
- SAP Community
- Products and Technology
- Enterprise Resource Planning
- ERP Blogs by SAP
- B1i GY302-Adapter, Mk I: The Basics
Enterprise Resource Planning Blogs by SAP
Get insights and updates about cloud ERP and RISE with SAP, SAP S/4HANA and SAP S/4HANA Cloud, and more enterprise management capabilities with SAP blog posts.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member45
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
07-29-2019
12:41 PM

This blog post is about to explain how the GY302-adapter for B1iP is done and how it internally works. It may serve as a starting point and blueprint for own sensor-prone B1iP related adapter development. As there is some overall information to spread, the post is split into two parts: This first part is about to understand the very environment for the adapter whereas the 2nd part shows the concrete things to be done.
The Hardware Implications
The adapter of question connects the GY302 sensor that in fact is just another convenient Arduino Sensor to the world and B1iP. The sensor is about to measure the light intensity it is exposed to in the unit of Lux. Concretely, the whole sensor is made up as a breakout board that contains the necessary electronic auxiliary plumbing components and - most often - a prominent particular central sensor component itself. In this case, it is the BH1750 light sensor (the "black bug" in the center of the board). The "birdseed" styled components around it just only are for plumbing in order to conveniently access the sensor from the outside - they do not add any special meaning concerning the overall software-access to the sensor. Professional manufacturers of electronic devices would just take this small "bug" and embed it to an own designed board layout (e.g. on the main-board of a smartphone). Knowing that, you see how compact things can get accomplished.
Getting this sensor connected to B1iP means first to have a suitable hardware around that is able to run B1iP. For sensors or similar stuff, a natural choice would be to run B1iP on a Raspberry PI, as this hardware also allows to electrically connect such a sensor in an easy way (this concrete sensor is accessible using the I2C Bus). Therefore, it is good to know that also B1iP supports accessing devices via I2C (and beside of that, also e.g. via SPI or GPIO or Serial Port on that hardware).
The relevant B1iP Basics
In the past, writing an Adapter for B1iP always meant to use B1iP's adapter framework, choose a suitable adapter type out of it and in turn do the implementation of the adapter itself in Java. In turn, the ready adapter had to be registered in B1iP for usage (what is pretty easy to do though). The overall drawback of this approach though is that the prominent programming-model hats on top of B1iP (e.g. B1if, /dev, ...) do not know about this custom-built adapter and therefore also cannot leverage it. So it is with the SLD (the paramount System Landscape Directory of B1i). That all makes the effective usage for such an adapter a bit more cumbersome than it should.
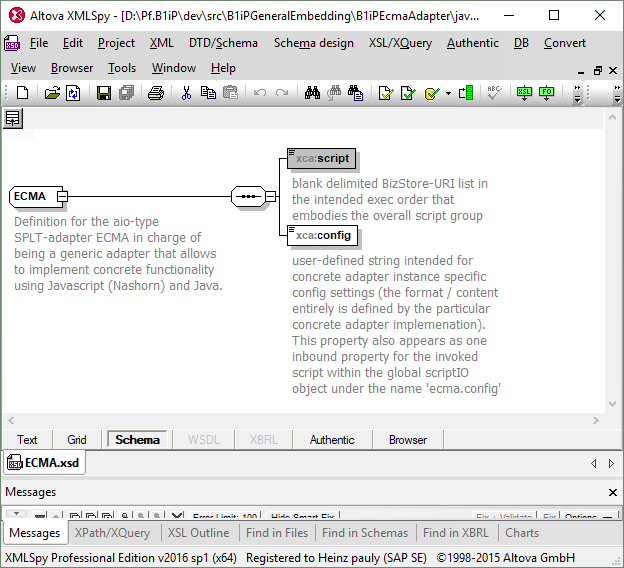
But there is a new kid on the block making things easier in that adapter development area as well: It is the new B1iP ECMA-Adapter (that technically is available for all platforms B1iP supports). This new adapter can be seen as a kind of "meta-adapter" or "adapter-shell" that allows to easily implement and in turn use concrete adapters that might come up to be required in a project. As the adapter also is well known to the programming-model hats of question and to the SLD, using it for concrete adapter implementations has the benefit to be able to immediately bring them up to "full B1i fidelity". Concretely, the ECMA-adapter has unified configuration properties (that is why it also always is known to the SLD). One of this properties is a user-definable string that allows to pass configuration information in a way the adapter implementation chooses to make sense (it works a bit like a JDBC connection URL concerning the intent).
The instance specific configuration properties of the B1iP ECMA Adapter
But as the instance config properties already show up, there is another special thing to say about this adapter (what is probably even THE thing to say about it):
The adapter gets its concrete meaning by user-defined / -supplied coding that in turn makes up the real / concrete implementation for a concrete required adapter. What is so special about that fact is that the implementation is not done using plain Java, but server-side ECMAScript instead (a.k.a. Javascript; concretely, it is the Nashorn-implementation supplied by the JDK). The benefit doing so is the quick and easy development roundtrip, preserving the typical "edit - run" development cycle B1i is known for (including the resulting hot-deployment). The further benefit is that adapter coding suddenly gets a part of the other integration content, thereby making deployment and distribution a lot easier than needing to take care to hassle to get some binary platform-dependent adapter-related files to the hosting operating system.
The adapter in fact represents a B1iP aio-style adapter (active input / output) in charge of being used as secondary I/O from within a running BizFlow. Thus, it is necessary to (periodically) poll the sensor that way (what is a usual access-pattern for such cases).
As of now, the adapter does not support any transactional behavior as some other fully fledged B1iP adapters do. For the intended usage, transactional coping most likely is not a matter and a usage-pattern of a deferred / subsequent write that only happens asa the preconditions have fulfilled will be the real and practical approach in such cases instead.
Furthermore, the adapter is a B1iP SPLT-style / specific payload-type) what concretely means that it always passes XML in and out from within the embedding BizFlow and IPO-Step. Whereas the embedding side looks and behaves like standard XML (as being the usual unified approach in the BizFlows), the Javascript centric internal environment has a totally different nature: It copes with data I/O from and towards the embedding BizFlow in a Javascript usual (and convenient) JSON abstraction. Therefore, the data always is represented in a way being natural and convenient for the particular area one moves within.
The Inner Circle of the ECMA-Adapter
Getting in the middle of the Javascript implementation now means to understand and get aware of some further details:
In order that the batch-like style executed Javascript is able to communicate with the embedding BizFlow, there exists a global pre-ddefined object in the script-environment called scriptIO. It contains all facilities / methods necessary for the kind of information flow that is necessary for the script.
That is by the way the very same stage as the scriptIO-object also has in the Xform-Atom!
Thus, it e.g. is possible to easily retrieve the incoming message as a JSON-string using
scriptIO.getJsonInMessage (...)
or to set an outbound result message using
scriptIO.setJsonOutMessage (...)
There are some more words to say about this automatic XML <-> JSON conversion in these cases - it is about the options how this conversion concretely can be used.
In the very beginning of JSON coping within B1i, things were pretty fixed:
- When getting data from a JSON source, the data could be in any shape as possible to express with JSON. So the data-source in fact could be free-style, not having a potential later XML-processing in mind. As there is no free lunch in life, the downside of this approach is that the resulting XML-data then was rendered into an artificial pre-defined XML structure being able to express the whole semantics of the JSON data, the B1iP defined artificial json_pltype representation for XML.
- In an analogue way, things just were inverse when converting data from XML to JSON again: In that case, the data exactly had to be expressed in the aforementioned artificial XML representation for JSON, finally resulting to a freely definable JSON structure then.
Latest (but not only!) due to the advent to the ECMA-Adapter, a bit of added flexibility made sense: Until now, only the JSON side was free to be chosen concerning the intended data-format; the XML side always needed to be artificial. Therefore, what was missing is that things just can get inverse: To be able to freely choose the shape of the XML side concerning the supplied data format in order to complete the overall offering. As there never is free lunch in life, the downside in this case is that the opposite JSON structure now gets / needs to be artificial / B1iP defined.
In that way, there now are added another two flavors to the overall XML <-> JSON conversion. Concerning the concrete shape of this newly introduced artificial JSON representation, see the description of the B1iP JSON payload-type converter in this document: JSONPltConf
Diving Down
That's it so far about the B1iP related basics worth to know for this topic (well, almost, as we will see).
The next thing to be discussed is about how to concretely access the hardware in the adapter code. From a first point of view, there seems to be bad news: Javascript by itself has absolutely no I/O-facilities inbuilt to its core. But as concretely coping with Nashorn (what is a Javascript engine in effect embedded within Java), it is possible to access the embedding Java-environment in an easy and convenient way (therefore it pays to get familiar with the capabilities of Nashorn, in particular concerning Java interaction).
The benefit about this way to do Java is that suddenly, Java gets lifted to the scripting level, not needing any compilation and restart of the embedding application server environment. But still, the resulting execution artifacts are Java VM byte code (as any fully fledged language on top of the JVM results to - be it Java, Groovy, Apache XSLTC's XSLT and so on. Thus, when having a closer look to resulting adapter coding, it is very likely that a high percentage of the code in effect will be expressed Java coding.
Concerning the concrete Java offerings available so far, there is everything accessible as exposed in a standard B1iP on the particular platform: Basically, the JDK itself will offer a high percentage of coverage about what is required. Besides of that, the (few) 3rd party libraries bundled to B1iP are offered*.
But most important for our case, some few but special libraries for the concrete coping with attached hardware very likely would be required to use:
It is Pi4J, the library that makes the hardware interfaces of the Raspi accessible for programming. People writing adapter code will want to get familiar with it to some extent.
And as i impended at the beginning of this paragraph, there still is a tiny piece of B1i functionality essential to be used on the Raspi if an adapter shall be programmed:
The Pi4JResourceDispenser class (along with the helper-interfaces I2cExecutor, SpiExecutor and SerExecutor). This more general purpose library is located in the B1iP Raspi-Adapter and therefore only accessible on that platform, as it makes no sense on other platforms.
In fact, that is no component that adds any kind of new functionality to the adapter environment, but the necessary degree of coordination instead. Because libraries like Pi4J (or the based-upon wiring Pi for C(++) access or simply accessing the particular Linux device files) all have in common that they do not care about concurrent environments as e.g. B1i is. But almost all I/O related resources on e.g. a Raspi (e.g. the I2C-bus) need to perform exclusive / singleton access at one time only. The Pi4JResourceDispenser class grants and coordinates such concurrently occurring access to the particular interfaces as e.g. made by the various adapters. Basically, it just only offers specialized execution-wrappers for the various hardware-interfaces that care about (fair!) serialization of the execution. The concrete hardware accesses of course also will work without these wrappers, but for sure will make trouble / produce race conditions asa being in a productive and stressed environment.
* It is not the intent to get the B1i environment to an overall "open-source grave" comprising any kind of open-source libraries / frameworks and tools this universe ever has seen. In many cases, bringing in 3rd party software in a careless and unneeded way leads to bloatware-styled results. There always should be the consideration on the table whether it makes sense to buy a cow if one wants to drink (a glass of) milk (the outcome of this decision will comprise the overall pre-conditions / consequences and finally how much milk shall be available...). As the downside, 3rd party code always comes along with the risk of regression bugs, discontinuation, not being in the shape as needed, being over-featured (means, -sized) and finally possibly being problematic concerning licensing / re-distribution terms. That is why trivial / minimal functionality better should not be accomplished in that way.
That's all about to say about the basic information that is necessary to write a concrete adapter-implementation using the B1iP ECMA-adapter as the boilerplate. In the next blog-post, we do the hands- (and heads-) on work to implement the adapter!
(This blog-post originally appeared on my Da Vinci Space Blog: https://davincispace.wordpress.com/2018/07/13/b1i-gy302-adapter-mk-i-the-basics/)
- SAP Managed Tags:
- SAP Business One Extensibility
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
Artificial Intelligence (AI)
1 -
Business Trends
363 -
Business Trends
21 -
Customer COE Basics and Fundamentals
1 -
Digital Transformation with Cloud ERP (DT)
1 -
Event Information
461 -
Event Information
23 -
Expert Insights
114 -
Expert Insights
151 -
General
1 -
Governance and Organization
1 -
Introduction
1 -
Life at SAP
415 -
Life at SAP
2 -
Product Updates
4,685 -
Product Updates
205 -
Roadmap and Strategy
1 -
Technology Updates
1,502 -
Technology Updates
85
Related Content
- Is there a way to get my PM orders with a basic start & finish dates 1 month apart? in Enterprise Resource Planning Q&A
- Beyond Basic (2): Certificate-Based Authentication in SAP S/4HANA Cloud Public Edition in Enterprise Resource Planning Blogs by SAP
- Beyond Basic (1): Certificate-Based Authentication in Enterprise Resource Planning Blogs by SAP
- SAP Enterprise Support Academy Newsletter April 2024 in Enterprise Resource Planning Blogs by SAP
- Demystifying Transformers and Embeddings: Some GenAI Concepts in Enterprise Resource Planning Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 5 | |
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 2 | |
| 2 | |
| 2 | |
| 2 |