

- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP HANA Native Storage Extension(NSE) - Increase ...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
07-22-2019
11:11 AM
Introduction:
SAP HANA Native Storage Extension(NSE) is a general-purpose, HANA built-in warm data storage solution. This solution is available on HANA 2.0 SP04. As we all know that now a day’s value of data is enormous from an organization's standpoint of view and Hence data storage solution and Access mechanism of data matter a lot. Data is broadly categorized into 3 different temperature tiers – Hot, Warm, and Cold. Frozen is also there, normally it is not considered in HANA data tiering options(DTO).

From the above image, we can see that SAP HANA Native Storage Extension(NSE) is one of the warm data solutions, and Without replacing it complements DTO solutions - extension nodes, dynamic tiering. However, there are some key differences as-well that NSE is built-in disk-based or flash-drive based database technology solution with deeply integrated into the SAP HANA (It uses HANA in-memory buffer for operations and Persistence layer for storage of warm data) and Full functionalities like query optimizer, query execution engine, and column store are supported. The second difference is that NSE is based on paging concepts, meaning data is read in the form of pages (4KB-16MB) while with other DTO solutions minimum data unit can be read as either whole table or partition. That means if a partition contains 100 million of records, then it will pull all 100 million of records into HANA in-memory while in NSE, based on the query processing selection criteria and Page units, Only required records are pulled into the main memory which might be 10 million records required based on the selection condition in the form of a set of pages. Now let’s deep dive into NSE high-level architecture and Implementation details…
The below image shows the difference between standard SAP HANA and SAP HANA with Native Storage Extension(NSE) (HANA 2.0 SP04).

- Data capacity: In standard SAP HANA memory size is equal to the amount of hot data memory while in SAP HANA with NSE is the amount of hot data memory plus the amount of warm data (built-in). Warm data is stored into an existing persistence layer. The main memory(Hot data) recommended ratio with NSE (Warm data) is 1:4 that means if total HANA in-memory size is 2TB i.e. hot data (800GB) + buffer cache (400GB) + working area (400GB) then warm data size can be 3.2TB (800GB * 4) or Less. Here the overall database size of usable memory would be 4TB(800GB for hot data + 3.2TB for warm data). Refer below example, In this case, additional HANA memory is added for cache buffer, As an alternative solution buffer cache can be adjusted from existing hot data memory as well considering ratios are met as per recommendations.

- HANA in-memory: In normal cases, 50% used to store hot data, and 50% used as working space.
- Hot Data “Column loadable”: Completely resides in main memory and Loads all data into memory for fast processing and Analytics.
- Warm Data “Page loadable”: With NSE, warm data may be specified as “page loadable”. As mentioned earlier data is loaded into memory in granular units of pages for query processing. NSE will reduce memory footprint as data is partially in memory and partially on disk.
- Performance: With NSE, as data is distributed between the main memory and disk storage. So, don’t expect data load to be very fast, Normal range would be 2-10 times slower than in-memory processing.
- Buffer Cache: It is used to load the page units from disk storage (warm data) into the main memory (hot data). With the current NSE feature by default, 10% of the main memory is reserved for buffer cache and Not allocated.
Queries to view and update buffer cache size:
- On 10 TB HANA DB server (Default):
SELECT VOLUME_ID as "Volume ID",
ROUND(MAX_SIZE/1024/1024/1024,3) AS "Max Buffer Size in GB"
FROM SYS.M_BUFFER_CACHE_STATISTICS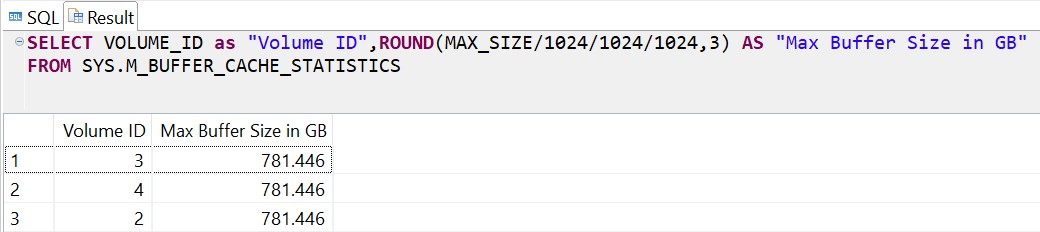
2. Update buffer cache size:
‘max_size_rel’: This is a relative parameter like 10%, 15% of total HANA memory.
‘max_size’: This is the exact size in GBs like 500,1000 etc.
ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'system')
SET ('buffer_cache_cs','max_size_rel') = '10' WITH reconfigure;Buffer cache ratio with NSE storage is normally 1:8 i.e. Buffer size should be at least 12.5% of the total size of NSE storage space.
NSE implementation:
- By default, in HANA 2.0 SP 04 NSE is enabled, there is no separate action required apart from executing correct SQL/DDL statements.
- “Page loadable” means data in NSE (Warm store) and “Column loadable” means data in the main memory (Hot store).
- “Page loadable” can be specified at table level, index level, partition level, and Column level.
- Data may be converted between “page loadable” to “column loadable” or Vice-versa.
- Load units: Loading behavior is determined by a load unit set for Column, Index, Partition, and Table.
- PAGE (Warm store): On NSE storage disk.
- COLUMN (Hot store): In main memory
- DEFAULT(Depends): If you do not specify a load unit for a given granularity, the LOAD_UNIT column in the system views shows the load unit as DEFAULT.
Standard HANA system views to view load unit set:
1. TABLES
2. M_CS_TABLES
3. TABLE_PARTITIONS
4. TABLE_COLUMNS
5. INDEXES – shows the index load unit for supported index types.
Example:
SELECT lOAD_UNIT from M_CS_TABLES
where table_name = 'VBRK' AND
schema_name = <SchemaName> ;
The behavior of the load unit setting:
| Load unit is set to: | The effective load unit is: |
| If the column-level load unit is configured as either PAGE LOADABLE or COLUMN LOADABLE | The configured load unit. |
| If the column-level load unit is configured as DEFAULT LOADABLE | SAP HANA checks, and uses, the partition-level load unit. |
| If the partition-level load unit is configured as PAGE LOADABLE or COLUMN LOADABLE | The configured load unit. |
| If the partition-level load unit is configured as DEFAULT LOADABLE | SAP HANA checks, and uses, the table-level load unit. |
| If the table load unit is configured as PAGE LOADABLE or COLUMN LOADABLE | The configured load unit. |
| If the table load unit is configured as DEFAULT LOADABLE | The COLUMN LOADABLE load unit. |
- Table Partitioning support:
- Unbalanced RANGE
- Unbalanced RANGE-RANGE
- HASH (Note: For hash partitioning entire table or column must or index be “page loadable” or “column loadable”)
DDL statements:
Creating new table SAP HANA Native Storage Extension(NSE) enabled:
--Sets the load unit to page loadable for the entire table
CREATE COLUMN TABLE tab_jeet (emp_id INT, name VARCHAR (100)) PAGE LOADABLE;--Sets the load unit to page loadable for the column name
CREATE COLUMN TABLE tab_jeet (emp_id INT, name VARCHAR (100) PAGE LOADABLE);--Sets the load unit for table and Column.
CREATE COLUMN TABLE tab_jeet
(emp_id INT COLUMN LOADABLE, name VARCHAR(100)) PAGE LOADABLE;--Single-level heterogenous partitioned table. Note that the double parenthesis surrounding the partition declaration is syntactically required by CREATE TABLE.
CREATE COLUMN TABLE tab_jeet (emp_id INT, name VARCHAR (100) )
PARTITION BY RANGE (emp_id)
((PARTITION 600000 < VALUES <= 99999 PAGE LOADABLE,
PARTITION 19999 <= VALUES < 600000 COLUMN LOADABLE,
PARTITION OTHERS COLUMN LOADABLE));Please note: The double parenthesis surrounding the partition declaration is syntactically required for NSE. If any table is partitioned, please make sure it follows the correct syntax and It means a lot. If (PARTITION is created using old syntax and Then NSE is not supported. ((PARTITION syntax is required to enable NSE.
--If the table is already range partitioned, then you can below query to identify if it follows correct syntax or not. If it does not then you will have to ALTER, the partition to re-org the new format/structure.
SELECT partition_spec FROM tables WHERE table_name = <table_name>;--Converting any existing partition to NSE enabled format with simple ALTER statement no need to DROP and CREATE
ALTER TABLE tab_jeet PARTITION BY RANGE (C1)
((PARTITION 600000 < VALUES <= 99999,
PARTITION 19999 <= VALUES < 600000 , PARTITION OTHERS));--Create Second-Level NSE-Enabled Partitions
CREATE COLUMN TABLE tab_jeet ( emp_id INT, zipcode INT, name VARCHAR (100) )
PARTITION BY RANGE (emp_id)((PARTITION 100000 <= VALUES < 199999,
PARTITION 199999 <= VALUES < 299999 PAGE LOADABLE, PARTITION OTHERS)
SUBPARTITION BY RANGE (zipcode)
(PARTITION 55100 <= VALUES < 55200, PARTITION 55200 <= VALUES < 55700,
PARTITION 55700 <= VALUES < 55900 , PARTITION OTHERS));
Changing the load unit of the existing table, column, partition.
-- Changing the Load Unit for a Table and Use of CASCADE removes any existing partition or column-level load unit preferences.
ALTER TABLE tab_jeet PAGE LOADABLE CASCADE;-- Changing the Load Unit for a Column
ALTER TABLE tab_jeet ALTER (emp_id INT PAGE LOADABLE);
--Revert
ALTER TABLE tab_jeet ALTER (emp_id INT COLUMN LOADABLE);-- Changing the Load Unit for a Partition
ALTER TABLE tab_jeet ALTER PARTITION 2 PAGE LOADABLE;-- Changing the Load Unit by specifying the RANGE clause
ALTER TABLE tab_jeet ALTER PARTITION RANGE(emp_id)
((PARTITION 19999 <= VALUES < 600000)) PAGE LOADABLE ;--Alter First-Level NSE-Enabled Partitions
ALTER TABLE tab_jeet ALTER PARTITION RANGE (emp_id)
((PARTITION 100000 <= VALUES < 199999)) COLUMN LOADABLE;--Alter Second-Level NSE-Enabled Partitions
ALTER TABLE tab_jeet ALTER PARTITIONRANGE (emp_id)
((PARTITION 100000 <= VALUES < 199999)
SUBPARTITION BY RANGE(zipcode) (PARTITION 55200 <= VALUES < 55700))
PAGE LOADABLE;
Table Indexes (Inverted index):
Indexes are created on one or more than one column for a table and It contains the same value as column contains. Normally if the index is based on one or two columns then that can be kept in main memory and Does not impact much of memory consumption, however, in some cases, you may not need to keep all indexes in main memory to get the desired performance. With NSE inverted index can be moved to disk storage “Warm Data” and Memory can be freed.
An inverted index is a special type of HANA index which is created for column type tables.
Advantages:
- Significantly reduced memory footprint due to the absence of concat attribute
- Less I/O in terms of data and redo logs
- Reduced delta merge efforts
- DML change operations can be faster due to reduced concat attribute maintenance
--Here index idx is moved to NSE storage
ALTER INDEX idx PAGE LOADABLE;Conclusion:
SAP HANA Native Storage Extension(NSE) is a warm data solution that increases HANA data capacity along with core In-memory at low-cost TCO as its deeply integrated warm data tier, with full HANA functionality support. It is supported for both on-premise and cloud platforms(HANA SaaS). It's by default available on HANA 2.0 SP 04 and Can be implemented easily by setting the buffer size, following correct recommend ratios, required partition types, and simple SQL execution with load unit to specify hot, warm data category based on the business needs.NSE complements, without replacing existing DTO solutions - extension node, dynamic tiering.
Important SAP Notes or links:
2799997 - FAQ: SAP HANA Native Storage Extension (NSE):https://launchpad.support.sap.com/#/notes/2799997
2771956 - SAP HANA Native Storage Extension Functional Restrictions:https://launchpad.support.sap.com/#/notes/2771956
2785533 - Using SQL Commands to get recommendations from the NSE Advisor:https://launchpad.support.sap.com/#/notes/2785533
- SAP Managed Tags:
- SAP HANA,
- SAP HANA dynamic tiering,
- Big Data
Labels:
6 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
86 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
270 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,578 -
Product Updates
323 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
395 -
Workload Fluctuations
1
Related Content
- Recap — SAP Data Unleashed 2024 in Technology Blogs by Members
- SAP BTP ABAP Environment – Elastic Scaling of Application Servers in Technology Blogs by SAP
- Performance Optimization in Invoice Import to SAP Business One in Technology Q&A
- Navigating the Complexities of Local Tax Compliance in Global Operations in Technology Q&A
- Embracing Simplicity to Boost Innovation: Driving Bosch's Centennial Journey of Excellence Forwards in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 11 | |
| 10 | |
| 10 | |
| 10 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 7 | |
| 6 |