




- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- SAP Native HANA best practices and guidelines for ...
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member30
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-05-2019
9:02 AM
SAP Native HANA combined the best practices and guidelines for significant performance
Hi All,
Just putting up and writing down all the consolidated best practices and guidelines including tips for SAP HANA modeling (Majorly for version 2.0 SPS 02)
Covering underneath points like
- Summary
- Top 10 reasons to choose SAP HANA
- SAP HANA layered architecture (Great to have) and naming conventions
- Join type performance
- SAP HANA best practices and guidelines
- SAP HANA general performance principles
- SAP HANA 2.0 new features for better performance (SAP HANA data modeling)
- Few other HANA Modelling area guidelines like Joins, Calculated columns, Filters & Aggregation
- SAP HANA modeling – Normalized virtual data model scenarios
- SAP HANA General Tips and Tricks
- SAP HANA models - Performance test analysis in QA
- Few reference links and further information
Summary
- The goal is to provide the clear SAP HANA modeling recommendations for setting up HANA information models, optimizing performance, using the SAP HANA modeler and development perspectives, as well as solving complex requirements efficiently in SAP HANA
- Every project/partner companies require SAP HANA best practices and recommendations. We thought it is a great idea to my experience to come up with an SAP HANA best practices and recommendations consolidated document
- This blog talks about SAP HANA modeling techniques based on actual SAP HANA project experiences. I have collected few HANA experts combined experiences contributed in this document have various involvement with multiple HANA implementation projects
- Thought to fabricate high-performing SAP Native HANA data model to lift business solutions in an optimized manner. SAP is continuously improving SAP HANA and with each release new features are distributed to the customers. This, in turn, results in a large and growing number of conceivable approaches to implement a reporting solution based on SAP Native HANA
- Will be enhancing/upgrade this document based on any new findings/discoveries in future HANA releases/ enhancements
Top 10 reasons to choose SAP HANA
SAP HANA layered architecture (Great to have) and naming conventions
As per my view in Native HANA great to have Three (3) Layers like SAP HANA Live models
- Base View (1 layer - Raw data 1:1 source to HANA Base layer, Global Filters)
- Reuse View (Max 3- 4 layers view good to have – Logics, BTL, Mappings, complex)
- Query View/Report View (1 layer – Final View – Thin layer)
P.S – Master data will be maintained as individual with Dimensions with Star model and consumed in relevant transactional HANA Models
Calculation View: CV_<Layer>_<BUSINESS_NAME> e.g. CV_BV_FSR_1
Naming Conventions – Keep the name as short as possible (preferably under 15 chars)
Name every element in CAPITAL LETTERS. Give meaningful business names
- CV_BV_XYZ
- CV_RV_XYZ1, 2, 3 (Based on the complexity layers will increase – max 5 nice to have. Possible chunk to smaller
- CV_QV_XYZ
Good for reconciling and support reason to analyse the issues (Easier troubleshooting)
SAP HANA Best practices and guidelines
Beneath mentioned few HANA best practices and guidelines are from my experience and referral from experience HANA consultants.
Always great to follow and adhere to the SAP HANA best practices and guidelines
- Use Inner join/referential/left outer joins as maximum any way it depends on the business needs, consider replacing them with UNION nodes (where possible). May vary based on a business case to case
- Specify the correct cardinality in joins (n:1 or 1:1) – only if sure
- Use table functions instead of scripted calculation views
- All views/tables are nice to be used with a projection node. Projection nodes improve performance by narrowing the data set (required columns)
- Use star join in calculated view and join calculation view (Dimension – Master data) for better performance (Star schema concept)
- Execute in SQL-engine (Semantics properties or at during custom calculations)
- Avoid transfer of large result sets between the SAP HANA DB and client applications
- Reduce the data set as early as possible. Use design time filters at the lowest level, this helps to reduce at least 20-30% execution time
- Input Parameter (Mandatory/Optional): Placeholders part of the models can be used in the calculation. Can accept multiple values and can be derived from the table (Value help Models) or stored procedures
- Ensure Variables (where clause) is pushed to the lowest level. Confirm using Visualization Plan/plan cache
- Wherever possible use variables and input parameters to avoid fetching a big chunk of data
- Avoid calculated object using IF-THEN-ELSE expression, use restricted measure instead. HANA SPS 11 supports expression using SQL in Restricted column
- Avoid performing joins on calculated columns
- Proceeding, avoid script-based calculation view, WHERE clause will not be pushed down
- Using Filter is better than using Inner Join to limit the dataset
- Avoid joining columns which are having more NULL values
- Before You Begin please check for key columns for any null values at table level. The columns that are part of the joins in the HANA models should not contain any NULL values (resolve null values through ETL or SLT jobs before starting modeling)
- While using Unions make sure there will be no null values in Measure columns otherwise Union Operation will chock (do manage mappings and supply 0 values for null measures columns)
- Execute the SAP HANA models in SQL Engine (Semantics properties)
- Make use of aggregation nodes in your models for handling duplicates
- Avoid filters on the calculated column (consider materializing these columns)
- Do not create working tables in different schemas. This will create security problems on ownership. Instead of that create a separate schema and create all working tables and use it in your Modelling
- One of the best practices in HANA modeling is to define joins on columns with either INTEGER or BIGINT as data types
- Check the performance of the models during the initial development rather than doing at the final phase
- Partition the tables if they are having a huge number of records for better performance Max 2B records per table (or table partition) and max 1000 partitions per table nice to have
- Use analytical privilege latest SQL analytical privilege (SP10) to filter the data based on business requirement
- Join on Key columns and indexed columns
- Use execution plan & Visualization plan to analyse HANA Models performance and take necessary steps if any performance issues observed, Best way to deal with performance issues is after every step of the Modelling rather than final version of the modeling, by this good chance of overcoming memory allocation issues/CPU/memory consumption issues can be addressed during the development stage
- It is not recommended to have joined on calculated columns/fields with NVARCHAR or DECIMAL as data types, might create performance issues. Anyway, case to case it differs based on business needs, however, stick to best practices
These are some of HANA the best practices pursued by numerous SAP HANA consultants. However, still, some complex business requirements coerce us to use or alleviate from such HANA best practices, which can be ignored.
SAP HANA general performance principles
- Identify the long-running queries by reviewing the Performance tab to analyse system performance located under the Administration perspective
- Perform performance testing of HANA information models in a QA environment before hit production environment
- SAP HANA cockpit is a good Admin monitor tool, make use of this tool soon to keep away from the performance bottlenecks and avoid major issues on production environment
- SAP HANA automatically handles Indexes on key columns usually enough, however, when filter conditions on Non- Key fields, please create a secondary index on non-key columns if it is necessary. Creating an index on the non-primary key columns (with high cardinality) will enhance the performance
- Non-SAP applications make use of SDA (Smart data access), no loading required, low cost, maintenance, on virtual tables business will get Realtime data insights if customer applications are greater side to non-SAP side
SAP HANA 2.0 new features for better performance (SAP HANA data modelling)
Simply setting up and writing down all the consolidated few new features for SAP HANA Modelling – Version 2 SPS03 perspective what we witnessed for better performance execution. Maybe a couple might be referenced for reference purpose, nice to adopt them while implementing SAP HANA models and later for support activities & monitoring
- Expose only required columns used in reports and hierarchies at lower data models
- Give meaningful business names for all exposed attributes in final reporting views
- In Latest version please use calculation views of type Dimension (Master Data – in place of Attribute View) and calculation Views of type with cube/star-join (Analytical Views and Calculations Views old concept – Star Schema – Fact Table surrounded by Dimensions (Attribute Views)
- Note: Table functions can be used as input sources for either dimensions or facts
- Nice to have Virtual tables (SDA), SDI: Scheduling and Executing Tasks (Flow Graphics), extended table (Dynamic Tiering) can be consumed in calculation views, so it is essential these features extended to all business cases
- SAP HANA Cockpit – offline and online (SAP HANA admin performance monitor tool)
- SAP Web IDE for SAP HANA - Full support for graphical data models (Web-based)
- Enabling SQL Script with Calculation views (outdated/retired)
- SAP HANA 2.0 use SQL Script table functions instead of script-based calculation views. Script based-calculation models can be refactored into table functions
Consuming non-In Memory data in Calculation views
Dynamic Tiering
• Provides a disk-based columnar SAP HANA database extension using SAP HANA external tables (extended tables)
Smart Data Access
• Provides a virtual access layer to outside SAP HANA data (e.g. other databases, Hadoop systems, etc.) using so-called virtual tables model and approach these scenarios carefully and monitoring query performance
• Ensure that filters and aggregation is pushed to remote sources
Calculation View Enhancements – Hierarchies (Hierarchy SQL Integration)
• Hierarchy-based SQL processing capabilities enabled via SAP HANA View-based hierarchies
Restricted Objects in advanced versions of HANA
The flowing HANA artifacts should not be created by HANA modelers since they are deprecated in the higher versions and required the laborious amount of work for migrating these objects.
- Attribute Views and Analytical Views
- Script based calculation views
- XML – based Classical analytical privilege
Prepare for the future migration from existing old SAP HANA information views
Security and Authorizations – Analytical privileges
Create SQL-based analytic privileges
- Start with general Attribute based Analytic Privilege, then switch to SQL-based
- Use SQL Hierarchies within SQL Analytical Privileges
SAP HANA Cockpit – offline and online – Sample dashboard (Fiori)
Few other HANA modelling area guidelines like Joins, Calculated columns, Filters, Aggregation and so on
The right place to create calculated columns in HANA models
- A view having calculated columns at the lower levels can be slower than a view having the same equivalent calculated columns at the highest level. However, some cases may differ based on business needs (Case by case). The greater part we have actualized in our projects at the top level (Aggregation)
- Calculated columns at the top level (Aggregation) for example, if a calculation such as "Sales amount – Tax amount" is done at the lowest level (for each table record entry) then it will take significantly longer to process. Another example like needs to view rating flag like sales >20,000 to be calculated on the sum of measures. All Date Calculations, Time Stamp Conversions, Time Zone Conversions must be pushed to the TOP level of the Model. Because they are the most expensive statements
- On the lowest level – If the calculated column is a measure like count/sales data for
- which discount/logic needs to be applied. (With the goal that it will not give you an unexpected value)
NOTE: Developer needs to analyze from his end, and create the calculated columns on the best place based on the requirement
Filters
- Apply all filters, Fixed values and the input parameter expressions at the lowest level of the views
- Using filters is better than Inner Join to limit the dataset in terms of performance
- Avoid applying filters on calculated columns
- Use SQL analytical Privilege to filter data, and avoid using classical analytical privilege since they are obsolete in HANA 2.0 SPS03
SAP HANA Restricted measures and logical partitioning (Example on year OR on the plant in the case to view region wise logical partition)
Aggregation
- When using the aggregation node, always try to use at least one of the aggregated functions like COUNT, MIN, MAX, AVG, so that the aggregation works much faster
- If there are some unavoidable duplicates rows getting generated from the models, then use the aggregation node immediate to the JOIN node and remove the duplicates at the very lower level itself
- Never use the TOP aggregation node for removing duplicates, always introduce a separate aggregation node for handling duplicates
- Be careful with the keep flag in aggregation node, where the results get different when this flag is been set in aggregation node (Lower level is best)
SAP HANA modeling – Normalized virtual data model scenarios
SAP HANA virtual data modeling – Key concept 
SAP HANA best practice - Designing larger virtual data models using HANA views

SAP HANA General Tips and Tricks
Value help look up models
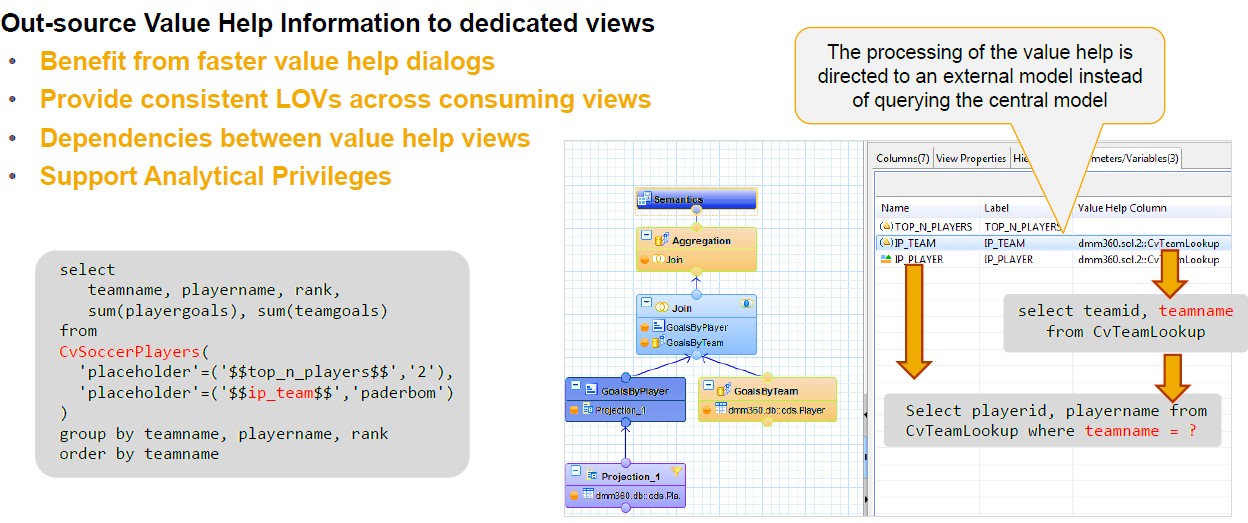
SAP HANA general tips and tricks – filter and aggregation to push down

SAP HANA views – Performance analysis – Must pursue in QA

Few reference links and further information
- https://blogs.sap.com/2014/03/26/hana-modeling-good-practices/
- https://help.sap.com/viewer/fc5ace7a367c434190a8047881f92ed8/2.0.02/en-US/4c1652b4bf39481db9c6b52f6b...
- https://answers.sap.com/questions/385886/performance-tuning-for-calculation-views.html
- https://blogs.sap.com/2015/08/05/performance-bits-and-bites-for-sap-hana-calculation-views/
- https://blogs.sap.com/2015/05/27/get-your-data-running-simple/
- https://blogs.sap.com/2018/03/18/conventional-abap-to-abap-on-hana-mapping-blog-1-of-2/
- https://blogs.sap.com/2013/10/31/simple-script-to-generate-more-data/
- https://blogs.sap.com/2018/04/11/sap-hana-2.0-sps-03-new-developer-features-database-development/
- https://blogs.sap.com/2017/05/05/passing-input-parameters-from-one-calculation-view-to-another/
- https://blogs.sap.com/2018/04/13/sap-hana-2.0-sps-03-security-documentation/
- https://blogs.sap.com/2019/02/20/tips-for-sap-hana-monitoring-and-administration/
 Anand Kumar Kotha
Anand Kumar Kotha
Anand Kotha is an SAP NetWeaver BW solution Senior architect, Native HANA Architect and CoE Senior Manager with KLA, with 17 years’ experience in SAP NetWeaver BW, HANA analytics. He offers significant expertise in the SAP NetWeaver BW reporting area, including design, data integration, data visualization, performance optimization, and the clean-up of existing SAP NetWeaver BW systems. His senior-level expertise in leadership, customer management, pre-sales, hands-on SAP solution design (BW, HANA, and Analytics), business development, consulting, competency building, Competency Global Head for BI HANA and analytics (CoE), projects execution, driving business growth, delivery management, people management, and GTM solutions.
4 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
"TypeScript" "Development" "FeedBack"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
2 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
absl
2 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
AEM
1 -
AI
7 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
3 -
API Call
2 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
5 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
2 -
aws
2 -
Azure
1 -
Azure AI Studio
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
bitcoin
1 -
Blockchain
3 -
bodl
1 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
12 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Application Studio
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
1 -
Business Data Fabric
3 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
4 -
CA
1 -
calculation view
1 -
CAP
3 -
Capgemini
1 -
CAPM
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
4 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Consolidation Extension for SAP Analytics Cloud
2 -
Control Indicators.
1 -
Controller-Service-Repository pattern
1 -
Conversion
1 -
Cosine similarity
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
cyber security
3 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
database tables
1 -
Datasphere
2 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
digital transformation
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
2 -
Fiori
14 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
Flask
1 -
Full Stack
8 -
Funds Management
1 -
General
1 -
Generative AI
1 -
Getting Started
1 -
GitHub
8 -
Grants Management
1 -
groovy
1 -
GTP
1 -
HANA
6 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
2 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
HTML5 Application
1 -
Identity cards validation
1 -
idm
1 -
Implementation
1 -
input parameter
1 -
instant payments
1 -
Integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
iot
1 -
Java
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
8 -
Kerberos for JAVA
8 -
KNN
1 -
Launch Wizard
1 -
learning content
2 -
Life at SAP
5 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
2 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MTA
1 -
Multi-Record Scenarios
1 -
Multiple Event Triggers
1 -
Neo
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
2 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Process Automation
2 -
Product Updates
4 -
PSM
1 -
Public Cloud
1 -
Python
4 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
research
1 -
Resilience
1 -
REST
1 -
REST API
1 -
Retagging Required
1 -
Risk
1 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
3 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
8 -
SAP AI Launchpad
8 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
4 -
SAP Analytics Cloud for Consolidation
3 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BTP
21 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
6 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
2 -
SAP CDC
1 -
SAP CDP
1 -
SAP CDS VIEW
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Migration in Retail Industry
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
10 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
2 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
9 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Odata
2 -
SAP on Azure
1 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP successfactors
3 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP Utilities
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapmentors
1 -
saponaws
2 -
SAPS4HANA
1 -
SAPUI5
4 -
schedule
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
SEN
1 -
SEN Manager
1 -
service
1 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
soap
1 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
Substring function
1 -
SuccessFactors
1 -
SuccessFactors Platform
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
14 -
Technology Updates
1 -
Technology_Updates
1 -
terraform
1 -
Threats
1 -
Time Collectors
1 -
Time Off
2 -
Time Sheet
1 -
Time Sheet SAP SuccessFactors Time Tracking
1 -
Tips and tricks
2 -
toggle button
1 -
Tools
1 -
Trainings & Certifications
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
2 -
ui designer
1 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Validations
1 -
Vector Database
2 -
Vector Engine
1 -
Visual Studio Code
1 -
VSCode
1 -
Web SDK
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- Hack2Build on Business AI – Highlighted Use Cases in Technology Blogs by SAP
- SAP HANA Cloud Vector Engine: Quick FAQ Reference in Technology Blogs by SAP
- Empowering Retail Business with a Seamless Data Migration to SAP S/4HANA in Technology Blogs by Members
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
- CAP LLM Plugin – Empowering Developers for rapid Gen AI-CAP App Development in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 10 | |
| 9 | |
| 5 | |
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 3 | |
| 3 |