This blog post is part of the series
My Learning Journey for Hadoop. In this blog post I will focus on
- What is Big Data?
- Why Hadoop came into existence?
"A picture is worth a thousand words" - Keeping that in mind, I have tried to explain with less words and more images. Let me know know in comment if this is helpful or not
🙂
What is Big Data?

Where does Big Data come from?
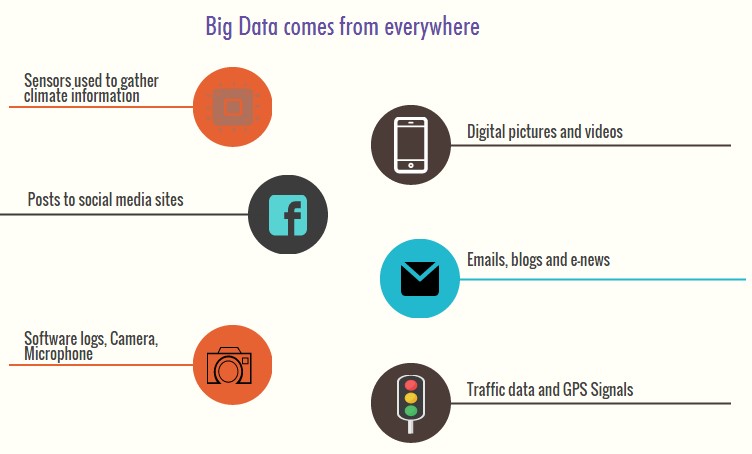
The data coming from everywhere for example
- In last 10-15 minutes on Facebook, you see millions of links shared, event invites, friend requests, photos uploaded and comments
- Terabytes of data generated through Twitter feeds in the last few hours
- Consumer product companies and retail organizations are monitoring social media like Facebook and Twitter to get an unprecedented view into customer behaviour, preferences, and product perception
- GPS data from mobile devices
- weblogs, emails text, email attachments
- sensors used to gather climate information
- posts to social media sites,
- purchase transaction records and much more
All these together constitute Big Data.
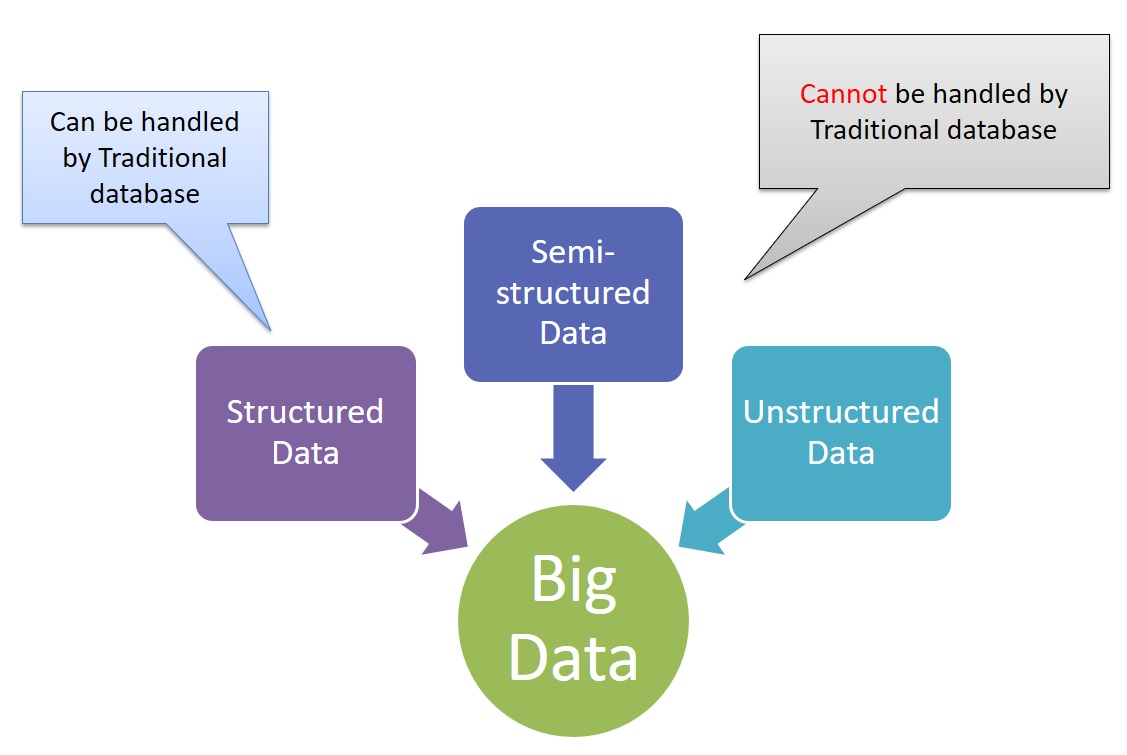
Big Data contains both Structured and Unstructured Data
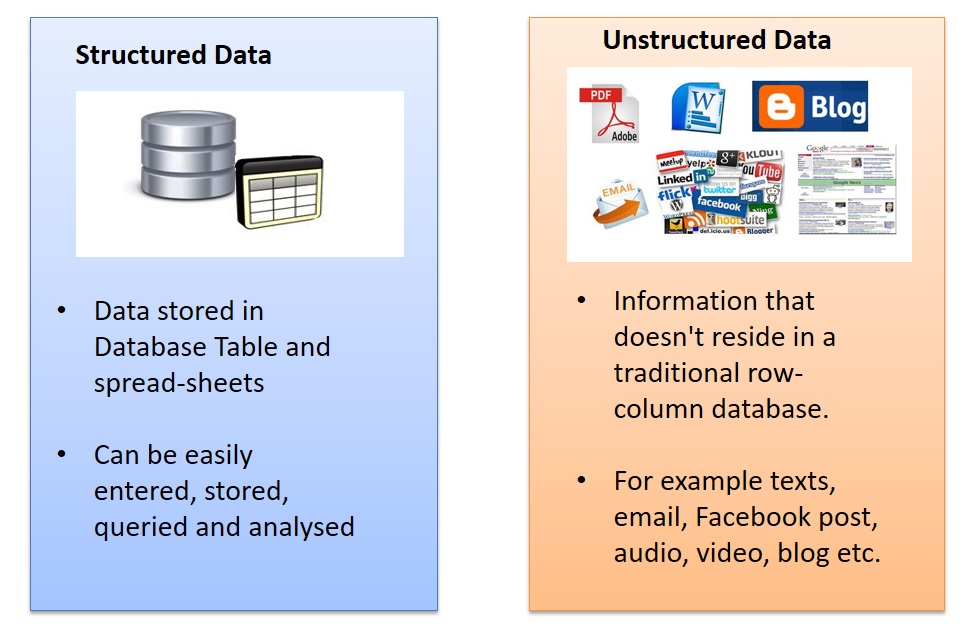
Large collection of structured and unstructured data that can be captured, stored, aggregated, analyzed and communicated to make better business decisions is called Big Data.
Big Data is Growing Fast

3Vs (volume, variety and velocity) defining Big Data
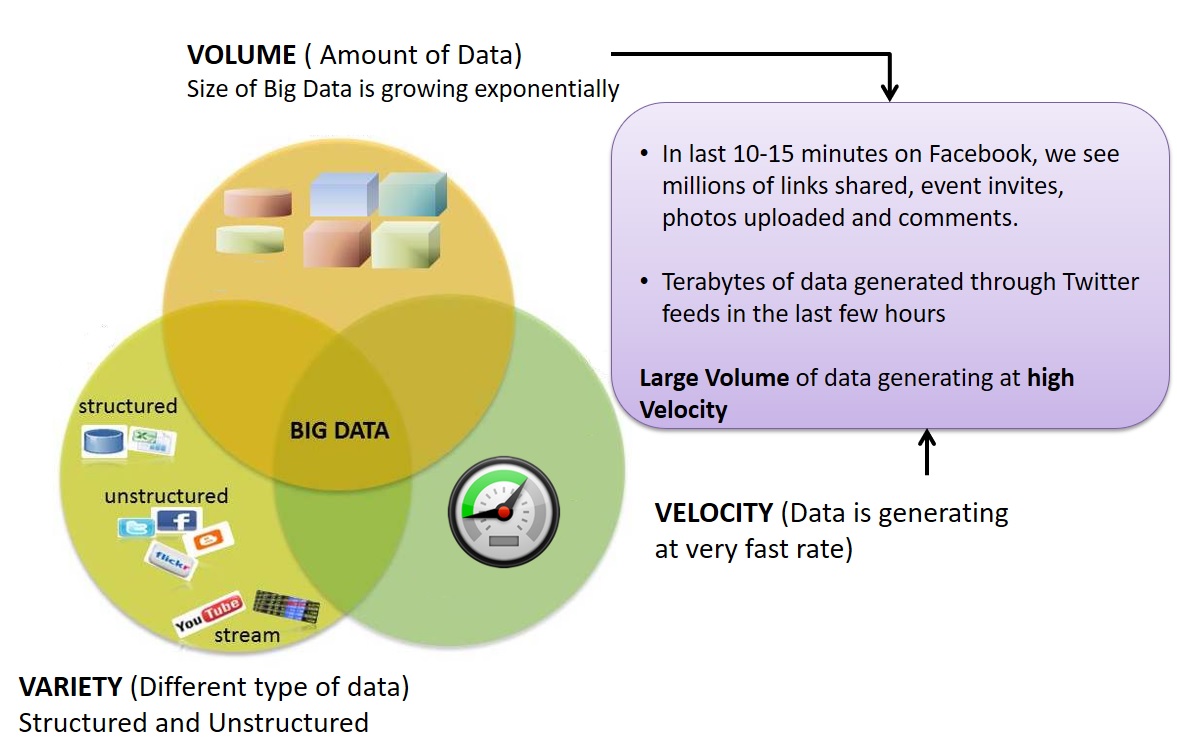
Volume refers to the amount of data

The size of available data is growing today exponentially. A text file is a few kilobytes, a sound file is a few megabytes while a full-length movie is a few gigabytes.
More sources of data are getting added on continuous basis. It is very common to have Terabytes and Petabytes of the storage system for enterprises. As the database grows the applications and architecture built to support the data needs to be changed quite often.
Velocity refers to the speed of data processing
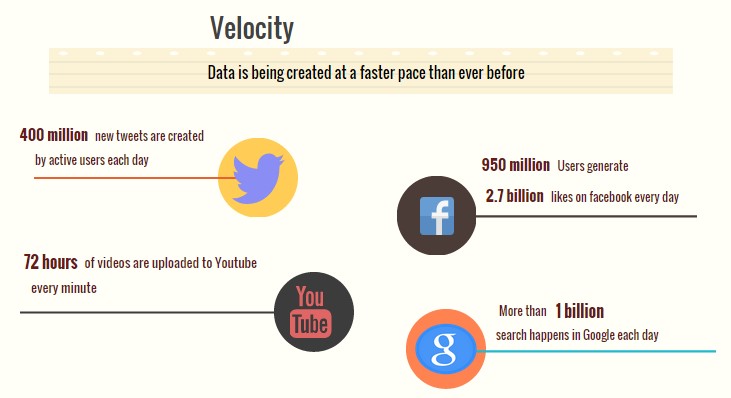
The data growth and social media explosion have changed how we look at the data. Initially, companies analyzed data using a batch process. One takes a chunk of data, submits a job to the server and waits for output. That process works when the incoming data rate is slower.
With the new sources of data such as social and mobile applications, the batch process breaks down. Today people reply on social media to update them with the latest happening. On social media sometimes a few seconds old messages (a tweet, status updates etc.) is not something interests users. They often discard old messages and pay attention to recent updates. The data movement is now almost real time and the update window has reduced to fractions of the seconds.
Variety refers to the number of types of data

From excel tables and databases, data structure has changed to lose its structure and to add hundreds of formats. Pure text, photo, audio, video, web, GPS data, sensor data, relational data bases, documents, SMS, pdf, flash etc.
Now we no longer have control over the input data format. Structure can no longer be imposed like in the past to keep control over the analysis. As new applications are introduced new data formats come to life. The real world has data in many different formats and that is the challenge we need to overcome with the Big Data.
Why Hadoop is Needed for Big Data?
Now let us see why we need Hadoop for Big Data.
Hadoop starts where distributed relational databases ends.
If relational databases can solve your problem, then you can use it but with the origin of Big Data, new challenges got introduced which traditional database system couldn’t solve fully.
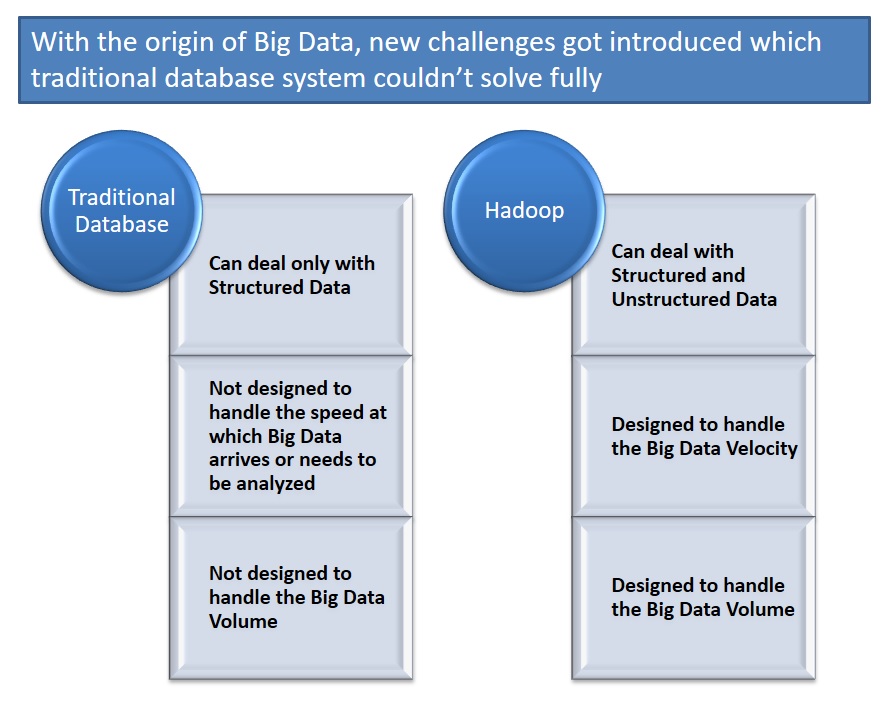
Let us understand these challenges in more details.
Challenges for traditional Database management system to handle Big Data
Challenge 1:
Big Data has got variety of data means along with structured data which relational databases can handle very well, Big Data also includes unstructured data (text, log, audio, streams, video stream, sensor, GPS data). The traditional databases require the database schema to be created in ADVANCE to define the data how it would look like which makes it harder to handle Big unstructured data.
 Challenge 2:
Challenge 2:
Big Data is getting generated at very high speed. The traditional databases are not designed to handle database insert/update rates required to support the speed at which Big Data arrives or needs to be analyzed.
 Challenge 3:
Challenge 3:
Big Data is data in Zettabytes, growing with exponential rate. If the data to be processed is in the degree of Terabytes and petabytes, it is more appropriate to process them in parallel independent tasks and collate the results to give the output. Traditional database approach can’t handle this.

To handle these challenges a new framework came into existence, Hadoop.
Hadoop is a frame work to handle vast volume of structured and unstructured data in a distributed manner.
Hadoop is not a database
It’s very important to know that Hadoop is not replacement of traditional database.
Unlike RDBMS where you can query in real-time, the Hadoop process takes time and doesn’t produce immediate results. Hadoop is a computing architecture, not a database.
What’s Next?
Check the blog series
My Learning Journey for Hadoop or directly jump to next article
Introduction to Hadoop in simple words
