
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- New R and enhanced Python API for SAP HANA Machine...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member22
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
04-05-2019
12:52 PM
Announcement
On April 5th 2019, HANA 2.0 SPS 04 has been released! Amongst a whole bunch of great features released (see this blog by Joerg Latza for more details), I am going to focus on two exciting capabilities – the new R and the enhanced Python API for SAP HANA Machine Learning.
Key Points
Python Example - Exploratory Data Analysis
Exploratory Data Analysis (EDA) is an essential tool for Data Science. It is the process of understanding your dataset using statistical techniques and visualizations. The insight that you gain from EDA can help you to uncover issues and errors, give guidance on important variables, draw assumptions from the dataset and build powerful predictive models. The Python API now includes 3 EDA techniques:
Note: The EDA capabilities will be expanded with further release cycles.
The benefit of leveraging these EDA plots with the HANA DataFrame is best illustrated with some performance benchmarks. I tested these plots on the same 10 million row data set and compared the time it took to return to plots in Jupyter.
The below example is using the Titanic data set. Credit for the data goes to https://www.kaggle.com/c/titanic/data.
This is just a preview of the EDA capabilities, an in-depth overview of all the plots and parameters will be detailed in my next blog... stay tuned.
R Example - K Means Clustering
K-means clustering in SAP HANA is an unsupervised machine learning algorithm for data partitioning into a set of k clusters or groups. It classifies observation into groups such that object within the same group are similar as possible.
For this example, I will be using the Iris data set, from University of California, Irvine (https://archive.ics.uci.edu/ml/datasets/iris). This data set contains attributes of a plant iris. There are three species of Iris plants.
Connecting to HANA
Data Exploration
Training K-Means Clustering model
These snippets are not meant to be an exhaustive analysis, simply to showcase some of the capabilities within the API. To learn more about the benefits of using the HANA ML API see this blog, and to get a deeper understanding of the R API, see Kurt's blog once again.
Summary
Appendix
On April 5th 2019, HANA 2.0 SPS 04 has been released! Amongst a whole bunch of great features released (see this blog by Joerg Latza for more details), I am going to focus on two exciting capabilities – the new R and the enhanced Python API for SAP HANA Machine Learning.
Key Points
- The API’s are now generally available from April 5th with the release of HANA 2.0 SPS 04. You can download the packages multiple ways, for example with the HANA Express Download Manager (see this blog) and can get started straight away, for free!
- Alongside the Python API, we now have a comparable API for R! In my previous blogs, I have given a walk-through on how to use the Python API and the value it can bring for building Machine Learning models on massive datasets, but below you'll find a preview of one of the enhanced features - Exploratory Data Analysis. With the addition of the R API, you can train and deploy models in a similar fashion. Below I have provided some code samples for the R API, but for a detailed overview see this blog by Kurt Holst.
- The manual stages of the Machine Learning process (such as feature engineering, data encoding, sampling, feature selection and cross validation) can now be taken care of by the Automated Predictive Library (APL) algorithms. The user only needs to focus on the business problem being solved. See the documentation for more details and for a worked example use this link.
Python Example - Exploratory Data Analysis
Exploratory Data Analysis (EDA) is an essential tool for Data Science. It is the process of understanding your dataset using statistical techniques and visualizations. The insight that you gain from EDA can help you to uncover issues and errors, give guidance on important variables, draw assumptions from the dataset and build powerful predictive models. The Python API now includes 3 EDA techniques:
- Distribution plot
- Pie plot
- Correlation plot
Note: The EDA capabilities will be expanded with further release cycles.
The benefit of leveraging these EDA plots with the HANA DataFrame is best illustrated with some performance benchmarks. I tested these plots on the same 10 million row data set and compared the time it took to return to plots in Jupyter.
- Using a Pandas DataFrame = on average 3 hours
- Using the HANA DataFrame = less than 5 seconds, for each of the 3 plots
The below example is using the Titanic data set. Credit for the data goes to https://www.kaggle.com/c/titanic/data.
# Import DataFrame and EDA
from hana_ml import dataframe
from hana_ml.visualizers.eda import EDAVisualizer
# Connect to HANA
conn = dataframe.ConnectionContext('ADDRESS', 'PORT', 'USER', 'PASSWORD')
# Create the HANA Dataframe and point to the training table
data = conn.table("TABLE", schema="SCHEMA")
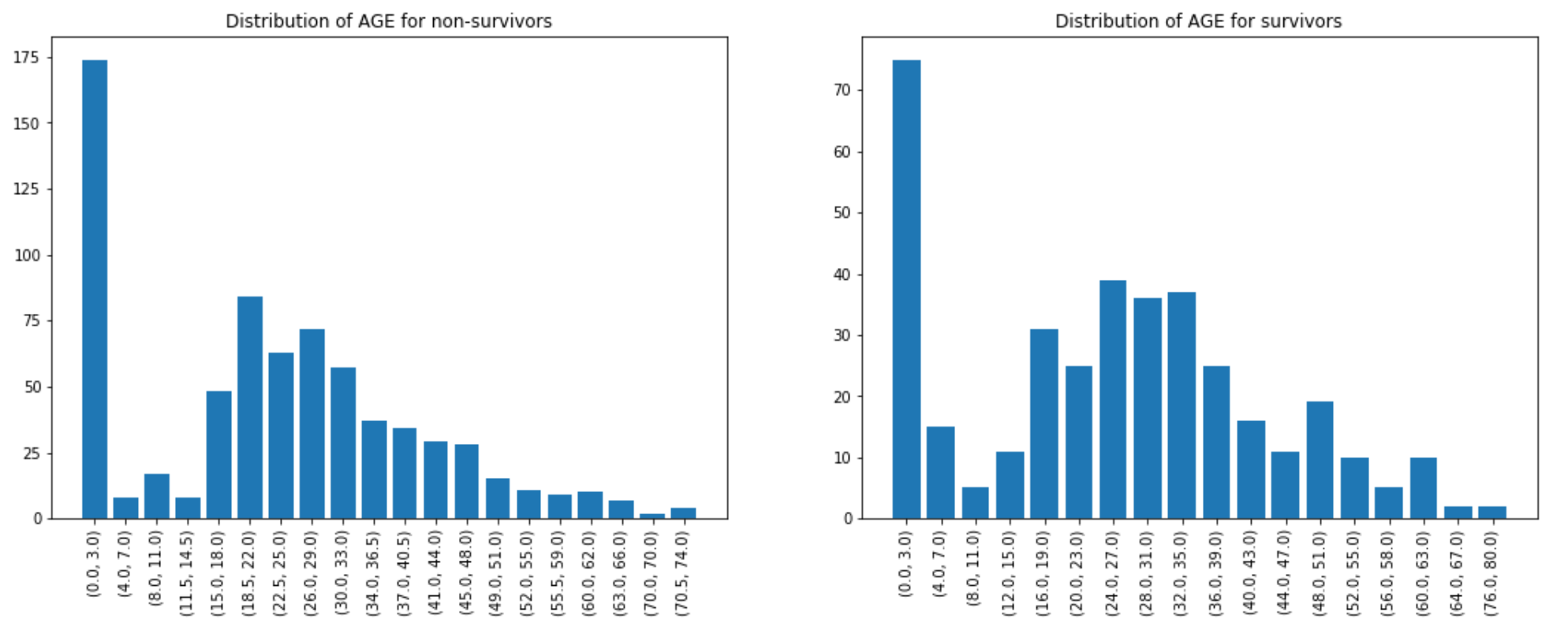
# Create side-by-side distribution plot for AGE of non-survivors and survivors
f = plt.figure(figsize=(18, 6))
ax1 = f.add_subplot(121)
eda = EDAVisualizer(ax1)
ax1, dist_data = eda.distribution_plot(data=data.filter("SURVIVED = 0"), column="AGE", bins=20, title="Distribution of AGE for non-survivors")
ax1 = f.add_subplot(122)
eda = EDAVisualizer(ax1)
ax1, dist_data = eda.distribution_plot(data=data.filter("SURVIVED = 1"), column="AGE", bins=20, title="Distribution of AGE for survivors")
plt.show()This is just a preview of the EDA capabilities, an in-depth overview of all the plots and parameters will be detailed in my next blog... stay tuned.
R Example - K Means Clustering
K-means clustering in SAP HANA is an unsupervised machine learning algorithm for data partitioning into a set of k clusters or groups. It classifies observation into groups such that object within the same group are similar as possible.
For this example, I will be using the Iris data set, from University of California, Irvine (https://archive.ics.uci.edu/ml/datasets/iris). This data set contains attributes of a plant iris. There are three species of Iris plants.
- Iris Setosa
- Iris Versicolor
- Iris Virginica
Connecting to HANA
# Load HANA ML package
library(hana.ml.r)
# Use ConnectionContext to connect to HANA
conn.context <- hanaml.ConnectionContext('ADDRESS','USER','PASSWORD')
# Load data
data <- conn.context$table("IRIS")Data Exploration
# Look at the columns
as.character(data$columns)
>> [1] "ID" "SEPALLENGTHCM" "SEPALWIDTHCM" "PETALLENGTHCM"
[5] "PETALWIDTHCM" "SPECIES"
# Look at the data types
sapply(data$dtypes(), paste, collapse = ",")
>> [1] "ID,INTEGER,10" "SEPALLENGTHCM,DOUBLE,15"
[3] "SEPALWIDTHCM,DOUBLE,15" "PETALLENGTHCM,DOUBLE,15"
[5] "PETALWIDTHCM,DOUBLE,15" "SPECIES,VARCHAR,15"
# Number of rows
sprintf('Number of rows in Iris dataset: %s', data$nrows)
>> [1] "Number of rows in Iris dataset: 150"Training K-Means Clustering model
library(sets)
library(cluster)
library(dplyr)
# Train K Means model with 3 clusters
km <- hanaml.Kmeans(conn.context, data, n.clusters = 3)
# Plot clusters
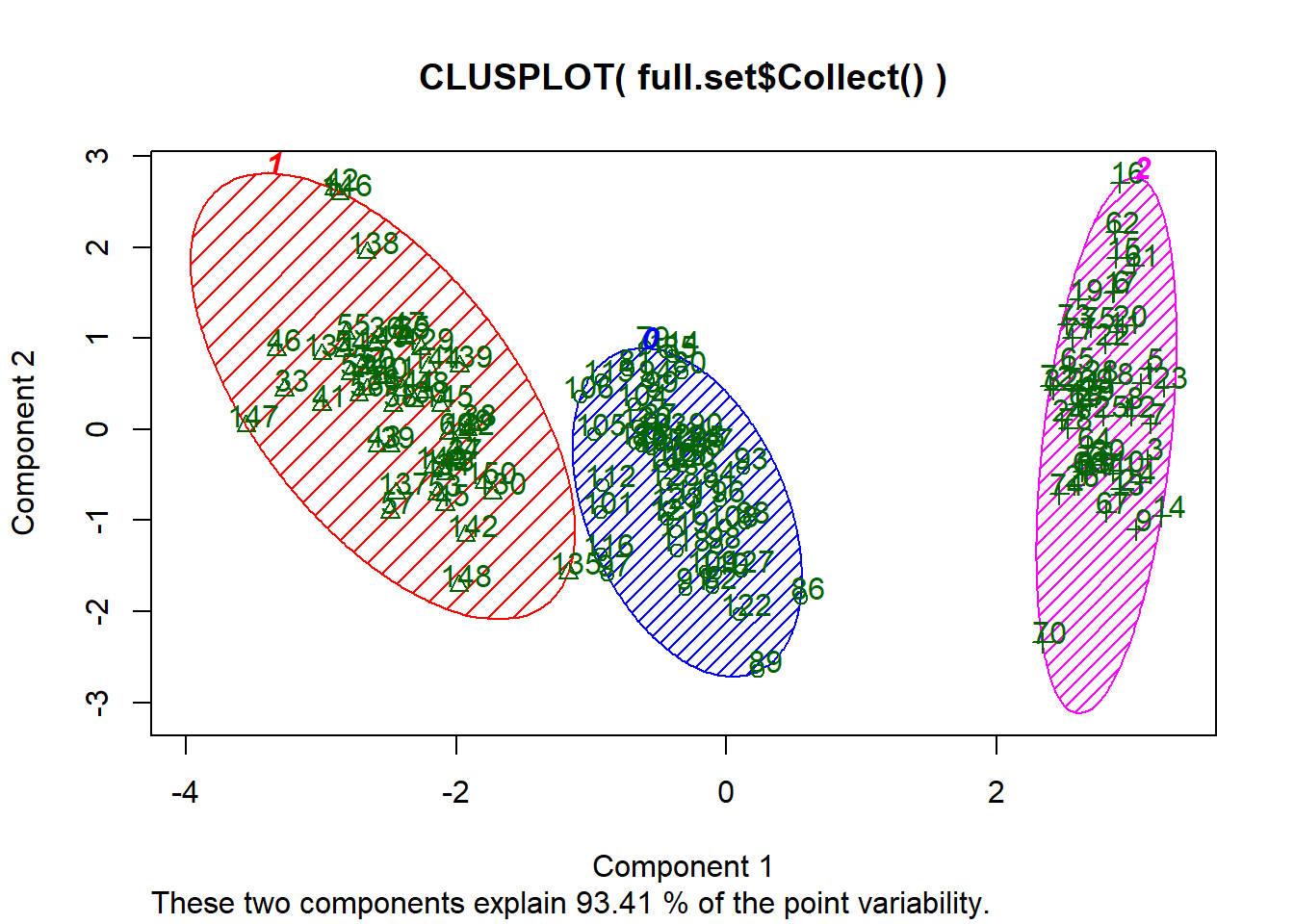
kplot <- clusplot(data$Collect(), km$labels$Collect()$CLUSTER_ID, color = TRUE, shade = TRUE, labels = 2, lines = 0)# Print cluster numbers
Cluster_number<- select(km$labels$Collect(), 2) %>% distinct()
print(Cluster_number)
>> CLUSTER_ID
1 2
2 1
3 0These snippets are not meant to be an exhaustive analysis, simply to showcase some of the capabilities within the API. To learn more about the benefits of using the HANA ML API see this blog, and to get a deeper understanding of the R API, see Kurt's blog once again.
Summary
- R and Python are undoubtedly 2 of the first tools within a Data Scientist's toolbox. With the HANA ML package now supporting both programming languages this can help to boost productivity of your Data Science teams significantly.
- No more cumbersome data transfer, no more waiting for days for models to train, leveraging the HANA DataFrame is a game changer for EDA and Machine Learning.
- As we look to boost productivity we naturally fall into the world of automation. The APL enables easy access to automated algorithms to quickly identify contributing factors, validate hypotheses and build powerful predictive models all within the same API.
- The PAL and APL collectively house over 100 algorithms within HANA. The contents of the API's will be updated with the release cycles. For information on what's available today, follow the links for the R API and the Python API documentation.
Appendix
- What's new in SAP HANA SPS04 - https://blogs.sap.com/2019/04/05/whats-new-in-sap-hana-2.0-sps-04-2/
- Machine Learning from SAP HANA from R - https://blogs.sap.com/2019/04/09/machine-learning-with-sap-hana-from-r/
- Python Client API for Machine Learning in SAP HANA 2.0, Express Edition SPS 03, Revision 33 - https://blogs.sap.com/2018/10/29/python-client-api-for-machine-learning-in-sap-hana-2.0-express-edit...
- What is SAP HANA Automated Predictive Library - https://help.sap.com/viewer/cb31bd99d09747089754a0ba75067ed2/2.5.0.0/en-US
- End-to-End APL example - https://help.sap.com/doc/0172e3957b5946da85d3fde85ee8f33d/2.0.03/en-US/html/hana_ml.html#end-to-end-...
- Blog explaining the benefits of the HANA ML package - https://blogs.sap.com/2018/12/17/diving-into-the-hana-dataframe-python-integration-part-1/
- R API Documentation - https://help.sap.com/doc/c48739beb06a4304a98e44b4d5b60a50/2.0.04/en-US/hana.ml.r/html/00Index.html
- Python API Documentation - https://help.sap.com/doc/0172e3957b5946da85d3fde85ee8f33d/2.0.03/en-US/html/index.html
- Learn about the SAP HANA DataFrame - https://blogs.sap.com/2018/12/17/diving-into-the-hana-dataframe-python-integration-part-1/
- Learn about the ML capabilities within the Python API - https://blogs.sap.com/2019/01/28/diving-into-the-hana-dataframe-python-integration-part-2/
- SAP Managed Tags:
- Machine Learning,
- SAP HANA,
- Big Data,
- SAP Business Technology Platform
Labels:
6 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
103 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
69 -
Expert
1 -
Expert Insights
177 -
Expert Insights
325 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,576 -
Product Updates
370 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,872 -
Technology Updates
457 -
Workload Fluctuations
1
Related Content
- revamped SAP First Guidance Collection in Technology Blogs by Members
- SAP Datasphere News in April in Technology Blogs by SAP
- Elevate Your SAP Cloud ALM Experience: Introducing the New ‘’Launchpad’’ and ‘’Welcome App’’ in Technology Blogs by SAP
- The 2024 Developer Insights Survey: The Report in Technology Blogs by SAP
- SAP Datasphere + SAP S/4HANA: Your Guide to Seamless Data Integration in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 24 | |
| 8 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 6 | |
| 6 | |
| 5 |