
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- NodeJS chatbot tutorial: A movie bot with SAP Conv...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-19-2019
6:00 AM
By the end of this tutorial, you will be able to build a fully functional movie bot! It will be able to make movie recommendations based on several criteria. We're using SAP Conversational AI platform to build the bot and The Movie Database for information on movies.
Here's a demo chat with Movie Bot:
[caption id="" align="aligncenter" width="640"]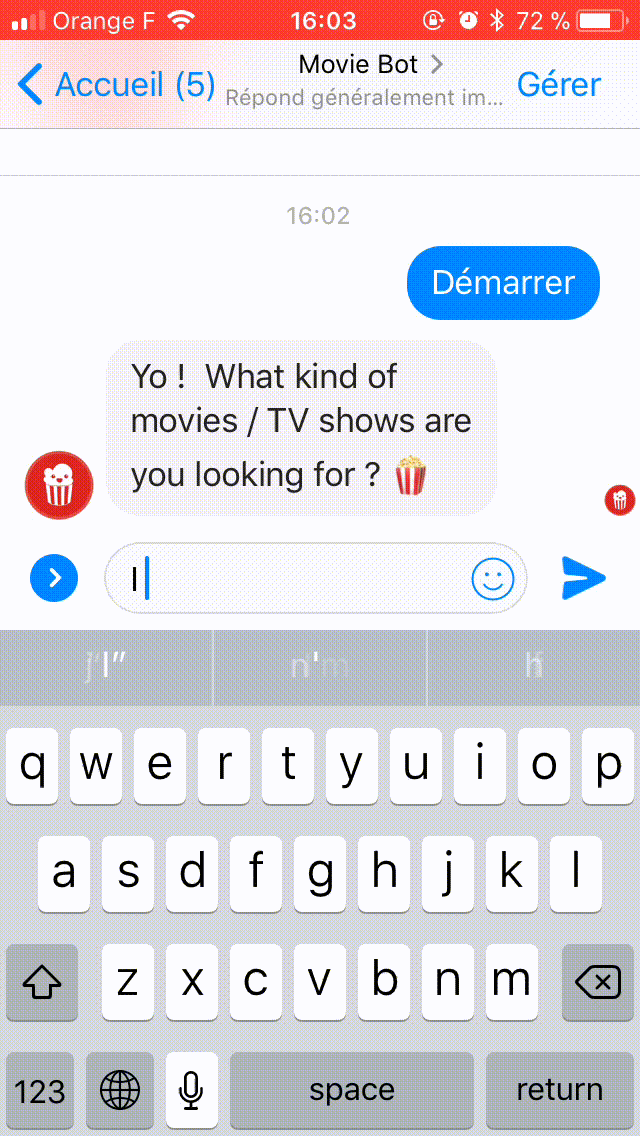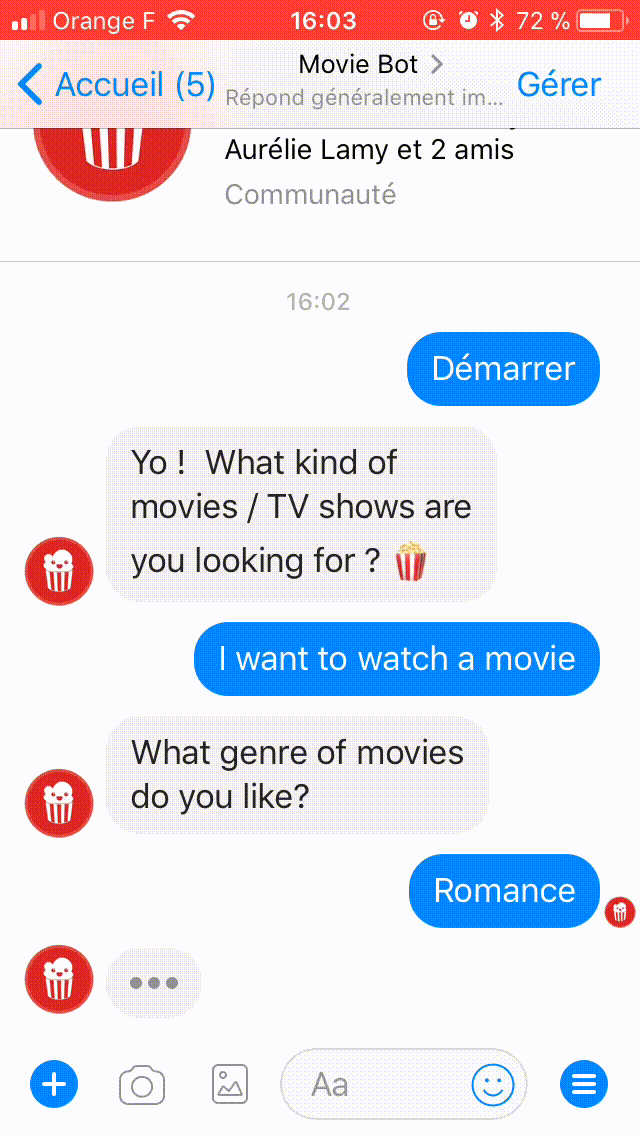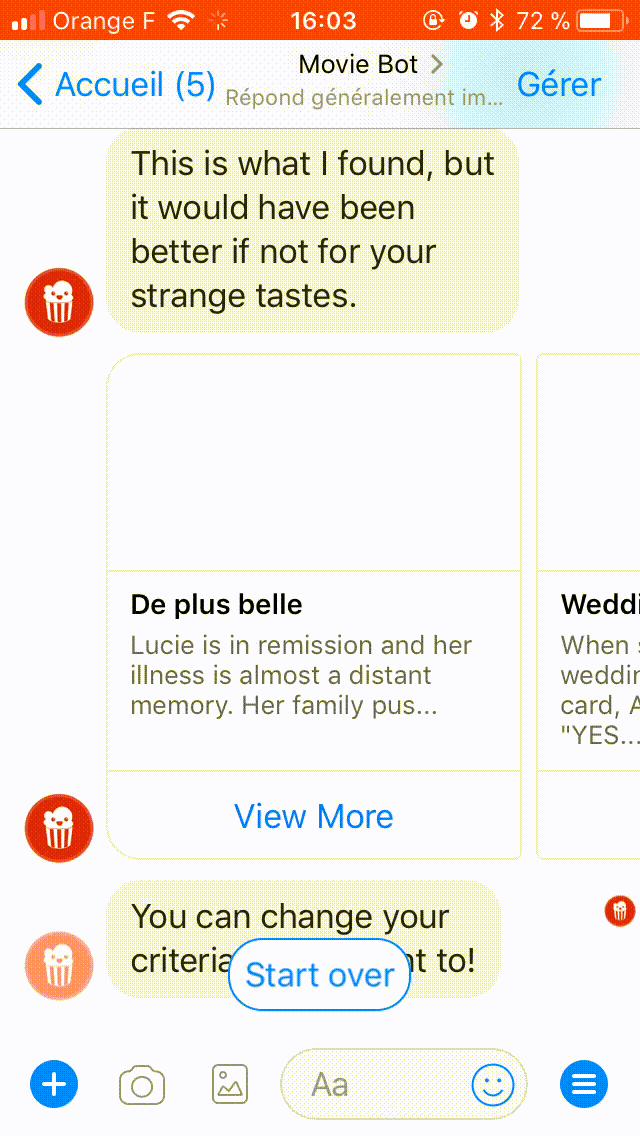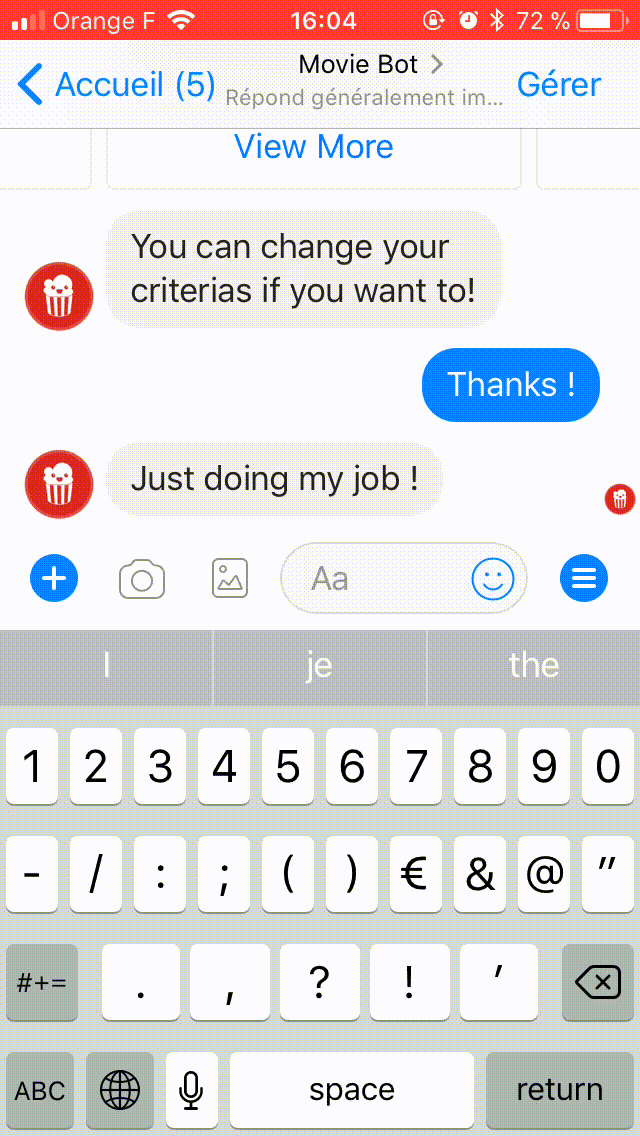 Movie bot in action[/caption]
Movie bot in action[/caption]
Interacting with third party APIs (such as The Movie Database) allows for much more interesting use cases that simple Q/A chatbots. With Bot Skills, we added the option to call webhooks directly from the builder, which makes it even easier.
Today's bot requires several steps:
You'll need a SAP Conversational AI account, Node.JS and potentially Ngrok for testing.
Before we jump in, please check this guide instead if you are looking for a guide detailing the creation of your first bot.
This tutorial covers Node.JS only. If you would rather code with Python, check this tutorial covering a similar use case.
Let's get to it!
Intents are helpful to determine the overall meaning of a sentence. For our use case, knowing that the user wants to watch something is not enough.
We need to know what the users want to watch.
Entities are designed to solve this problem: they extract key information in a sentence.
Intents make you understand that you have to do something. Entities help you actually do something.
Let's imagine you are a telco company providing phone and internet access, and your bot has an intent that understands when people are complaining about an outage:
[caption id="" align="aligncenter" width="590"] Entities extract key information from a sentence[/caption]
Entities extract key information from a sentence[/caption]
The entities extracted will help understand what is going wrong, where and since when.
For our movie bot, we will try to extract 3 key pieces of information:
To help you speed up your development, SAP Conversational AI extracts several entities by default : Dates, locations, phone numbers... An exhaustive list is available here.
The
[caption id="" align="aligncenter" width="488"]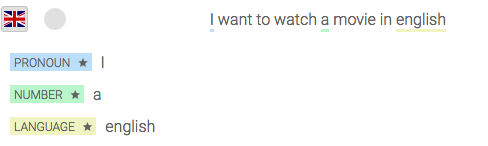 Gold Entities - Language[/caption]
Gold Entities - Language[/caption]
See the little star next to the entity name? It differentiates a gold entity from a custom one.
We will use it to fulfil our third requirement: the movie language.
We will create custom entities to extract the information we need. As with intents, training is very important: the more examples you add to your bot, the more accurate it gets.
Training your entities can happen through multiple intents. Entities are independent of intents.
For our movie bot, we only need one intent,
Open the intent
To tag your expressions, select the text you want to tag and type your entity name:
[caption id="attachment_7897" align="aligncenter" width="1024"] Tagging custom entities[/caption]
Tagging custom entities[/caption]
You should add many more examples: 15 would be nice, but a production-ready bot would require at least 50 examples to perform well. To speed up the process you can fork the entities built within this bot [recording entity, genre entity] and then fork the discover intent from this bot.
You can see here that "French" was detected as a nationality, not a language, because that's what it is in this context. When building the bot flow, we'll make sure to check for these two entities.
Now that we have labeled have our entities we are going to enrich them! Open the entities panel from your bot under the training tab as showed below:
[caption id="attachment_7898" align="aligncenter" width="1024"] Entities section[/caption]
Entities section[/caption]
Now let's open the
[caption id="attachment_7899" align="aligncenter" width="1024"] Entity panel[/caption]
Entity panel[/caption]
Within the entity panel you have access to different options for your entity:
For more in depth information about entities you can read our detailed documentation.
In our case our
Add all the different genres to our list of values and don't forget to also add synonyms such as SF, Sci-Fi for Science Fiction, Romantic for Romance or Animated, Cartoon for Animation. You can fetch the all list of values from there. As you can see from the JSON above, there are ids associated with the genres. The reason is because the Movie Database can't search for a specific genre based on its English name, but rather on a custom number. What we can to achieve is to associate for each of the genre values a specific id that will be return within the JSON of the NLP API so we can pass it on to the Movie Database API. This is the purpose of custom enrichments: whenever an entity is detected, the JSON returned by the NLP API is enriched with additional information about the entity.
Within the custom enrichment panel we need to create 3 keys:
In order to add a custom enrichment click
[caption id="attachment_7900" align="aligncenter" width="1024"] Custom enrichments for name[/caption]
Custom enrichments for name[/caption]
[caption id="attachment_7901" align="aligncenter" width="1024"] Custom enrichments for ids[/caption]
Custom enrichments for ids[/caption]
[caption id="attachment_7902" align="aligncenter" width="1024"] Custom enrichments for article[/caption]
Custom enrichments for article[/caption]
You can fork the whole entity from this page which will include the enrichment. Now this is done let's test is within the test console. If you send the sentence "I want to watch an animation movie" you now should now see the following custom enrichment:
Great, now our enrichment gives us the generic name, id and the article! Let's do the same thing for the recording entity, go back to the entities panel and click on recording then make it restricted and add all possible values and synonyms for tv show and movie (such as tv shows, shows, motion picture, film, films, movies, etc.) see the entire list here. Now go to custom enrichments and add the key
It should look like this:
[caption id="attachment_7903" align="aligncenter" width="1024"] Custom enrichments for type[/caption]
Custom enrichments for type[/caption]
Sending back our sentence "I want to watch an animation movie" we now also have the enrichment for recording:
Since we just need to make sure all our criteria are filled before calling a Node.JS API, the build part will be rather simple.
We will just need one skill, let's call it
You can find an example of a configured skill here.
We want to trigger this skill if the intent @Discover is present:
[caption id="" align="aligncenter" width="1083"]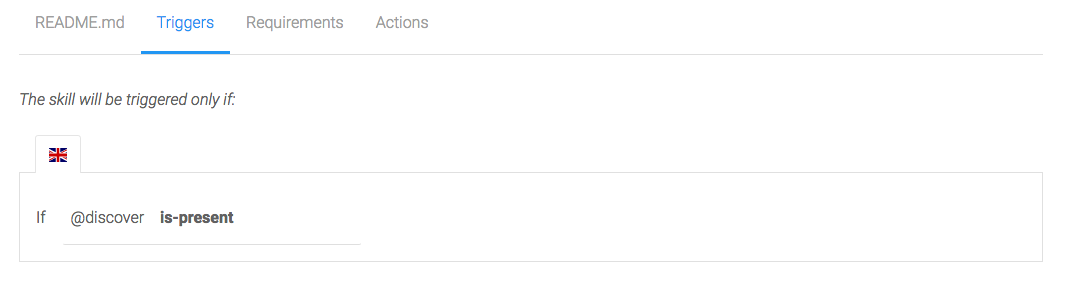 Message triggers[/caption]
Message triggers[/caption]
This tab helps you collect data before moving to Actions.We want to make sure the user specifies a recording, a genre, a language and a yes or no intent before moving on:
[caption id="attachment_7905" align="aligncenter" width="1024"] Requirements[/caption]
Requirements[/caption]
The requirements will be checked one by one. They can all be fulfilled on the first message, for example if the user says I want to watch a crime movie in English, then the Actions will be triggered immediately.
For each Requirement, you can choose to send a message if it is complete or if it is missing.
Sending messages when a requirement is complete can make your bot more lively: A crime movie? I love them too!, but are almost mandatory when the requirement is missing: You need to ask your users to fill what you need to know.
For example, I send quick replies with suggested genres if #genre is missing:
[caption id="" align="aligncenter" width="868"]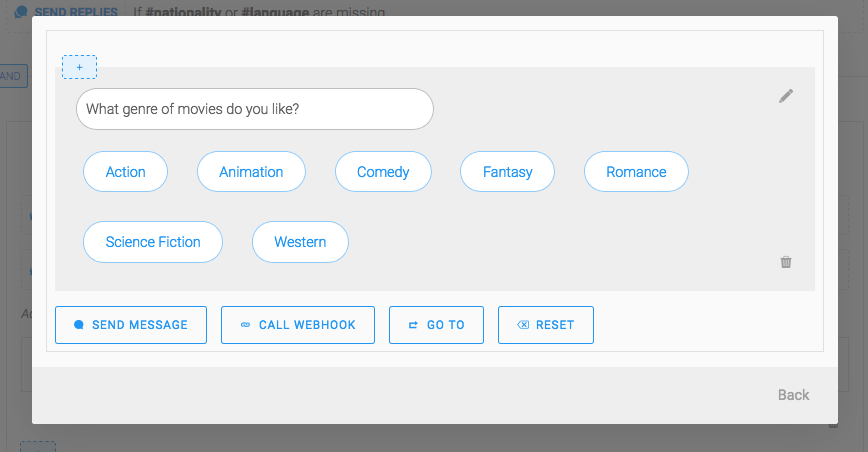 Conditional message if a requirement is missing[/caption]
Conditional message if a requirement is missing[/caption]
For the confirmation we are using the memory to display a dynamic message to validate the choice of the user using @yes and @no intent:
[caption id="attachment_7906" align="aligncenter" width="1024"] Using the memory for dynamic message[/caption]
Using the memory for dynamic message[/caption]
Once you have set up questions for the 4 groups of entities, go to the
Once the requirements are fulfilled, we want to call our API to actually perform the search if the user said yes else we reset the memory and ask again what the user wants to watch.
If
If
Next, add an action
[caption id="attachment_7908" align="aligncenter" width="1024"] Actions[/caption]
Actions[/caption]
If you don't have a public server, or if you want to test your bot during development, ngrok is a very handy tool: It creates a public URL for you and forwards requests to your computer.
Once you installed it, run
And copy the
All your bot needs now is its API to get your movies!
The NodeJS part of this bot is fairly simple: It will behave as an HTTP proxy between SAP Conversational AI and The Movie Database.
When your application receives a request from SAP Conversational AI, it sends a search query to the Movie Database with the criteria of your user and formats the JSON answer to the SAP Conversational AI message format.
[caption id="attachment_7071" align="aligncenter" width="421"] Bot API diagram[/caption]
Bot API diagram[/caption]
You can clone the entire project directly from our Git repository : https://github.com/plieb/movie-bot-skills-training
Step 1 - scaffolding your project
Step 2 - getting a TMDb API token
You will need a token to use the Movie Database API, go here to generate one, and edit your
Step 3 - filling your index.js with an Express application
Let's create an Express application to handle the requests from SAP Conversational AI. To better organize our project, as seen in Step 1, we have a folder
Step 4 - filling discover-movies/index.js
We ask SAP Conversational AI to send a POST request to
The main goal of our controller is to pick and format the preferences from the memory to send them to the Movie Database's API:
Step 5 - filling discover-movies/movieApi.js
Now that we have extracted and formatted all the filters of the request, we need to send the request to the Movie Database and format the answer:
Step 6 - Start the engine!
That's all! You're ready to test your bot.
Start your application by running:
All being well, you should see:
Movie recommendation, weather, health, traffic... With third-party APIs, everything is possible! Now that you're familiar with the workflow, we can’t wait to hear from you about what you’re building! And remember you’re very welcome to contact us if you need help, trough the comment section below or via Slack.
Here's a demo chat with Movie Bot:
[caption id="" align="aligncenter" width="640"]
Movie bot in action[/caption]WHAT ARE WE BUILDING TODAY?
Interacting with third party APIs (such as The Movie Database) allows for much more interesting use cases that simple Q/A chatbots. With Bot Skills, we added the option to call webhooks directly from the builder, which makes it even easier.
Today's bot requires several steps:
- Extracting key pieces of information in a sentence
- Building the bot flow (triggers, requirements, actions)
- Creating and connecting a bot API able to fetch data from The Movie Database
You'll need a SAP Conversational AI account, Node.JS and potentially Ngrok for testing.
Before we jump in, please check this guide instead if you are looking for a guide detailing the creation of your first bot.
This tutorial covers Node.JS only. If you would rather code with Python, check this tutorial covering a similar use case.
Let's get to it!
I/ EXTRACTING KEY INFO FROM A SENTENCE
Intents are helpful to determine the overall meaning of a sentence. For our use case, knowing that the user wants to watch something is not enough.
We need to know what the users want to watch.
Entities are designed to solve this problem: they extract key information in a sentence.
Intents make you understand that you have to do something. Entities help you actually do something.
Let's imagine you are a telco company providing phone and internet access, and your bot has an intent that understands when people are complaining about an outage:
[caption id="" align="aligncenter" width="590"]
Entities extract key information from a sentence[/caption]The entities extracted will help understand what is going wrong, where and since when.
For our movie bot, we will try to extract 3 key pieces of information:
- What the user wants to watch (movie vs TV show)
- What genre they are looking for
- In which language
USING GOLD ENTITIES
To help you speed up your development, SAP Conversational AI extracts several entities by default : Dates, locations, phone numbers... An exhaustive list is available here.
The
Language entity will be helpful:[caption id="" align="aligncenter" width="488"]
Gold Entities - Language[/caption]See the little star next to the entity name? It differentiates a gold entity from a custom one.
We will use it to fulfil our third requirement: the movie language.
CREATING CUSTOM ENTITIES
We will create custom entities to extract the information we need. As with intents, training is very important: the more examples you add to your bot, the more accurate it gets.
Training your entities can happen through multiple intents. Entities are independent of intents.
For our movie bot, we only need one intent,
discover, and 2 entities:recordingto identify that the user wants to watch a movie or a tv showgenre
Open the intent
discover and add expressions. Make sure to cover every possibility, this means a healthy mix of expressions with:- No entities at all: “My boyfriend wants to watch something tonight”
- One entity: “I want to watch a movie”
- Many entities: “Can you recommend me some French drama TV shows?”
To tag your expressions, select the text you want to tag and type your entity name:
[caption id="attachment_7897" align="aligncenter" width="1024"]
Tagging custom entities[/caption]You should add many more examples: 15 would be nice, but a production-ready bot would require at least 50 examples to perform well. To speed up the process you can fork the entities built within this bot [recording entity, genre entity] and then fork the discover intent from this bot.
You can see here that "French" was detected as a nationality, not a language, because that's what it is in this context. When building the bot flow, we'll make sure to check for these two entities.
ADDING CUSTOM ENRICHMENTS
Now that we have labeled have our entities we are going to enrich them! Open the entities panel from your bot under the training tab as showed below:
[caption id="attachment_7898" align="aligncenter" width="1024"]
Entities section[/caption]Now let's open the
genre entity. If you look at the top right of the panel you should see a toggle saying free - restricted and settings, open it so we can explain in details the different options you have access to:[caption id="attachment_7899" align="aligncenter" width="1024"]
Entity panel[/caption]Within the entity panel you have access to different options for your entity:
- Free vs Restricted - A free custom entity is used when you don’t have a strict list of values and want machine learning to detect all possible values whereas a restricted custom entity is used if you have a strict list of words to detect and don’t need automatic detection of the entity.
- Fuzzy matching - Fuzzy matching is an index between 0 and 1 to indicate how close a word can be from the one in your entity list of values. If the word is above this index then the platform will tag it as the closest value within your list.
- List of values - This is where you can add all the list of values of your entity which could be different values or synonyms
For more in depth information about entities you can read our detailed documentation.
In our case our
genre entity is going to be restricted as theMovie Database API only manages a specific list of genres. Here is the list below:[
{ id: 28, name: 'Action' },
{ id: 12, name: 'Adventure' },
{ id: 16, name: 'Animation' },
{ id: 35, name: 'Comedy' },
{ id: 80, name: 'Crime' },
{ id: 99, name: 'Documentary' },
{ id: 18, name: 'Drama' },
{ id: 10751, name: 'Family' },
{ id: 14, name: 'Fantasy' },
{ id: 36, name: 'History' },
{ id: 27, name: 'Horror' },
{ id: 10402, name: 'Music' },
{ id: 9648, name: 'Mystery' },
{ id: 10749, name: 'Romance' },
{ id: 878, name: 'Science Fiction' },
{ id: 53, name: 'Thriller' },
{ id: 10752, name: 'War' },
{ id: 37, name: 'Western' }
]Add all the different genres to our list of values and don't forget to also add synonyms such as SF, Sci-Fi for Science Fiction, Romantic for Romance or Animated, Cartoon for Animation. You can fetch the all list of values from there. As you can see from the JSON above, there are ids associated with the genres. The reason is because the Movie Database can't search for a specific genre based on its English name, but rather on a custom number. What we can to achieve is to associate for each of the genre values a specific id that will be return within the JSON of the NLP API so we can pass it on to the Movie Database API. This is the purpose of custom enrichments: whenever an entity is detected, the JSON returned by the NLP API is enriched with additional information about the entity.
Within the custom enrichment panel we need to create 3 keys:
name- to map synonyms under a same valueid- to enrich with the id of the Movie Databasearticle- to add the article of the genre (we will use this later)
In order to add a custom enrichment click
add new key and add the three keys listed above - for the article set the default key value to 'a' as most of the genres would be with 'a'. Within name you can start adding the specific enrichment and map it to all the different values for your article, id and name such as below:[caption id="attachment_7900" align="aligncenter" width="1024"]
Custom enrichments for name[/caption][caption id="attachment_7901" align="aligncenter" width="1024"]
Custom enrichments for ids[/caption][caption id="attachment_7902" align="aligncenter" width="1024"]
Custom enrichments for article[/caption]You can fork the whole entity from this page which will include the enrichment. Now this is done let's test is within the test console. If you send the sentence "I want to watch an animation movie" you now should now see the following custom enrichment:
"genre": [
{
"value": "animated",
"raw": "animated",
"confidence": 0.99,
"name": "animation",
"id": 16,
"article": "an"
}Great, now our enrichment gives us the generic name, id and the article! Let's do the same thing for the recording entity, go back to the entities panel and click on recording then make it restricted and add all possible values and synonyms for tv show and movie (such as tv shows, shows, motion picture, film, films, movies, etc.) see the entire list here. Now go to custom enrichments and add the key
type and add 2 specific values:movie- for all movies synonymstv- for all tv shows synonyms
It should look like this:
[caption id="attachment_7903" align="aligncenter" width="1024"]
Custom enrichments for type[/caption]Sending back our sentence "I want to watch an animation movie" we now also have the enrichment for recording:
"recording": [
{
"value": "movie",
"raw": "movie",
"confidence": 0.99,
"type": "movie"
}
]
II/ BUILDING YOUR BOT FLOW
Since we just need to make sure all our criteria are filled before calling a Node.JS API, the build part will be rather simple.
We will just need one skill, let's call it
discover.You can find an example of a configured skill here.
TRIGGERS
We want to trigger this skill if the intent @Discover is present:
[caption id="" align="aligncenter" width="1083"]
Message triggers[/caption]REQUIREMENTS
This tab helps you collect data before moving to Actions.We want to make sure the user specifies a recording, a genre, a language and a yes or no intent before moving on:
[caption id="attachment_7905" align="aligncenter" width="1024"]
Requirements[/caption]The requirements will be checked one by one. They can all be fulfilled on the first message, for example if the user says I want to watch a crime movie in English, then the Actions will be triggered immediately.
For each Requirement, you can choose to send a message if it is complete or if it is missing.
Sending messages when a requirement is complete can make your bot more lively: A crime movie? I love them too!, but are almost mandatory when the requirement is missing: You need to ask your users to fill what you need to know.
For example, I send quick replies with suggested genres if #genre is missing:
[caption id="" align="aligncenter" width="868"]
Conditional message if a requirement is missing[/caption]For the confirmation we are using the memory to display a dynamic message to validate the choice of the user using @yes and @no intent:
[caption id="attachment_7906" align="aligncenter" width="1024"]
Using the memory for dynamic message[/caption]Once you have set up questions for the 4 groups of entities, go to the
Actions tab.ACTIONS
Once the requirements are fulfilled, we want to call our API to actually perform the search if the user said yes else we reset the memory and ask again what the user wants to watch.
If
_memory.no is present - reset the whole memory and send a message such as "Let's start again, what do you want to watch?"If
_memory.yes is present create a CALL WEHBOOK action. You can either type a full URL (eg: https://mydomainname.com/discover-movies), or a relative url (/discover-movies). SAP Conversational AI will use the parameter Bot base URL in you bot settings when you type a relative URL.Next, add an action
UPDATE CONVERSATION > EDIT MEMORY > RESET ALL MEMORY to empty the memory once the call has been made.[caption id="attachment_7908" align="aligncenter" width="1024"]
Actions[/caption]If you don't have a public server, or if you want to test your bot during development, ngrok is a very handy tool: It creates a public URL for you and forwards requests to your computer.
Once you installed it, run
ngrok http 5000And copy the
Forwarding URL in HTTPS (https://XXX.ngrok.io) to your bot Settings ("Bot webhook base URL" field). All requests made to these URL will be forwarded to the port 5000 of your computer.All your bot needs now is its API to get your movies!
III/ CREATING THE MOVIE BOT API
The NodeJS part of this bot is fairly simple: It will behave as an HTTP proxy between SAP Conversational AI and The Movie Database.
When your application receives a request from SAP Conversational AI, it sends a search query to the Movie Database with the criteria of your user and formats the JSON answer to the SAP Conversational AI message format.
[caption id="attachment_7071" align="aligncenter" width="421"]
Bot API diagram[/caption]Option 1 : the automatic way
You can clone the entire project directly from our Git repository : https://github.com/plieb/movie-bot-skills-training
Option 2 : the manual way
Step 1 - scaffolding your project
mkdir movie-bot && cd movie-bot
npm init
npm install --save express body-parser axios
touch index.js config.js
mkdir discover-movies && cd discover-movies
touch index.js movieApi.js
cd..
Step 2 - getting a TMDb API token
You will need a token to use the Movie Database API, go here to generate one, and edit your
config.js file:module.exports = {
MOVIEDB_TOKEN: process.env.MOVIEDB_TOKEN || 'PURYOURTOKENHERE',
PORT: process.env.PORT || 5000,
};
Step 3 - filling your index.js with an Express application
Let's create an Express application to handle the requests from SAP Conversational AI. To better organize our project, as seen in Step 1, we have a folder
/discover-movies/ which contains the core of our bot code (instead of putting all our files in the same folder) and we call it through loadMovieRoute.const express = require('express');
const bodyParser = require('body-parser');
const config = require('./config');
const loadMovieRoute = require('./discover-movies');
const app = express();
app.use(bodyParser.json());
loadMovieRoute(app);
app.post('/errors', function(req, res) {
console.log(req.body);
res.sendStatus(200);
});
const port = config.PORT;
app.listen(port, function() {
console.log(`App is listening on port ${port}`);
});
Step 4 - filling discover-movies/index.js
We ask SAP Conversational AI to send a POST request to
/discover-movies when a user has filled his search criterias.The main goal of our controller is to pick and format the preferences from the memory to send them to the Movie Database's API:
const config = require('../config');
const { discoverMovie } = require('./movieApi');
function loadMovieRoute(app) {
app.post('/discover-movies', function(req, res) {
console.log('[GET] /discover-movies');
const kind = req.body.conversation.memory['recording'].type;
const genre = req.body.conversation.memory['genre'].id;
const language = req.body.conversation.memory['language'];
const nationality = req.body.conversation.memory['nationality'];
const isoCode = language
? language.short.toLowerCase()
: nationality.short.toLowerCase();
return discoverMovie(kind, genreId, isoCode)
.then(function(carouselle) {
res.json({
replies: carouselle,
conversation: {
}
});
})
.catch(function(err) {
console.error('movieApi::discoverMovie error: ', err);
});
});
}
module.exports = loadMovieRoute;
Step 5 - filling discover-movies/movieApi.js
Now that we have extracted and formatted all the filters of the request, we need to send the request to the Movie Database and format the answer:
const axios = require('axios');
const config = require('../config');
function discoverMovie(kind, genreId, language) {
return moviedbApiCall(kind, genreId, language).then(response =>
apiResultToCarousselle(response.data.results)
);
}
function moviedbApiCall(kind, genreId, language) {
return axios.get(`https://api.themoviedb.org/3/discover/${kind}`, {
params: {
api_key: config.MOVIEDB_TOKEN,
sort_by: 'popularity.desc',
include_adult: false,
with_genres: genreId,
with_original_language: language,
},
});
}
function apiResultToCarousselle(results) {
if (results.length === 0) {
return [
{
type: 'quickReplies',
content: {
title: 'Sorry, but I could not find any results for your request :(',
buttons: [{ title: 'Start over', value: 'Start over' }],
},
},
];
}
const cards = results.slice(0, 10).map(e => ({
title: e.title || e.name,
subtitle: e.overview,
imageUrl: `https://image.tmdb.org/t/p/w600_and_h900_bestv2${e.poster_path}`,
buttons: [
{
type: 'web_url',
value: `https://www.themoviedb.org/movie/${e.id}`,
title: 'View More',
},
],
}));
return [
{
type: 'text',
content: "Here's what I found for you!",
},
{ type: 'carousel', content: cards },
];
}
module.exports = {
discoverMovie,
};Step 6 - Start the engine!
That's all! You're ready to test your bot.
Start your application by running:
node index.jsAll being well, you should see:
App started on port 5000Movie recommendation, weather, health, traffic... With third-party APIs, everything is possible! Now that you're familiar with the workflow, we can’t wait to hear from you about what you’re building! And remember you’re very welcome to contact us if you need help, trough the comment section below or via Slack.
- SAP Managed Tags:
- Machine Learning,
- SAP Enterprise Chatbot,
- Training,
- SAP Business Technology Platform
Labels:
3 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
88 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
65 -
Expert
1 -
Expert Insights
178 -
Expert Insights
280 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
330 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
408 -
Workload Fluctuations
1
Related Content
- Elevating Customer Engagement: Harnessing the Power of SAP Chatbots for a Personalized Experience in Technology Blogs by Members
- Embrace the Future: Transform and Standardize Operations with Chatbot in Technology Blogs by Members
- Deliver Real-World Results with SAP Business AI: Q4 2023 & Q1 2024 Release Highlights in Technology Blogs by SAP
- SAP Build | SAP Build Code – When Generative AI comes to help! in Technology Blogs by SAP
- LangChain vs LlamaIndex: Enhancing LLM Applications on SAP BTP in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 11 | |
| 10 | |
| 9 | |
| 9 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 |