
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- PAi Series Blog 6: Defining the Target
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
paul_ohara2
Discoverer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-28-2019
9:23 AM
Welcome to the sixth installment in the PAi and S/4Hana Blog Series. In this installment I'd like to talk about one of the most important stages of a use case – defining the target value to be predicted. It is critical that the target value is correctly defined, as it can have a significant impact on the output for a use case. In this entry, we will see how what appears to be a straightforward classification use case, can be solved through distinctly different targets, one requiring regression, and the other classification.
Let us imagine we have a use case where the goal is determining if the delivery of an item will be “late” or “not late” (yes, it is the return of the stock in transit predictive scenario). Let us also assume initial discussions with the business stakeholders have occurred, and that we were informed that on-time delivery means delivery occurring either before or on the planned delivery date. Let us also assume the technical stakeholders have identified all tables/views related to item delivery, and made them available. Now the fun begins!
From the initial description this suggests the solution requires a classification algorithm. This is a good starting point, though we will only be able to verify this once we have performed an initial data exploration. When we explore the data, our goal is to determine:
The technical stakeholders inform us the data relating to deliveries exists across 5 tables, and none of these tables contain a column stating a delivery was late or not late. This means we need to devise a way materialize our target from the data.
As shown in Figure 1, looking into the data and from discussions with the technical stakeholders, we uncover several date fields exist:

Figure 1 - Identified Date Fields
From this, and as demonstrated in Figure 2, we identify it is possible to materialize the classification target through determining if the actual delivery date is after the planned delivery date, that is:
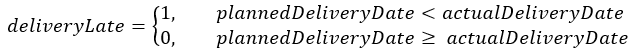

Figure 2 - Defining the Classification Target
Exploring the data, we note an alternative approach is possible, and we can materialize a different target that will allow us to achieve the same results. If you look at the data you note there are several date fields, and it is possible to predict a difference in days between the planned and actual delivery date. Utilizing this prediction, if the value is 1 or more, it is possible to indicate a late delivery will occur.
To achieve this would require a different target, and to utilize a regression algorithm. Before continuing, we decide more information on the date fields is required. We reach out to our business and technical stakeholder colleagues, and are informed all planned date fields are mandatory, with the actual delivery dates updated when the related action occurs.
This means our ideas are plausible, and as shown in Figure 3, we derive the new target:
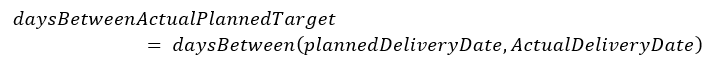

Figure 3 - Defining the Regression Target
Then as shown in Figure 4, using the prediction, we would derive a late delivery through:
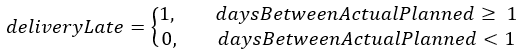

Figure 4 - Utilizing Regression Prediction to derive Late Delivery Prediction
Though that is not the end, as shown in Figure 5, after a further review of this new prediction target, we realize it would be possible to provide an additional piece of information:

Figure 5 - Calculated Delivery Date Prediction
We again reach out to our business stakeholders, inform them of this new potential piece of information, and request if it will be of value. The stakeholders are energized and enthusiastic on utilizing this new piece of information for incorporating as a correction factor for planned delivery dates! This is great news.
As you can see, on the initial analysis we considered a classification solution, though on analysis of the data we uncovered and switched to a regression. This regression solution not only met the original use case scenario, but generated added value to the stakeholders.
The take away is that the definition of the target is a critical component of the use case, and although an initial intuition of the target may be given through the use case description, the true target definition can only be finalized once the data is explored. Furthermore, a key part of this process was continuous discussion with our business and technical stakeholders.
Let us imagine we have a use case where the goal is determining if the delivery of an item will be “late” or “not late” (yes, it is the return of the stock in transit predictive scenario). Let us also assume initial discussions with the business stakeholders have occurred, and that we were informed that on-time delivery means delivery occurring either before or on the planned delivery date. Let us also assume the technical stakeholders have identified all tables/views related to item delivery, and made them available. Now the fun begins!
From the initial description this suggests the solution requires a classification algorithm. This is a good starting point, though we will only be able to verify this once we have performed an initial data exploration. When we explore the data, our goal is to determine:
- The target attribute for the classification task can be materialized from the data
- That classification is the best approach to meeting the use case goal, and no alternatives exist which are better supported by the data.
Exploring the Data and Determining the Target
The technical stakeholders inform us the data relating to deliveries exists across 5 tables, and none of these tables contain a column stating a delivery was late or not late. This means we need to devise a way materialize our target from the data.
As shown in Figure 1, looking into the data and from discussions with the technical stakeholders, we uncover several date fields exist:
- Order Creation Date – the date the order was placed
- Planned Packaging Date – the date the order is planned to be packaged
- Actual Packaging Date – the actual date the order packaging occurred
- Planned Shipping Date – the date the order is planned to be shipped
- Actual Packaging Date – the actual date the order shipping occurred
- Planned Delivery Date – the date delivery is planned to occur on
- Actual Delivery Date – the actual date delivery occurred
Figure 1 - Identified Date Fields
From this, and as demonstrated in Figure 2, we identify it is possible to materialize the classification target through determining if the actual delivery date is after the planned delivery date, that is:
Figure 2 - Defining the Classification Target
Exploring the data, we note an alternative approach is possible, and we can materialize a different target that will allow us to achieve the same results. If you look at the data you note there are several date fields, and it is possible to predict a difference in days between the planned and actual delivery date. Utilizing this prediction, if the value is 1 or more, it is possible to indicate a late delivery will occur.
To achieve this would require a different target, and to utilize a regression algorithm. Before continuing, we decide more information on the date fields is required. We reach out to our business and technical stakeholder colleagues, and are informed all planned date fields are mandatory, with the actual delivery dates updated when the related action occurs.
This means our ideas are plausible, and as shown in Figure 3, we derive the new target:
Figure 3 - Defining the Regression Target
Then as shown in Figure 4, using the prediction, we would derive a late delivery through:
Figure 4 - Utilizing Regression Prediction to derive Late Delivery Prediction
Though that is not the end, as shown in Figure 5, after a further review of this new prediction target, we realize it would be possible to provide an additional piece of information:
Figure 5 - Calculated Delivery Date Prediction
We again reach out to our business stakeholders, inform them of this new potential piece of information, and request if it will be of value. The stakeholders are energized and enthusiastic on utilizing this new piece of information for incorporating as a correction factor for planned delivery dates! This is great news.
As you can see, on the initial analysis we considered a classification solution, though on analysis of the data we uncovered and switched to a regression. This regression solution not only met the original use case scenario, but generated added value to the stakeholders.
The take away is that the definition of the target is a critical component of the use case, and although an initial intuition of the target may be given through the use case description, the true target definition can only be finalized once the data is explored. Furthermore, a key part of this process was continuous discussion with our business and technical stakeholders.
- SAP Managed Tags:
- Machine Learning,
- SAP Predictive Analytics,
- SAP Predictive Analytics integrator,
- SAP S/4HANA
Labels:
1 Comment
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
107 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
72 -
Expert
1 -
Expert Insights
177 -
Expert Insights
340 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
14 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
384 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,872 -
Technology Updates
470 -
Workload Fluctuations
1
Related Content
- Exploring ML Explainability in SAP HANA PAL – Classification and Regression in Technology Blogs by SAP
- Syniti RDG provides an effortless way to create Data Model extension. in Technology Q&A
- Replication Flow Blog Part 6 – Confluent as Replication Target in Technology Blogs by SAP
- SAP BTP FAQs - Part 2 (Application Development, Programming Models and Multitenancy) in Technology Blogs by SAP
- Currency Translation in SAP Datasphere in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 17 | |
| 14 | |
| 13 | |
| 8 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |