Introduction
In this blog post I would like to share my experience on how to do SDI(Smart Data Integration) development on Cloud Foundry(CF). We will separate the development from application project and focus on data integration.
Architecture && Use Case
Think about we have following requirements.
- We need extract master data from on-premise S/4 HANA into HANA DB on Cloud;
- Base on those master data, we will develop some applications.
To decouple the development, we will create two project on SAP Web IDE:
- One SAP HANA Database Application, only for data integration(extract master data from S/4 periodically);
- One SAP Cloud Platform Business Application, based on your business requirements.
Below is overall architecture looks like:

Two SAP HDI(HANA Deployment Infrastructure) Container has been created.
Named HDI 1 is for Business Application; HDI 2 is for Data Integration Application;
Flow graph and replication tasks will based on virtual table from S/4 and Synonyms from application's real table.
Regarding DP Agent Installation && Configuration please refer to:
Installation and Configuration Guide for SAP HANA Smart Data Integration and SAP HANA Smart Data Qua...
Detail Steps
1. Build HANA Database Application
Suppose we have already build our business application since this blog only focus on SDI development.
Let's build one HANA Database Application:

Be careful to select your HANA Database version.

2. Add dependency resources
After application created, open your mta.yaml file, add existing SAP HDI Container : HDI 1 as dependent resource.
Choose "org.cloudfoundry.existing-service" and give the right service name

Create source folder as below:

Here we can see one "grants.hdbgrants" file. Which grant enough privileges for us.
For create virtual table/function and subscribe need below privileges from root HANA DB:
{
"sdi-grant-service": {
"object_owner": {
"global_object_privileges": [{
"name": "yourremotesource",
"type": "REMOTE SOURCE",
"privileges": [
"CREATE VIRTUAL TABLE",
"CREATE VIRTUAL FUNCTION",
"CREATE REMOTE SUBSCRIPTION",
"PROCESS REMOTE SUBSCRIPTION EXCEPTION",
"ALTER",
"DROP"
]
}]
},
"application_user": {
"global_object_privileges": [{
"name": "yourremotesource",
"type": "REMOTE SOURCE",
"privileges": [
"CREATE VIRTUAL TABLE",
"CREATE VIRTUAL FUNCTION",
"CREATE REMOTE SUBSCRIPTION",
"PROCESS REMOTE SUBSCRIPTION EXCEPTION",
"ALTER",
"DROP"
]
}]
}
},
"your_exsting_hdi": {
"object_owner": {
"container_roles": [
"MASTER::external_access_g#"
]
},
"application_user": {
"container_roles": [
"MASTER::external_access"
]
}
}
}
"sdi-grant-service" is another dependent service offer by cloud platform.
You can define this by open your cloud platform cockpit. Under the service part, create one new "User-Provided Services" instance.
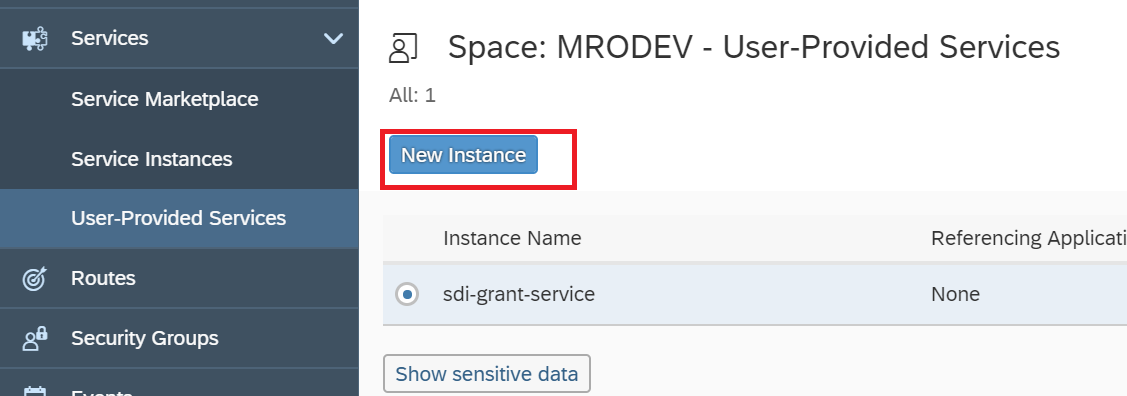
Normally you will use DB's "SYSTEM" account or which has remote source access right.

Also your existing SAP HDI container will create the role for access by external HDI container.
{
"role": {
"name": "MASTER::external_access",
"object_privileges": [
{
"name":"your object need access",
"type":"TABLE",
"privileges":[ "SELECT", "INSERT", "UPDATE", "DELETE" ]
}
]
}
}
3. Create Virtual Table
After these objects setup. Now we can begin define source and target object.
Source object is from remote source, we need define virtual table for it.
Under "vt" folder, define one file with extension: hdbvirtualtable.
And insert code simply as below:
VIRTUAL TABLE "your table name" AT "your remote source"."database"."schema"."remote table name"
4. Create Synonym
Target object is from existing HDI container, we need define synonym for it.
Under "sy" folder, define one file with extension: hdbsynonym.
And insert code simply as below:
{
"your synonym": {
"target": {
"object": "target table name",
"schema": "target schema name"
}
}
}
5. Create Flow graph
Finally we can define our flow graph which transform data from source to target. You can perform "join","union" or other functions base on your requirements.
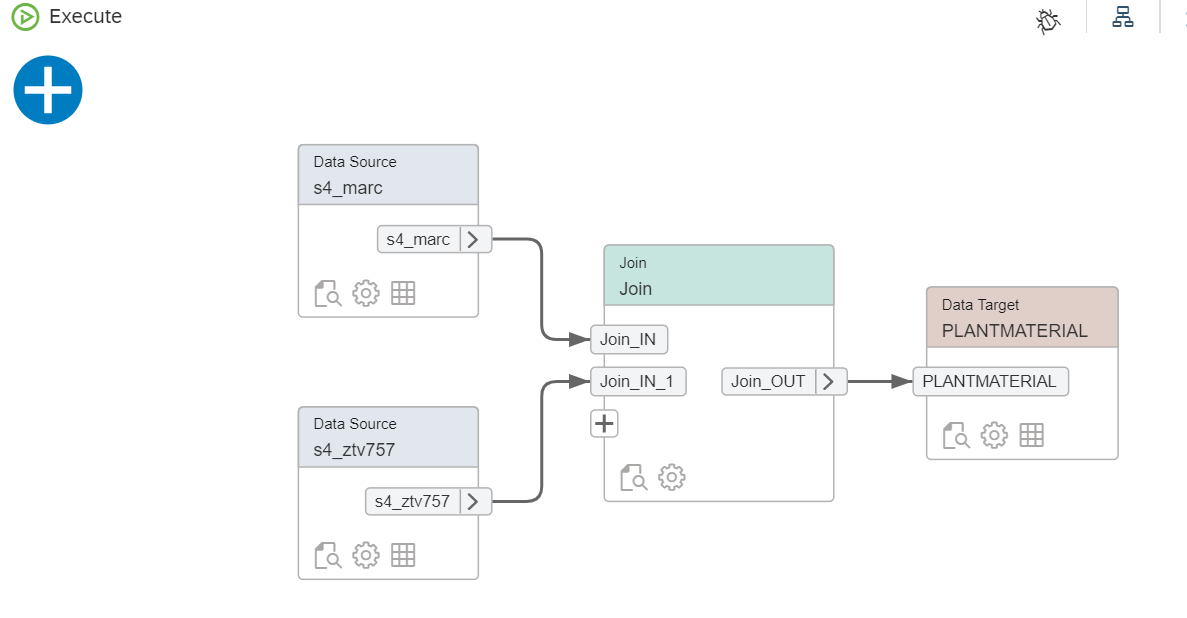
6. Check built objects
Then build your project. A new HDI container will be created. You can open data explore to find the built procedure base on your flow graph.

Now we can see it is just a normal store procedure. So we can build a program to call these procedure via JDBC.
Then you can publish this generated call as one URL, on CF job scheduler can consume this URL.
Conclusion:
Finally we achieve our goal to separate Data Integration from business application.
We have use
Synonyms for cross HDI( HANA Deployment Infrastructure) container table access.
But this may not best solution. Hope you can provide better solution for us.
