In this blog, we will see how we can do processing of large files in integration flows and avoid performance and memory related issues. Handling huge text files (which are either have extension 'csv' or fixed length) is a challenge in CPI (SAP Cloud Platform Integration) for processing. In CPI usually, scenarios comes where requirement is to process an input csv or any other character delimited text file. These files are of huge size compared to when we get data as xml or json format.
Mostly before converting data to xml format that is required for mapping, we do read them via groovy scripts to manipulate the data and we also need to convert incoming data into string format. Here, during converting into string format leads to memory issues.
In this blog post, the purpose is to provide alternate ways to handle them, not only how to read large files but also how to manipulate the data in required format.
The input file data can have “,” or tab or “|” delimiters or is of fixed length, which creates additional complexity as first data need to be read, sorted, converted to XML (for mapping to target structure format). Also, most of the time we have to perform some validations steps beforehand, to avoid processing of invalid data.
Integration flow starts with scripts by converting the input payload to String Object. String Content= message.getBody(String) // file data
But in case of huge data, the above line converts the whole data to String and stores them in memory and consumes big size. So, performing any operation on String Content by creating or replacing with new String Objects consumes more space. This also has the probability of having – OutOfMemoryError Exception.

Solution: The better practice is to handle them as stream. There are two class given that can handle stream data. java.io.Reader -> handles data as character or text stream and java.io.InputStream -> handles data as raw or binary stream. Mostly the Reader class is easier to use as it returns data as text/character (UTF-16) rather than raw binary data (UTF-8). Below the code in Groovy Script via java.io.Reader to read the data and best approach of doing a replace functionality.
Reading Data:
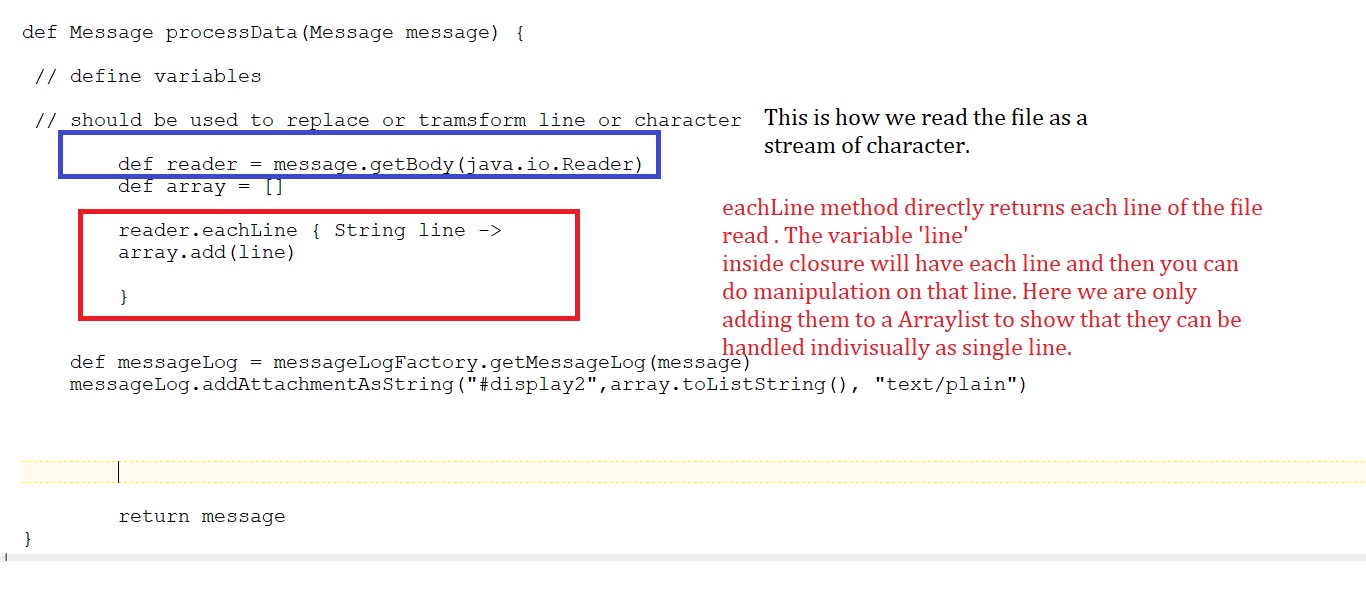
Approach of doing a replace while reading it as Stream

Conclusion: This blog is helpful to build required groovy scripts in SAP Cloud Platform Integration Flows. There are multiple cases, need to be handled for large text files in csv or in another delimited format, which requires reading the entire file. These types of business requirement can be achieved with the solution given in this blog.
