
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- Eng Swee's tips for CPI development
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
engswee
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-14-2019
5:11 AM
It has been about three and a half years since my first foray into the world of cloud integration. A lot has changed since - the official product name changed from HCI to CPI (with a few others thrown in between that did not stick long enough); Eclipse was dropped in favor of WebUI (which I still do not agree with, but have chosen to move on); the many quirky bugs and errors that beleaguered the initial versions of the product have more or less been dealt with; and the product has gone from strength to strength, maturing with each passing month's rolling software update. Of course, there are some parts that have not changed like the sorely missing self-service free trial access, but that will be a story/battle for another day. [Update 21 Jun 2019: Self-service CPI trial is finally available in SAP Cloud Platform Cloud Foundry (CF) environment - yay!]
While it is relatively easy for someone with an integration background (like PI) to pick up CPI and be productive, ensuring that the integration flow designs are robust and can withstand the test of time is a different matter. While Apache Camel (as the underlying framework) supports a flexible modelling environment, it also shifts the onus to the developer/architect to ensure the interfaces are well designed.
After implementing custom CPI developments firstly for SuccessFactors Employee Central integration, followed by A2A integrations with an on-premise S/4HANA system, I have found various design and development practices that have worked particularly well for me. In the rest of this post, I will share those with you.
Certain adapters have configuration parameters that are interface agnostic and therefore can/should be reused between multiple interface. Unlike PI, there is no concept of communication channels in CPI. The design of each interface is within its own IFlow and there are limited options for reuse. The introduction of the ProcessDirect adapter last year enables us to overcome such limitation.
For example, an IDoc receiver can be modelled as a separate IFlow as shown below using ProcessDirect in the sender channel.

This allows the common IFlow to be invoked by more than 1 IFlow merely by sending to the same endpoint via a ProcessDirect receiver channel as shown below.

The benefit of such approach is that common values that need to be populated in an IDoc receiver channel (e.g. URL, Credential Name) are just maintained in one place. This simplifies matters when we need to deploy multiple interfaces at the same time, as well as future maintenance if there are changes to the common receiver.
During runtime, multiple messages (one for each linked IFlow) will appear in the message monitor and these can be linked together with the Message Correlation ID (as shown below).
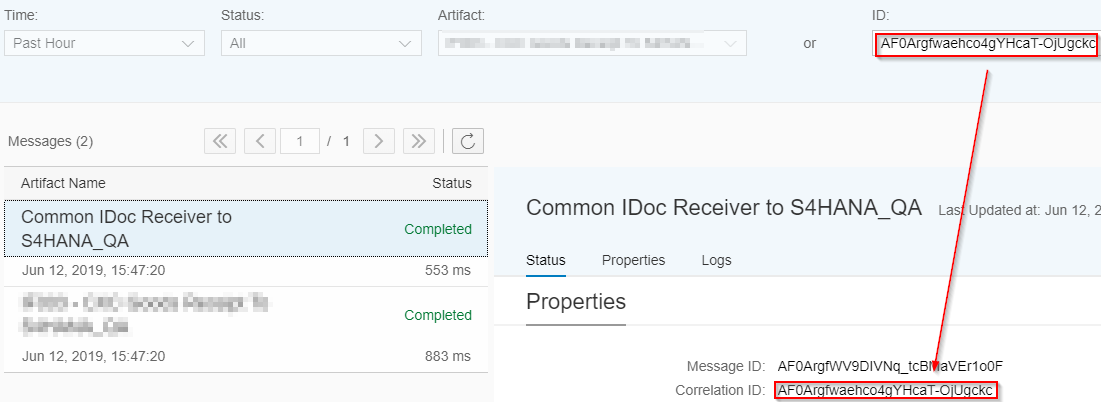
This approach is not only applicable for grouping common channels, but also to reuse common mappings or common extenal libraries (e.g. if you use FormatConversionBean in more than 1 IFlow).
For most integration scenarios, mapping is one of the most pivotal part of the design and development. A mapping object changes many times throughout its lifecycle - from initial development, initial production release, and the many enhancements during the maintenance period. Sometimes, it may end up looking totally different from how it was when it was first developed.
Therefore, deciding on which mapping approach to use is important - this affects how easy/effective it is to develop, maintain and enhance a mapping object during its lifecycle. Personally, I am most at home when working with a full-fledged programming language. In the context of CPI, that means developing mappings as Groovy Scripts, as I have described in detail in I *heart* Groovy mapping.
Using Groovy allows me to develop, maintain and enhance mappings in a very effective manner.
Stream the XMLSlurper input in Groovy Scripts has been around for two years, yet I see too many scripts online (forum and blog posts) and in CPI tenants utilising the following inefficient manner to access the payload (message body).
While this is acceptable and may not cause any issues with smaller sized payloads, it does not scale well when the payload gets larger.
Instead, always access the message body with a Reader (even in the case when you are not using XmlSlurper for further XML parsing).
Furthermore, you can even use strong typing to utilise the IDE's code completion in the subsequent lines of code. Also, Groovy extends Reader with many helper methods that lets you work with IO in an efficient manner.
Consider using externalised parameters to optimise design of the IFlows for configurability. This allows certain aspects of the IFlow to be changed without editing it. It follows the same approach for SAP's prepackaged content where most of them are "Configure-Only".

Common use cases for externalised parameters are:-
The monitoring capabilities in CPI are somewhat limited. Often, when there are many messages in the system, it is not straightforward to uniquely identify a message that is required for further analysis. CPI does not have functionality such as User Defined Message Search (UDMS) that is available in PI. The search functionality for IDs is limited to searching by Message ID, Correlation ID or Application ID.
Fortunately, we can take advantage of Application Message ID for our purposes. This is achieved by populating the message header SAP_ApplicationID with an appropriate value. Depending on the scenario, following are two options to populate that header.
Note that the value populated via (1) can be overwritten by (2).
The onus is on the developer to consider what is the appropriate value to populate into the Application Message ID. This could be a unique value sent by the sender system or possibly the filename in the case of file based integration - screenshot below shows how a message can be searched based on the filename.

CPI/Camel places the onus on the developer for error handling. This requires a paradigm shift for those coming from a PI background.
For asynchronous scenarios, not all CPI adapters have native capability for reprocessing messages, or native support for Exactly Once Quality of Service. As such the developer needs to consider the cases when a message fails in CPI, and what type of error handling is required. Below are some options for consideration:-
Another aspect to consider is implementing exception handling using exception sub-process. This allows the developer to introduce explicit logic to handle exceptions that occur during message processing. However, for complex IFlows that are broken down into multiple Local Integration Processes (typical of SuccessFactors Employee Central or Hybris Marketing integrations involving multiple OData calls), the error handling can get tricky or messy. Exceptions are not automatically propagated from Local Integration Process to the main Integration Process, so exception sub-process steps need to be implemented in each Local Integration Process block which could lead to a lot of duplication.
By default, most CPI landscapes are 2-tier, with one non-production tenant and one production tenant. However, the systems connected to CPI are typically 3-tier (Dev, QA & Prod) for example an on-premise SAP system. Therefore the common approach is to use the non-production CPI tenant to integrate with both Dev and QA environments.
This is achieved via duplicating the integration artifacts in design under a different name (typically adding a suffix like _QA) and deploying them with different configured parameters.

Ensure that the design of the integration artifacts supports such deployment approach. Some common aspects to consider are:-



Version management is an important aspect in any development lifecycle. CPI provides a basic version management functionality in WebUI, while it is also possible to download the artifacts and manage it externally via an SCM like Git. My recommendation is to use both.
WebUI
The functionality provided allows us to persist the entire state of the artifact at a point in time. It is recommended to use 'Save as Version' whenever the artifact reaches a somewhat stable/working state. This allows us to make further changes with the assurance that we can revert back to a working version if required.
Furthermore, without version management in WebUI, the state of the artifact remains in 'Draft'. Because an IFlow consists of many objects (IFlow model, schemas, scripts), it is difficult to compare the state of an IFlow across the different environments/tenants. If the copies of the IFlow in Dev, QA and Prod all have the 'Draft' status, this will require manual comparison of all objects within an IFlow to determine if there are any differences between them.

Personally, I use the version number to enable me to know if the IFlow is the same or not between each environment, without having to individually inspect each object. CPI uses a 3-digit numbering system similar to Semantic Versioning. My approach is slightly different and I use it also to indicate the release state of the IFlow during the major stages of the implementation lifecycle. The following denotes the different stages:-
The last digit is incremented by one for every fix/enhancement.
Note: Thank you to Piotr Radzki who highlighted that packages with objects in 'Draft' cannot be exported. Since this is a pre-requisite to transport to Production environment, all the more reason to implement a version numbering system that is easy to use and makes sense.
Git
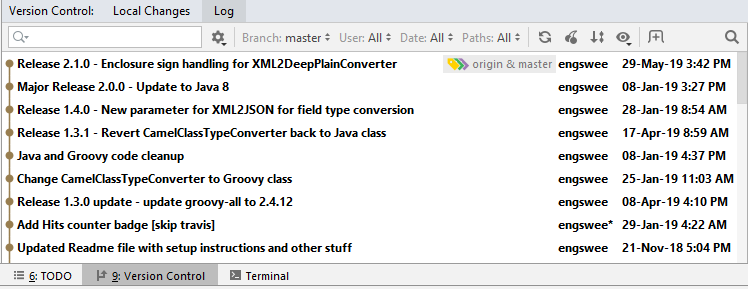
As part of my workflow, I also use Git within an IDE to externally manage my CPI development. While this is mainly for the Groovy Scripts which typically go through lots of changes during the implementation lifecycle, I also store all the other objects of an IFlow.
I have described this approach using the HCI Eclipse plugin (before it was deprecated), but now that I have switched over to IntelliJ IDEA, it is still applicable using the VCS functionality provided by IntelliJ.
So there it is, some of the the practices, approaches and guidelines that have worked particularly well for me when I work on CPI development. It is by no means a "best practices" document (yet), as the whole area of cloud integration is still changing at a rapid pace. As vadim.klimov commented here, "the more we work on cloud integration, the more we find new creative ways to deal with them" (paraphrased).
I welcome any comment, opinion, and feedback on these, and feel free to even disagree with me if you have a different perspective on them.
Conversation about this post on LinkedIn.
While it is relatively easy for someone with an integration background (like PI) to pick up CPI and be productive, ensuring that the integration flow designs are robust and can withstand the test of time is a different matter. While Apache Camel (as the underlying framework) supports a flexible modelling environment, it also shifts the onus to the developer/architect to ensure the interfaces are well designed.
After implementing custom CPI developments firstly for SuccessFactors Employee Central integration, followed by A2A integrations with an on-premise S/4HANA system, I have found various design and development practices that have worked particularly well for me. In the rest of this post, I will share those with you.
1. Utilise ProcessDirect adapter to create common/shared IFlows
Certain adapters have configuration parameters that are interface agnostic and therefore can/should be reused between multiple interface. Unlike PI, there is no concept of communication channels in CPI. The design of each interface is within its own IFlow and there are limited options for reuse. The introduction of the ProcessDirect adapter last year enables us to overcome such limitation.
For example, an IDoc receiver can be modelled as a separate IFlow as shown below using ProcessDirect in the sender channel.
This allows the common IFlow to be invoked by more than 1 IFlow merely by sending to the same endpoint via a ProcessDirect receiver channel as shown below.
The benefit of such approach is that common values that need to be populated in an IDoc receiver channel (e.g. URL, Credential Name) are just maintained in one place. This simplifies matters when we need to deploy multiple interfaces at the same time, as well as future maintenance if there are changes to the common receiver.
During runtime, multiple messages (one for each linked IFlow) will appear in the message monitor and these can be linked together with the Message Correlation ID (as shown below).
This approach is not only applicable for grouping common channels, but also to reuse common mappings or common extenal libraries (e.g. if you use FormatConversionBean in more than 1 IFlow).
2. Use Groovy Script for mappings
For most integration scenarios, mapping is one of the most pivotal part of the design and development. A mapping object changes many times throughout its lifecycle - from initial development, initial production release, and the many enhancements during the maintenance period. Sometimes, it may end up looking totally different from how it was when it was first developed.
Therefore, deciding on which mapping approach to use is important - this affects how easy/effective it is to develop, maintain and enhance a mapping object during its lifecycle. Personally, I am most at home when working with a full-fledged programming language. In the context of CPI, that means developing mappings as Groovy Scripts, as I have described in detail in I *heart* Groovy mapping.
Using Groovy allows me to develop, maintain and enhance mappings in a very effective manner.
3. Use Reader when accessing message body in Groovy Script
Stream the XMLSlurper input in Groovy Scripts has been around for two years, yet I see too many scripts online (forum and blog posts) and in CPI tenants utilising the following inefficient manner to access the payload (message body).
def body = message.getBody(java.lang.String)While this is acceptable and may not cause any issues with smaller sized payloads, it does not scale well when the payload gets larger.
Instead, always access the message body with a Reader (even in the case when you are not using XmlSlurper for further XML parsing).
def body = message.getBody(Reader)Furthermore, you can even use strong typing to utilise the IDE's code completion in the subsequent lines of code. Also, Groovy extends Reader with many helper methods that lets you work with IO in an efficient manner.
Reader reader = message.getBody(Reader)4. Externalise parameters to optimise configurability of IFlows
Consider using externalised parameters to optimise design of the IFlows for configurability. This allows certain aspects of the IFlow to be changed without editing it. It follows the same approach for SAP's prepackaged content where most of them are "Configure-Only".
Common use cases for externalised parameters are:-
- Endpoint, URL, server, directory and credentials
- Scheduler for polling adapters
- IDoc partner profile details
- Parameter to control payload logging
- Parameter values that differ in different environments (Dev, QA, Prod)
5. Populate Application Message ID to uniquely identify messages
The monitoring capabilities in CPI are somewhat limited. Often, when there are many messages in the system, it is not straightforward to uniquely identify a message that is required for further analysis. CPI does not have functionality such as User Defined Message Search (UDMS) that is available in PI. The search functionality for IDs is limited to searching by Message ID, Correlation ID or Application ID.
Fortunately, we can take advantage of Application Message ID for our purposes. This is achieved by populating the message header SAP_ApplicationID with an appropriate value. Depending on the scenario, following are two options to populate that header.
- For scenarios with HTTP-based sender channels, this can be populated by the sender system in HTTP header SAP_ApplicationID.
- Within the IFlow, message header SAP_ApplicationID can be populated via Content Modifier, Groovy Script or Javascript.
Note that the value populated via (1) can be overwritten by (2).
The onus is on the developer to consider what is the appropriate value to populate into the Application Message ID. This could be a unique value sent by the sender system or possibly the filename in the case of file based integration - screenshot below shows how a message can be searched based on the filename.
6. Implement error handling in IFlow
CPI/Camel places the onus on the developer for error handling. This requires a paradigm shift for those coming from a PI background.
For asynchronous scenarios, not all CPI adapters have native capability for reprocessing messages, or native support for Exactly Once Quality of Service. As such the developer needs to consider the cases when a message fails in CPI, and what type of error handling is required. Below are some options for consideration:-
- For HTTP-based senders, explore possibility of sender system retriggering message to CPI.
- For SFTP sender, the files are not consumed (archived or deleted) if there is an error during message processing in CPI. Such erroneous files will be picked up for processing again during the next polling cycle. Design the IFlow/mapping such that there will be no application errors expected for all cases, and therefore only leaving the possibility of systemic errors such as intermittent connectivity. This inherently enables the files to be automatically delivered again once the connection is re-established. The drawback for such an approach is if the polling frequency is often, this can generate a lot of noise in the message monitor.
- Consider utilising JMS adapter/queues to introduce native reprocessing functionality. The good news is that it is now available for non-Enterprise Edition tenants (requiring additional $$$ of course). The drawback is that JMS queues are "expensive" and even Enterprise Edition comes with only 30 queues by default. Furthermore, if it is a typical 2-tier landscape, then the queues in the non-production tenant will have to be split between Dev and QA (considering a typical 3-tier backend landscape).
- Manually implement Exactly Once using approaches described here and here.
- [Update 2 Jul 2019] - If you can get your hands on some JMS queues (by any means necessary!) - consider implementing the design detailed in Not enough JMS queues for Exactly Once? Share them between IFlows!
Another aspect to consider is implementing exception handling using exception sub-process. This allows the developer to introduce explicit logic to handle exceptions that occur during message processing. However, for complex IFlows that are broken down into multiple Local Integration Processes (typical of SuccessFactors Employee Central or Hybris Marketing integrations involving multiple OData calls), the error handling can get tricky or messy. Exceptions are not automatically propagated from Local Integration Process to the main Integration Process, so exception sub-process steps need to be implemented in each Local Integration Process block which could lead to a lot of duplication.
7. Design integration artifacts to cater for 2-tier landscape
By default, most CPI landscapes are 2-tier, with one non-production tenant and one production tenant. However, the systems connected to CPI are typically 3-tier (Dev, QA & Prod) for example an on-premise SAP system. Therefore the common approach is to use the non-production CPI tenant to integrate with both Dev and QA environments.
This is achieved via duplicating the integration artifacts in design under a different name (typically adding a suffix like _QA) and deploying them with different configured parameters.
Ensure that the design of the integration artifacts supports such deployment approach. Some common aspects to consider are:-
- Configurable endpoint, URL, server, credentials
- Value Mapping containing different Agency/Identifier combinations
- Separate packages for Dev and QA artifacts
8. Implement version management - both in WebUI and Git
Version management is an important aspect in any development lifecycle. CPI provides a basic version management functionality in WebUI, while it is also possible to download the artifacts and manage it externally via an SCM like Git. My recommendation is to use both.
WebUI
The functionality provided allows us to persist the entire state of the artifact at a point in time. It is recommended to use 'Save as Version' whenever the artifact reaches a somewhat stable/working state. This allows us to make further changes with the assurance that we can revert back to a working version if required.
Furthermore, without version management in WebUI, the state of the artifact remains in 'Draft'. Because an IFlow consists of many objects (IFlow model, schemas, scripts), it is difficult to compare the state of an IFlow across the different environments/tenants. If the copies of the IFlow in Dev, QA and Prod all have the 'Draft' status, this will require manual comparison of all objects within an IFlow to determine if there are any differences between them.
Personally, I use the version number to enable me to know if the IFlow is the same or not between each environment, without having to individually inspect each object. CPI uses a 3-digit numbering system similar to Semantic Versioning. My approach is slightly different and I use it also to indicate the release state of the IFlow during the major stages of the implementation lifecycle. The following denotes the different stages:-
| Version No | State |
| 1.1.0 | Initial release for System & Integration Testing (SIT) |
| 1.2.0 | Initial release for User Acceptance Testing (UAT) |
| 2.0.0 | Initial release for Production |
The last digit is incremented by one for every fix/enhancement.
Note: Thank you to Piotr Radzki who highlighted that packages with objects in 'Draft' cannot be exported. Since this is a pre-requisite to transport to Production environment, all the more reason to implement a version numbering system that is easy to use and makes sense.
Git
As part of my workflow, I also use Git within an IDE to externally manage my CPI development. While this is mainly for the Groovy Scripts which typically go through lots of changes during the implementation lifecycle, I also store all the other objects of an IFlow.
I have described this approach using the HCI Eclipse plugin (before it was deprecated), but now that I have switched over to IntelliJ IDEA, it is still applicable using the VCS functionality provided by IntelliJ.
Conclusion
So there it is, some of the the practices, approaches and guidelines that have worked particularly well for me when I work on CPI development. It is by no means a "best practices" document (yet), as the whole area of cloud integration is still changing at a rapid pace. As vadim.klimov commented here, "the more we work on cloud integration, the more we find new creative ways to deal with them" (paraphrased).
I welcome any comment, opinion, and feedback on these, and feel free to even disagree with me if you have a different perspective on them.
Conversation about this post on LinkedIn.
- SAP Managed Tags:
- SAP Integration Suite,
- Cloud Integration
21 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
"TypeScript" "Development" "FeedBack"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
2 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
absl
2 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
AEM
1 -
AI
7 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
3 -
API Call
2 -
API security
1 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
5 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
2 -
aws
2 -
Azure
1 -
Azure AI Studio
1 -
Azure API Center
1 -
Azure API Management
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
bitcoin
1 -
Blockchain
3 -
bodl
1 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
12 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Application Studio
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
1 -
Business Data Fabric
3 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
4 -
CA
1 -
calculation view
1 -
CAP
3 -
Capgemini
1 -
CAPM
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
4 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Consolidation Extension for SAP Analytics Cloud
2 -
Control Indicators.
1 -
Controller-Service-Repository pattern
1 -
Conversion
1 -
Cosine similarity
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
cyber security
3 -
cybersecurity
1 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Flow
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
database tables
1 -
Datasphere
3 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Defender
1 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
digital transformation
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
2 -
Exploits
1 -
Fiori
14 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
Flask
1 -
Full Stack
8 -
Funds Management
1 -
General
1 -
General Splitter
1 -
Generative AI
1 -
Getting Started
1 -
GitHub
8 -
Grants Management
1 -
GraphQL
1 -
groovy
1 -
GTP
1 -
HANA
6 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
2 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
HTML5 Application
1 -
Identity cards validation
1 -
idm
1 -
Implementation
1 -
input parameter
1 -
instant payments
1 -
Integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
iot
1 -
Java
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
8 -
Kerberos for JAVA
8 -
KNN
1 -
Launch Wizard
1 -
Learning Content
2 -
Life at SAP
5 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
Loading Indicator
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
2 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MTA
1 -
Multi-Record Scenarios
1 -
Multiple Event Triggers
1 -
Myself Transformation
1 -
Neo
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
2 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Process Automation
2 -
Product Updates
4 -
PSM
1 -
Public Cloud
1 -
Python
4 -
python library - Document information extraction service
1 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
research
1 -
Resilience
1 -
REST
1 -
REST API
2 -
Retagging Required
1 -
Risk
1 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
3 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
8 -
SAP AI Launchpad
8 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
4 -
SAP Analytics Cloud for Consolidation
3 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP API Management
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BTP
21 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
6 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
2 -
SAP CDC
1 -
SAP CDP
1 -
SAP CDS VIEW
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Migration in Retail Industry
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
9 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
3 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
9 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP LAGGING AND SLOW
1 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Master Data
1 -
SAP Odata
2 -
SAP on Azure
2 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP successfactors
3 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP Utilities
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapmentors
1 -
saponaws
2 -
SAPS4HANA
1 -
SAPUI5
5 -
schedule
1 -
Script Operator
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
Self Transformation
1 -
Self-Transformation
1 -
SEN
1 -
SEN Manager
1 -
service
1 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
Slow loading
1 -
soap
1 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
Substring function
1 -
SuccessFactors
1 -
SuccessFactors Platform
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
14 -
Technology Updates
1 -
Technology_Updates
1 -
terraform
1 -
Threats
2 -
Time Collectors
1 -
Time Off
2 -
Time Sheet
1 -
Time Sheet SAP SuccessFactors Time Tracking
1 -
Tips and tricks
2 -
toggle button
1 -
Tools
1 -
Trainings & Certifications
1 -
Transformation Flow
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
2 -
ui designer
1 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Validations
1 -
Vector Database
2 -
Vector Engine
1 -
Visual Studio Code
1 -
VSCode
1 -
Vulnerabilities
1 -
Web SDK
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- Consuming SAP with SAP Build Apps - Mobile Apps for iOS and Android in Technology Blogs by SAP
- ABAP Cloud Developer Trial 2022 Available Now in Technology Blogs by SAP
- Recap - SAP ALM at SAP Insider Las Vegas 2024 in Technology Blogs by SAP
- SAP Datasphere - Space, Data Integration, and Data Modeling Best Practices in Technology Blogs by SAP
- Navigating OData Service Customization in ABAP Cloud in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 8 | |
| 5 | |
| 5 | |
| 4 | |
| 4 | |
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 3 |