
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- Rapid Groovy Scripting in CPI: Dynamic Loading and...
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
vadimklimov
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-17-2019
9:46 AM
Disclaimer
Material in this blog post is provided for information and technical features demonstration purposes only. The described technique is only applicable for non-productive usage and under no circumstances shall it be considered for utilization in production-oriented scenarios in CPI tenants, as it might introduce excessive overcomplication to troubleshooting process and security risk associated with potential lack of retrospective traceability and auditability of executed integration flow logic. An area where usage of the technique might be considered, is various proof of concepts that involve development of CPI iFlows.
Intro
When it comes to production-oriented development in CPI, the organization in general and the developer in particular shall be inclined to set up the appropriate development lifecycle infrastructure that aims enhancement of developer efficiency and development quality, as well as automation of recurrent steps that form parts of development, testing and deployment processes. There are nice blog posts out there written by engswee.yeoh and addressing developer productivity and aspects of unit testing of Groovy scripts. An intention is to develop representative and meaningful tests alongside the actual script, so that tests will cover critical (if not all) areas of the script functionality. Consequently, such unit tests can be re-executed locally on the developer machine and a script under test can be validated before being introduced to the iFlow in CPI.
In contrast to production-oriented development, it is commonly not feasible or not reasonable to prepare test specifications for the developed proof of concept iFlow and scripts within it. Development happens at a very high pace and consists of many amendments and changes that are not necessarily unit tested before deployment to the CPI tenant. It is a common case when the iFlow undergoes many iterative changes, each requiring the iFlow to be saved, deployed and started before it can be tested end to end – these steps are repeated and take time. One of areas that often requires several iterations of adjustments, is script steps within the iFlow. In between Groovy and JavaScript scripting languages that are supported by CPI, Groovy is way more popular choice among CPI developers – hence, in this blog post, we will focus on Groovy scripts, and terms "Groovy script" and "script" will be used interchangeably.
In this blog post, I would like to illustrate a technique that, when applied under certain circumstances, can be utilized to reduce a number of redeployments of the iFlow when working with scripts. The technique is not supposed to be used in production-oriented development, but might be useful when working on proof of concepts.
Overview
Fundamental idea of the technique is to replace static script with a generic wrapper that can execute a script logic that is dynamically submitted to it during execution of the iFlow. Since there are no changes to the iFlow at design time (assuming we only change script logic and no other steps of the iFlow), there is no need to save and re-deploy such an iFlow every time we need to introduce a change to a script.
Underlying concept is based on scripting nature of Groovy, where a currently executed script can instruct Groovy scripting engine to load an arbitrary submitted script code from a given location, parse and run it. Location of such dynamically called script code can vary – it can be a local script file, or externally located script, or a code snippet submitted to the script by other means. We can utilize this concept and pass code snippet together with (as a part of) the call to the iFlow – as a result, a message sent to the iFlow will not only contain data that needs to processed by the iFlow, but it will also include information on how data shall be processed.
This concept has much wider application and is effectively used in local environments when testing Groovy scripts. Now it is time to illustrate how it can be brought from the ground to the cloud and how it can be used in context of CPI development. Here I’m going to cover in details the particular case and implementation example that can be further adapted as per specific needs.
Implementation
In the demo, code snippet is going to be submitted in a request message body:

Obviously, this is not the only way to deliver code snippet to the wrapper script. For HTTP requests, code snippet can be passed as a part of the message body (in case the message body shall also include application data), or in a custom header (preliminarily code snippet shall be encoded – for example, using Base64 – as well as overall header value length shall be considered), or retrieved from some other location accessible from the Groovy script step within the iFlow.
In sake of simplicity, the iFlow consists of only one script step, which is a Groovy step implementing a generic wrapper and expecting dynamically submitted script code that is to be passed to it. No other steps are added to the iFlow deliberately, so that we can see pure effect of the script on the entire outcome of the iFlow execution at a later stage.
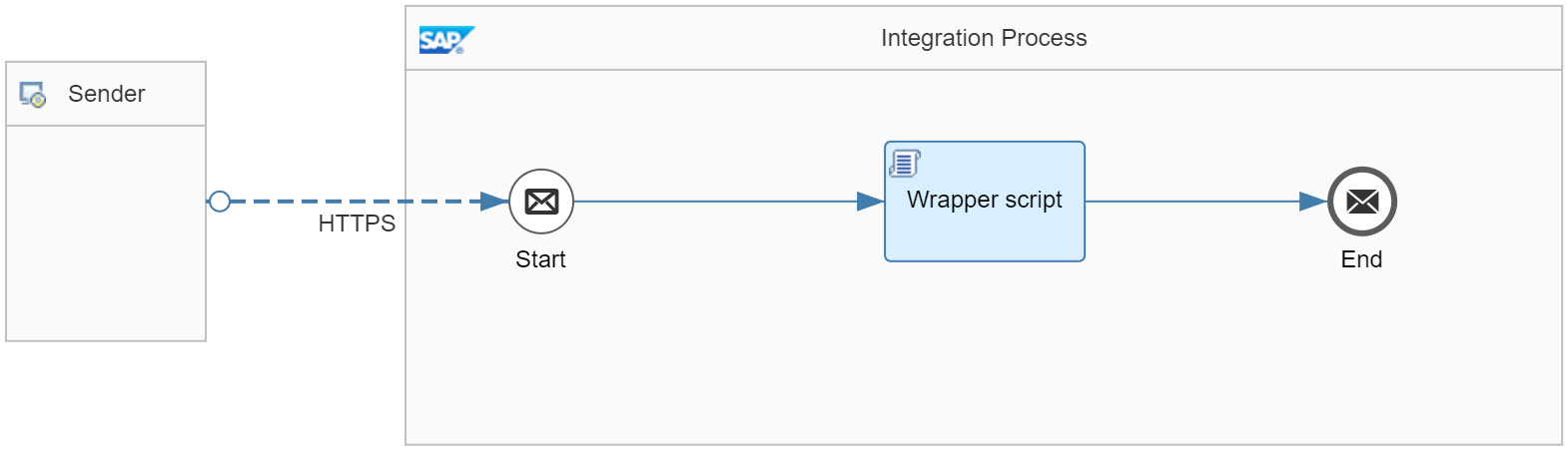
The entire logic of the wrapper script is based on usage of
GroovyShell that allows invocation of a Groovy script from another Groovy script. There are few other alternatives that can be used to implement dynamic loading of Groovy scripts and that are not covered in this blog post – those are based on usage of GroovyScriptEngine and GroovyClassLoader. A reason why they are not used here is because GroovyScriptEngine has advanced support for dependent scripts, and GroovyClassLoader has advanced support for complex hierarchy of classloaders and additional capabilities to support loading of Groovy classes – when dealing with many Groovy script steps in CPI, both features are not somewhat commonly utilized, but it is rational to be aware of these alternatives in case GroovyShell will not be fit for purpose in certain circumstances.Below is code snippet of the wrapper script:
import com.sap.gateway.ip.core.customdev.util.Message
import org.codehaus.groovy.control.CompilerConfiguration
import org.codehaus.groovy.control.customizers.ImportCustomizer
Message processData(Message message) {
def body = message.getBody(java.io.Reader)
def script = new StringBuilder()
def config = new CompilerConfiguration()
def customizer = new ImportCustomizer()
def binding = new Binding()
binding.message = message
body.eachLine { line ->
line = line.trim()
if (line.startsWith('import ')) {
def importClassName = line.replaceAll(';', '').minus('import ')
customizer.addImport(importClassName)
} else if (!line.empty) {
script << "${line}\n"
}
}
config.addCompilationCustomizers(customizer)
def shell = new GroovyShell(binding, config)
shell.evaluate(script.toString())
message = binding.message
return message
}Let’s have a walkthrough its most critical and essential parts. Considering the following part of the blog post will contain references to specific code lines, let me provide a screenshot of the code snippet above from the code editor:

Code line 7. Given we expect called script’s code snippet to arrive in the message body, we firstly need to retrieve the body from message instance.
Code lines 9-12. We will need several objects that contain code of the called script to be executed, configuration for Groovy Shell and binding between the wrapper script and the called script in particular:
- Builder (script) is used to collect code of the called script. In the demo, code snippet is going to be small and will not occupy much space, so we are going to use
StringBuilder, but if there is possibility of submitted large blocks of code in code snippet, we shall take care of optimization of memory consumed by the wrapper script and avoid potential suboptimal memory consumption – in such cases, we might want to switch to usage ofReaderandWriterobjects to manipulate submitted code snippet. - Compiler configuration (config) is used to tweak and customize behaviour of Groovy compiler – for example, by setting specific supported compiler properties and flags, specifying used imports. In this demo, we will use compiler configuration to add imports that are required by the called script and that are passed as a part of the message body alongside code snippet. The wrapper script contains a minimal number of imports required for its own execution, but any specific imports that are required for correct execution of the called script, are not known to the wrapper script – hence, we can dynamically specify them when sending the request.
- Import customizer (customizer) is used to hold information about imports that are required by the called script.
- Binding (binding) is used to bind variables between the wrapper script and the called script and allow exchange of data between them. For example, in the demo, we will use binding to pass Message object from the wrapper script to the caller script (to allow manipulation with this object within the caller script), and then get it back from the called script and return as an outcome of the wrapper script execution.
Code line 14. Here we set up binding between variable message of the wrapper script with the similarly named variable that will be accessible within the called script. Variables don’t necessarily need to be named similarly and can carry different names, but usage of same names here reduces confusion.
Code lines 16-24. We go through code snippet retrieved from the message body line by line and split them into two categories:
- Lines that contain import statements are retrieved from code snippet and added to import customizer to consolidate script imports.
- Lines that contain code of the called script are retrieved from code snippet and passed to builder to consolidate script code).
Import customizer provides various methods to add imports – for example, it is possible to add static imports, wildcard imports. In the demo, we will not need static imports, and wildcard imports are generally considered as an anti-pattern as in many cases, they can be replaced with specific class imports to improve readability and avoid potential import ambiguities and conflicts, so we will not use them here. Given that Groovy doesn’t enforce usage of semicolons at the end of statements, and different developers have different styles – some prefer usage of semicolons to emphasize end of statement, whereas others prefer more compact code and avoid usage of redundant characters – we’d rather let the wrapper script support both styles when retrieving imports.
As it can be evidenced, we don’t run any validations against obtained code snippet – for example, we don’t validate imported classes against rules for fully qualified names of classes (which can be done using regular expression) and we don’t run syntax checks for parsed code of the called script before executing it. These checks are omitted in the demo and we assume correctness of input submitted in the message body – if this assumption turns to be wrong, the wrapper script is going to fail, resulting in subsequent failure of message processing by the iFlow.
The iFlow also doesn’t check if the message body exists at all – it is assumed that code snippet is provided in the body of the submitted request, otherwise the iFlow shall not be called. Should this be a production-oriented scenario, such condition should have been considered and handled appropriately – for example, by checking message body size before making use of it within the script, or by checking a value of the header Content-Length of the request message against equality to zero (which would be a reflection of a message with the empty body).
Code line 26. After we have collected all imports into import customizer, we can add it to compiler configuration.
Code lines 28-29. Groovy Shell is created and configured by submitting binding and compiler configuration to it, followed by execution of the called script with the help of the shell. In simple cases, it is possible to use Groovy Shell without binding and/or compiler configurations, but in this demo, we need them both for a good reason.
Note that here we use method
GroovyShell.evaluate() – that is a convenient way of running a script once and combining steps of parsing script and executing it. An alternative to this would be usage of combination of methods GroovyShell.parse() (to parse the called script) and GroovyShell.run() (to run the called script) – this is useful and more optimal when the script has to be parsed once and executed several times. As this is not the case here in the demo, we gravitate towards a simpler form.Code lines 31-33. Message variable is read from the one that has been bound to the called script, back in the wrapper script and finally returned from the wrapper script to the executed route.
Alternatively, we could reduce number of code lines in the wrapper script by omitting explicit assignment of the bound variable back to the message variable and returning content of the bound variable in the wrapper script straightaway – here, they are separated and split into two steps in sake of better readability and illustration.
Test
Let’s now put the iFlow under test. Given demo implementation of the wrapper script expects the script code to arrive in the message body, we are going to compose a corresponding request and send it to the endpoint of the iFlow using Postman. For illustrative purposes, code snippet implements logic to compose a JSON object with elements that contain both static content (fixed value) and dynamic content (message ID and current timestamp) and pass it to a body of the response message, and given object content is marshalled to JSON formatted output, we also want to set a specific content type header that indicates the response message body is a JSON document – Content-Type = application/json. Full code snippet used in the request mesage is provided below and highlighted with red colour on the following screenshot.
import groovy.json.JsonOutput;
def body = JsonOutput.toJson(
messageId: "${message.headers['SAP_MessageProcessingLogID']}",
timestamp: "${new Date().format('yyyy-MM-dd HH:mm:ss.SSS')}",
text: "For demonstration purposes only"
);
message.setBody(body);
message.setHeader('Content-Type', 'application/json');
Let’s pay attention to a response that has been received (highlighted with blue colour on the screenshot above) – this is exactly what we would expect a response message to look like, if the code that has been submitted in the request, would have been placed in the Groovy step script in the iFlow! We can evidence that the wrapper script successfully identified import requirement for
JsonOutput and executed the script that was passed to it in the request.CPI Message Monitor provides additional details and evidences that the message triggered execution of the wrapper script and demonstrates message body before and after a script step execution – all together confirming once again that execution of dynamically submitted code snippet was carried and fulfilled as expected:



Alternative implementation by Eng Swee Yeoh
After publication of this blog post, engswee.yeoh made a proposal how the wrapper script can be implemented in an alternative way, making source code of the script significantly more compact and straightforward. The idea behind the version provided by Eng Swee, is to pass the entire Groovy script to the iFlow and consequently to the wrapper script, and not to consider input as a combination of imports section and code snippet that have to be handled in two different ways, as well as making usage of bindings redundant. Let me express gratitude to Eng Swee for exploring, testing and suggesting a more compact alternative, and provide the version that he shared, in here.
Below is code snippet of the wrapper script that has to be embedded into a Groovy script step of the iFlow:
import com.sap.gateway.ip.core.customdev.util.Message
Message processData(Message message) {
def reader = message.getBody(Reader)
Script script = new GroovyShell().parse(reader)
message = script.processData(message)
return message
}An amended sample request that was used in the demo, has to be slightly adjusted and shall result into the following message body to conform to the modified wrapper script:
import com.sap.gateway.ip.core.customdev.util.Message
import groovy.json.JsonOutput
Message processData(Message message) {
def body = JsonOutput.toJson(
messageId: "${message.headers['SAP_MessageProcessingLogID']}",
timestamp: "${new Date().format('yyyy-MM-dd HH:mm:ss.SSS')}",
text: "For demonstration purposes only"
)
message.setBody(body)
message.setHeader('Content-Type', 'application/json')
return message
}Outro
This was indeed a simple example, but I hope it illustrated the described concept – without changing the wrapper script and keeping it generic, we could flexibly compose the entire actually required custom script logic outside of CPI (here, in Postman) and let CPI execute it at runtime without necessity of making a single change in the iFlow implementation after it has been deployed. We can now send various requests (with different scripts in the message body) to this iFlow, and each time the script in the request will get changed, the same iFlow will behave differently.
This kind of flexibility has certain payoff – transparency and traceability. I would like to conclude this blog post by placing emphasis on what has been mentioned earlier: this concept is useful when rapidly developing and tweaking proof of concepts, but it is an inappropriate approach for production-oriented scenarios. In cases when script code is not settled as a part of the iFlow definition during design time, but is submitted and executed at runtime, it is much more complex to ensure consistency of executed flow logic. Not only it exposes a corresponding integration scenario to possible inconsistency and lack of predictability of flow logic, but raises a security concern – if flow logic is impacted from outside of the deployed iFlow, we set strong dependency on security of externally and dynamically submitted script code and enter discussion of analysis and assurance of the code (being it static or dynamic) that is executed at runtime, to be not malicious and to be free of security vulnerabilities.
- SAP Managed Tags:
- SAP Integration Suite,
- Cloud Integration
20 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
"TypeScript" "Development" "FeedBack"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
2 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
absl
2 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
AEM
1 -
AI
7 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
3 -
API Call
2 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
5 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
2 -
aws
2 -
Azure
1 -
Azure AI Studio
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
bitcoin
1 -
Blockchain
3 -
bodl
1 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
12 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Application Studio
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
1 -
Business Data Fabric
3 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
1 -
CA
1 -
calculation view
1 -
CAP
3 -
Capgemini
1 -
CAPM
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
4 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Consolidation Extension for SAP Analytics Cloud
1 -
Control Indicators.
1 -
Controller-Service-Repository pattern
1 -
Conversion
1 -
Cosine similarity
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
cyber security
3 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
database tables
1 -
Datasphere
2 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
digital transformation
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
1 -
Fiori
14 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
Flask
1 -
Full Stack
8 -
Funds Management
1 -
General
1 -
Generative AI
1 -
Getting Started
1 -
GitHub
8 -
Grants Management
1 -
groovy
1 -
GTP
1 -
HANA
6 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
2 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
HTML5 Application
1 -
Identity cards validation
1 -
idm
1 -
Implementation
1 -
input parameter
1 -
instant payments
1 -
Integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
iot
1 -
Java
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
8 -
Kerberos for JAVA
8 -
KNN
1 -
Launch Wizard
1 -
learning content
2 -
Life at SAP
1 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
2 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MTA
1 -
Multi-Record Scenarios
1 -
Multiple Event Triggers
1 -
Neo
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
2 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Process Automation
2 -
Product Updates
4 -
PSM
1 -
Public Cloud
1 -
Python
4 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
research
1 -
Resilience
1 -
REST
1 -
REST API
1 -
Retagging Required
1 -
Risk
1 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
3 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
8 -
SAP AI Launchpad
8 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
4 -
SAP Analytics Cloud for Consolidation
2 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BTP
21 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
6 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
2 -
SAP CDC
1 -
SAP CDP
1 -
SAP CDS VIEW
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Migration in Retail Industry
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
9 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
2 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
9 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Odata
2 -
SAP on Azure
1 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP successfactors
3 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP Utilities
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapmentors
1 -
saponaws
2 -
SAPS4HANA
1 -
SAPUI5
4 -
schedule
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
SEN
1 -
SEN Manager
1 -
service
1 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
soap
1 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
Substring function
1 -
SuccessFactors
1 -
SuccessFactors Platform
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
1 -
Technology Updates
1 -
Technology_Updates
1 -
terraform
1 -
Threats
1 -
Time Collectors
1 -
Time Off
2 -
Time Sheet
1 -
Time Sheet SAP SuccessFactors Time Tracking
1 -
Tips and tricks
2 -
toggle button
1 -
Tools
1 -
Trainings & Certifications
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
2 -
ui designer
1 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Validations
1 -
Vector Database
2 -
Vector Engine
1 -
Visual Studio Code
1 -
VSCode
1 -
Web SDK
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- Embracing TypeScript in SAPUI5 Development in Technology Blogs by Members
- SAP Analytics Cloud - Performance statistics and zero records in Technology Blogs by SAP
- Winshuttle script execution - Error: Field is not an input field in Technology Q&A
- Streamline the updates for SAP HANA Cloud with SAP Automation Pilot in Technology Blogs by SAP
- Workload Analysis for HANA Platform Series - 1. Define and Understand the Workload Pattern in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 12 | |
| 12 | |
| 7 | |
| 5 | |
| 5 | |
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 3 |