Enabling transparency and collaboration among those is now one of the essential ingredients to scale ML from research to production. Think of it as an assembly line not for industrial production, but for AI and ML: supporting specific AI-related expert work and at the same time linking all of it together in an integrated manner. In doing that, SAP Data Intelligence allows organizations to move from a fractured approach – often dominated by data sprawl and diverse tool set – to a continuous and integrated operation.
Learn More
